
基于三角模糊数的车联网簇头节点选择方法
2018-09-27 07:14刘蕴曹军芳王凤琦
汽车技术 2018年9期
刘蕴 曹军芳 王凤琦
(1.周口职业技术学院,周口 466000;2.许昌职业技术学院,许昌 461000;3.长安大学,西安 710064)
主题词:车联网 簇头选择 三角模糊数 学习机制 相对距离 相对速度
1 前言
基于车联网中车辆间的交互通信提高交通安全性已成为近年来的研究热点。由于网络中车辆节点的高速移动性,车联网存在网络拓扑变化频繁、链路断开频繁、车辆密度多变等特点,使得车联网网络连接性频繁变化[1]。针对上述问题,电气和电子工程师协会(Institute of Electrical and Electronics Engineers,IEEE)发布了IEEE 802.11p协议,以满足车联网安全应用中的可靠性和低延迟需求[2]。但该协议在可预测性、公平性等方面存在不足,网络密度较高时会使网络吞吐量下降并造成较高的数据冲突[3]。
为了提升车联网的网络传输性能和可靠性,相关研究人员提出了基于簇的多路访问控制(Multiple Access Control,MAC)协议[4]。在车联网中,车辆节点集簇有助于限制信道竞争、提供公平的网络接入,并通过网络资源的空间复用和网络拓扑的有效控制提升网络的性能[5]。集簇过程中的主要难点在于如何有效降低因簇头选取及在高动态性和快速变化的网络拓扑中维护所有簇成员等带来的额外网络开销[6]。
针对车辆节点的集簇问题,文献[7]提出了一种LID集簇算法,车辆节点向其邻居广播自身ID,具有最低ID的节点被选为簇头,处于簇头通信范围内的邻居节点成为簇成员;文献[8]提出了一种加权集簇算法,通过考虑一个簇头可处理的节点数量、传输功率、能量消耗和移动性等因素,并为上述因素赋不同的权重得到一个度量标准,进而选取度量值最低的节点为簇头,该方法能够实现较高的吞吐,但是因为存在较高的通信和计算负载,无法满足高移动速度节点的需求,因此并不适用于车联网环境;文献[9]基于近邻传播算法提出了一种基于移动性的集簇机制,基于车辆间的距离完成簇头的选取,该方法对移动性提供较好的支持,但存在长聚合延迟及网络负载较高、吞吐较低等问题。针对现有方法的不足,本文提出了一种基于三角模糊数的车联网簇头节点选择方法,主要通过三角模糊数和学习机制完成车辆节点加速度的预测,并通过定义的加权稳定因子完成簇头节点的选取。
2 典型车联网场景构建
本文构建了如图1所示的一种典型车联网应用场景。该场景基于一条单向多车道道路构建。因此,在该场景中,车辆仅能与自身同向运动的车辆进行通信。考虑到一般车联网通信设备(技术)的通信范围远大于道路宽度,为了不失一般性的同时简化研究难度,通过上述方式将车联网通信网络中的节点设定为同向运动。假定所有车辆节点依赖卫星定位系统的时间信息进行时间同步,当车辆节点同步到控制信道间隔(Control Channel Interval,CCI)时,相互传输安全状态信息。本文按照文献[10]的方法,将CCI设置为100 ms。在控制信道间隔的开始,车辆节点周期性地发送自身状态信息,一般包含其位置、速度、加速度和行驶方向,行驶方向指车辆通过卫星定位系统计算的自身相对于真北方向的运动方向。设定所有的车辆状态信息均具有相同的长度L,所有车辆节点具有相同的通信范围R。车辆基于泊松分布在道路上分布,平均车辆密度设定为λv。此外,每个车辆节点的行驶速度在vmax和vmin间随机分布。
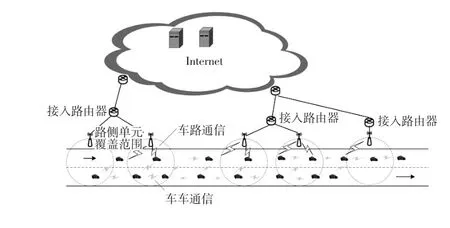
图1 典型车联网应用场景
3 簇头选择算法
考虑到车联网中的车辆节点是高度动态的,并且车联网的网络拓扑会频繁变化,因此,簇头选取算法应当是分布式且异步操作的。这要求簇头的选取和重选算法应公平、简洁且与处于其通信范围内的车辆具有尽可能少的通信和协调过程。为使在具有高动态特性的车联网环境中形成的簇更加稳定,算法不应该频繁发起簇头选取,而且应使节点能够平滑地加入、离开当前簇或形成新的簇。此外,如果网络发起了一次簇头的选择或重选过程,算法应能在很短的时间内形成稳定的簇拓扑。
在车联网通信网络中,簇头的选取和簇的形成依赖于道路上互相处于通信范围的车辆节点的车辆状态信息交互。本文设定车辆状态信息包括车辆的ID、速度v、加权稳定因子WSF、位置x0、加速度a、通信范围R、簇头ID(CHID)、备选簇头ID(CHBK)。
3.1 加权稳定因子
在定义的车辆状态信息中,加权稳定因子WSF指该车辆在道路上运动时,相对于其他车辆的运动稳定性的加权平均值。车辆运动稳定性指道路上相邻车辆间的相对运动状况,本文采用稳定系数SF对其进行描述。在每一个控制信道间隔,每辆车j将获得处于其通信范围内的所有车辆的状态信息,进而利用状态信息计算自身与所有处于其通信范围内邻居车辆的速度差值的平均值:

式中,n为车辆j与处于其通信范围内的所有邻居车辆的数量的总和;vj为第j辆车的行驶速度。
在每个控制信道间隔结束前,车辆j利用计算自身稳定系数:

基于上述公式,如果道路上没有其他车辆,车辆j将直接通过vj和vmax计算稳定系数SF,其中SF∈[0,1]。
加权稳定因子WSF是稳定系数SF的指数加权移动平均值。每个车辆i通过最新计算得到的稳定系数值SFi和最近计算的加权稳定因子WSFi-1(WSF0=0)计算最新的加权稳定因子:

式中,ξ∈[0,1]为平滑因子,本文设ξ=0.5。
WSF越大的车辆运动稳定性越高,本文设定WSF较高的车辆节点更容易被选为簇头。
3.2 基于三角模糊数的加速度预测
在本文定义的车辆状态信息中,加速度a是指车辆在某一时刻的加速度。通过加速度可以预测车辆在未来短时间内的速度和位置,进而实现簇头的选择和重选。
驾驶员进行加速、减速和维持速度不变等决定依赖于多种因素,例如与前车的相对距离和相对速度、实时道路状况、驾驶员的驾驶行为等。一般说来,驾驶员的行为(加速、减速或恒速)与驾驶员个人对车间距、相对速度等参数的预估有关,是一种相对主观的行为,难以通过确定的方式进行预测,属于典型的不确定性问题。因此,本文基于模糊逻辑构建模糊推理系统(Fuzzy Inference System,FIS)处理该问题。
FIS是一种基于一系列IF-THEN模糊规则的系统,能借助隶属度函数概念,根据几个变量的输入,以及一组自然语言表述的经验规则,来决定输出,从而模拟人脑实施规则型推理[11]。因此,本文基于FIS的上述特性,构建一种模糊推理系统以实现根据驾驶员的前期行为完成车辆加速度的预测。除此之外,考虑到FIS缺少一种能够自适应地处理变化的外部环境的能力,为了解决该问题,本文在构建的模糊推理系统中引入了一种学习机制,以更好地满足对驾驶员行为的适应性。本文选取三角模糊法实现FIS的构建,设置FIS的输入参数为两车的车间距和相对速度,输出参数为车辆的加速度。
设车辆与其前方紧邻车辆的距离的隶属函数为μd,且μd可以取值为“小”“中”或“大”,如图2所示。图2中,ts为后车j以车速vj行驶过与前车i的安全跟随距离所需的时间,是一个设计参数。
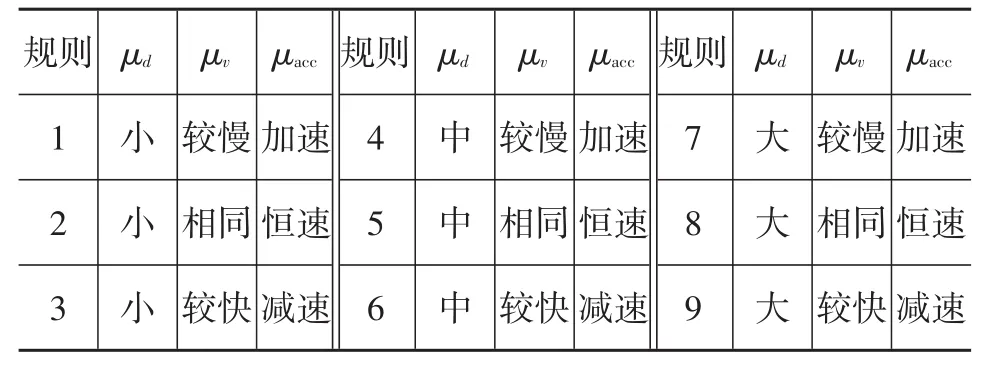
表2 模糊推理系统的模糊规则
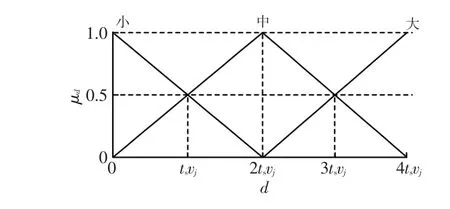
图2 相对距离的隶属函数
设车辆与其前方紧邻车辆相对速度的隶属函数为μv,且μv可以取值为“较慢”“相同”或“较快”,如图3所示。本文设置参数α和γ,赋予FIS一定的学习能力,使其对道路上驾驶员行为的自适应更优。具体学习机制为:设α=γ=1,在系统运行过程中,若驾驶员关于加速或减速的实际决策与预测值不匹配,则α和γ逐步增加或减少ε,具体执行规则如表1所示的。通过该方式,图3所示的μv隶属函数的相交点将向左或向右移动,直到经过一段时间后α和γ收敛到确定值,以实现对道路上驾驶员行为的跟踪。

表1 参数α和γ的赋值规则
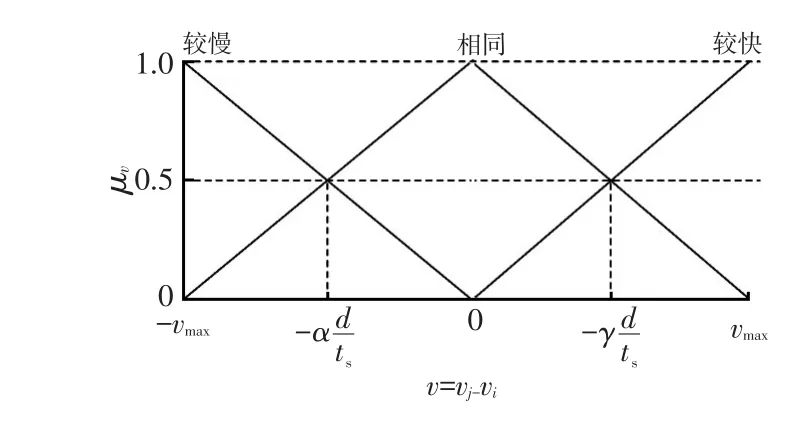
图3 相对速度的隶属函数
定义FIS的输出量,即预测加速度为μacc,且μacc可以取值为“加速”“恒速”或“减速”,本文取选择2 m/s2、0、-2 m/s2为其具体值。这种中心平均解模糊化能够基于输出模糊集的加权平均值产生明确的输出值。输出变量μacc如图4所示,模糊规则如表2所示。
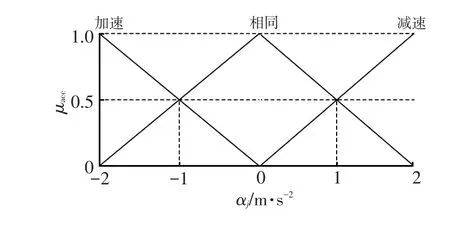
图4 加速度的隶属函数
通过上述构建的基于三角模糊数的模糊推理系统,使每辆车能够在下一个簇维持时间Tf内,基于自身与前方最邻近车辆间的相对速度和相对距离,广播其预测的加速度。该Tf结束后,车辆基于其当前速度、之前的速度和行驶距离计算自身在过去Tf时间内的真实加速度。如果真实值与预测值相符,该车辆不改变α和γ的值,也即构建的模糊推理系统已经学习到了当前道路上的驾驶员行为。否则,系统将基于前述规则动态改变α和γ的值,也即模糊系统继续进行学习。通过改变α和γ的值,μv隶属函数的相交点将会不断变化以反映驾驶员对于道路上速度和距离的个体感知。
3.3 簇头选取方法
如果某车辆在处于其通信范围内的所有车辆中具有最高的WSF,该车辆将选择自身为簇头,并将车辆状态信息帧中的簇头ID设置为自身ID。如果处于其通信范围的邻居车辆中,有其他车辆同样具有最高的WSF,当前车辆将选择该邻居车辆为临时簇头,并将车辆状态信息帧中的备选簇头ID设置为该邻居车辆的ID。最新选取的临时簇头车辆将检验在处于其通信范围的所有车辆中,自身是否具有最高的WSF,如果是,该车辆将选择自身为簇头,否则该邻居车辆将允许自身被设置为临时簇头,在与其他簇合并或自身状态改变为主要簇头前,不会参与选择新的簇头。
新选择的临时簇头进入到其相邻簇头通信范围的1/2距离时,将发送一个包含该相邻簇头ID的状态信息,实现与该簇的融合。当接收到该状态信息时,临时簇头的簇成员将判断自身是否处于该相邻簇头的通信范围内:如果是,临时簇头的簇成员将加入该相邻簇头所在簇;如果不是,它们将在不能加入该相邻簇的剩余车辆节点中选取一个拥有最高WSF的车辆节点作为新的簇头。
为了促使车联网通信网络形成稳定的簇拓扑,如果一辆车在其通信范围内既不是簇头,且处于某临时簇头的通信范围内,那么该车辆节点将加入该临时簇,且不会参与选择其他的临时簇头。如果一辆车同时处于2个簇头的通信范围内,该车辆节点将与最近的簇头集簇。
一旦簇头选择完毕,应当尽可能使得形成的簇拓扑结构稳定,因此应尽量减少簇头选取的频率。为了实现上述目的,在Tf结束后,簇头将基于所有簇成员的速度和加速度计算所有簇成员的预期位置:

式中,x0为车辆的当前位置。
簇头将从所在簇质心周围的所有车辆中选取一个拥有最高WSF值的节点作为备选簇头。并在簇头的状态信息中备注备选簇头的ID(BKID),进而通过状态信息的交互将备选簇头信息告知所有簇成员。如果前簇头消亡或驶出通信范围,备选簇头将自动成为新的簇头,周而复始,从而在一定程度上维护了簇的稳定性。
如果在下一个Tf内,所有的簇成员将继续处于簇头的通信范围内或者当前簇头比备选簇头的覆盖范围广,那么当前簇头将维持其簇头职责。否则,当前簇头通过把簇头ID(CHID)赋值为BKID,从而将簇头职责移交给备选簇头,并向簇成员广播新簇头消息。在收到该消息后,簇成员将直接与新簇头通信,从而避免了不必要的簇头重选过程。
4 仿真平台搭建
4.1 评价参数
为了测试方法的有效性,采用簇头平均生存时间(仿真阶段网络内所有簇头生存时间的平均值)、簇成员平均驻留时间(仿真阶段网络内所有车辆节点作为簇成员驻留于一个簇内的平均时间)和簇平均规模(网络内所有车辆节点数量与在仿真阶段生成的所有簇的数量的比值)作为评价标准进行测试。
4.2 仿真环境
基于iTETRIS软件构建仿真平台[12],采用NS-3网络仿真器进行车联网通信网络的仿真,采用微观交通仿真器SUMO产生的MOVE车流模型进行交通流的仿真。在SUMO中设定道路仿真环境为一段长度8 km的单向4车道高速公路,道路上仿真车辆的限速为80~120 km/h,如图5所示。采用Nakagami-m传播模型进行仿真参数的配置。基于“三秒车距”法设定仿真环境内的安全行车时间为ts=3 s,设定簇维持时间Tf=10 s。将本文提出的方法与CMCP方法[13]和APROVE[9]方法进行比较。设每次仿真时间为1 000 s,共仿真10次,具体仿真参数如表3所示,其中,取车辆密度设置标识ρ=1表示一般车辆密度,每公里道路约为100辆车。

图5 仿真界面
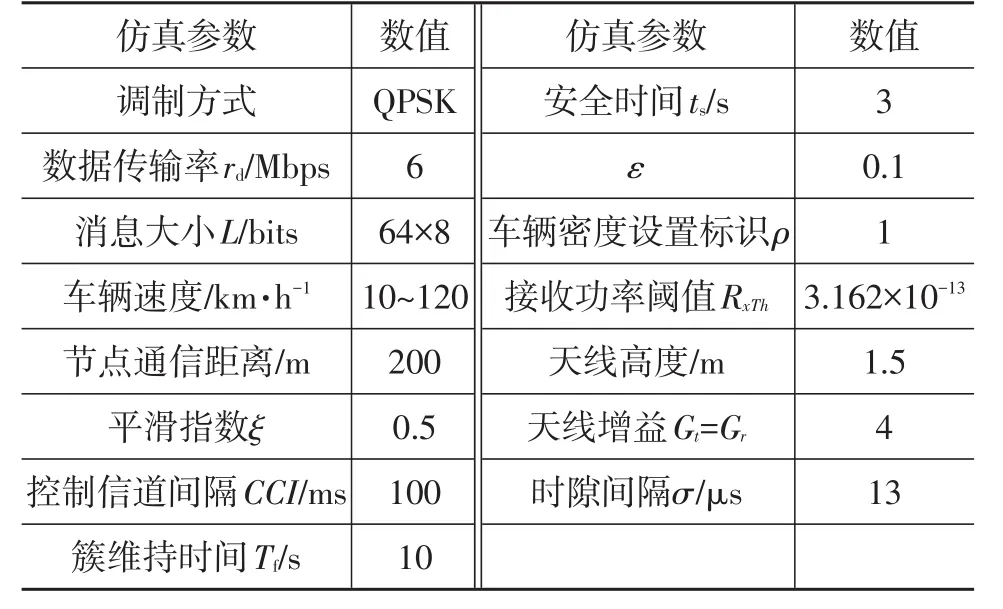
表3 仿真参数配置
5 仿真测试结果
图6所示为交通流密度对簇拓扑结构影响的仿真结果。仿真场景中的交通密度λv的增加可以通过降低车辆平均速度或增加单位道路路段内的车辆数量实现。图6a描述了车辆密度对簇头平均生存时间的影响,测试结果表明,3种方法均表现出簇头平均生存时间随车辆密度而增加,这是由于随着车辆密度的增加,车间距变小。但相对而言,本文提出的簇头选取方法更为有效,这是因为经过Tf后,簇中大多数或全部成员都处于簇头通信范围内时,允许簇头对自身进行重选。图6b和图6c说明,对于3种方法,随车辆密度增加,簇规模和簇成员平均驻留时间均显著增加,这也表明了本文算法的有效性。

图6 簇拓扑结构对车辆密度的影响
图7所示为簇维持时间Tf对簇拓扑结构影响的仿真结果。Tf增加时,车辆未来位置和速度预测结果的准确性一般会下降,但测试结果表明,对于本文提出的方法,当Tf增加时,预测结果下降的程度更不显著。这是由于本文提出的方法能更好地描述道路上的驾驶员对自车与相邻前车间的相对距离和相对速度变化的真实反应。本文提出的学习算法增加了选择和重选簇头的有效性,能够给簇成员更多的时间驻留于所在簇边界,而且簇的规模也将增加。从图7所示的测试结果可以看出,对于每一个网络场景,Tf存在一个最优值,能够最大化簇的稳定性。因此,应根据配置范围和平均车辆密度谨慎选择Tf,以增加驻留时间,并降低算法的复杂度。

图7 簇维持时间Tf对簇拓扑结构的影响
6 结束语
本文针对现有车联网簇头节点选择方法不足的问题,提出了一种基于三角模糊数的车联网簇头节点选择方法。通过基于iTETRIS构建的车联网仿真平台,验证了提出的基于三角模糊数的车联网簇头节点选择方法的有效性。后续研究中,将对提出的方法在大规模仿真场景中(城市级)进行测试验证,以提高算法的适应性。
猜你喜欢
今日农业(2022年3期)2022-11-16
汽车实用技术(2022年14期)2022-07-30
当代水产(2022年6期)2022-06-29
党的生活(黑龙江)(2022年4期)2022-04-25
汽车实用技术(2022年7期)2022-04-20
现代电子技术(2022年8期)2022-04-13
汽车实用技术(2022年4期)2022-03-07
现代电子技术(2022年4期)2022-02-21
金桥(2018年4期)2018-09-26
劳动保护(2018年8期)2018-09-12
