
多层递阶融合模糊特征映射的模糊C均值聚类算法
2018-09-19 01:05鲍国强应文豪蒋亦樟张英王骏王士同
智能系统学报 2018年4期
鲍国强,应文豪,蒋亦樟,张英,王骏,王士同
(1. 江南大学 数字媒体学院,江苏 无锡 214122; 2. 江苏省媒体设计与软件技术重点实验室,江苏 无锡 214122;3. 常熟理工学院 计算机科学与工程学院,江苏 常熟 215500)
近年来,面向复杂非线性数据的模糊聚类问题得到了研究人员的广泛关注[1-6]。在无监督学习环境中为了提高复杂非线性数据的可分性,一个重要的研究思路是使用非线性映射将数据映射到高维空间中。在众多非线性映射方法中,核方法作为经典的隐性映射方法得到了广泛的应用[5-13]。研究表明,核方法通过使用核函数代替内积运算,将待分类数据隐性地映射到高维空间,从而有助于复杂非线性数据的学习。但是,核方法还存在着诸多局限性,尤其是如何针对不同的问题选择合适的核函数和相关参数,这都会影响算法的聚类效果。
模糊系统因其强大的不确定性系统建模能力、优良的可解释性和出色的泛化能力,近年来在复杂非线性数据学习问题中得到了大量的研究。在已有的经典模糊系统中,Takagi-Sugeno-Kang(TSK)[14-17]模糊系统由于其良好的解释性和简洁性得到了广泛应用。在TSK模糊系统中,其规则前件部分通过显性映射方式(本文称之为模糊特征映射),将输入数据映射到高维空间中去。从本质上讲,模糊特征映射可以视为一种特殊的非线性映射方式。基于此,本文将输入数据进行相应的非线性映射。在具体实现过程中我们发现,经模糊特征映射后的特征维数过高,这会增加计算量,同时也导致了数据的冗余。为此,本文通过引入多层递阶融合机制和主成分分析,提出新型的基于多层递阶融合的模糊特征映射新方法。并将之与经典模糊聚类技术相结合,进一步提出基于多层递阶融合模糊特征映射的模糊C均值聚类新方法。经实验验证,本文算法在处理复杂非线性数据时能够取得比传统模糊聚类算法更有效的聚类效果。
1 Takagi-Sugeno-Kang模糊系统及模糊特征映射
Takagi-Sugeno-Kang模糊系统模型[18-23]是最重要的用于建模与智能控制的模糊模型之一。对于经典的TSK模糊模型,最常用的模糊推理规则的定义如下:
第k条模糊规则:
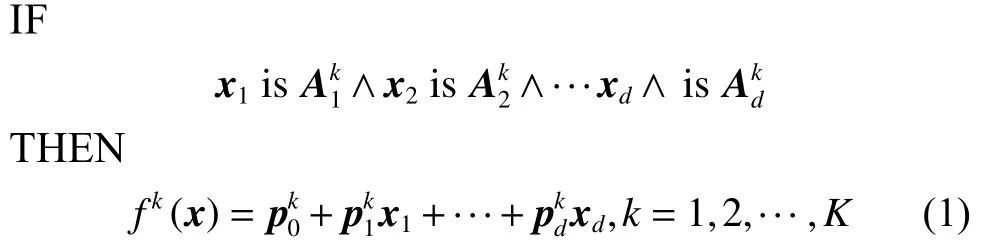


通常采用高斯函数作为模糊隶属函数,其计算公式为








TSK模糊模型的训练问题转化为式(13)线性回归模型的参数学习问题[24]:

从式(13)中可以观察到,输入向量经式(8)~(10)计算,可以变换为一个维的高维向量,本文中我们将这一转换过程称为模糊特征映射。与已有核方法中的隐性映射相比,模糊特征映射具有以下特点:1)它是一种显性映射方式,用户可以在高维特征空间中得到数据的显式表示方法;2)模糊特征映射基于模糊规则进行构建,而模糊规则本身具有较强的可解释性;3)输入向量经模糊特征映射后得到的高维特征向量的维数可以由模糊规则数确定,这有利于用户控制高维空间中数据的复杂程度。
2 基于多层递阶融合模糊特征映射的模糊C均值聚类算法
2.1 基于多层递阶融合的模糊特征映射新方法
原数据通过模糊特征映射,得到其在高维空间中的新表示。但是作为单层映射结构,会因映射后的特征维数过高使得数据变得混乱和冗余,继而影响算法后续的聚类效果。研究表明[25-26],将单层映射结构改造为多层映射结构,可以有效地提高算法对复杂非线性数据的学习能力。为此,本文引入多层递阶融合的概念来构造新型的映射,提出基于多层递阶融合的模糊特征映射新方法(MLHFFFM)。通过对每层模糊特征映射之后的高维特征表示进行PCA降维,再进行相应的信息补充,形成新的融合层,依次进入下一层的压缩融合过程,其结构如图1所示。

图 1 MLHFFFM算法结构图Fig. 1 Structure of MLHFFFM algorithm
基于多层递阶融合的模糊特征映射新方法MLHFFFM算法描述如下:
输入 给定一个数据集D={X, Y},设置初始模糊规则数K,分层融合层数S。
1) 对原数据进行第一层的模糊特征映射(初始层)
④ 再经过式(8)~(10)的转化,得到映射后高维空间中的数据矩阵。
2) 多层递阶融合
② For i=2:(S-1);
③ 重复步骤1),对原数据进行模糊特征映射,得到数据矩[阵];
⑥ end;
2.2 基于多层递阶融合模糊特征映射的模糊C均值聚类算法MLHFFFM-FCM
本节中,将多层递阶融合模糊特征映射与经典模糊聚类算法FCM相结合,提出基于多层递阶融合模糊特征映射的模糊C均值聚类算法。MLHFFFM-FCM算法描述如下:
输入 给定一个数据集D={X, Y},设置初始模糊规则数K,分层融合层数S。
1) 通过基于多层递阶融合的模糊特征映射,将输入数据X转化为。
输出 模糊划分矩阵U。
3 实验研究与分析
为了验证MLHFFFM-FCM算法在复杂非线性数据分析上的有效性,本节从3个方面进行对比分析:1)各FCM演变算法之间聚类效果的对比实验;2)单层映射结构与多层递阶融合映射结构的聚类效果对比实验; 3)关键参数敏感性的对比实验。
3.1 算法性能的评价指标
为了对各类算法的聚类性能进行对比,本文采用NMI(normalized mutual information)和RI(rand index)作为实验评价指标。这两个指标的值越接近1,说明算法聚类性能越好。其计算公式如下:
1) NMI

2) RI

3.2 实验设置
我们采用UCI真实数据集(http://archive.ics.uci.edu/ml/)来评估本文算法。为了测试实验应用数据集的广泛性以及避免选取数据集的偶然性,选择其中7个具有代表性的数据集Ar2、Diabetes、Zoo、Australian、Breast、Heart、Chronic_Kidney_Disease进行测试,其中数据集的相关信息如表1所示。同时本文选取5种经典的聚类算法与MLHFFFM-FCM算法进行对比实验,分别为FCM算法、PCA-FCM算法、ELM-FCM算法、KFCM-K算法以及KFCM-F算法。所有实验运行平台的配置如下:酷睿 i3 3.6 GHz CPU,3.42 G RAM,32位Windows 7操作系统,MATLAB R2012b编程环境。另外各算法相关说明及其参数设置如表2所示,其中各算法涉及的模糊指数m的寻优范围均为{1.2, 1.4, 1.6, 1.8, 2.0, 2.2, 2.4, 2.6, 2.8, 3.0, 3.2,3.4, 3.6, 3.8, 4.0}。

表 1 实验数据集Table 1 Experimental data sets

表 2 各算法的说明以及相关参数设置Table 2 The description of the algorithm and related parameters
3.3 聚类效果对比实验
为了验证MLHFFFM-FCM算法的有效性,本节对算法进行对比实验测试。在本实验中,将初始模糊规则数r设置为30,多层递阶融合层数设置为5层,并根据表2的实验相关参数设置,分别对各算法重复运行10次。最终的实验中各算法的参数取值情况和实验结果如表3和表4所示。

表 3 各算法参数取值情况Table 3 Parameter values of each algorithm

表 4 各算法的运行结果Table 4 Results of each algorithm
从表4中可以明显地看出,在聚类精度上,文中涉及的对比算法只能在某个或某几个数据集上取得较优的结果,而MLHFFFM-FCM算法不仅在所有的测试数据集上取得满意的结果,并且还有着明显的提高。这说明了MLHFFFM-FCM算法的有效性,也进一步说明了该算法处理复杂非线性数据的强大能力。
3.4 单层映射结构与多层递阶融合映射结构的聚类效果对比实验与分析
为了体现本文算法引入的多层递阶融合方法的优越性,本节实验针对多层递阶融合映射结构对FCM算法性能的影响进行实验与分析。实验在模糊规则数设置相同的情况下,分别采用单层映射结构和多层递阶融合映射结构对原输入数据进行非线性映射,将映射后的数据采用FCM进行聚类。实验最终的参数取值情况和结果如表5和表6所示,其中因受篇幅所限,仅在表6中给出RI指标结果,NMI与之有类似的结果,不再列出。
从表5和表6中可以明显地观察出,相比于单层映射结构,基于多层递阶融合映射结构的模糊聚类方法能够取得更好的学习效果。这是由于在单层映射之后的数据存在冗余信息,而在压缩之后又会导致信息缺失。但是多层递阶融合的映射结构是建立在单层映射结构的基础上,采用PCA技术对每一层模糊特征映射得到的高维特征表示进行压缩,再对应地结合每一层数据信息融合形成的。因此通过多层递阶融合的方法,可以有效地精简冗余信息,同时对每一层进行适当的信息弥补。这也充分体现了本文提出的多层递阶融合映射结构的优越。

表 5 两种算法结构的参数取值情况Table 5 Parameter selection of two algorithms

表 6 两种算法结构的RI_mean性能指标Table 6 Performance index of two algorithms
3.5 参数敏感性实验
模糊规则数r作为MLHFFFM-FCM算法中的关键参数,本节针对该参数进行参数敏感性实验。这里为了让实验结果能够直观地进行观察与对比,我们同时对KFCM-F算法中的关键参数进行参数敏感性实验,进而研究模糊规则数这一关键参数对MLHFFFM-FCM算法性能的影响。实验中,MLHFFFM-FCM模糊规则数r的实验取值范围为{5, 10, 15, 20, 25, 30, 35, 40, 45, 50},KFCM-F算法中核参数的实验取值范围为{0.1,1.5, 10, 50, 100, 150, 200, 500, 1 000},实验最终结果分别如图2和图3所示。

图 2 KFCM-F算法性能随变化的影响Fig. 2 Effect of on the performance of KFCM-F

图 3 MLHFFFM-FCM算法性能随模糊规则数r变化的影响Fig. 3 Effect of fuzzy rules r on the performance of MLHFFFM-FCM
4 结束语
本文提出的MLHFFFM-FCM算法,是一种采用新型的显性映射方式来处理复杂非线性数据的无监督学习方法。相比于现有的核函数映射方法,MLHFFFM-FCM算法在取得良好聚类效果的同时,还对算法中模糊规则数不敏感,这更有利于算法在实际应用中的选用。但是本文提出的MLHFFFM-FCM算法仍然具有一定的缺陷,例如对于高维数据,其时间开销较大。如何有效克服这些问题,将是今后进一步研究的重点。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
铁道通信信号(2019年6期)2019-10-08
当代陕西(2019年10期)2019-06-03
Coco薇(2017年11期)2018-01-03
雷达学报(2017年6期)2017-03-26
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
互联网天地(2016年1期)2016-05-04
