
深度学习实时多人姿态估计与跟踪
2018-09-20 07:00:50许忠雄张睿哲石晓军岳贵杰刘弋锋
中国电子科学研究院学报 2018年4期
许忠雄,张睿哲,石晓军,岳贵杰,刘弋锋*
(1. 中国电子科学研究院,北京 100041;2.电子科技大学,成都 610041;3.中国电子科技集团有限公司,北京 100846)
0 引 言
基于计算机视觉的人体姿态估计是从单张RGB图像上获取人体骨点位置以及骨点之间的相互连接。人体姿态估计在智能监控[1]、人机交互[2]以及手势识别[3]等领域有着广阔的应用前景。然而,人体姿态估计的研究面临许多挑战,如图像中人数通常无法预先确定,多人情况下出现人体相互遮挡等。随着人数的增加,算法的运行效率也面临巨大的挑战。在深度学习被广泛应用之前,图结构(Pictorial Structures)模型[4]被广泛应用于人体姿态估计,其将人体肢体视为组成人体的组件,通过人工指定的图像特征检测组件实现人体姿态估计。基于图结构的模型精度不高,且难以扩展到多人姿态估计。深度学习算法的提出,给人体姿态估计提供了一种新的思路,部分研究者开始尝试用深度学习方法进行多人姿态估计。目前多人姿态估计主要有两种思路,一种是基于自顶向下的算法[5-9],先从图像中检测出所有人,随后利用单人姿态估计的方法[10-11]对所有人进行姿态估计。自顶向下算法的缺点是算法运行效率随着人数增加而降低,且部分被遮挡的人无法被检测,精度不高。另一种是基于自底向上的算法[12-13],先检测出所有人的骨点,再将骨点进行连接形成图,最后通过图优化的方法剔除错误的连接,实现多人姿态估计。自底向上算法的优点是运行时间不随人数增加而线性增加,更有利于实时多人姿态估计。本文多人姿态估计是基于自底向上的方法,提出一种六阶段双分支的深度神经网络结构,可同时获得骨点位置以及骨点之间的连接置信度,有效稀疏骨点连接图,提高算法运行效率。对于骨点连接置信度,提出骨点之间的亲和区域,通过在亲和区域上的线性积分计算骨点连接置信度。
1 多人姿态估计
对于一张输入图像,深度神经网络同时预测出每个骨点的热力图S=(S1,S2,…,SJ)和骨点之间的亲和区域L=(L1,L2,…,LC)。热力图的峰值为骨点的位置,骨点相互连接构成二分图,亲和区域对图的连接进行稀疏,最后对二分图进行最优化实现多人姿态估计。
1.1 网络结构
如图1所示,整体网络架构为六阶段双分支,上分支负责预测骨点位置,下分支负责预测骨点之间的亲和区域。前一阶段的预测结果融合原有图像特征并作为下一阶段的输入,经过多阶段的操作以提高骨点预测精度。
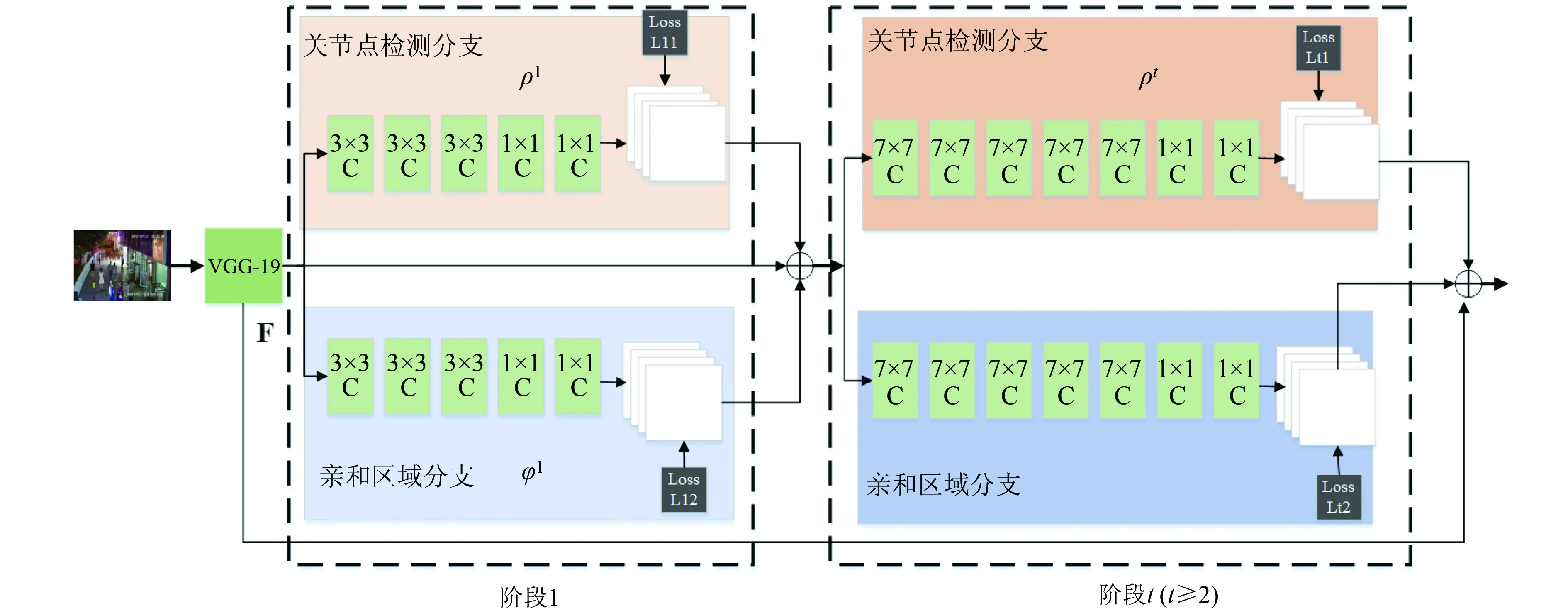
图1 网络结构
图像特征采用VGG-19模型进行提取,并用符号F表示图像特征。在第一阶段,网络以F作为输入,输出骨点热力图S1=ρ1(F)和骨点之间的亲和区域L1=φ1(F),其中ρ1和φ1为网络的映射函数,其本质是一系列的卷积操作。在第一阶段,对于输入特征采用3×3大小的卷积核连续进行三次卷积,之后用1×1大小的卷积核连续进行三次卷积。之后的阶段将前一阶段的预测结果和原图像特征F进行融合,作为当前阶段的输入,经过卷积操作分别预测出骨点热力图和亲和区域:
St=ρt(F,St-1,Lt-1),∀t≥2
(1)
Lt=φt(F,St-1,Lt-1),∀t≥2
(2)
其中ρt和φt分别表示现阶段t的卷积操作,先用大小为7×7的卷积核连续进行五次卷积操作,之后用大小为1×1的卷积核连续两次卷积操作,最终输出本阶段的骨点热力图和亲和区域。
由于骨点热力图和亲和区域本质有所不同,因此在训练的时候需要分别对骨点位置和亲和区域进行监督, 损失函数均采用L2损失。为了避免梯度消失现象发生,在每个阶段的输出都添加损失函数,起到中继监督作用。另外在样本标注的时候,会存在行人漏标等情况对损失函数造成影响,因此需要对损失函数在各个位置进行掩膜操作。于是,对于骨点位置和亲和区域的损失函数形式如下:
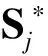
1.2 骨点热力图
骨点热力图是衡量骨点在图像某位置出现的置信度,由一系列二维的点组成,每个点表示骨点出现在该位置的置信度,骨点最终位置定义为置信度最高的位置。对于图像中只有一个人的情况,则某一类型可见的骨点在热力图中只有一个峰值。对于多人情况,某一类型可见的骨点存在多个峰值,表示不同人的同一个类型骨点。在对样本进行标注时,只需确定骨点的位置,则该骨点真值热力图为在该点处放置一个固定方差的高斯核,用高斯函数确定各个位置的置信度。对于第k个人的第j个骨点,以xj,k表示骨点的实际位置,则该骨点周围的像素点的置信值为:
其中标准差σ控制了置信值的分布范围。对于一张存在多人的图像,每个人特定骨点的实际热力图为取得高斯核范围内的最大值:
1.3 骨点亲和区域
如图2所示,骨点亲和区域由一系列单位向量组成,每一段肢体对应一个亲和区域,位于肢体上的像素点都由一个单位向量进行表示,包含了位置和方向信息,所有在肢体上的单位向量构成亲和区域。

图2 骨点亲和区域

图3 肢体示意图
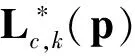
(8)
其中v=(xj2,k-xj1,k)/‖xj2,k-xj1,k‖2表示单位向量,亲和区域被定义在肢体线段上的所有单位向量:
(9)
其中σl为距离阈值,单位为像素;lc,k=‖xj2,k-xj1,k‖2为整个肢体的长度;v⊥为垂直于肢体的向量。肢体重叠的亲和区域表示为:
其中nc(p)为在位置p处不同人的亲和区域在该处的叠加次数,即在该处将所有人的非零向量进行叠加。
在网络推理测试阶段,任意两个骨点之间的关联置信度是通过在两点之间对亲和区域进行线性积分得到的。对于两个骨点位置dj1和dj2,在两骨点组成的线段上对亲和区域Lc进行采样,则两骨点之间的关联置信度为在该线段上亲和区域的积分:
其中p(u)为在两个节点dj1和dj2之间的插值:
p(u)=(1-u)dj1+udj2
(12)
1.4 二分图优化
经过网络推理,得到骨点热力图以及骨点之间的亲和区域,对热力图采取非极大值抑制得到一系列候选骨点。由于多人或者错误检测,对于每一类型的骨点会存在多个候选骨点。这些候选骨点之间的连接构成二分图,每两个骨点之间的连接置信度通过式(11)线积分计算得到。为二分图找到最优的稀疏性是NP-Hard问题。
约束条件:


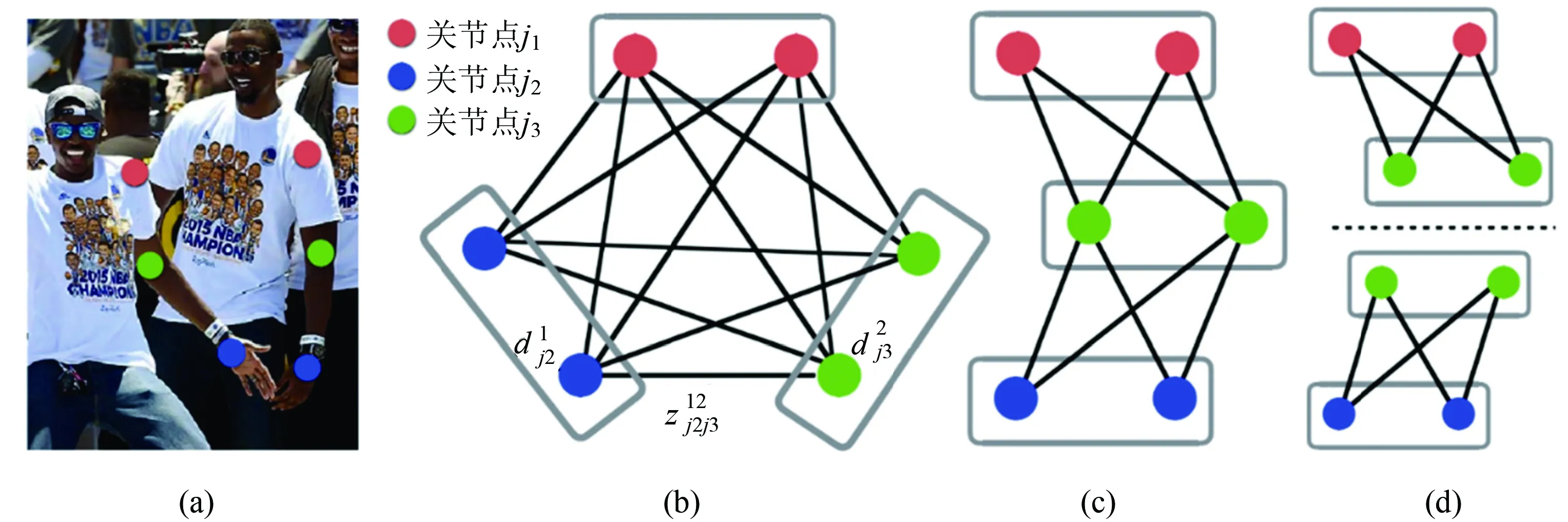
图4 多人姿态估计求解
扩展到多人所有骨点的最优化问题,即定义Z为K维匹配问题,这是一个NP-hard问题,为了提高最优化效率,如图4所示,本文采用两种方法降低二分图优化算法的复杂度。首先,如图4(c)所示,剔除跨骨点之间的连接构成稀疏二分图,代替图4(b)所示的全连接二分图;然后根据肢体将稀疏后的二分图拆解得到图4(d)所示的多个简化二分图。因此,整体优化问题转化为对各个简化后的二分图进行最优化。而最优化的目标函数为所有简化二分图的权重之和达到最大:
优化之后将各个简化二分图中共同的骨点进行整合得到最终多人人体姿态估计。这样做的优点是将NP-hard问题转化为多个较容易求解的二分图最优化,可以有效逼近全局最优解,同时降低算法复杂度,提高算法的运行效率,达到实时多人姿态估计的目的。
2 实验分析
2.1 精度评价
对于骨点预测精度,将本文所提的六阶段双分支网络与现有基于深度学习的人体姿态估计算法进行对比,图像尺寸缩小至654×368输入到各个算法,对人体上半身7个骨点通过不同的高斯核标准差计算平均OKS值[15],得到如图5所示的对比结果,由图可知本文所提的方法骨点预测精度略高于其他算法,与DeeperCut[12]和ArtTrac[16]的精度相近。取标准差为1时对7个骨点的预测精度进行量化对比,得到如表1所示。从表中可知本文所使用的网络结构有5个骨点的预测精度要优于DeepCut[13]、DeeperCut和ArtTrack。运行效率方面,在输入图像为654×368的情况下,本文所使用的网络每帧耗时5毫秒,而DeepCut和DeeperCut达到秒级,ArtTrack在150毫秒。
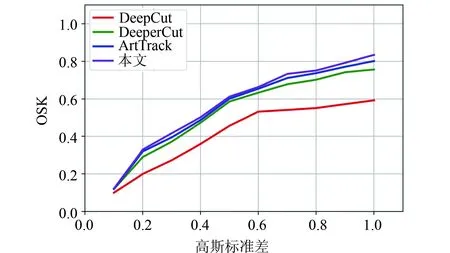
图5 骨点精度对比图
2.2 运行效率
实验所使用的显卡为NVIDIA TITAN XP,CPU为Intel i7-6900K。图像大小为1920×1080,通过下采样方法额外获得1280×720和720×480两个低分辨率的视频。首先分析运行效率与人数的关系,在相同视频流和相同分辨情况下,计算自顶向下与自底向上运行时间与人数关系,计算结果如图6所示。由图可知,自顶向下随着人数的增加耗时几乎呈线性增加,而自底向上的运行耗时几乎不随人数增加而递增。卷积神经网络预测骨点的耗时也几乎不随人数增加而增加。因此本文所使用的自底向上算法的运行效率不受行人数量的影响,对人数不确定的情况依然可以实时进行多人姿态估计。

表1 各个骨点预测平均准确率

图6 运行耗时
最后,对三种分辨率视频采用两种不同方法进行耗时分析,结果如表2所示,随着分辨率的降低,处理速度越来越快。若对视频所有帧都进行骨点检测,在最高分辨率情况下每秒可处理23帧,人眼感觉不到卡顿,基本达到实时。如果采用间隔检测结合跟踪,帧率可提高十几帧,完全达到实时要求。

表2 不同分辨率运行效率对比
3 结 语
针对现有人体姿态估计算法无法满足实时的要求,提出一种实时多人体姿态估计与跟踪方法。通过实验对比,本文提出的六阶段双分支网络结构在骨点预测精度上略高于现有基于深度学习的人体姿态估计算法。算法运行效率方面,由于网络同时预测出骨点位置和骨点之间的空间关系,为多人姿态估计算法提供更加稀疏的二分图,降低二分图优化复杂度达到实时的效果。目前算法估计出来的人体骨点和姿势仍处在二维平面,实际应用时局限性大,为了扩大实际应用,今后的研究目标是单张图像人体三维姿态估计。
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
英语文摘(2021年4期)2021-07-22 02:36:30
学生天地(2020年3期)2020-08-25 09:04:16
现代临床医学(2019年4期)2019-09-10 07:44:02
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
计算机应用(2018年5期)2018-07-25 07:41:26
中学历史教学(2017年12期)2018-01-19 03:00:23
轴承(2015年2期)2015-07-25 03:51:04
现代检验医学杂志(2015年6期)2015-02-06 01:44:27
