
基于PAD模型的级联分类情感语音识别
2018-09-21 11:39张雪英
太原理工大学学报 2018年5期
张雪英,张 婷,孙 颖,张 卫
(太原理工大学 信息与计算机学院,山西 晋中 030600)
语音作为人类日常交流的主要方式,其中所携带的情感信息越来越受到研究者的重视。情感语音识别在人机交互、模式识别和人工智能等领域具有广泛应用前景,开展情感语音识别研究对于人类社会的进步与发展具有重要意义[1]。在语音情感识别研究中,提高识别率主要有两个研究方向[2]。一是改进情感语音特征的提取方式或者选取方式;在情感语音识别中,常用的声学特征一般包括有声学参数的统计特征、时序特征等[3]。二是改进分类方法或者选取更适合的分类方法;在情感识别方法的研究上,多种模式识别的分类方法均可用于情感识别[4]:如人工神经网络ANN(artificial neural network)[5]、隐马尔科夫模型HMM(hidden markov models)、高斯混合模型GMM(gaussian mixture models)、支持向量机SVM(support vector machines)等。相较于其他模式识别算法,SVM是在结构风险最小化原则上建立起来的,而且可以克服小样本数据和非线性问题,具有良好的情感分类能力。近年来,SVM 被广泛应用于语音情感识别中,是一种有效的语音情感识别分类器[6]。
本文在TYUT2.0情感语音数据库的基础上,提出了声学特征与情感语音PAD数据相结合的级联分类方法。首先根据前期PAD标注实验的数据结果[7],将4类情感中混淆度高的情感按照愉悦度值高低划分为2类,其次在此基础上使用SVM识别网络分别识别高低愉悦度的情感,然后在已区分高低愉悦度的基础上再次使用SVM识别网络,最终实现对4种情感的分类,情感分类识别率较传统仅使用声学特征的分类识别率提高了15.4%.
1 情感语音数据库及三维情感模型
1.1 情感语音数据库
本文采用的太原理工大学数字音视频技术研究中心前期建立的TYUT2.0情感语音数据库。该数据库首先采用截取广播剧的方式,包含“高兴、愤怒、悲伤、惊奇”4种情感类别共237句的摘引型离散情感语音数据库。后期在原有的离散情感语音数据库的基础上,根据PAD三维情感模型,通过心理学实验的方法对情感语音进行标注,建立了维度情感语音数据库。该数据库中每句语音都有对应的PAD值,为后续的识别实验奠定了数据基础[7]。
1.2 PAD三维情感模型
情感可以用连续变化的维度表示,情感维度理论通常将不同的情感映射到一个多维空间中的一个点,该点的空间坐标对应标识某一种情感。其中PAD三维情感模型被广泛认可[8]。该模型由UCLA大学的MEHRABIAN开发,采用语义差异评价方法将情感分为三个维度,它们分别是:反应说话者情感状态的正负特征的愉悦度P(Pleasure-displeasure);反应说话者神经生理的激活程度是主动的还是被动的激活度A(Arousal-nonarousal);反应说话者对情境和他人的控制欲望强弱的优势度D(Dominance-submissiveness)。三维情感模型是对情感空间的理论描述,建立了情感空间中不同情绪范畴的定位和关系,使不同的情感可以映射到三维空间中。根据文献[7]标注实验得出的PAD数据,将悲伤、愤怒、高兴、惊奇4种情感分布在三维情感空间,如图1所示。
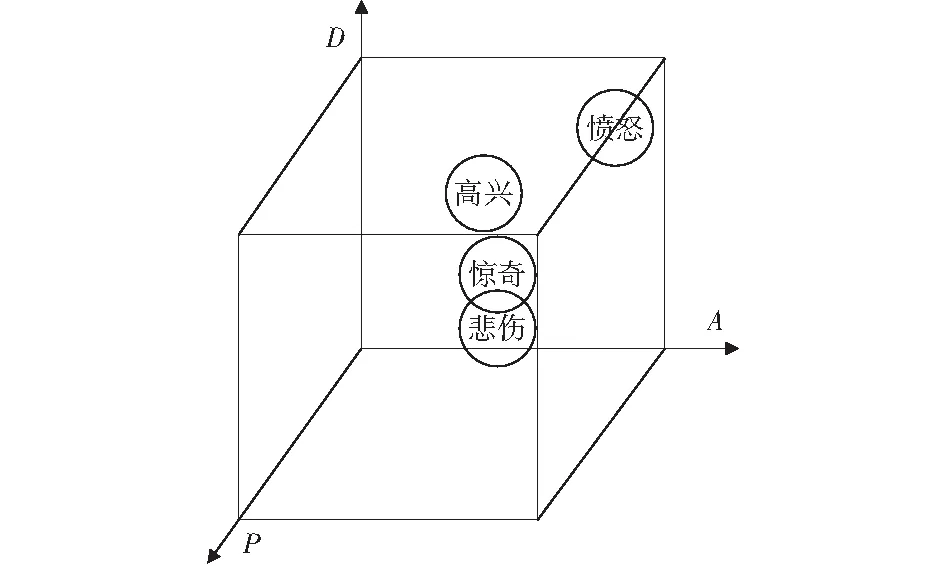
图1 4种情感状态在PAD三维情感空间上的分布Fig.1 Distribution of four emotional states in PAD three-dimensional emotional space
2 情感语音特征
采用何种有效的语音特征参数用于情感识别对于语音情感识别研究至关重要,情感语音特征参数的优劣直接决定情感最终识别结果的好坏。目前用于情感语音识别的声学特征大致可归纳为韵律学特征、基于谱的相关特征和音质特征这3种类型[9]。韵律学特征在情感语音识别领域已经得到研究者的广泛认可[10]。文献[11]研究了Mel频率倒谱系数(mel-frequency cepstrum coefficient,MFCC)和基频、能量、发音持续时间与三维情感空间之间的关系,结果表明MFCC参数与三维情感空间的相关性最高。所以本文主要提取情感语音的韵律特征和MFCC特征用于情感语音识别。
2.1 韵律特征
韵律特征可以分为3个主要方面:音高、强度以及时间特性。通过测量相应提取轮廓的统计值来获得特征。 其中平均值、中值、最小值、最大值和方差是最常用的统计值。本文从语音信号中提取了38维韵律特征。对应的韵律特征及统计参数如表1所示。

表1 韵律特征及统计参数Table 1 Prosodic features and statistical parameters
2.2 MFCC特征
MFCC特征是基于人耳听觉特性提出来的,符合人类的听觉特性,不仅能很好地度量语音频谱的能量包络,同时倒谱运算具有良好的解卷性能,因此MFCC特征广泛地应用于情感语音识别、说话人识别、音频和音乐分类方面。基于以上特性,本文提取了MFCC前12阶的偏度、峰度、均值、方差、中值共60维特征用于识别实验。
3 识别实验
在本节的识别实验中,首先通过3组对比实验,分别比较了仅使用韵律特征的分类识别率、仅使用MFCC特征的分类识别率及将2种特征组合的分类识别率。数据库使用TYUT2.0情感语音数据库,对“悲伤”、“愤怒”、“高兴”、“惊奇”4种情感语音进行分类识别。利用支持向量机SVM[12]识别情感语音采用十折交叉验证(10-fold cross validation)的测试方法。所有语句被平均分为10份,识别实验也相应地进行10次,轮流将其中9份作为训练集,1份作为测试集。取10次实验结果的正确率的平均值作为识别结果。采用交叉验证测试方法能够有效地降低随机因素的影响 ,提高识别结果的可信度。
3.1 韵律特征分类
单独运用韵律特征对情感语音进行分类识别,混淆矩阵如表2所示。
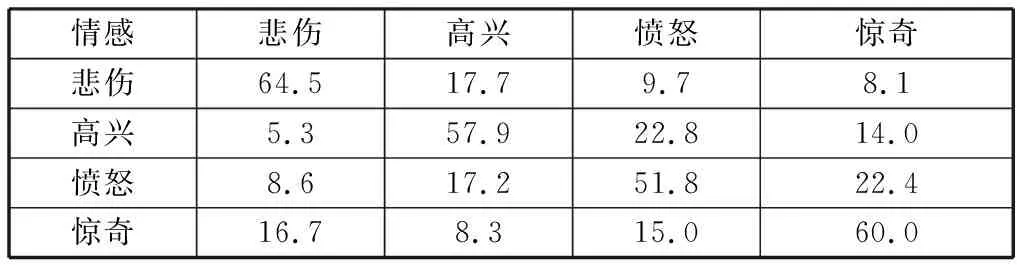
表2 单独使用韵律特征的情感识别混淆矩阵Table 2 Emotion recognition confusion matrix using prosodic features alone %
整体平均识别率是58.6%,其中“愤怒”的识别率最低,仅达到51.8%.此外,单独运用韵律特征时,“愤怒—高兴”的混淆率、“愤怒—惊奇”的混淆率较高。实验数据显示,“悲伤”的识别率最佳达到64.5%;这是由于在TYUT2.0数据库中,“悲伤”情感语音的发音较为缓慢,并且停顿时间较长,因此语速特征能够较好的识别“悲伤”情感。
3.2 MFCC特征分类
单独运用MFCC特征对情感语音进行分类识别,混淆矩阵如表3所示。
整体平均识别率是62.3%.通过实验可以看到单独运用MFCC特征,“愤怒”和“惊奇”的识别率得到了明显提高,“愤怒”识别率提高了10.3%,“惊奇”识别率提高了10%.由此提出假设,MFCC特征中是否包含着一些韵律特征所不包含的特征信息,如果将这2种特征组合是否能提高分类识别率。

表3 单独使用MFCC特征的情感识别混淆矩阵Table 3 Emotion recognition confusion matrix using MFCC features alone %
3.3 MFCC和韵律特征组合特征集分类
将MFCC和韵律特征组合进行分类识别,混淆矩阵如表4所示。整体平均识别率达到67.5%.相较于单独运用韵律特征和MFCC特征,识别率有一定程度的提高。

表4 运用韵律特征和MFCC特征组合的情感识别混淆矩阵Table 4 Using prosodic feature and MFCC feature combinationof emotion recognition confusion matrix %
由以上3组实验可以看出由韵律特征和MFCC特征组合的分类识别率相比之下最好,分析原因是两种特征的组合减弱了由于单一特征无法全面描述情感信息而导致的识别率低的缺点,在情感识别应用中具有互补性,因此可以在一定程度上提升分类识别结果。韵律特征和MFCC特征的组合特征是后续级联分类实验的特征基础。
3.4 级联分类
之前的分类识别方法仅仅是将声学特征简单地组合在一起,并没有考虑到哪种类型特征能更好的对情感进行分类识别,文献[7]中标注实验得出的4类情感语音的PAD数据如表5所示,可以看出在P(愉悦度)上分数呈现明显的高低差异,且在此维度上能够很好的区分“愤怒—高兴”和“愤怒—惊奇”这两组混淆率较高的情感。据此将“悲伤”和“愤怒”2

表5 4种情感的PAD值Table 5 PAD value of four types emotion
种情感标记成“低”,“高兴”和“惊奇”2种情感标记成“高”。
图2是级联分类流程图,将分类过程分为2个步骤。在第一阶段中将“悲伤”、“愤怒”、“高兴”、“惊奇”4种情感按照表5的高低分数标注分为两类:一类为“悲伤”、“愤怒”,这2种情感具有较低的愉悦度;另一类为“高兴”、“惊奇”,这两种情感具有较高的愉悦度。将声学特征组合与愉悦度情感维度的高低分类相结合,利用SVM分类器Ⅰ来区分高愉悦度情感和低愉悦度情感,如表6混淆矩阵所示,分类识别率达到了97.5%.

图2 级联分类流程图Fig.2 Cascading classification flowchart
第二阶段是在第一阶段的基础上,对于已经分类的高低不同的愉悦度的情感语音进一步分类识别。同样运用SVM分类器Ⅱ来区分高愉悦度情感中的“高兴”、“惊奇”,而SVM分类器Ⅲ来区分低愉悦度情感中的“悲伤”、“愤怒”。每一步的分类器都使用一个二进制SVM分类。表7和表8分别显示了第二步的分类识别结果。

表6 高低愉悦度情感分类识别结果混淆矩阵Table 6 High and low pleasure emotion classification recognition result confusion matrix %

表7 低愉悦度情感分类识别结果混淆矩阵Table 7 Low pleasure emotion classification recognition result confusion matrix %

表8 高愉悦度情感分类识别结果混淆矩阵Table 8 High pleasure emotion classification recognition result confusion matrix %
通过将图2两个步骤组合起来,得到总体分类识别率的混淆矩阵如表9所示,平均分类识别率达到82.9%.可以看出本文提出的级联分类方法无论在4种情感的识别率还是平均识别率都有很大程度的提高,尤其是在情感“高兴”、“愤怒”中的表现尤为突出,级联分类识别率相较于运用韵律特征和MFCC特征组合的分类识别率得到了明显提高,识别率提高了15.4%.
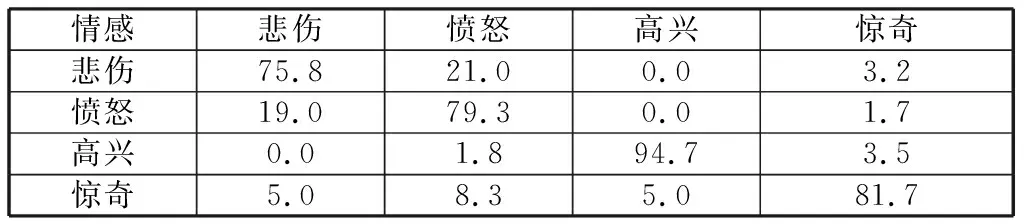
表9 级联分类识别结果混淆矩阵Table 9 Cascading classification recognition results confusion matrix %

图3 识别结果对比图Fig.3 Recognition result contrast diagram
图3直观地展示了仅用传统的声学特征和本文提出的将声学特征与情感语音PAD数据相结合的级联分类方法识别率对比结果。由图3可以明显看出,通过将声学特征与情感语音PAD数据相结合的级联分类方法,各类情感的识别率均有提高,尤其对于“高兴”情感来说,识别率提高了26.3%.
4 结论
针对运用声学特征(韵律特征和MFCC特征)对情感语音的分类识别性能不理想的问题,提出了将声学特征与情感语音PAD数据相结合的级联分类方法。从三维空间情感模型出发,将声学特征和PAD三维情感模型中对情感区分度最强的愉悦度相结合,通过SVM分类识别网络,在每一步的识别中逐渐减少样本数目,使得后一个分类器总比前一个分类器有更精确的分类。整体识别率提高了15.4%;尤其对于“高兴”情感来说,识别率提高了26.3%,可达94.7%;其他情感的识别率也大幅提高。以上分析结果表明,本文提出的级联分类的方法与传统的情感语音识别方法相比有明显的优势,为语音情感识别提供了一种可靠可行的方法。但通过实验结果可以看出,最终结果中的一些情感的混淆率仍然很大。因此在今后的研究工作中,需要进一步探究语音的情感特征与PAD三个维度的相关性,提取相关性高的情感特征,更有针对性地减少混淆率,从而有效提高情感识别率。
猜你喜欢
核安全(2022年3期)2022-06-29
读者(2021年12期)2021-05-27
中华诗词(2019年1期)2019-08-23
中国听力语言康复科学杂志(2019年3期)2019-06-24
福建基础教育研究(2019年11期)2019-05-28
听力学及言语疾病杂志(2019年3期)2019-05-24
—— “T”级联
同位素(2019年1期)2019-03-14
中国交通信息化(2018年3期)2018-06-13
周末·校园文学(2017年35期)2018-02-06
中国高新技术企业(2017年5期)2017-05-05
