
多分辨率线段提取方法及线段语义分析
2018-09-21 09:46:04王正玑程章林
集成技术 2018年5期
宋 欣 王正玑 程章林
1(中国科学院深圳先进技术研究院 深圳 518055)
2(中国科学院大学深圳先进技术学院 深圳 518055)
3(中国科学技术大学软件学院 苏州 215123)
1 引 言
线段是一种常见的几何元素,在一些计算机辅助设计软件中常常作为基本的几何元素用于人造物体的设计。这使得生活中的一些人造物体,如工业零件、建筑、家具等都具有丰富的线段特征。因此,线段的检测和提取在数字图像处理、计算机视觉领域具有重要意义。
与各种点特征相比,线段特征是一种更具有全局特性的特征,不仅具有位置信息,还具有方向信息,在很多情况下鲁棒性更佳。线段特征已被广泛应用于场景理解[1-3],几何与姿态估计[4,5],同步定位与地图构建[6-8]及三维重建[9,10]等方面。
当前的许多线段提取方法都是从图像的灰度梯度角度来考虑的。线段特征在图像上的主要特点是,在某个方向上图像的灰度梯度较大,而在与之垂直的方向上灰度梯度较小。线段提取比较经典的一项工作是 Von Gioi 等[11]提出的线段检测器(Line Segment Detector,LSD)。该方法首先通过计算图像中每个像素的灰度梯度和灰度明暗变化的分界线生成一个单位向量场,再根据向量场中各个向量的方向将向量场分割成不同的连通区域,即在同一个连通区域中的向量方向具有一致性。然后,在这些连通区域上拟合出候选线段。最后,根据 Helmholtz 原则[12]来剔除错误检测。该方法能够得到亚像素精度的结果,并且能够很好地控制错误检测的数量。
除了直接在原始图像上提取线段外,还有一些线段提取方法通过先从原始图像上提取一张边缘图(Edge Map),然后在边缘图上来提取线段[13,14]。基于统计的霍夫变换(Hough Transform,HT)是在边缘图上提取线段常用的方法,但 HT所提取到的是满足有足够多的边缘点支持的无限长直线,需要将其分割后才能得到线段。这样不仅容易造成过多的错误检测,还使提取到的线段非常细碎、不完整和不连续。针对以上问题,2015 年,Lu 等[14]提出了 CannyLines 方法,该方法使用了自适应参数的 Canny 算子来提取边缘图,并加入了线段扩展和合并的操作,提高了线段的连续性和完整性。
虽然线段提取方法的效果已越来越好,但从本质上说,无论是在原始图像上提取线段还是在边缘图上提取线段,都是基于局部梯度信息,均存在以下两个问题:(1)由于光照不均或者遮挡等因素的影响,线段提取的结果往往不完整、不连续;(2)不能区分不同语义的线段。传统的基于梯度的线段提取方法认为图像灰度梯度大的地方就是线段,但图像上灰度梯度大却有着两种不同的语义。其中,第一种是由于纹理或者光照等因素造成的颜色突变,第二种是不同物体的轮廓。在本文中,分别称这两种不同语义的线段为纹理线段和轮廓线段。
以上两个问题的存在,使得传统基于梯度的线段提取方法不能满足某些应用的需求,如立体匹配和三维重建等。完整连续的线段能够保证立体匹配的效果,语义信息则可以加速线段匹配的速度,并且能够减少错误匹配的数量。因此,区分两种不同语义的线段在基于线段的三维重建中具有重要的意义。尽管这两种不同语义的线段在图像上的表征十分相似,但在三维空间中却有着不同的几何意义。其中,由纹理和光照等因素产生的线段常常分布在一个平面多边形的内部,而物体轮廓的线段则起着支撑物体形状的作用。这两种不同语义的线段之间是一种非常复杂的关系,很难通过设计一些简单的规则来进行区分。而深度神经网络具有非常强大的描述能力,能够表达非常复杂的关系。
因此,本文提出了一种线段提取方法,该方法在多分辨率的图像上进行线段提取,提高了线段的完整性和连续性,并且结合深度神经网络技术对线段进行语义上的区分。该方法的主要步骤如下:首先,在不同分辨率下提取线段;其次,使用深度神经网络分析线段语义;最后,对线段进行聚类合并。该方法具有以下两个创新点:(1)采用多分辨率提取线段再聚类合并的方法提高了线段的连续性和完整性;(2)将传统基于梯度的线段提取方法与深度学习相结合,分析不同线段的语义。
2 多分辨率线段提取
图像上线段特征的提取结果与分辨率有很大关系。一般来说,在高分辨率下提取线段的结果更加精确,但由于高频噪声及纹理的影响,线段的连续性和完整性不够好。而在低分辨率下提取线段则会损失一部分精度,但由于高频噪声及纹理的减少,提取的线段会更加完整。因此,在高分辨率和低分辨率下提取线段有不同的优缺点。为了发挥不同分辨率下提取线段的优势,保证提取线段的连续性和完整性,本文将在多个分辨率下提取线段,并在后面的步骤中对不同分辨率下提取的线段进行聚类合并。
本文采用 LSD 方法[11]来提取特定分辨率下的线段。其中,LSD 方法提取的线段为矢量形式,用线段的起点和终点坐标表示,如线段Li=siei(si、ei分别为线段的起点和终点)。分辨率的设置根据具体情况调整,一般来说设置为 2~3个分辨率。分辨率的范围为原始图像分辨率的0.5~2 倍。其中,超过 1 倍分辨率的图像通过对原始图像进行上采样得到,上采样过程中使用 3次样条插值方法进行插值。如图 1 所示,在一些实例中,从原始图像上无法提取到线段,但在上采样后的图像上却可以提取到线段。而低于 1 倍分辨率的图像则是通过对原始图像进行高斯滤波和下采样得到。过低的分辨率将会带来较大的误差,过高的分辨率则会增加计算复杂度。由图 2可以看到,线段的完整性随着分辨率的降低而提高,但精度却在下降。

图1 上采样对线段提取结果的影响Fig. 1 Effect of upsampling on line segment extraction results
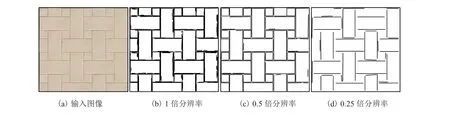
图2 不同分辨率下线段提取的结果Fig. 2 The results of line segment extraction at different resolutions
3 基于神经网络的线段语义分析
单层的神经网络也称作感知机,是最简单的神经网络。由于感知机只能处理线性可分的问题,对于很多复杂的问题需要使用多层神经网络来解决。多层神经网络可以看作是多个感知机单元的组合。其中,前端第一层叫做输入层,中间的叫隐含层,末端的叫输出层。在 2006 年,Hinton 和 Salakhutdinov[15]发现具有多个隐含层的神经网络学习特征的能力更强,并且可以通过逐层预训练的方法来缓解训练复杂性,自此越来越多的科研人员投入到深度神经网络的研究当中。
卷积神经网络在计算机视觉领域应用非常广泛。与普通的神经网络相比,卷积神经网络使用了大量的卷积层。1990 年,Le Cun 等[16]提出的LeNet-5 多层卷积神经网络在手写字体识别上取得了非常高的准确率。2012 年,Krizhevsky等[17]提出的 AlexNet 卷积神经网络在图像分类竞赛中取得了最低的错误率,并远远超过第二名的成绩。2015 年,Long 等[18]提出了全卷积神经网络(Fully Convolutional Network,FCN),能够接受任意大小的图像作为输入,且输出结果也是一张图像,大小与输入图像相关。由于全卷积神经网络能对输入图像进行像素级别的分类和预测,故非常适合处理像素级别图像语义分割的任务。
线段的语义与图像上像素的语义有紧密关系,可以由线段周围的像素语义得到线段的语义。而获取图像上像素的语义是一个像素级别的图像语义分割问题,即图像上所有的像素可以分为两类:物体轮廓边缘的像素和其他像素。这两种像素构成了一副轮廓图。
由于全卷积神经网络非常适合处理像素级别的语义分割问题,所以本文采用全卷积视觉几何组(Fully Convolutional Network-Visual Geometry Group,FCN-VGG)网络来对图像进行语义分割。FCN-VGG 网络由视觉几何组(Visual Geometry Group,VGG)网络[19]进行结构调整得到。与 VGG 网络相比,FCN-VGG 去掉了最后的 3 个全连接层,但加上了反卷积层。
深度神经网络的精度和泛化能力与训练样本的数量有很大关系,但这样大量的样本很难获取且标注成本很高。因此,本文首先采用 VGG网络在 ImageNet 数据集上训练得到的权值作为FCN-VGG 网络特征提取部分的初始权值;然后,使用手工标注的 219 张图像进行调优。这样不仅节省了大量的训练时间,还节约了数据标注的成本。图 3 为数据集标注的实例。其中,图3(a)为输入图像;图 3(b)为标注的轮廓图,轮廓图中白色像素表示轮廓像素,黑色像素表示其他像素。

图3 图像标注实例Fig. 3 Image annotation example
在训练过程中,将训练集中的 219 张图像随机分为两部分。其中,154 张为训练集,65 张为测试集。本文采用 TensorFlow 框架对 FCNVGG 网络进行训练,每次训练图片的 Batch 大小为 4,采用随机梯度下降优化算法进行优化。在训练过程中,训练集上的损失和测试集上的损失如图 4 所示。由图 4 可以看到,随着迭代次数的增加,训练集上的损失逐渐变小,测试集上的损失则先逐渐变小,但在 3 000 次迭代后呈现出增长趋势,说明此时神经网络模型存在过拟合的风险。因此,在后面的步骤中采用 3 000 次迭代的神经网络模型进行预测。
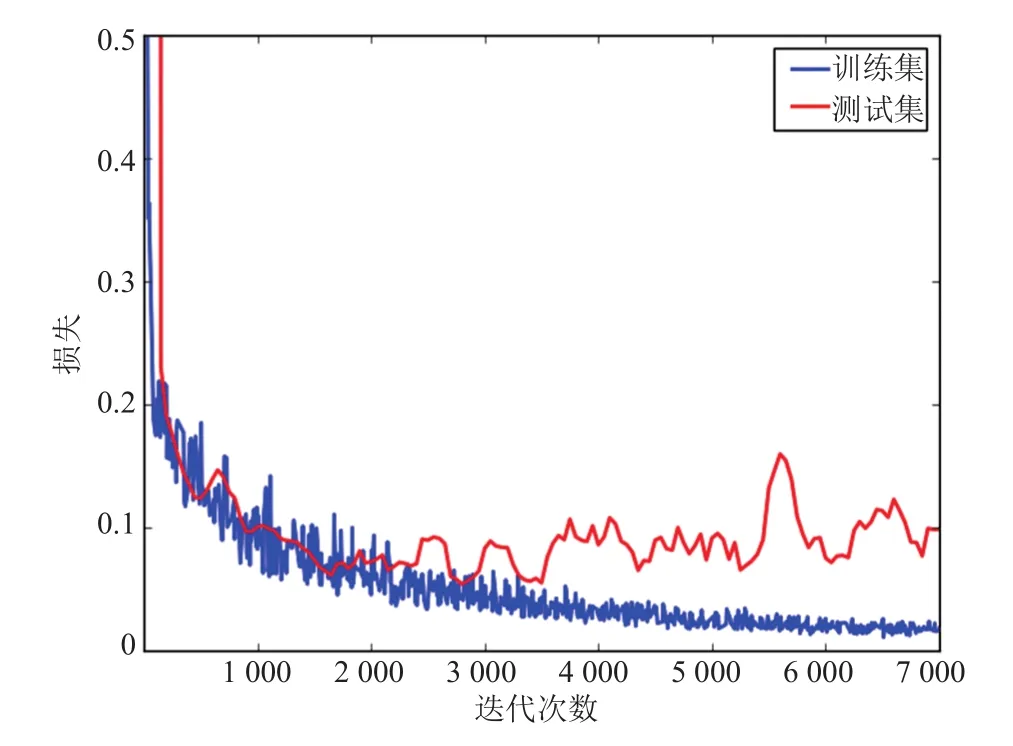
图4 损失曲线Fig. 4 Loss curve
由于 FCN-VGG 卷积神经网络得到的是一副带有语义信息的图像,即轮廓图,需要将图像中的语义信息融合到线段中。如图 5 所示,对于线段Li,首先从起点开始到终点结束均匀地选取m个采样点,分别为p1,p2, …,pm;然后,统计落在轮廓边缘区域内的点的数量n。最后,若n/m大于阈值r,则线段Li为轮廓边线段,否则为纹理线段。
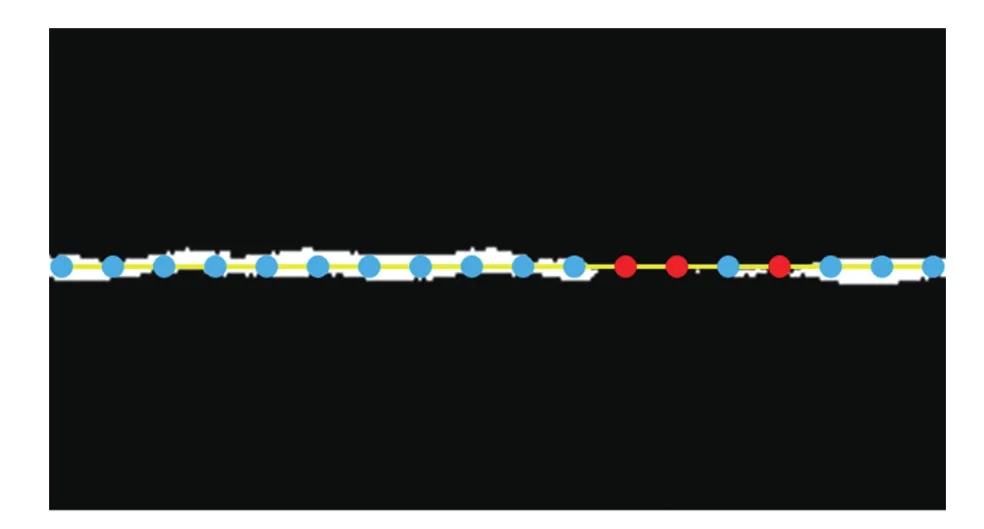
图5 从图像中获取线段语义Fig. 5 Get segment semantics from the image
4 线段聚类及合并
为了保证线段的连续性和完整性,需要对一些线段进行连接、合并。本文采用聚类的方法来决定哪些线段应当合并到一起。对于聚类问题,两个非常关键的因素需要考虑,一是距离的定义,二是聚类算法的选择。如图 6 所示,通过观察发现影响线段是否应该合并的因素有 3 个:(1)线段之间夹角的大小;(2)线段之间垂直间距的大小;(3)线段之间平行间距的大小。对于线段之间的距离定义,本文参考了 Lee 等[20]提出的轨迹聚类算法中使用的轨迹距离,并加以修改使之满足线段聚类的要求。图 7 为本文线段之间距离定义的示意图。本文定义的线段之间的距离包含 3 个部分:角度距离dθ、平行距离dp和垂直距离dv。

图6 影响线段合并的因素Fig. 6 Factors affecting line segment consolidation
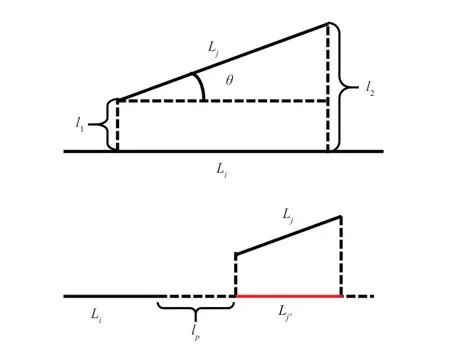
图7 线段距离定义示意图Fig. 7 Segment distance def i nition
角度距离的定义如公式(1)所示。其中,θ是线段Li和Lj之间的夹角;表示线段Lj的长度。本文中,线段的聚类不考虑线段方向的影响,即线段eisi和线段siei表示同一条线段。

垂直距离的定义如公式(2)所示。假设Li的长度比Lj长,则l1和l2为线段Lj的两个端点到Li所在直线的距离。线段Li和Lj之间的垂直距离定义为l1和l2的 2 阶 Lehmer 平均数。

平行距离的定义如公式(3)所示。假设Li的长度比Lj长,将Lj向Li所在的直线方向上投影得到线段线段Li和Lj之间的平行距离为Li与之间的最小距离lp。当Li与相互交错时,Li与Lj之间的平行距离为 0。

最终两条线段之间的距离为以上 3 部分的加权和。
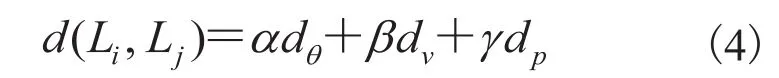
其中,α、β、γ为各项距离的权重,且满足以下两个条件。
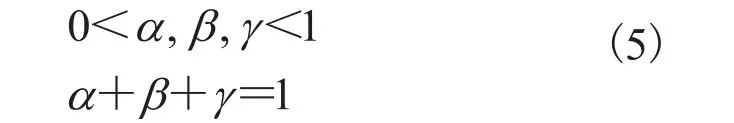
定义好线段之间的距离后需要确定聚类算法,本文采用基于密度的有噪声应用空间聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)[21]算法对线段进行聚类。DBSCAN 算法需要两个参数,分别是计算局部密度的半径r和局部密度阈值n。这两个参数很容易根据具体应用情况进行调节。此外,DBSCAN 算法具有抗噪声的功能。因此,DBSCAN 算法非常适合线段的聚类。
聚类完成后需要对同一类的线段进行合并。虽然同一类的线段可能来自不同分辨率的图像,但从高分辨率图像上提取的线段精度更高,故合并时选择该类中从最高分辨率的图像中提取的线段进行合并。对于给定的需要合并的线段集合首先需要计算这些线段的几何中心o和平均方向v。其中,计算平均方向时需要保证集合中的线段方向一致,即对任意的两条线段Li和Lj,其方向向量的内积要为非负值。在具体计算过程中,可以将所有的线段和第一条线段L1的方向保持一致即可。然后,计算合并后的线段。具体计算过程请参考算法 1。

如图 8 所示,几何中心o和方向v可以确定合并后的线段所在的直线l,将集合C中每一条线段的端点向直线l上投影,则这些投影点分布在点o的两侧。记在点o两侧距离o点最远的两个投影点为s和e,即为合并后的线段的起点和终点。图 8 中,黄色线段L为合并后的线段。
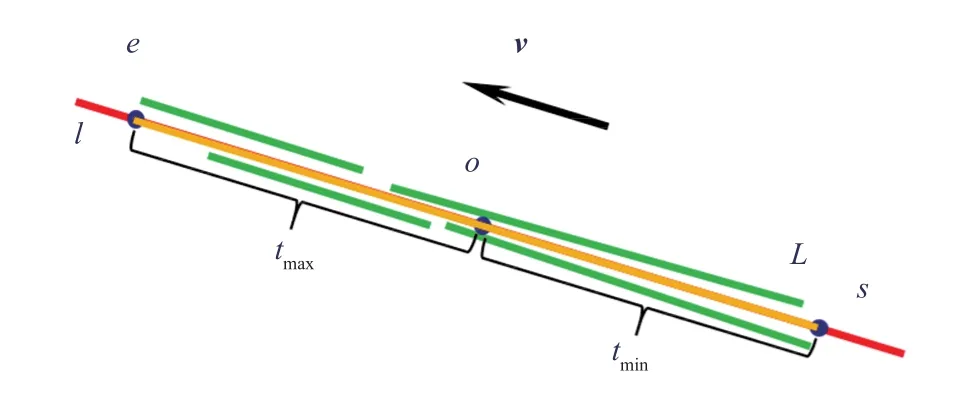
图8 线段合并示意图Fig. 8 Segment consolidation
5 实验结果
与其他传统的线段提取方法相比,本文提出的线段提取方法主要特点为:在多分辨率的图像下进行线段提取,并进行语义分析以区分边缘轮廓线段和纹理线段,在此基础上对线段进行了聚类合并,提高了线段的完整性和连续性。因此,本文将从两个方面分析实验结果:(1)线段的完整性和连续性;(2)线段语义分析的准确性。
5.1 线段的完整性和连续性
为了评估提取线段的完整性和连续性,本文选取了几个不同的实例进行测试,并与相关工作进行比较。由于参与比较的 CannyLine[14]和LSD[11]线段提取方法没有对线段进行语义分析,所以在进行线段完整性和连续性评估时不考虑线段的语义区别。不同方法提取线段的结果如图 9所示。其中,9(a)为输入图片,9(b)~9(d)分别为 CannyLine、LSD 和本文方法提取的线段。通过观察发现,本文方法提取的线段完整性和连续性最好,断裂线段的数量最少,视觉效果最好。
为了定量评估线段的完整性和连续性,本文选取了 10 张真实场景的图片进行测试。其中,5张为室内场景,5 张为室外场景。并对这 10 个实例中不同方法提取到的线段平均长度进行统计,结果如表 1 所示。从表 1 的数据可以看到,在10 个实例中,本文方法提取的线段平均长度最长。图 10 为两个具有代表性的实例的线段提取结果。
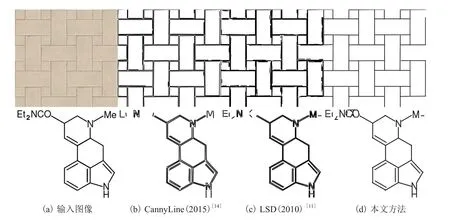
图9 不同方法提取线段的结果Fig. 9 Results of different line segment extraction method
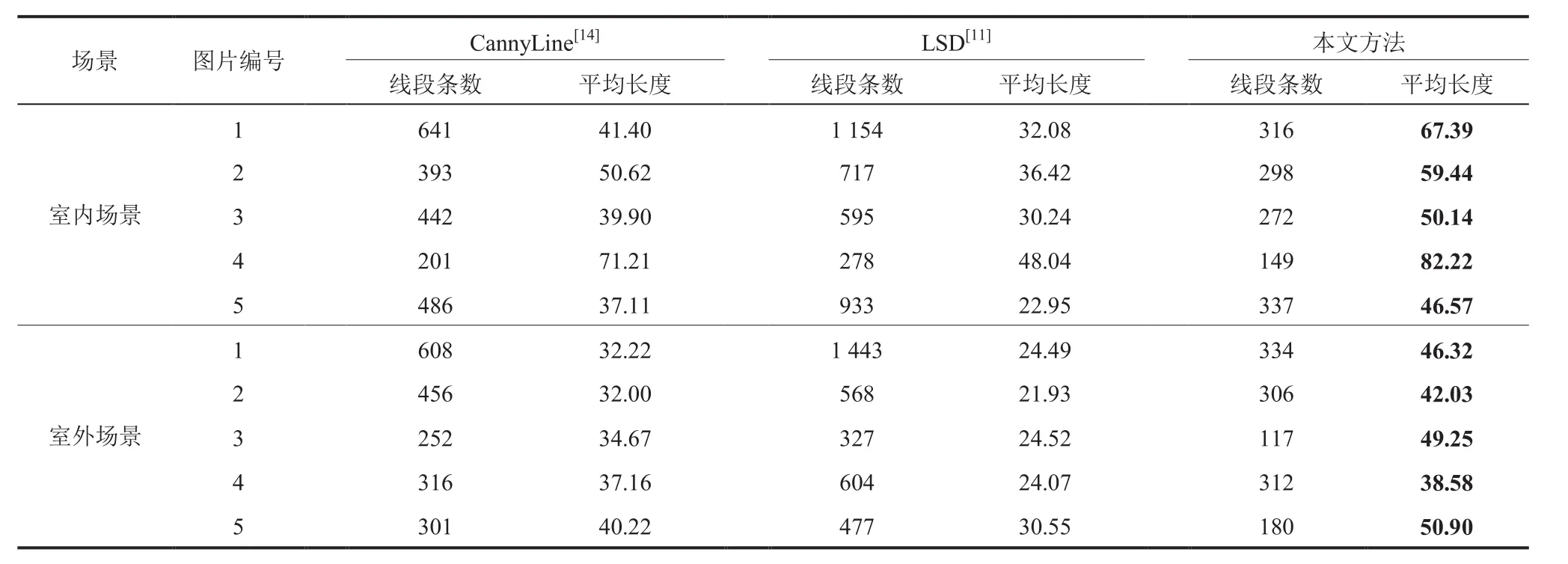
表1 不同方法线段提取结果的完整性比较Table 1 Integrity comparison of different methods
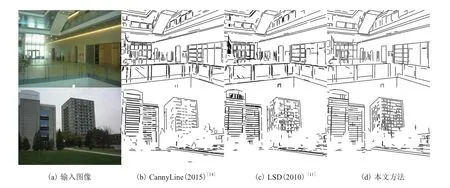
图10 室内和室外场景中不同线段提取方法的结果Fig. 10 Result of different line segment extraction methods in indoor and outdoor scene
本文提出的方法可以非常灵活地满足不同应用的需求。同时,还可以通过改变线段聚类合并的参数来调整最终线段提取的结果。如图 11 所示,改变聚类半径的参数可以调整最终线段提取的边缘效果。
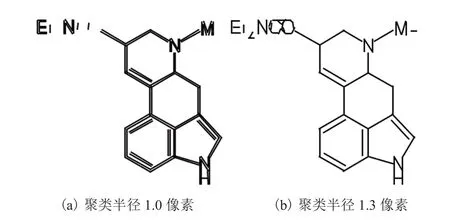
图11 不同参数对结果的影响Fig. 11 The effect of different parameters
5.2 语义分析的正确率
由本文第 3 部分可知,线段的语义来源于图像上像素的语义,而获取图像上像素的语义是一个二类语义分割问题。因此,采用评估图像语义分割常用的像素精度、平均精度和平均交并比 3个指标对本文语义分析的正确率进行分析,结果见表 2。设nij表示本身是i类像素且被预测为j类像素的像素数目,ncl为像素总类别数(本文中,ncl=2),ti表示i类像素的总数目,即那么以上 3 个指标的定义如下。
由表 2 可以看出,本文所采用的图像语义分割方法具有非常高的精度,其中像素精度高达97.82%,能够满足线段语义分析的要求。

表2 图像语义分割精度Table 2 Image semantic segmentation accuracy
图 12 为测试集中 3 个线段语义分析的实例。其中,每一行表示一个实例,从左到右分别是输入的图像实例、人工标注的真实结果、深度神经网络预测的结果和将语义信息融合到线段上的结果。图中红色线段表示轮廓线段,黑色线段表示纹理线段。
为了测试神经网络的泛化能力,本文收集了一些不同风格的场景图像(这些图像既不属于训练集也不属于测试集),并使用上述神经网络对其进行预测,结果如图 13 所示。从图 13 可以看出,与训练集中风格越相近的场景预测结果越好。这表明该神经网络具有一定的泛化能力,但泛化能力有限。
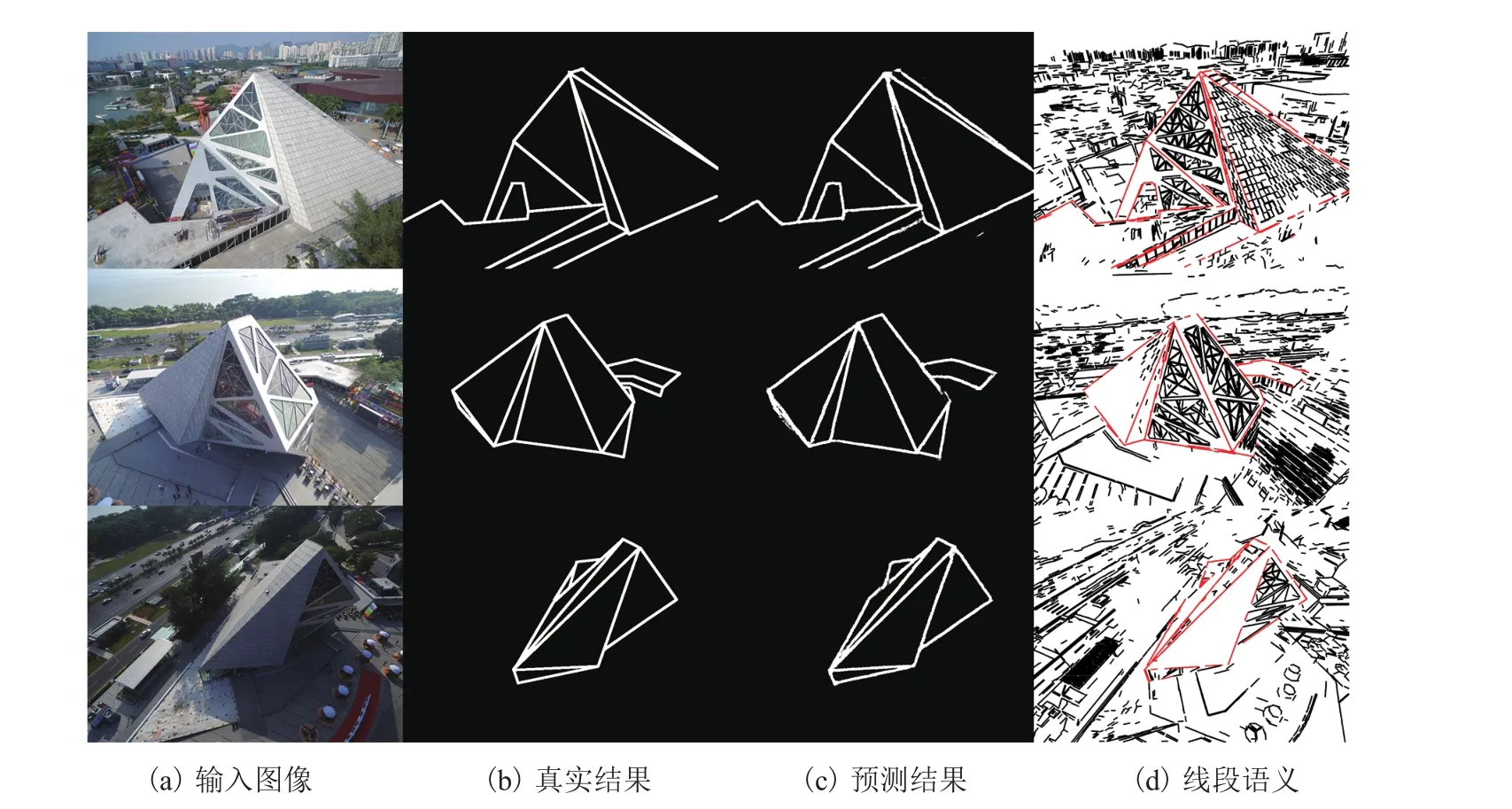
图12 线段语义预测结果Fig. 12 Result of line segment semantic prediction
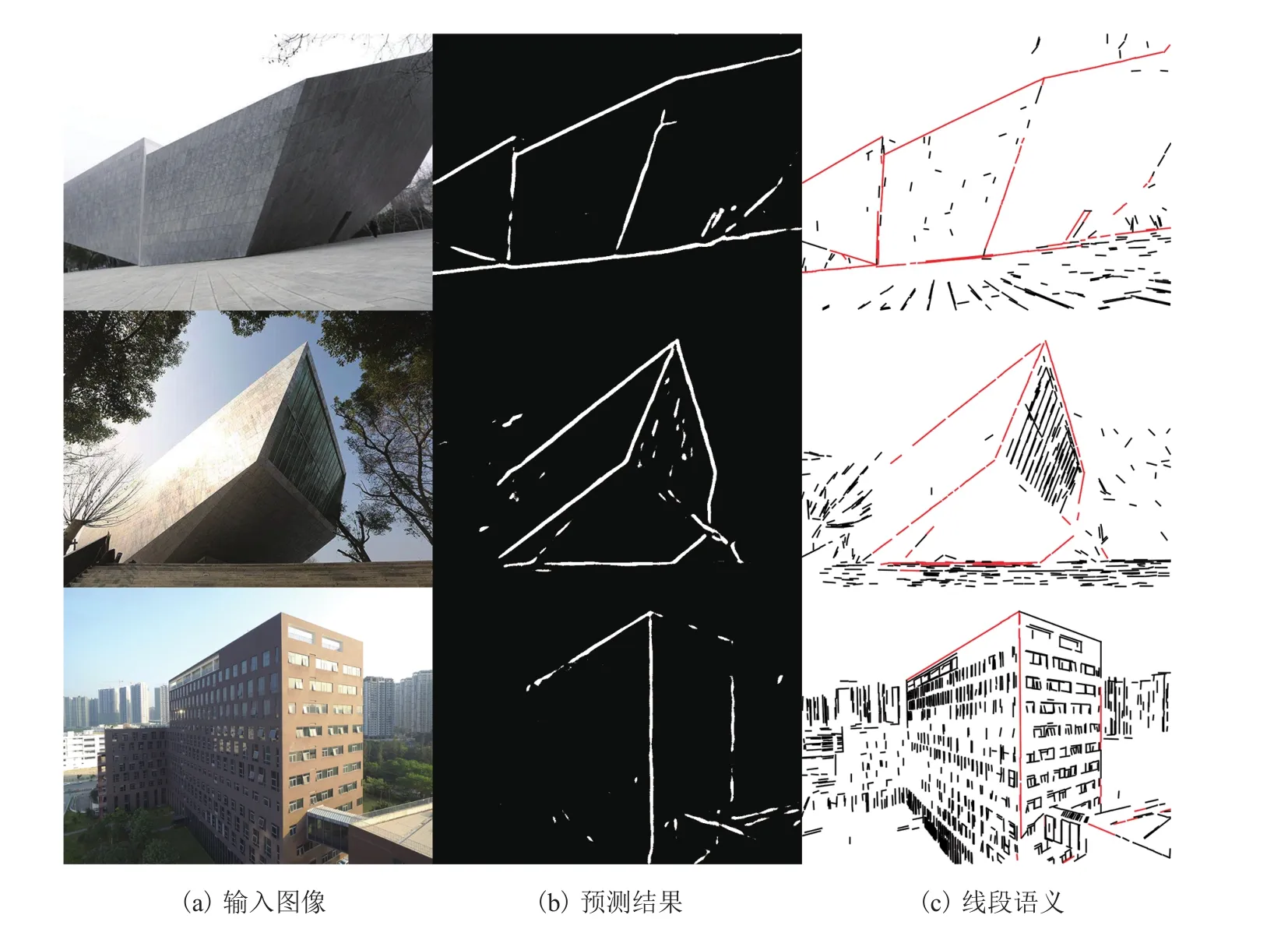
图13 不同风格场景预测结果Fig. 13 Prediction results of different style scenes
6 结 论
本文提出了一种基于语义分析的线段提取方法,并使用深度神经网络对线段进行语义分析。与 CannyLine[14]和 LSD[11]方法相比,本文方法不仅在线段完整性和连续上有明显提高,而且还能够区分轮廓线段和纹理线段,对基于线段的立体匹配和三维重建等应用具有较高的价值。但本文方法仍存在一定的局限性:首先,由于使用LSD 方法对特定分辨率的图像进行线段提取,所以最终线段提取的效果还是会受到 LSD 方法的局限影响;其次,用于训练深度神经网络的数据集较小,还存在泛化能力不够的问题。在未来,可以深入运用多分辨率思想,脱离 LSD 方法的束缚,进一步提高线段的完整性和连续性。此外,还可以增加训练数据集,增强神经网络的泛化能力,提高线段语义分析的准确性,并将线段提取工作放入卷积神经网络,实现端对端的线段检测算法。
猜你喜欢
云南化工(2021年9期)2021-12-21 07:44:00
小学生学习指导(高年级)(2021年5期)2021-05-18 07:34:42
数学物理学报(2019年3期)2019-07-23 01:15:40
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
小学生学习指导(低年级)(2019年4期)2019-04-22 03:28:40
小学生学习指导(低年级)(2018年12期)2018-12-29 11:13:38
家庭影院技术(2018年9期)2018-11-02 05:31:32
中国音乐教育(2017年4期)2017-05-20 09:21:06
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
