
小口径供水镀锌钢管漏损预测模型的构建与评价
2018-09-28 09:33侯本伟李云峰
净水技术 2018年9期
李 岚,吴 珊,侯本伟,李云峰
(1.北京工业大学建筑工程学院,北京 100124; 2.北京市自来水集团有限责任公司,北京 100031)
据《城市供水统计年鉴》显示,2014年全国城市供水漏损水量为62.56亿m3,平均漏损率为15.35%[1]。国务院2016年印发的《水污染防治行动计划》中明确要求到2020年全国公共供水管网漏损率要控制在10%以内[2]。《城镇供水管网漏损控制及评定标准》(CJJ 92—2016)[3]也在2017年3月1日开始正式实施。为此,迫切需要研发漏损控制技术和手段,提升管理水平。而建立复杂供水管网系统的漏损预测模型,有助于对不同类型的供水管线出现漏损事故的概率及风险进行科学的预测和评估,进而提前防控,对于提高供水管网漏损管理效率具有重要的应用价值。
已有研究表明,影响供水管网漏损的因素有管龄、管材、管径、平均压力等,可以利用比例风险模型、遗传程序设计和差分自回归移动平均模型等方法建立相应的爆管风险评估模型、爆管预测模型和漏损预测模型等[4-10]。已有的成果中对DN≥300的铸铁管、球墨铸铁管等研究较多,对小口径管段(DN100以下)的关注相对较少。在城市供水管网中,镀锌钢管是小口径管段常用管材之一,其在实际工作环境中,是漏损事故发生频率较高的一类管段。以往针对镀锌钢管的研究多是基于镀锌层脱落产生的腐蚀对水质的影响,涉及漏损问题的很少[11-13]。本研究主要针对小口径(DN100以下)的镀锌钢管道漏损问题展开。
研究选择某大城市的漏损事故数据资料,采用遗传程序设计(genetic programming,GP)和进化多项式回归(evolutionary polynomial regression,EPR)两种方法,建立以管径、管龄和管长为影响因素的镀锌钢管漏损预测模型,为确定模型的预测精度,选择最新一年的实际漏损统计数据对所建两类模型分别进行了检验。根据结果,从模型的拟合精度、公式的简洁度以及预测准确度等方面对两类模型进行了对比评价。所建立的漏损预测模型的应用可以为管网漏损控制的管理以及管道的更新改造提供科学的依据。
1 镀锌钢管漏损特点
1.1 漏损事故发生率
将所研究城市的供水管网中球墨铸铁管、钢管、普通铸铁管和镀锌钢管四种管材的连续八年的漏损资料进行了系统的分析。由于各类管材在供水管网中铺设长度不同,为更准确地表示各种管材出现漏损事故的频率,图1中采用“管长比”(各管材的实际铺设长度占供水管网所有管材铺设总长的百分比)和“事故发生率λ”(各管材每年、每单位管长出现的平均漏损次数)两个指标来进行对比,结果如图1所示。

图1 各类管材事故发生频率Fig.1 Accident Occurrence Rate of All Kinds of Pipe Materials
由图1可知,虽然镀锌钢管的铺设长度仅占总长度的9.56%,但其漏损事故发生率高达0.6次/(年·km),是四种管材中漏损事故发生率最高的。
1.2 漏损事故与管龄的关系
对比漏损资料中镀锌钢管各管龄的年平均漏损次数(简称“年漏损数”)分布情况和现状管网中不同管龄的镀锌钢管管段数分布状况,如图2所示。

图2 现状管网管龄分布Fig.2 Existing Pipe Age Distribution of Pipe Network
黑色实线为年漏损数随管龄序列的分布情况,数值对应左侧纵坐标。由此可知,管龄位于15~30年的管道,年漏损数较高;30~70年的管龄,年漏损数逐渐下降。
黑色虚线为现状供水管网中不同管龄区间镀锌钢管管段数的分布情况,数值对应右侧纵坐标。绝大多数的镀锌钢管管段位于20~40年的管龄区间,40~70年的管龄区间分布较少。
分析可知,在横坐标20~30年的管龄/年区间出现了两条曲线程度较高的重叠,且数值均为较高的峰值区。即该区间年漏损数较高,同时恰好又是镀锌钢管管段数较多的区域。表明年漏损数和管段数量随管龄/年序列的变化存在一定的趋同性。可以认为现状管网中发生漏损事故的概率较高的区域主要存在于镀锌钢管较多的区域。从侧面也证实了对镀锌钢管漏损规律研究的必要性。
图2显示的镀锌钢管的年漏损数随管龄先急剧增加而后不断下降,最后处于波动状态的变化规律,基本符合通常描述管龄与年漏损数之间的Weibull分布关系[7](图3)。Weibull分布主要用于材料的老化和寿命分析,其概率密度函数如式(1)。
(1)
其中:h—尺度系数;
b—形状系数;
g—位置参数。
镀锌钢管各管龄的年漏损数分布拟合得到的Weibull分布的概率密度曲线的3个参数值分别为h=34.3,b=1.694,g=0。

图3 年漏损数随管龄分布Fig.3 Distribution of Annual Leakage Number with Pipe Age
1.3 漏损原因
梳理分析该水司有关管道漏损的实际资料记录,可以得到镀锌钢管、球墨铸铁管和铸铁管3种管材发生漏损的原因,结合每种管材中各漏损原因导致的漏损数占总年漏损数的比例进行统计计算,结果如图4所示。

图4 漏损原因占比Fig.4 Proportion of Different Leakage Causes
图4表明球墨铸铁管和铸铁管出现漏损事故最常见原因是不均匀沉降和管道附件问题,且不均匀沉降导致的年漏损在总年漏损数中占比最大。而镀锌钢管显示出与这两类管材不同的漏损原因,97.73%的年漏损事故是由腐蚀引起的。腐蚀导致镀锌钢管漏损的原因可以从镀锌钢管防腐机理的角度解释。镀锌钢管分为热镀锌钢管和冷镀锌钢管,其中冷镀锌钢管是在小口径的钢管上镀一层锌进行防腐,锌层与钢管基体独立分层,锌层较薄不够致密均匀,使用过程中很容易消耗脱落,所起的作用更加有限,且镀锌钢管朝阳极腐蚀结垢,极易产生腐蚀漏点,从而发生漏水并影响水质。热镀锌钢管是钢管基体与熔融的镀液发生复杂的物理、化学反应,形成结构紧密的锌—铁合金层。合金层与纯锌层、钢管基体融为一体,故其耐腐蚀能力强于冷镀锌钢管。但随着铺设时间的增加,在复杂的水环境和土壤环境的共同作用下,腐蚀问题逐渐暴露。镀锌钢管腐蚀形成的原因,除了自身的管材特性外,水力条件也有影响[12-13],包括管长、管龄和管径等因素。
2 漏损预测模型的构建方法
2.1 遗传程序设计
遗传程序设计(genetic programming,GP)是一种智能化的全局搜索的优化算法,是模拟达尔文生物进化论的自然选择和遗传机理的生物进化过程的计算模型,可用于处理多参数、多变量的非线性优化问题。其基本思想是:随机产生一个适用于所给问题环境的初始种群,给种群选定一个确定的适应度,按照适者生存和优胜劣汰的原理,借助自然遗传学的遗传算子进行组合交叉和变异,产生新的高适应度的个体,即新一代的种群,如此循环,得到所给问题的最优解。这个过程将导致种群自然进化得到的后代种群比前代更加适应于环境,可以作为问题近似最优解。与遗传算法不同,遗传程序设计采用动态树状结构编码,树的结点由终结点、原始函数与运算符组成(图5)。遗传程序设计在符号回归(函数建模)问题上不仅有效(找出拟合函数关系式),且显示出很强的解题能力。

图5 遗传程序设计树状结构示意图Fig.5 Tree Structure for Genetic Programming
2.2 进化多项式回归
进化多项式回归(evolutionary polynomial regression,EPR)是一种混合的数据挖掘方法,主要是将遗传算法的有效性和数值回归相结合,提供一种进化的数学模型构建方法,能够在保证最大拟合精度的前提下,提高模型表达式的简洁度,从而在比较各最优模型表达式的同时,利用拟合精度来选取需要的模型形式[14-17]。近年来在供水管网漏损研究中逐渐被应用。
EPR的生成函数有多个可供选择的形式,本研究采用3种形式分别进行拟合,如式(2)~式(4)。
(2)
(Xk)ES(j,k))
(3)
f((X1)ES(j,k+1)·...·(Xk)ES(j,2k))
(4)
其中:Xk—第k个解释变量;
ES—未知的矩阵指数:
aj—多项式系数;
m—多项式的项数;
a0—偏差项;
f(*)—一个特定的函数类型。
3 漏损预测模型的建立
3.1 数据的收集与整理
利用收集的城市管网相关资料和连续8年的漏损事故数据,分析镀锌钢管各管径的年漏损数的变化趋势,结果如图6所示。

图6 各管径年漏损数变化趋势Fig.6 Variation Trend of Annual Leakage Number of All Kinds of Pipe Diameters
观察图6中5条分别代表DN15~DN50管径的镀锌钢管在8年中漏损数变化的折线,明显可以看出数据规律性地分为了两组:一组是除DN40以外的其他4个管径的管道年漏损数变化趋势(Ⅰ类),较为平稳的波动;另一组是DN40的管道(Ⅱ类),逐年上升。考虑8年间各管径的管道长度的变化,除DN15管道8年的长度变化值占第n年的比为33%外,DN20、DN25、DN40、DN50的管道8年的长度变化值占第n年的比在0.05%~0.13%,变化幅度很小,因此管长对年漏损数变化趋势的影响可以忽略。为保证所建模型的精确度,研究中将5个不同管径的镀锌钢管相关数据分为Ⅰ类(不同管径的组合数据)和Ⅱ类(单一管径数据)分别建模。

表1 拟合数据和验证数据的相关信息Tab.1 General Information of Model Fitting Data and Validating Data
由表1可知,计算中将5个不同直径D的管段以年(共7年)为单位分为35组,其中属于Ⅰ类的DN15、DN20、DN25、DN50这4个管径有28组数据,Ⅱ类DN40有7组。年漏损数Z,基于管长的加权平均管龄A以及各管径对应管段的总长L分别由式(5)~式(7)求出。
Z=∑Zi
(5)
其中:Z—年漏损数,次/年;
i—管段编号;
∑Zi—镀锌钢管中某管径对应的所有管段的总漏损数,次。
L=∑Li
(6)
其中:L—镀锌钢管中某管径对应所有管段的总长,km;
Li—管段i的长度,km。
(7)
其中:A—加权平均管龄,年;
Ai—以观察年为截止年,供水管网中某管径对应的管段i的管龄,年。建模阶段的截止年依次为n年12月31日~ (n+6) 年12月31日,验证阶段截止年为(n+7)年12月31日。
年漏损次数与许多因素有关,其中管径、管长和管龄影响较大[18],建模部分数据如表2和表3所示。

表2 Ⅰ类各管径漏损数与相关属性Tab.2 Leakage Number and Pipe Properties of Type I
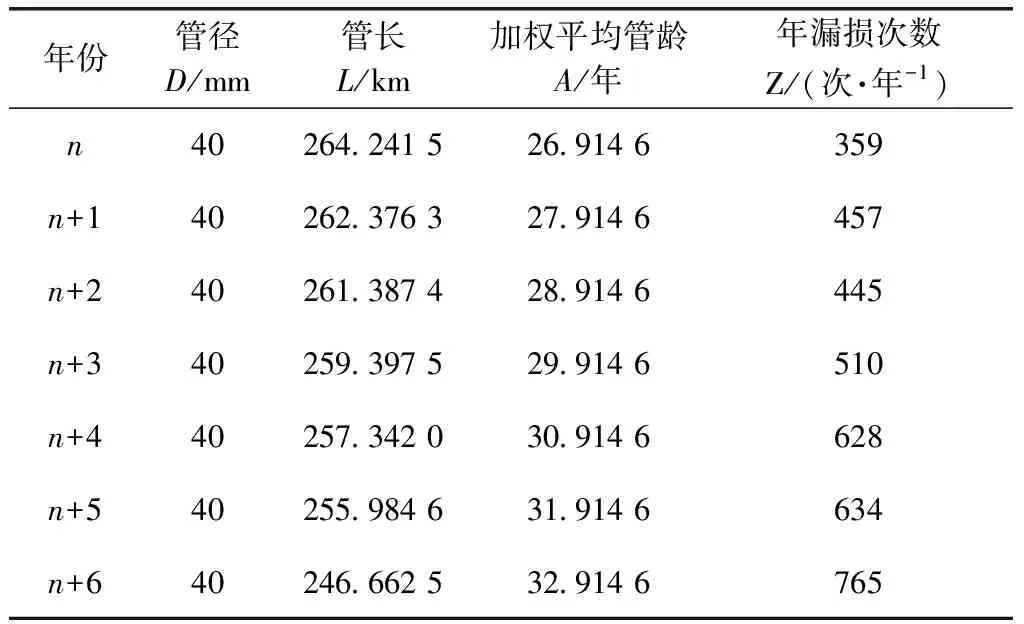
表3 Ⅱ类漏损数与相关属性Tab.3 Leakage Number and Pipe Properties of Type II
3.2 参数设置
本研究以Kuhlmann和Hollick的GP程序编码为基础,利用C++语言编程,建立以管径、加权平均管龄和管长为影响因素的镀锌钢管漏损预测模型。根据遗传程序的原理,采用不同种群大小、进化代数、交叉和变异概率的组合,进行多次程序的运行,参数的设置如表4所示。
采用Berardi 等[19]开发的EPR-MOGA XL软件包进行公式拟合。采用遗传算法寻找最优多项式模型结构,采用最小二乘法估计模型参数值。多项式的模型优劣仍然采用CoD来判断回归方程的拟合精度。参数的设置如表5所示。

表4 GP参数设置Tab.4 Parameters Setting for GP

表5 EPR运行参数设置Tab.5 Parameters Setting for EPR
3.3 拟合能力的判断
漏损预测模型拟合能力优劣采用决定系数(coefficient of determination,CoD)来判断[14,20],CoD取值范围为[0,1],值越大对应的拟合精度越高如式(8)。
(8)
其中:n—数据分组数,Ⅰ类建模时取n=28,Ⅱ类建模时取n=7;

yj—第j组数据年漏损次数的真实值;

4 预测模型计算结果与验证
4.1 预测模型计算结果
采用GP和EPR方法分别对Ⅰ类和Ⅱ类的数据进行训练,得到了数个不同的模型公式。参考各自的CoD值并考虑模型的简洁度,初步选取出了8个典型公式,如表6所示。

表6 GP和EPR方法得到的模型公式Tab.6 Equations Obtained by GP and EPR
分析表6中所列的8个公式可知,从整体来看,各模型的CoD值均达到了0.7以上,在0.9以上的有63.5%,均具有较好的拟合效果。接下来,进一步从以下两方面再进行评价。
(1)建模数据的不同分类选用方法的效果对比如下。①本研究中依据图6所显示的各管径漏损数变化趋势的不同,将镀锌钢管按照管径分为了Ⅰ类(DN15、DN20、DN25、DN50)和Ⅱ类(DN40)两组数据分别进行建模。利用Ⅱ类数据得到的模型公式CoD值均在0.93以上,Ⅰ类数据为基础的4个模型的CoD值最高为0.917 2,大部分在0.70~0.85。从形式上可以直观看出Ⅱ类数据公式比Ⅰ类更为简洁明了。但是,若选择每个管径单独建模,一方面会大大增加建模计算工作量;另一方面,由于会得到更多的模型公式,会导致今后实际应用难度和复杂程度增大。②尽管组合数据建模得到的Ⅰ类公式的CoD值比Ⅱ类小,但相比之前研究得到的其他管材模型的CoD值[7,9],本次研究得到的公式的CoD值还是更高的,说明对建模数据的拟合程度更好。因此,组合数据建模也是可行的,能够满足应用需要。
综上,两种数据分组方法均可建立有效的供水管网漏损预测模型。当各管径的年漏损数随管龄的变化趋势较为一致时,可采用组合数据建模,提高建模效率;当某一管径的年漏损数随管龄的变化趋势与其他管径不同,或针对重点管径进行漏损状况预测时,可以单独建模以提高预测的精度。
(2)两种方法的建模效率和结果对比如下。①实际建模过程中,EPR根据设定得到公式形式及参数范围,自动给出适合的模型表达式,效率较高,但已限定了模型的形式,因此,得到的可选择模型较少。GP首先得到树状结构的编码,再进一步整理模型的表达式,效率较低,但通过交叉、变异等方法,得到的模型公式数量为设置的进化代数的数量,可选择范围广。②EPR得到的公式大多为单项式,而GP建模得到的均为多项式。③Ⅰ类4个模型中,EPR得到的两个模型的CoD值更高,公式项数更少;Ⅱ类4个模型中,公式均较为简单且GP得到的两个模型的CoD值更高。
综上,两种方法各有优势,EPR更能够快速高效地得到简洁的模型表达式,而采用GP能得到更多的模型选择范围,且组合建模时宜采用EPR,而单一管径建模宜采用GP。
4.2 模型检验
从应用角度分析后,选中表6中公式编号为28-EPR-1、28-EPR-2、7-GP-1和7-GP-2的4个模型进入下一步的验证。
将利用上述4个公式对该市管网第(n+7)年漏损情况进行的预测计算结果与该市第(n+7)年供水管网实际漏损维修统计资料进行对比分析,采用均方根误差(root mean square error,RMSE)表示预测模型预测能力的优劣,RMSE值越小,预测模型精度越高,如式(9)。
(9)

y—第(n+7)年各管径年漏损数的真实值;
m—数据分组数,Ⅰ类验证时取m=4,Ⅱ类验证时取m=1。
各模型预测结果如表7所示。
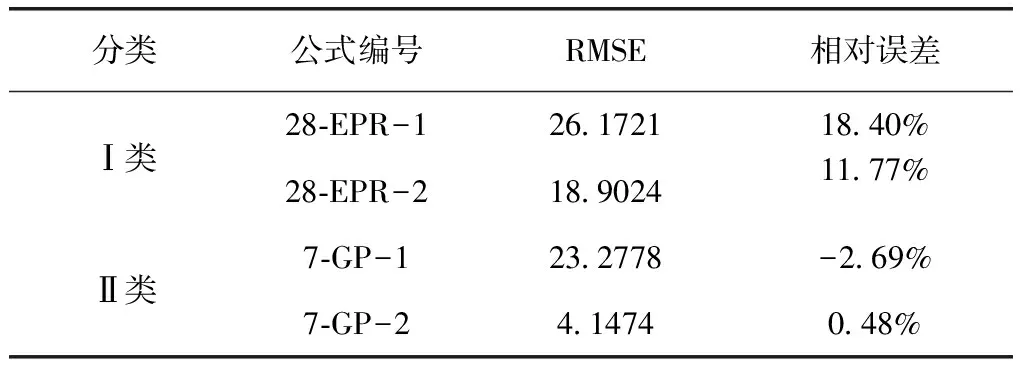
表7 模型预测结果Tab.7 Results of Model Prediction

图7 Ⅰ类数据预测值与实际值对比Fig.7 Comparison of Class I between Predicted Values and Actual Values
图7和图8为两类共4个模型的预测值与实际值的对比图,每个分类中,各模型计算得到的预测值与实际值均相差较小。综合考虑表7的预测结果,Ⅰ类中28-EPR-2的RMSE和相对误差比28-EPR-1小,预测准确度更高;Ⅱ类中7-GP-2的RMSE和相对误差的绝对值比7-GP-1小,预测准确度更高。因此,最终推荐28-EPR-2和7-GP-2为该市供水管网中镀锌钢管年漏损数的预测模型。

图8 Ⅱ类数据预测值与实际值对比Fig.8 Comparison of Class II between Predicted Values and Actual Values
5 结论
结合城市供水管网漏损事故的发生特点,本文针对镀锌钢管道漏损风险问题,分别运用遗传程序设计和进化多项式回归方法建立了以管径、管长和加权平均管龄为自变量,年漏损次数为因变量的镀锌钢管的漏损预测模型,研究结果如下。
(1)遗传程序设计和进化多项式回归两种方法均能建立拟合精度较高的供水管网镀锌钢管漏损预测模型,其中进化多项式回归建模效率更高,模型更为简洁,遗传程序设计建立的模型数量多,有更广的选择范围。
(2)经过综合分析评价,最终推荐以下用于镀锌钢管漏损预测的模型。
适用于DN15、DN20、DN25、DN50等管径的漏损预测模型如式(10)。
(10)
适用于DN40的漏损预测模型如式(11)。
(11)
(3)对于同一类管材不同管径的管道的漏损模型,可以选择组合数据建模和单一管径数据建模两种方式,且两种数据利用方式均可以对漏损数据进行有效拟合,得到较好的预测结果。从提高模型预测精度的角度考虑,需要根据各管径管材出现漏损事件的规律性是否一致来决定选用何种数据利用方式。
实际数据对研究得出的模型的验证结果表明所构建的模型能够较好地预测小口径镀锌钢管漏损事件的风险状况,可为今后供水管网的漏损管控、管道更新改造方案的制订等提供更多的参考依据。
猜你喜欢
表面工程与再制造(2022年1期)2022-05-25
供水技术(2022年1期)2022-04-19
净水技术(2022年3期)2022-03-10
建材发展导向(2021年22期)2022-01-18
煤气与热力(2021年7期)2021-08-23
建材发展导向(2021年11期)2021-07-28
煤气与热力(2021年5期)2021-07-22
表面工程与再制造(2019年3期)2019-09-18
电子制作(2019年14期)2019-08-20
原子与分子物理学报(2015年3期)2015-11-24
