
一种基于共享近邻亲和度的聚类算法
2018-09-18 02:12邱保志
计算机工程与应用 2018年18期
邱保志,辛 杭
郑州大学 信息工程学院,郑州 450001
1 引言
聚类是将给定的数据集划分成互不相交的非空子集,其中,每个子集代表一个类,同一类中的数据对象具有较高的相似性,而不同类中的数据对象高度不相似。目前人们已经提出了许多聚类算法,其中基于密度的聚类算法是通过寻找密度足够大的连通区域形成聚类,这类算法具有发现任意形状的聚类且对噪声不敏感的特点,所以在模式识别、机器学习、信息处理等诸多领域都具有广泛的应用。
基于密度的聚类算法以数据集在空间分布上的稠密程度为依据进行聚类,将簇看作是数据空间中被低密度区域分割开的高密度区域。DBSCAN[1]是一种经典的密度聚类算法,该算法将密度定义为给定半径邻域内对象的个数,密度大于给定阈值的对象被标识为核心点,然后对核心点进行密度可达聚类。然而随着维度的增加,对象分布将变得非常稀疏,这时,基于邻域度量密度的方式将失去度量意义。
基于密度的聚类算法DPC[2]中,密度被定义为与对象距离小于给定阈值的对象个数,据此将聚类的中心点定义为局部密度最高,且全局范围内与密度更高的中心点的距离较大。在准确识别聚类中心点后,按照最近邻分类完成对整个数据集的聚类。DPC算法在处理低维数据集时能够准确地识别聚类中心并得到较好的聚类结果,但是对高维数据集聚类准确度不高。
CLUB[3]算法引入了k近邻的概念,将对象的密度定义为与k个近邻的平均距离的倒数,利用与近邻对象的平均距离来度量局部分布特征,平均距离越小,表明对象局部分布的越紧密,对象就越有可能分布在稠密区域。该度量方式使得算法能够较好地处理多密度和任意形状的数据集,但是处理高维数据集时聚类准确度仍然不高。
共享近邻[4-5]采用对象间共享近邻的多少确定对象之间的相似性,对象间的共享近邻越多,这两个对象就越靠近,其相似性就越大,说明它们属于同一类的可能性越大;反之,对象间的共享近邻越少,这两个对象分布就越稀疏,其属于同一类的可能性就越小。
为了准确地度量对象的局部密度且使密度度量能适用于高维空间聚类[6-10],本文引入k近邻和共享近邻技术,提出一种基于共享近邻亲和度的聚类算法。k近邻可以准确反映空间中对象的局部分布特征,共享近邻用于度量空间中对象间的相似度。利用k近邻和共享近邻定义共享近邻亲和度,以共享亲和度作为密度度量方式提取核心点,然后使用广度优先搜索算法对核心点进行密度可达聚类,最后将非核心点指派到距离最近的点所属聚类中[11],即完成整个数据集的聚类。
2 相关定义
D表示数据集,dist(x,y)表示对象x和y的欧式距离。
定义1(k近邻空间)对 p∈D,p的k近邻空间是距离 p最近的k个点的集合,记作Nk(p):定义2(knn距离)对 p∈D,p的knn距离是与k个近邻的距离的平均值,记作distknn(p):

knn距离反映了对象的局部分布情况,knn距离越小,表明对象周围近邻分布的就越密集,对象就越有可能分布在稠密区域,反之则越有可能分布在稀疏区域。
对 p,q∈D,p与q的共享近邻是指 p与q的k近邻空间的交集元素,交集元素反映了对象间的相似程度,交集元素越多,表明两个对象在空间中分布的越靠近,其相似性就越大。
定义3(共享近邻数)对 p∈D,p的共享近邻数是指 p与其k个近邻的共享近邻元素的总个数,记作Snn(p):
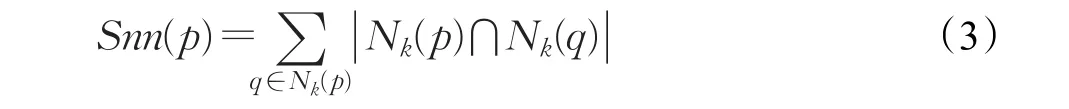
定义4(Snn亲和度)亲和度表示一个对象与其他对象之间的亲和程度,一个对象的共享近邻亲和度定义为该对象的共享近邻数与knn距离的比值。记作Affinitysnn(p):

对象的共享近邻数越多,knn距离越小,Snn亲和度就越大,表明对象与近邻的亲和程度就越大,对象局部空间分布就越紧凑,即反映该对象的局部密度就越大。反之,局部密度就越小。
定义5(核心点)对 p∈D,若 p为核心点,则其需要满足以下条件:

即核心点的Snn亲和度不小于k个近邻点的Snn亲和度的平均值。
定义6(密度直接可达)若为核心点,如果两个对象满足:,即两个核心对象的k近邻空间存在交集元素,则称核心对象 p和q是密度直接可达的。
选取亲和度足够大的点作为核心点,核心点分布在数据空间的稠密区域,通过对核心点进行密度直接可达聚类,将数据空间中高密度区域连接起来形成聚类的骨架,然后将非核心点划归到距离最近的高密度点所属聚类中,即完成整个数据集的聚类。
k近邻方法选取空间中距离对象最近的k个近邻来反映其局部分布特征,适用于描述高维空间中对象的分布特征,共享近邻适用于任意维度空间对象的相似性度量[12-15],因此本文基于k近邻和共享近邻定义亲和度作为新的密度度量方式,同样也适用于高维空间的聚类处理。
3 算法描述
算法首先寻找每个对象的k近邻集,据此计算对象的knn距离和共享近邻数,然后计算共享近邻亲和度并提取核心点,利用广度优先搜索算法将满足密度直接可达的核心点进行聚类,最后对剩余点进行指派即完成整个数据集的聚类。算法伪代码如下:
SNNA算法
Input:D,k//D表示原始数据集,k表示近邻数
Output:Result//Result表示最终的聚类结果
2.for each x∈D do
3. Find Nk(x)

13.CoreClust←BFS(Core,Nk(x))//使用广度优先搜索算法对核心点进行聚类
14.Assign the rest objects to their nearest CoreCluster
15.Result←CoreCluster
4 实验结果与分析
实验环境为:Intel Core i3-2130 CPU 3.4 GHz,内存4 GB,操作系统Microsoft Windows 7,算法编写环境为MATLAB R2014a。
4.1 实验数据
实验选取了10个数据集来验证本文算法对于聚类任务的有效性,数据集的维度从二维到万维不等,这些数据集可广泛代表数据的各种分布。数据集详细信息如表1所示。二维数据集含有多种不同的分布,Flame数据集包含两个形状不规则的聚类,且两个聚类间呈现半包围的环绕分布,用以测试算法能否准确的识别距离较近的两个聚类;Compound数据集共有6个密度分布不均匀的聚类,且聚类之间存在嵌套分布,用以测试算法能否准确识别多密度聚类和嵌套的聚类;R15数据集共包含15个大小、形状均不相同的聚类,用以测试算法能否准确识别多个聚类;Aggregation数据集共包含7个大小形状均不相同的聚类,且聚类之间存在干扰的桥接线,用以测试算法能否准确识别多密度聚类和存在桥接干扰线的聚类;其他6个数据集为高维分类数据集,用来测试算法能否在高维空间中准确聚类。

表1 数据集基本信息
4.2 参数设置与时间复杂度
本算法只需设置一个参数,即近邻数k。算法在处理二维数据集时准确率与参数k的关系如图1所示,从图中发现当k在[5,15]取值时通常能得到较好的聚类结果。相比DBSCAN算法和DPC算法,本文算法的参数易于确定。SNNA算法需要根据k近邻和共享近邻来计算亲和度,算法的时间消耗主要在于计算k近邻集合,时间复杂度为O(k⋅n2),若采用R*-tree空间索引进行优化,时间复杂度可降低为O(k⋅n⋅lbn)。
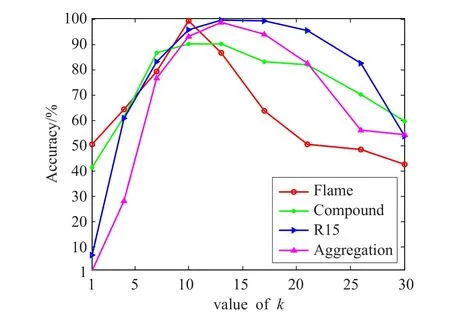
图1 SNNA算法中,k值与准确率的关系
4.3 聚类结果分析
本算法在各二维数据集上的核心点提取和聚类结果如图2所示,从图中可以看出,算法在二维数据集上总能正确识别聚类的个数并得到较好的聚类结果,从而验证了算法在二维数据集上的有效性。
各算法在实验数据集上的参数设置和聚类结果如表2所示,采用准确率(Accuracy)和调整兰德系数(ARI)来评价各聚类算法的执行结果,具体描述如下。其中,准确率为正确分类的对象数与识别出的对象总数的比值,其值在[0,1]区间,值越大意味着正确分类的对象越多;调整兰德系数(ARI)是兰德系数(RI)的改进形式,ARI的值在[-1,1]区间,值越大意味着聚类结果与真实情况越吻合。


图2 二维数据集的聚类结果

表2 各算法在各数据集的聚类结果
从表2中可以看出,与其他算法相比,SNNA算法在处理二维数据集时可以得到更高或相近的准确率和ARI值。对于Compound数据集,由于该数据集右侧呈现嵌套分布,数据分布稀疏,参数k的取值范围较小,因此未能对此簇完全聚类,从而导致本算法在处理该数据集时准确率要稍低于CLUB算法,但是仍然能够准确识别出聚类个数,且准确率高于DBSCAN和DPC算法。对于高维度数据集,SNNA算法同样能够得到较好的聚类结果,与其他三个算法相比,SNNA算法在各数据集均能得到较高的聚类准确率,并且在Sonar和Facedata数据集上得到了远高于其他算法的准确率,同时本算法也取得了较高或相近的ARI值,从而验证了本算法在处理高维数据集时的有效性和准确性。
5 结论
本文引入k近邻和共享近邻,提出了一种基于共享近邻亲和度的聚类算法,定义共享近邻亲和度作为密度度量,算法保留了密度聚类算法在处理多密度数据集时的优点,同时适用于高维空间的聚类,从而更好地处理高维度数据集。该算法简单、易于理解,仅需要输入一个近邻参数k,能够很好地处理多密度数据集和高维度数据集。然而算法在处理大数据集时会面临运行时间过长的问题,如何进一步提高算法的执行效率以及处理高维度大数据集将是下一步的研究方向。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
铁道通信信号(2019年6期)2019-10-08
数学年刊A辑(中文版)(2019年3期)2019-10-08
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
山东青年(2016年1期)2016-02-28
中国学术期刊文摘(2016年1期)2016-02-13
智能系统学报(2015年4期)2015-12-27
当代修辞学(2014年3期)2014-01-21
