
基于深度学习的普适云服务迁移方法研究
2018-09-21 11:39朱连章张卫山谭守超孙浩云
太原理工大学学报 2018年5期
朱连章,李 博,张卫山,刘 昕,谭守超,孙浩云
(中国石油大学(华东) 计算机与通信工程学院,山东 青岛 266580)
普适云计算环境下,计算、服务和数据的调度与迁移是保证资源合理分配和服务性能的一个重要方式,是普适云计算可扩展性、灵活性、普适性和良好性能的基础和保障,是增强移动设备和移动系统能力的必然途径[1]。在商业领域,各大云服务提供商都有相应的解决方案,如国内阿里云的伏羲等。在学术领域,服务与数据迁移也是普适云计算的研究热点,但现有相关研究多集中在迁移架构与迁移决策方面。目前普适云架构可按照节点组成及距离分为四类,CLONE CLOUD[1]与VIRTUALIZED SCREEN[2]中使用的远端固定云架构,以CLOUDLET[3]为代表的近端固定云架构,近端移动云架构以及SAMI[4]使用的组成结构复杂的混合云架构。在迁移决策方面,遗传算法、马尔科夫决策链、线性编程等方法被提出作为决策算法。
对于普适云迁移的研究现状,文献[5]对现有迁移架构与迁移决策方面的相关工作进行了分析讨论,并重点关注了迁移决策的因素及流程。根据该综述的研究探讨,普适云迁移是一个包含了多方面内容的工作,从迁移的基础设施支持到迁移决策的制定,每一方面都是一个较复杂的问题。此外准确高效的迁移决策离不开深入的普适云环境感知,且研究表明基于预测的决策能够获取更有前瞻性的决策方案。迁移执行也需要适合的技术进行支撑,尽可能透明化,减少对环境以及用户体验的影响。在迁移相关的深入的上下文感知以及完整的迁移体系结构方面,目前仍缺少探索性的工作,由此也不可避免地引起普适云迁移的大规模部署与测试以及标准化的迁移流程上的缺失。
文献[6]提出了一个基于OSGi的弹性普适云基础设施OSGi-PC[6].OSGi作为Java模块化标准,具有模块化、动态部署、分布式通信的特征,对于普适云环境下的迁移问题具有显然的适应性。因此OSGi-PC基于OSGi技术搭建普适云基础设施,充分利用OSGi技术的模块化以及动态部署,结合D-OSGi与R-OSGi两种分布式OSGi部署方案,实现移动节点与云节点上的统一部署与两者之间无缝的服务通信。实验分析充分验证了该基础设施平台在PC节点与移动节点上部署的一致性,在不同节点之间执行服务迁移的可行性,并且迁移实验的分析说明了该基础设施在执行服务迁移上能够保持较低的性能消耗。
本文在OSGi-PC的基础上继续对普适云环境下服务迁移进行研究,研究重点在于普适云环境的上下文感知以及云节点资源可用性的预测,并提出基于历史数据与资源预测的迁移决策算法,以此搭建完整的普适云服务迁移体系结构。
1 上下文感知与资源预测
上下文感知是对环境信息进行获取,并监测其变化。随着物联网与计算模式的不断发展,上下文感知已应用在各个领域。对于普适云计算来说,上下文感知是实现计算环境与应用的智能管理,保证系统的正常高效运行,确保服务的质量(QoS)的基础,是普适云环境进行智能化配置,制定服务与应用迁移决策的前提。但要更好地发挥上下文信息的价值,获取更加有效的迁移决策,还需要对上下文信息进行分析处理,以此预测出未来时刻的系统状态,从而进行基于预测的决策,以获取有前瞻性的迁移方案,带来更好的系统性能[7]。
普适云计算涉及到多种资源类型,如内存,CPU,网络带宽等常用的性能指标。上下文感知获取到的资源数据具有时间特性,一段时间内周期性获取到的资源数据会形成一个时间序列,数据呈现出一定规律的变化。目前已有移动平均、回归分析以及神经网络等方法可用于对资源情况进行预测。
YOO W et al提出了一种单变量时间序列模型对高带宽网络的网络带宽使用量进行预测[8]。单变量时间序列模型结合了时间序列的季节性分解方法(STL)与自回归集成移动平均方法(ARIMA).STL将数据转换成季节性的、趋势性的时间序列,而后使用ARIMA进行数据的自回归预测。
CHEN et al提出了一种向量自回归模型来预测云环境下的虚拟机的资源使用情况[9]。该模型将数据样本建模为如下的数组:x[j][i]={x1ij,x2ij,x3ij,x4ij},i=1…n,j=0…m.其中,i代表集群中被检测的节点,j代表时间序列,x1ij代表CPU使用率,x2ij代表内存使用率,x3ij代表io使用率,x4ij代表带宽使用率。然后根据各指标之间的相关性,通过对样本数据进行向量化处理,并为其添加权重信息,将单一变量自回归模型转化为向量自回归模型,从而对云环境的资源使用情况进行短期或者长期的预测。
MICHAEL BORKOWSKI et al使用机器学习模型对应用任务的云资源的使用情况进行了预测[10],其机器学习预测方法的系统模型如下:待预测的任务类型T;T任务的输入数据向量〈a,b,c,…,z〉;一个待预测资源的列表R1,R2,…,Rn;代表着CPU事件/核数、运行时间、内存使用量、存储空间、和其他任务T所需的资源。预测的结果是一个向量〈Rp1,Rp2,…,Rpn〉,其中Rpn代表着T任务对资源Rn的预测使用量。在众多的机器学习算法中,选择了最适应需求的人工神经网络ANN模型,记录实际的资源数据作为训练数据。随着训练数据的增加,ANN模型的适应性不断提高,预测结果也越来越精确。
ZHANG et al的相关研究提出了使用深度置信网络DBN对云计算中的资源需求进行预测[11]。为了提高预测的准确性,作者按照每分钟的时间间隔提取资源请求数据,然后通过微分变换来减少数据的线性相关,从而使其适应神经网络。此后通过实验选取合适的DBN参数,在数据样本的基础上执行操作,获取资源请求数据的预测值,可进行长期预测与短期预测。
大部分预测方法的研究表明,基于神经网络的预测方法比基于回归的预测方法更加优越。首先人工神经网络的适应性强,基于回归的预测方法需要以历史数据中的变量关系正常为假设前提,但是这对于大部分收集到的数据来说是不现实的,而且回归方法对于数据的缺失的处理也比较薄弱;而人工神经网络能够较好地处理数据丢失的情况,同时能够适应任何关系的数据类型,也就是说不受数据类型的限制。其次,人工神经网络的预测结果更加精确,而且相对于回归方法来说能够更好地处理变化。但是相对回归方法,基于人工神经网络的预测方法需要更多的数据,结构也更加复杂。
在神经网络用于时间序列预测方面,由于时间序列的数据具有相关性,并且预测需要对数据的长期依赖进行分析,所以递归神经网络LSTM对此具有结构上的优势。目前已有相关研究使用LSTM对时间序列数据进行预测。文献[12]使用LSTM神经网络对美股股指的价格趋势进行了预测,其研究指出了LSTM对RNN在神经网络反馈误差上的改进,也指出了其可能出现局部最优解的可能性。作者还提出了基于数学理论对LSTM学习速率进行改进的方法,以降低局部最优的可能,提高模型的收敛准确率。实现结果表明了LSTM对时间序列预测的可能性。SHI et al[13]将降水临近预报问题定义为一个时空序列预报问题,提出了卷积LSTM(ConvLSTM)来构建端到端的降水临近预报训练模型,该模型对全连接LSTM(FC-LSTM)进行扩展,使其卷积输入状态与状态转换具有卷积结构。其实验结果表明ConvLSTM能够更好地捕捉到时空相关性与一致性,表现优于FC-LSTM.FELIX et al对LSTM对持续输入数据的处理进行了研究[14],指出由于连续数据没有明确标记的序列结束点,所以LSTM对于连续输入数据无法进行其内部网络结构的状态重置,因此状态的持续增长可能引起网络崩溃。对此他们提出了一种新型自适应的forget gate促使LSTM网络单元能够在合适的时间重置自己的状态,释放内部资源,以满足对连续数据输入处理的要求。
2 基于深度学习的普适云服务迁移方法
2.1 OSGi普适云服务迁移体系结构
前期工作基于OSGi的弹性普适云基础设施研究[7]已经搭建起了OSGi普适云服务迁移方法的基本环境,结合使用D-OSGi与R-OSGi分布式通信技术实现了普适云环境的通信,并借助OSGi的动态部署可进行服务的动态迁移。为了支持对迁移决策的研究,普适云服务迁移体系结构在设计上需要满足以下条件:一是适应普时云环境结构的异构性,即能够在云计算节点中运行,也能够运行在资源受限的移动节点,并实现移动节点与云节点之间服务的无缝通信与统一管理;二是要提供框架的自我感知能力,要求中心决策节点负责对每个框架的系统与服务资源信息进行感知是不合理且难以实现的,所以OSGi框架应该具有自我资源监测的能力;三是普适云设施要具有动态部署的能力,确保服务的动态添加与删除,以尽可能降低服务迁移对系统运行的影响。由此更改OSGi-PC中deployer组件,为其添加组件动态查找与迁移操作功能,并对OSGi-PC基础设施中各计算节点添加资源监控组件monitor.OSGi普适云服务迁移体系结构需要对服务迁移进行支持,所以为OSGi-PC搭建中心决策节点,负责对普适云环境进行全面感知,节点框架的资源信息进行预测,并基于监测及预测信息进行迁移决策。基于深度学习的普适云迁移体系结构如图1所示。
完整的普适云服务迁移体系结构中节点分为两类,普通计算节点(OSGi-FW)与中心决策节点(OSGi-CD),如图2所示。普通计算节点可以是PC节点,也可能是移动设备(包括安卓手机,安卓平板等),有三个重要的功能性组件:framework,deployer,monitor.其中framework组件的作用是唯一标识一个OSGi-FW框架,同时负责确保该框架中的deployer与monitor处于工作状态;deployer负责其OSGi-FW框架中服务的迁移与运行状态的控制,在中央迁移决策节点确定迁移方案后,相对应的deployer进行选定服务的停止迁出与迁入启动;monitor组件负责对框架可用资源与服务的资源使用情况进行监测,主要包含CPU与内存参数。中心决策节点作为特殊框架节点,在此基础上还有上下文分析组件contextProfiler、预测组件resourcePredictor与决策节点decisionMaker,决策节点基于OSGi分布式通信技术,通过contextProfiler组件定期发送监测任务给各个计算节点,获取各个计算节点的资源信息,而后通过预测组件进行节点可用资源的预测,对监测数据与预测结果进行分析,采用一定的决策算法确定是否进行服务的迁移,并获取迁移方案。决策节点部署于PC节点上,掌控整个系统的运行。
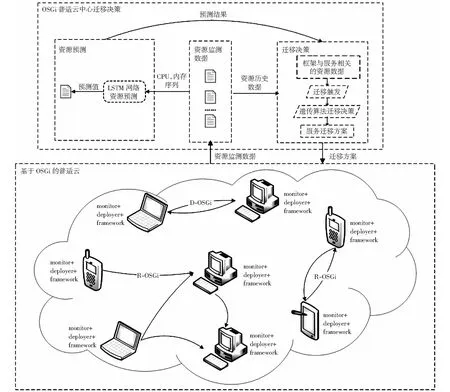
图1 基于深度学习的普适云服务迁移系统体系结构Fig.1 Overview of deep learning based pervasive cloud service migration architecture

图2 基于OSGi的普适云迁移基础设施Fig.2 OSGi based pervasive cloud migration infrastructure
2.2 OSGi普适云资源监测
OSGi普适云系统的感知包含三个层次的内容。第一是系统层次的感知,主要是获取系统中OSGi-FW框架的分布及运行情况,包含系统中共运行有多少个OSGi-FW框架,各个框架的功能组件的运行情况。第二个层次是对每个框架中服务的状况进行感知,主要是每个框架中运行了哪些服务。这两个层次的信息通过D-OSGi与R-OSGi分布式通信技术,借助framework与deployer组件即可获取。第三个层次是资源层次的监控,选取常用且性能相关的内存与CPU指标,监控参数包括节点框架的可用内存量以及CPU的可用率,节点框架内服务的内存与CPU资源使用情况。
对于OSGi-FW的资源可用情况的监控,由于OSGi组件服务运行于JVM中,因此节点框架内存可用量wmemory采用JVM可用内存来衡量,框架的CPU可用率wcpu(1减去CPU占用率)由系统CPU可用率表示。OSGi环境下服务以bundle为单位,所以传统的Java对象或者是线程层次的资源使用量监控并不能直接适用于OSGi普适云环境。为了获取bundle的CPU使用率dcpu,对开源项目jip-osgi进行相应改造,使其适应OSGi普适云环境。需要注意的一点是由于Android虚拟机的异构性,通过现有技术方法或工具对Android中的OSGi bundle的资源使用情况进行监控有很大的技术难度;此外考虑到整个OSGi普适云系统中服务的一致性,其他节点中的服务资源消耗情况相对地可基本衡量Android虚拟机中服务资源消耗的相对情况。基于此两点,在Android中运行的OSGi-FW框架不执行bundle相关的资源监控操作。
在对OSGi-FW节点的资源数据的获取方式上,采取了中心节点拉的方式,中心决策节点的contextProfiler组件周期性地向OSGi-FW框架中的监控组件发送监控通知,监控组件执行CPU、内存等分析操作来获取框架资源可用量与服务资源使用量并返回,中心决策节点将获取到的资源信息进行分析组织,并作为资源使用量历史进行保存。多次的资源数据构成一个时间序列,以便后续的预测与决策。
在资源数据的表示上,采用如下的结构:
1) 普适云系统信息sysInfo={ipi∶fwInfoi}.其中i∈(1,n),n为系统中框架的数量,ipi用于标识框架,fwInfoi表示框架的信息,如(2)所示。
2) 框架信息fwInfo={ip∶ipAddr,memory∶{ti∶mi},cpu∶{ti∶cI},bdsInfo∶{bdj∶bdInfoj}}.其中i表示时间序列索引,bdsInfo表示框架中的bundles信息,如(3)所示。
3) 框架中bundle的信息bdInfo={cpuInfo∶{ti∶ci},memoryInfo∶{ti∶mi}}cpuInfo与memoryInfo都为一个时间序列,表示了不同时间bundle的CPU与内存消耗情况。
中心决策节点获取的各框架的内存与CPU资源可用情况如图3所示。其中,图3(a)表示了框架的可用内存情况,图3(b)表示了框架的CPU可用率。

图3 OSGi计算节点框架的内存和CPU可用情况Fig.3 Memory availability and CPU availability of OSGi computing frameworks
由图可知,jvm虚拟机的可用内存呈现一定范围内的锯齿状周期性变化,这是符合java内存回收机制隐形所产生的效果的。图3(a)中最下面的折线代表了Android4.4系统的移动设备节点的内存可用量情况,显示效果波动较小;这是由于Dalvik虚拟机本身可用内存在一定量级上小于Ubuntu16.04节点上的JVM,所以统一图形显示效果受到影响。图3(b)可发现一定状况下CPU在某一范围内波动,且可用率持续保持较高水平;这是由于目前实验环境的CPU处理能力比较强大。所以这也是在后期决策过程中如果出现框架CPU与内存资源都较为紧张的情况,以内存为首要因素选取目标节点的原因。
2.3 OSGi普适云资源预测
上述数据采集过程获取到的各节点框架的资源可用量数据是有时间特性的,周期性获取的数据形成了一个时间序列,且各节点框架的内存与CPU可用量随时间呈现一定规律性的变化。LSTM长短期记忆模型在时间序列的预测处理上具有良好的可用性与适应性,因此采用LSTM对节点框架的资源可用量进行预测。在LSTM的具体实现上,使用纯python编写的深度学习框架keras,这是高度模块化的神经网络框架,使用广泛且较为便捷,并选择了TensorFlow作为后端。
在模型的构建上,根据LSTM网络用语时间序列预测方面的相关研究经验,采用序贯模型,用5层网络来搭建起LSTM资源预测网络模型,包括两层LSTM、两层Dropout、一层全连接层,如图4所示。
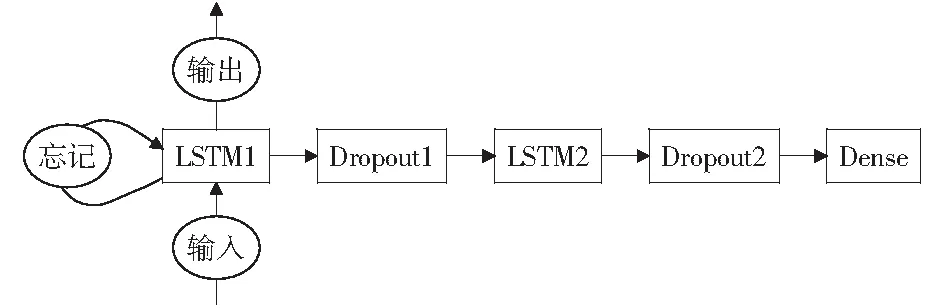
图4 5层序贯LSTM预测网络模型Fig.4 Sequential LSTM prediction network model with five layers
基于LSTM进行资源预测的基本过程如下所述。首先使用测试数据,选取不同的模型参数对其进行训练。CPU资源与内存资源可用量时间序列具有不同的特征,需要分别分析不同参数配置下模型的预测能力,因此对CPU预测与内存预测模型分别训练。不同模型参数下的CPU预测模型与内存预测模型的训练情况如表1与表2所示。

表1 不同参数下memory LSTM训练及验证误差Table 1 Train and validation loss with different parameters of memory LSTM

表2 不同参数下CPU LSTM训练及验证误差Table 2 Train and validation loss with different parameters of CPU LSTM
在表1与表2中,Sequence表示训练所使用的时间序列长度;LSTM1与LSTM2与Dense Layer表示神经网络层的输入数据;Train Loss与Validation Loss表示模型的训练误差与验证误差。不难理解训练误差与验证误差越小,证明模型的预测能力越强。因此对于内存与CPU可用量的预测,选取第二行所示的模型参数进行LSTM网络模型配置。
好的模型在训练过程中训练误差会逐渐减小,表示模型对数据具有收敛能力,验证误差一定程度上衡量了模型的泛化能力,表示模型的预测结果与测试数据更加接近。以CPU预测的LSTM网络的训练过程为例,分析训练过程中训练误差的变化情况,如图5所示。不难发现随着训练的不断进行,训练误差呈现明显下降趋势。
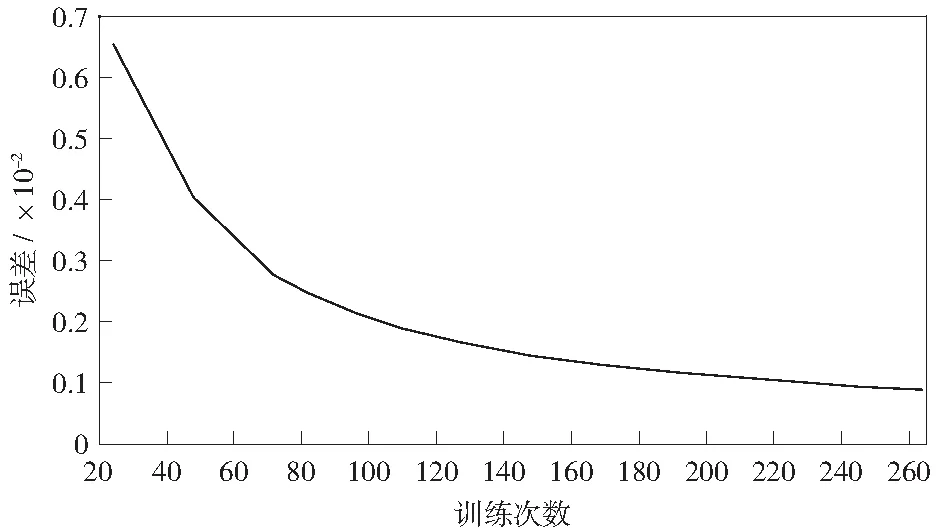
图5 LSTM预测模型训练误差的变化趋势Fig.5 Variation trend of training error of LSTM prediction model
选定模型并使用训练数据对其进行训练后,将该模型进行保存,在决策过程中直接读入训练后的LSTM神经网络模型,将监测到的历史数据进行数据预处理,处理为预测可用的数据格式,将其输入该模型,执行模型的预测方法,获取预测结果。
2.4 OSGi普适云服务迁移决策
在上下文感知与资源数据预测的基础上,以降低设备的资源压力,平衡系统的资源负载为目标,设计算法获取服务组件的迁移方案,并基于OSGi分布式通信与动态部署特性来实现OSGi普适云服务的迁移部署。迁移决策与部署的流程如图6所示。下面详细介绍迁移决策算法,并说明决策方案的执行与部署。

图6 OSGi普适云服务迁移决策算法Fig.6 Service migration decision algorithm for OSGi-based pervasive cloud
迁移算法的过程如下:
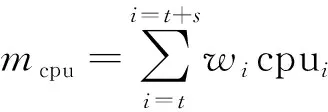
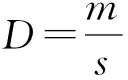
(1)
其中,m表示内存或者是CPU可用量的加权均值,s表示对应的标准差。所以D值综合衡量了框架的CPU或内存资源在大小与稳定性方面的情况。
对listat与listas分别进行遍历,计算其中各节点框架的D值,按照D值由大到小排序,得到考虑方差参数后的listbt与listbs,如图7中的listb所示。
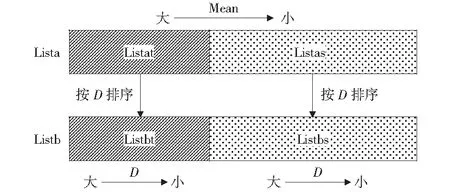
图7 OSGi普适云资源排序服务队列Fig.7 Resource sorted service list in OSGi based pervasive cloud
通过上述操作实现了将系统中的节点框架按照CPU与内存的指标进行排序后的框架列表。查看内存相关的listbt中D值最大的框架,若其的mcpu或mmemory超过设定的资源阈值cthreshold或mthreshold,则该框架作为待迁移框架wmigrated进行迁移决策处理,否则系统不需要进行迁移操作。
2) 第一步确定了是否进行迁移决策以及哪个节点框架优先进行组件服务迁移。这一步将根据wmigrated的资源情况选择合适的迁移目标框架wtarget.具体分三种情况选择迁移目标框架wtarget:
① 若wmigrated属于内存资源紧张类型,则选取内存空闲框架列表中listbts中D值最小(表示内存资源最优)的框架作为迁移目标框架wtarget.
② 若wmigrated属于CPU资源紧张类型,则选取CPU空闲框架列表listbs中的最优节点作为框架.
③ 若CPU与内存资源都相对紧张,则由以上内容分析可知,采用内存优先的原则,依序遍历内存空闲列表中的框架,若该框架也位于CPU空闲列表中,则选择该框架作为wtarget.对于以上3种情况,若没有找到可取的目标框架,则无法立即执行迁移,只能等待下次决策,迁移决策结束。
3) 若从第一步与第二步获取到wmigrated与wtarget,则对wmigrated中的OSGi组件服务一段时间内的CPU和内存资源消耗情况进行分析评估,类似分析不同节点框架资源消耗,获取CPU资源与内存资源消耗的加权均值,并按照CPU与内存的加权均值分别对bundle进行排序。若wmigrated当前的状态属于CPU资源紧张类型,选取CPU均值最高的那个服务作为待迁移服务dmigrated;若wmigrated属于内存资源紧张型,同理选出内存消耗最高的服务作为dmigrated;若wmigrated为CPU与内存都紧张的情况,则重复如第二步中目标框架选择逻辑,遍历内存消耗列表中的bundle,若其的CPU消耗也较大,则将其作为dmigrated,若不存在内存与CPU消耗都较大的bundle,由于内存因素的偏重性,只能选择内存消耗最大的bundle作为dmigrated.
基于上述三步获取到的迁移方案,在需要迁移的情况下通过服务迁移部署组件执行服务迁移。迁移的过程为:获取wmigrated中的部署组件deployermigrated,与其对应的迁移目标框架wtarget的deployertarget,通过deployermigrated迁出dmigrated到deployertarget,迁出操作对bundle执行stop,uninstall操作,迁入操作执行install,start操作。
3 实验结果与分析
实验所采用硬件实验平台是ThinkPad E460,核心为4核Intel Core i7 6500U,该硬件平台上搭建有4个ubuntu16.04虚拟机,一个Android4.4虚拟机,配置如表3所示。

表3 系统环境及配置参数Table 3 Deployment and configuration of OSGi-PC service migration system
采用的操作系统为Windows10 64位专业版,设计实现语言主要为java与python。下面对基于深度学习的普适云服务迁移体系结构进行分析评估,主要衡量LSTM资源预测的准确性以及普适云迁移决策的有效性。
对框架节点的资源可用量的预测,采用了具有记忆功能,能够对时间序列数据进行长期与短期预测的LSTM长短期记忆模型。从2.3章节中模型的训练与测试情况可知所选择的LSTM神经网络模型可以对节点框架的CPU与内存可用量进行预测。考察LSTM对节点框架资源可用量的预测能力,参考如图8的实验结果截图。
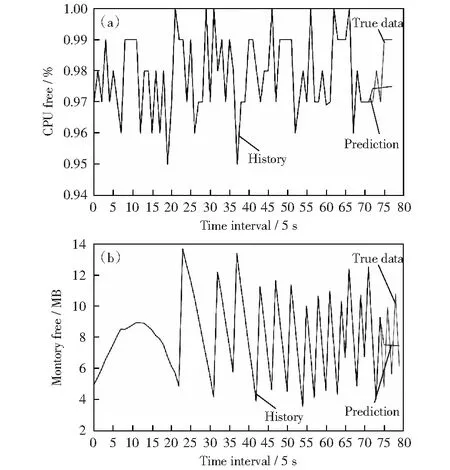
图8 基于LSTM的节点框架资源预测情况Fig.8 Prediction of framework available resource with LSTM
图8(a)为LSTM网络对JVM虚拟机CPU可用率的预测结果图,图8(b)为LSTM内存预测模型对JVM内存可用率的预测结果图。通过观察分析,LSTM模型在短期内(两三个时间点)的预测结果与实际数据较为吻合,但在较长期的趋势变化上并不太能够准确表达实际数据的变化趋势。
对LSTM预测准确性的衡量,采用均方差对所选模型进行衡量,均方差计算公式如式(2)所示。
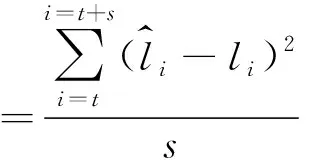
(2)
为了更好地说明LSTM网络模型的预测能力,采用时间序列预测的经典方法ARIMA自回归移动平均算法与其进行对比。对比试验选取ubuntu节点(192.168.182.134)的CPU与内存序列作为测试数据,分别进行5组不同的实验,计算预测值与实际值的均方差,实验结果数据如图9所示。

图9 LSTM与ARIMA在CPU与内存预测上的比较Fig.9 Compare the prediction of the LSTM based method with ARIMA
根据图9,构建的LSTM神经网络模型在CPU的预测上均方差值保持在10-4的数量级上,在内存的预测上保持10-1数量级,而且很明显地低于ARIMA算法的预测均方差,所以可以说LSTM长短期记忆模型对系统资源可用量的预测的准确性上具有良好表现。
在迁移算法的有效性上,以表4所示的迁移实例来说明决策算法的有效性。表4(a)与4(b)分别为节点框架与其服务资源的使用情况,以此讨论迁移算法是否选择出设计期望获取的方案。
表格4(a)中,192.168.182.133节点框架没有

表4(a) 迁移实例中各框架的资源情况Table 4(a) Frameworks resource info under the migration example

表4(b) 迁移实例中各框架中服务的资源情况Table 4(b) Resource info of bundles in each framework under the migration example
CPU信息,因为其为Android节点。表4(b)中,-x与没有数据的数据项表明bundle没有在对应节点框架中运行,x服务的资源消耗情况不可获得。不难发现com.tt.add.impl组件相对其他组件来说消耗的CPU时间较长一些,应该是一个计算类的服务,而com.tt.cals.imp组件的内存使用量明显超出其他组件,因为该组件中维持了一个不断增大的对象列表。
通过分析各框架在一段时间内的运行状态,选取0.95与9.0作为迁移的内存与CPU资源的阈值,对于移动节点的内存资源,设定的迁移阈值为0.10.上述迁移实例中,决策算法选择出的迁移方案为:wmigrated为192.168.182.135的节点(可用内存加权均值小于阈值),选出的dmigrated为com.tt.cals.impl,wtarget为192.168. 182.134的ubuntu节点框架,该迁移方案在阈值约束下,充分考虑当前系统状态,将内存资源紧张的框架中的内存消耗较高的服务迁移到内存资源较为丰富的ubuntu节点上,符合服务迁移的目标。
4 结束语
普适云环境下的服务迁移是普适云计算模式发挥优势的有效方式。本文提出了基于深度学习的普适云服务迁移方法,在前期工作中添加深入的普适云上下文感知,基于深度学习网络LSTM对普适云计算节点的CPU与内存资源可用量进行预测,有效利用上下文信息及预测数据,提出基于预测的普适云服务迁移决策算法,构建了完整的普适云服务迁移体系结构。实验分析验证了基于LSTM的资源预测的准确性以及迁移算法的有效性。下一步将继续探索LSTM网络结构与参数对预测准确性的影响,并进一步深入研究决策算法。
猜你喜欢
能源工程(2022年2期)2022-05-23
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国公路(2017年16期)2017-10-14
燕山大学学报(2015年4期)2015-12-25
电脑爱好者(2015年21期)2015-09-10
