
基于多尺度形变特征卷积网络的高分辨率遥感影像目标检测
2018-09-28 07:06邓志鹏周石琳邹焕新
测绘学报 2018年9期
邓志鹏,孙 浩,雷 琳,周石琳,邹焕新
国防科技大学电子科学学院,湖南 长沙 410073
自动目标识别是遥感图像智能解译任务的重要研究方向,它要求对遥感图像中存在的多类目标进行自动定位,并赋予相应的标签类别,对于军事目标的识别判读,遥感图像的语义检索等具有重要的意义[1]。
传统的遥感图像目标检测方法主要针对单类目标,根据不同目标的固有特性(如尺寸、颜色、形状等)分别设计人工特征,然后采用滑窗搜索的策略对整幅遥感图像中的特定目标进行提取。该类方法简单易行,但是难以对多类目标同时进行检测。当前多类目标检测方法主要采用基于显著度的区域提取与分类相结合的方法。该类方法首先采用显著图或者选择性搜索对图像中可能是目标的区域进行预测,然后提取这些区域的特征用于训练得到一个分类模型[2-6]。尽管该类方法在多类目标检测任务中取得了较好的检测效果,但仍然是一个多步骤的检测流程,一方面区域预测算法计算消耗较大,且区域预测的准确与否严重影响后续的分类精度;另一方面,分类模型的好坏取决于区域特征的提取,传统的手工设计特征依赖于专业知识和数据本身的特性,难以有效地区分不同目标。此外,目标检测本质是一个回归任务,将区域预测与区域分类分割开来难以取得理想的检测结果。
近年来非常活跃的深度学习为自动目标检测提供了一个有效的框架[7-11],其中应用最为成功的是快速区域卷积神经网络(faster region-based convolutional neural networks,FRCN)[12]。该方法是一种快速、准确、一体化的检测框架,在常见的21类近景图像数据集中取得了非常优越的检测效果,诸多学者在这个基础之上对其进行了改进[13-15]。但是,FRCN类的方法在遥感中的应用仍然较少[16-19],主要有以下几方面制约[20]:①遥感图像中的目标通常是任意方向分布的,目标方向多变会给同一类目标的表征建模带来挑战;②遥感图像中的目标通常尺寸差异较大,且往往呈现密集分布的特点,而FRCN类的方法对小而密集分布的目标检测性能不佳;③基于深度学习的目标检测方法需要大量的标记样本进行训练,而遥感图像的目标标记复杂耗时,且需要专业的判读知识,难以构造大规模的训练集。
针对以上问题,本文提出了一种基于多尺度形变特征卷积网络的遥感图像目标检测方法,利用形变卷积操作和形变池化操作对具有尺度和方向变化的遥感图像目标进行特征提取,然后在多层特征图中采用不同大小的卷积核进行目标候选区域的预测,以提高检测器对小而密集分布的目标的检测性能。针对标注样本集不足的问题,本文采用了裁剪、旋转、翻转及色度空间变换等方法,对已有的数据集进行扩充。本文在光学遥感图像10类目标数据集上训练检测器,并将其用于测试大幅面谷歌地球影像、高分2号影像以及吉林1号影像,结果证明了本文方法的优越性和稳健性。
1 基于形变卷积网络的目标检测方法
图1显示了本文方法的流程,具体包括3个步骤:数据标注、数据扩充和网络训练。在数据扩充部分,本文对光学遥感图像进行旋转、翻转、色度空间变换等操作,以模拟不同的成像条件,如光度变化、视角变化等。在网络训练部分,本文主要由目标区域预测子网络和目标区域鉴别子网络组成,二者共享相同的深度网络结构。
1.1 目标区域预测子网络
目标区域预测子网络需要从图像中提取出目标可能出现的位置。传统的深度学习检测算法如FRCN,采用规则的卷积操作提取特征,然后在最后一层深度特征图采用3×3大小的滑动窗口进行目标区域预测,这给遥感图像的目标检测任务带来两方面不足。一方面,遥感图像中的目标通常是任意方向分布的,规则的方块卷积核(如图2(a)所示)并不能够准确地对不同形变的目标进行特征提取。另一方面,最后一层深度特征图空间分辨率较低,约为原始输入图像的1/16,这会导致小尺寸的目标漏检。同时,采用固定大小的滑动窗口进行候选区域预测,难以有效覆盖多类目标的尺寸变化范围,且对于密集分布的目标难以有效区分。因此,本文采用形变卷积操作提取图像特征,通过改变方块卷积核的形状,让它能够自适应地根据目标的形状来调整卷积核感受野的分布,如图2(b)所示,然后在多层特征图中分别采用3种不同大小的滑动窗口(3×3,5×5,7×7)进行目标区域预测,从而可以更加充分地提取出多种尺寸变化的遥感图像目标。
检测效果取决于图像特征提取的优劣,网络层数越多,图像的特征表达能力越强。深度残差网络(ResNets)采用残差块(图3)作为网络的基本组成部分,通过顺序累加残差块拓展网络的深度,成为了当前主流的网络结构。考虑机器显卡的性能,本文采用50层的ResNets[21]用于提取遥感图像的特征,网络模型以任意大小的图像作为输入,首先经过第1卷积层,卷积核为7×7,步长为2,然后经过最大池化层,接着经过4组不同残差块,各残差块组的残差块数量分别为3、4、6和3,每个残差块包含3个卷积层(第1层和第3层为1×1大小的卷积层,第2层为3×3大小的卷积层)。为了对具有形变特性的遥感图像目标进行特征提取与建模,本文在最后一组残差块采用形变卷积操作[22]替换传统的规则卷积操作,其原理如图4所示。以3×3大小的卷积核为例,通过对方块卷积核每个卷积采样点加上一个偏移量,可以实现任意形变的卷积操作。
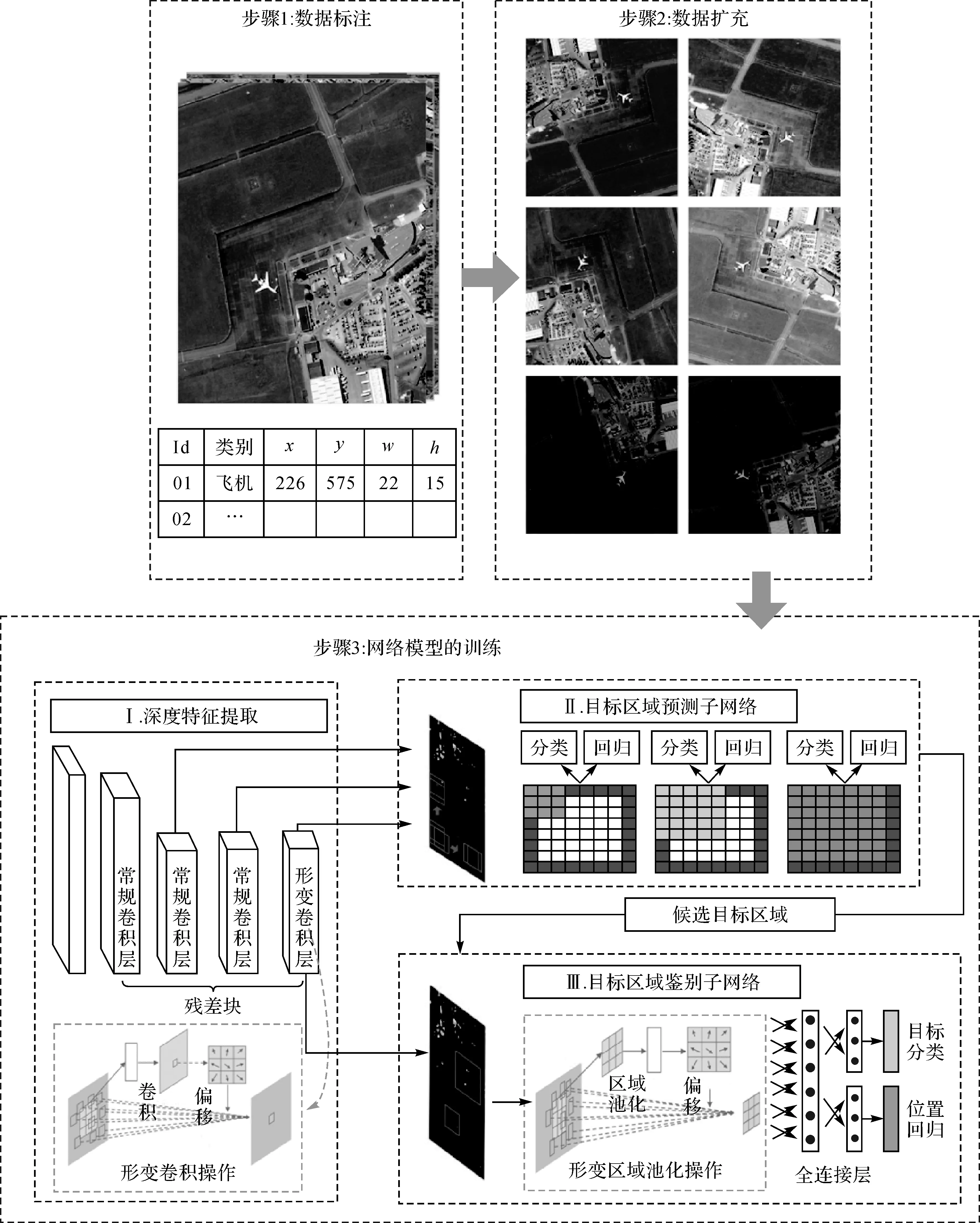
图1 本文流程Fig.1 The flowchart of our method
规则的方块卷积操作主要包括两个步骤:①在一个规则的区域R内对输入的上一层特征图进行采样;②将每个采样点的值与方块卷积核对应位置的权值进行加权求和,所得到的结果作为卷积操作的输出。其中规则的区域即为方块卷积核的感受野,以3×3大小的卷积核为例,R通常定义为

图2 卷积操作的感受Fig.2 Illustration of the receptive field
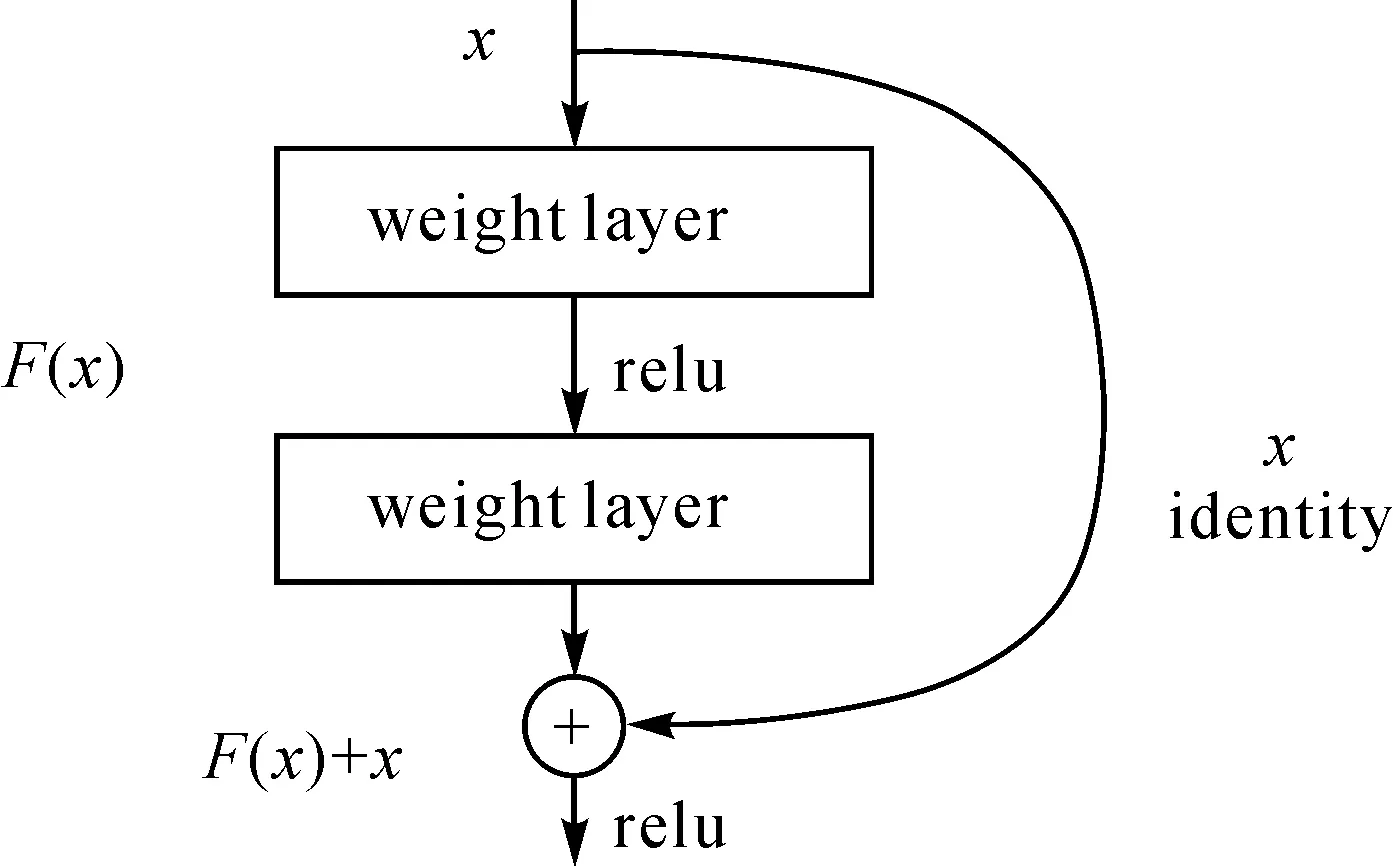
图3 残差块结构Fig.3 The architecture of residual block

图4 3×3形变卷积运算的采样示意图Fig.4 Illustration of the sampling locations in 3×3 standard and deformable convolutions
(1)
对于输出特征图y中的某一个点p0,其卷积操作定义如下
(2)
式中,pn是感受野区域R中的元素;x是输入特征图。
在形变卷积操作中,定义一个偏移量{Vpnn=1,…,N},其中N为感受野区域中元素的个数。对应的式(2)可以改写为
(3)


(4)

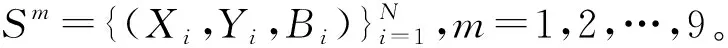
lm(X,Y,BW)=Lcls(p(X),Y)+
(5)
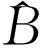
(6)
基于上述每一个训练集的定义,可以对候选目标区域预测子网络的整体损失函数定义如下
(7)
式中,αm表示加权参数。候选目标区域预测子网络可以采用梯度下降法[24]进行求解,优化目标函数为W*=arg minWLOPNW。在训练过程中,采用Image-Net预训练好的模型来初始化网络参数,新添加的形变卷积层参数初始化为0,设置加权参数αm=1,学习率为0.000 05,动量为0.9,在前10 000次迭代训练中,设置平衡参数λ=0.01,在后15 000次迭代训练中,λ=1。训练结束后,输入一幅遥感图像,将不同残差块预测出的候选矩形区域汇总后输入目标区域鉴别子网络进行进一步的分类和回归处理。
1.2 目标区域鉴别子网络
目标区域鉴别子网络对每一个候选目标区域进行区域池化操作,得到统一维度的深度特征,然后经过全连接层,得到每个候选目标区域的全连接特征,进而对候选目标区域进行分类和位置回归。考虑到遥感图像中目标的多方向旋转,会导致候选目标区域中有部分背景区域参与了区域池化操作,这会对目标特征的准确表达带来干扰,因此本文采用类似形变卷积的思想,对区域池化操作引入偏移变量,进而将其拓展为形变池化操作。常规的区域池化操作将一个w×h大小的矩形区域池化为一个k×k大小的区域,计算公式如下
(8)
式中,nij为每个子区域内像素的个数;p0是每个子区域左上角坐标。引入偏移量{Vpij|0≤i,j (9) 在上述定义的基础之上,本文的目标区域鉴别子网络采用形变池化操作,对每一个候选目标区域从第5个残差块组提取深度特征,然后采用式(5)对每一个候选目标区域进行进一步分类和回归操作,进而将式(7)的损失函数拓展为 (10) 式中,α10是目标区域鉴别子网络的加权参数,本文设置为1;S10是目标区域鉴别子网络的训练集,标记方法和目标区域预测子网络相同。采用目标区域预测子网络的模型初始化目标区域鉴别子网络,增加的全连接层参数初始化为0,然后将两个子网络联合训练,学习率设置为0.000 5,每训练10 000次,学习率减小为1/10。经过35 000次训练后,输入一幅遥感图像,取置信度最高的300个目标作为检测结果,然后采用非极大值抑制[26]对交并比重叠度较大的检测框进行剔除,剩余的检测结果作为最终检测结果。 为了验证本文方法的有效性,本文在NWPU VHR-10数据集[3]上进行了试验。该数据集共包含了650幅光学遥感图像,共标注了757个飞机、302个船只、655个油罐、390个棒球场、524个网球场、159个篮球场、163个田径场、224个港口、124个桥梁、477个车辆。这些遥感图像分辨率在0.5~2 m之间,平均尺寸约为600×800,每一幅图像至少包含一个目标。本文采用旋转、翻转和色度空间变换进行数据扩充。旋转变换分别对原图旋转90°、180°和270°。翻转变换分别对原图进行水平翻转和垂直翻转。色度空间变换首先将原图变换到HSV(hue-saturation-value)空间,然后将色彩信息H值设定为(0°,60°,120°,180°,240°,300°),将明亮程度V值设定为(0.8,1),最后将HSV空间变换回RGB(red-green-blue)空间,得到扩充后的训练样本。在训练过程中,随机取其中60%为训练集,剩下的40%为测试集。 为了验证本文方法的稳健性,本文将训练好的检测模型用于测试大幅面的谷歌地球影像和国产高分辨率光学遥感影像。其中谷歌影像是从Google Earth商业软件上截取的高分辨率彩色遥感图像,地点位于美国戴维斯蒙森空军基地(DM-AFB),分辨率为0.8 m,幅面为10 320×8465,共包含1139架飞机。国产高分辨率光学遥感影像来源于2幅高分2号卫星全色影像和2幅吉林1号卫星全色影像,分辨率为1 m,幅面为4000×4000,包含桥梁、油罐、船只、飞机等多类目标。 评价指标采用平均精度(average precision,AP),PR曲线(precision-recall curve,PRC)。其中,正确检测定义为检测结果与真值标注的IoU值大于0.5,若有多个检测结果的IoU值均大于0.5,取其中IoU值最大的检测结果为正确检测,其他检测结果为错误检测。 本文试验所采用的台式机配备有英特尔i7-CPU,英伟达GTX-1060显卡(6GB显存),64GB内存,试验平台采用深度学习工具包MXNet[27]。为了证明文本方法的优越性,本文对比了6种基于深度学习的目标检测方法: (1) RICNN(rotation-invariant CNN)[3]:采用选择性搜索算法提取候选目标区域,然后对每个区域提取具有旋转不变特性的深度特征,最后输入支持向量机分类器进行类别的判定。 (2) FRCN-VGG[12]:经典的双网检测模型,采用VGG模型提取深度特征,然后在最后一层特征图中预测目标候选区域,同时对目标类别进行分类以及对目标位置进行回归。 (3) R-FCN(region-based fully convolutional networks)[15]:在FRCN双网模型的基础上,采用50层残差网络提取深度特征,并引入了位置敏感性分数图对平移不变性进行建模。 (4) YOLO(you only look once)[13]:一种非常快速的单网检测模型,采用笔者给出的darknet19层网络模型提取深度特征,该方法首先对输入图像均匀划分为若干个小区域,然后对每个小区域预测若干个候选目标区域,最后对这些目标候选区域进行分类和位置回归。 (5) SSD(single shot detector)[14]:在YOLO基础上进一步改进的单网检测模型,采用VGG模型提取深度特征,然后对分辨率不同的多层深度特征图分别进行目标检测,因此适用于尺度变化较大的目标检测任务。 (6) FRCN-ResNets[25]:采用基于50层残差网络的双网检测模型,最后一组残差块采用形变卷积层,同时采用形变池化操作替换了常规的区域池化操作。 图5给出了10类目标在多种对比方法中的PR曲线,从中可以看出:①对比不同的类别,田径场和棒球场这两类目标对于所有的方法都取得了较好且相近的检测效果。而其他8类目标的检测结果差异较大,这是因为田径场和棒球场的尺寸相对较大,而深度学习的方法对于显著目标检测性能较好。②对比不同的算法,FRCN-VGG方法精度较差,这是由于最后一层的深度特征图分辨率较小造成的,R-FCN较FRCN-VGG性能有了明显提升,原因在于采用的残差网络层数较多,所学习出的深度特征更具有区分性。YOLO的召回率最低,这是由于YOLO算法划分的子区域数量较少造成的,SSD较YOLO算法性能有了较大提升,证明了多尺度检测的思想能够有效提升目标检测的性能。③对比FRCN-ResNets方法和FRCN-VGG方法可以看出,采用残差网络比采用VGG网络检测效果更佳。对比FRCN-ResNets类方法可以看出,单独采用形变卷积操作比单独采用形变池化操作更能提升检测性能,同时采用形变卷积操作和形变池化操作能够进一步提升检测性能,进而证明了形变卷积操作和形变池化操作对于遥感图像目标检测任务的有效性。④本文方法对于大多数类目标取得了最佳的检测效果,尤其是对于小尺寸的目标,如油罐,精度提升较为明显,证明了本文方法所采用的多尺度形变卷积特征的优越性。 表1给出了不同对比算法的性能统计结果,每一类目标最佳的检测结果用粗体表示,次优结果用下划线表示,从中可以看出:①RICNN方法的检测性能最差,且运算时间最长,这是由于该方法是个多步骤的检测方法,且区域分类过程未考虑位置的回归,其他方法均为基于深度学习的端到端的检测算法,取得了明显的性能提升,且计算效率得到了极大优化。②FRCN-VGG和YOLO算法的平均精度较低,SSD和R-FCN的平均精度较高,比较来看,双网模型的检测精度较高,单网模型的检测效率较高。③FRCN-ResNets类方法比FRCN-VGG方法检测精度高,证明了残差网络所学习出的特征比VGG网络所学习出的特征更有效。通过对比FRCN-ResNets类方法的不同组合模式可以看出,形变卷积操作比形变池化操作更能有效提升检测性能,同时采用形变卷积操作和形变池化操作能明显提升检测效果。证明了形变卷积操作和形变池化操作比传统的卷积操作和池化操作更能有效地提升检测效果。④本文方法取得了最佳的检测结果,且在多个类别均取得了最优和次优的检测结果,但是牺牲了一定的计算效率,由此证明了本文方法所采用的多尺度形变卷积特征用于遥感影像目标检测任务的优越性。 表1 不同对比算法的性能评估 图6给出了部分检测结果,不同的颜色表示不同的类别,从中可以看出,本文方法能够同时对多类目标进行检测,且在高分辨率光学遥感图像中,背景比较复杂,油罐、网球场等目标分布比较密集,车辆、船只等目标的尺寸较小,田径场目标尺寸较大,本文方法在这些复杂的情形下均能正确地对多类目标进行检测,证明了本文方法的有效性。 为了对比不同方法的检测效果,本文选取了两幅包含油罐目标和飞机目标的测试图像,这两幅图像中的目标均存在小而密集分布的特点,对比效果图如图7所示,其中绿色方框表示正确检测,红色方框表示错误检测。从图7中可以看出,FRCN-VGG方法和YOLO方法存在较多的错误检测和漏检,证明了这类从单一特征图中检测目标的方法不适用于小而密集分布的目标检测任务。SSD算法取得了较好的检测效果,其原因在于采用了多尺度检测的思想。R-FCN算法检测效果较好,其原因在于采用了更深的残差网络模型提取图像特征,具有更加优异的特征表达能力。但是这两种算法仍然存在一定数量的漏检和错误检测。本文方法结合了这两种算法的优势,采用了更小的滑动窗口对小目标进行提取,同时利用了形变卷积操作对存在着多种形变的遥感图像目标进行特征提取,因此取得了最优的检测性能,有效地减少了漏检和错误检测。 为了便于理解形变卷积网络对于遥感图像多类目标检测任务的作用,图8给出了2组形变卷积操作的采样效果图,其中红色的点(93=729个)表示经过3层形变卷积操作后,带有偏移量的采样点,绿色点表示当前采样的中心点。图中左侧图表示背景区域的采样效果图,中间图表示其中一类较大尺寸目标的采样效果图,右侧图给出了另外一类较小尺寸目标的采样效果图,从图中可以看出,对于背景区域,形变卷积的采样点分布比较杂乱,对于目标区域,形变卷积的采样点相对比较集中,且采样点的分布随着目标尺寸的变化而变化,因此具备一定的自适应性,将其用在遥感图像中,会在一定程度上具有尺寸和旋转不变特性。 为了验证本文方法的稳健性,以及对于小而密集分布目标的检测效果,本文将在上述10类目标数据集上训练好的检测模型,直接用于大幅面谷歌地球影像和国产的高分辨率光学遥感卫星影像。对于大幅面遥感影像,首先对其进行分块裁剪(600×800),为了避免对跨越边界目标的损坏,本文设置相邻裁剪块的重叠度为100个像素(略大于目标的平均尺寸);然后分别将每一个裁剪后的图像块输入本文提出的检测器;最后对输出的检测结果进行拼接。 图9给出了谷歌地球影像飞机坟场的检测效果,其中绿色方框表示正确检测结果,蓝色方框表示真值标注,红色方框表示错误检测。从图中可以看出:①飞机目标分布密集,较大尺寸的飞机如战略轰炸机,较小尺寸的飞机如战斗机,都能被有效检测出来,证明了本文方法对于检测小而密集分布的目标的有效性。②训练集所采用的主要是民航客机样本,而测试图像中主要为战斗机,且战斗机的种类较多,形状各异,本文方法均能够对它们进行有效检测,证明了本文方法所学习到的检测模型具有一定的迁移性和通用性。 图10和图11分别给出了高分2号和吉林1号光学遥感影像的检测结果,不同类别的目标分别用不同的颜色表示。从图中可以看出:多类目标能够同时被检测出来,且对于密集分布的油罐目标检测效果比较理想(图10(a)),飞机目标的检测性能比较稳定,船只目标在高分2号和吉林1号中的可视化效果差异较大,但是都能够较好的对其进行检测,桥梁目标存在少量的错误检测。上述检测结果证明了本文检测算法具有一定的推广能力,能够适用于不同类型的光学遥感图像。 图5 多种对比算法在NWPU VHR-10数据集中每一类目标的PR曲线Fig.5 PRCs of the proposed method and other state-of-the-art approaches on the NWPU VHR-10 data set 本文提出了一种基于多尺度形变特征卷积网络的目标检测方法,采用形变卷积操作和形变池化操作取代传统的规则卷积操作和池化操作,能够更加有效地对遥感图像中具有方向、尺度变化的目标进行特征学习,采用不同大小的卷积核从多层深度特征图中分别预测候选目标区域,能够更加准确地检测小而密集分布的遥感图像目标。未来工作将对检测器的泛化迁移能力展开研究,以期能够有效适用更多类型的遥感图像,同时考虑用带有主方向信息的旋转矩形框来表征遥感图像中的目标,以期对遥感图像中的目标进行更精准的检测。 图6 本文算法在NWPU VHR-10数据集中部分检测效果Fig.6 Number of object detection results in NWPU VHR-10 data set with the proposed approach 图7 不同对比算法的检测效果Fig.7 Detection results with different approach 图8 3×3形变卷积采样Fig.8 Sampling locations of 3×3 deformable convolutional layer 图9 本文方法在戴维斯-蒙森空军基地数据集的飞机目标检测效果Fig.9 Aircraft detection results on DM-AFB data set 图10 本文方法在高分2号数据集上的检测结果Fig.10 Multi-class targets detection results on GF-2 data set 图11 本文方法在吉林1号数据集上的检测结果Fig.11 Multi-class targets detection results on JL-1 data set
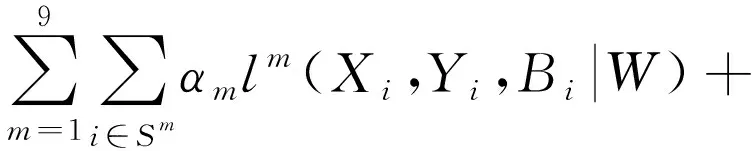
2 试验结果
2.1 试验设置
2.2 光学遥感图像10类目标数据集试验结果

2.3 大幅面光学遥感图像目标检测试验结果


3 结 论






猜你喜欢
科学技术与工程(2023年3期)2023-03-15
网络安全与数据管理(2022年3期)2022-05-23
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
北京航空航天大学学报(2018年1期)2018-04-20
