
基于多尺度特征融合CNN模型的车辆精细型号识别
2018-09-18 02:12刘廷建顾乃杰张孝慈林传文
计算机工程与应用 2018年18期
刘廷建,顾乃杰,张孝慈,林传文
1.中国科学技术大学 计算机科学与技术学院,合肥 230027
2.中国科学技术大学 安徽省计算与通信软件重点实验室,合肥 230027
3.中国科学技术大学 先进技术研究院,合肥 230027
1 引言
近年来,我国汽车保有量的急剧增长给交通管理造成了巨大的压力。智能交通管理系统的出现,极大地提高了交通管理的便捷性和高效性,给大众的生活带来了广泛的影响。卡口监控场景下的车辆精细型号识别作为智能交通系统中的重要组成部分,不仅可以为车辆检测、识别和跟踪提供有效的信息,还有助于打击违法套牌行为、减少套牌车犯罪行为等。
关于车辆型号识别的研究,最初主要解决的是车辆制造商品牌的分类,如奔驰、奥迪、比亚迪等,这类研究只对车辆型号做了粗略的分类。实际上,车辆的同一品牌会包含多个系列,如奥迪A5和奥迪Q5便属于奥迪旗下的两个不同的精细型号。由于车辆精细型号种类繁多,同一个制造商不同子型号的车辆正脸在外观上又很相似,而且监控摄像头容易受天气、光照等因素的影响,导致不同车辆型号间的差异变小,因此针对车辆精细型号的研究更具挑战性。
2 相关工作
针对车辆精细型号识别的问题,国内外众多学者已经进行了研究。Wang等人[1]通过提取车辆脸部位置特征向量,并建立车辆脸部特征库,然后利用最小距离法依次比较特征库中车辆脸部特征向量和目标样本特征向量之间的差异,以此判断该样本的类别。这种方法虽然实现简单,但算法泛化性能不足。Psyllos等人[2]利用车牌位置等先验知识定位出车标位置,然后使用一个概率神经网络(Probabilistic Neural Network,PNN)完成车辆品牌的识别,但对于车辆精细型号的识别,只用车标区域的特征信息并不足以很好地区分同一品牌下的不同子系列的型号。Yu等人[3]提出了一种基于词袋(Bag-of-Words,BoW)的车辆标识识别方法,首先提取车标的尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)特征,其次将特征量化为视觉词汇表,最后建立空间信息直方图训练一个SVM分类器来实现车标的识别。该方法对于SIFT特征的提取,通常需要大量的计算,且准确率也不高。张等人[4]提出一种基于联合特征的卷积神经网络(Convolutional Neural Network,CNN),该方法将通过CNN中不同层提取的特征联合起来作为全连接层的输入,训练分类器用于车型分类。该方法虽然识别效果较好,但由于额外使用了一个辅助网络,从而降低了模型的识别速度。Munroe等人[5]先检测出车辆正脸图片的边缘信息,然后从中提取一组固定长度的特征向量,最后用K最近邻(K-Nearest Neighbor,KNN)方法完成车型的分类。但由于只采用了单一的车辆边缘信息,没有考虑车辆其他局部区域的特征,因此识别效果不佳。Yang等人[6]构建了一个公开的车辆图像数据库CompCars,并用经典的CNN模型(AlexNet、Overfeat和GoogLeNet等)对车辆精细型号的识别问题进行了研究,但并没有针对车辆精细型号识别问题对现有的CNN模型作进一步改进。Fang等人[7]提出了一个由粗到精的CNN模型,用以提取并融合车辆的局部特征和全局特征,并训练一个SVM分类器实现车辆精细型号的识别,但相比端到端的CNN模型,这种方法训练和测试的速度都较慢。
如上所述,现有的车辆精细型号识别方法仍然存在诸多局限性。一方面,对于传统的人工提取车辆特征进行识别的方法[1,3],通常需要十分复杂的计算,且算法泛化性能不足;另一方面基于改进卷积神经网络的车辆精细型号识别方法[4,7],虽然在提取图像特征时,得到了比普适性较差的传统手工设计特征法更好的结果[8-10],但仍然存在一些缺点,例如(1)只重视模型识别精度的提升而忽略模型识别速度的下降;(2)车辆特征提取不充分,只提取车辆轮廓或车标区域等单一特征,而没能综合考虑车辆全局和局部特征;(3)模型参数规模较大,使得模型更容易过拟合。为克服上述局限性,本文针对卡口监控场景下的车辆精细型号识别问题,提出一种高效的基于多尺度特征融合的端到端CNN模型,在大幅度降低模型参数规模的同时,提高了模型的识别精度。
3 基于多尺度特征融合的CNN模型
3.1 网络结构
为解决复杂卡口监控场景下车辆精细型号的识别问题 ,本文构建了一个基于多尺度特征融合的卷积神经网络模型(Multi-Scale feature fusion CNN,MS-CNN)。为便于阐述,下文中采用MS-CNN指代该网络模型。MS-CNN模型的总体结构如图1所示。从图1可以看出,MS-CNN包含一个输入层,4个特殊的结构单元(TraConv0,MlpConv1,MlpConv2和MlpConv3),以及两个全连接层fc1和fc2。以下将从前向传播过程,依次阐述MS-CNN各层的结构。

图1 MS-CNN网络结构示意图
表1列出了MS-CNN模型的网络结构参数。如表所示,输入MS-CNN模型的是卡口监控场景中的车辆正脸彩色图像,该图像变换为3×224×224的尺寸后,作为结构单元TraConv0的输入。表1中的C、H、W分别代表图像的通道数、高度和宽度。TraConv0保持了传统的卷积形式,依次包含一个卷积层、一个池化层和一个局部响应归一化(Local Response Normalization,LRN)层[11]。加入LRN层的主要目的是抑制隐藏层输出大的激励,从而提升模型的泛化能力。此外,在MS-CNN模型中,每个卷积层后都会紧随一个ReLU(Rectified Linear Unit)层[11],以增强网络的非线性拟合能力。

表1 MS-CNN网络结构参数
如图1所示,在TraConv0后依次创建了3个结构单元:MlpConv1、MlpConv2和MlpConv3。这3个单元有相同的结构,不同之处在于MlpConv1中的第一个卷积层的步长以及填充与后两者不同,因此下文以Mlp-Conv1为例阐述这种结构单元的组成和作用。
MlpConv1结构单元包含一个卷积核大小为3×3的卷积层conv1,后接两个卷积核大小为1×1的卷积层cccp1_1和cccp1_2,最后将隐含层结果经过最大池化后输出。这种结构借鉴了Lin等人在文献[12]提出的NIN(Network In Network)网络中一个非常重要的观点:使用形如MlpConv1的结构代替传统的卷积结构,有助于改善模型对非线性特征的表达能力。以ReLU[11]激活函数为例,一个传统的卷积层可按照公式(1)计算:

公式中,(i,j)是特征图的像素索引,xi,j是卷积窗口中的特征块,k是特征图的通道索引。而MlpConv1结构可以看作是一个卷积层加上传统的多层感知器(Multilayer Perceptron,MLP),其计算公式为:

公式(2)中,n是MLP中层的编号。结合公式(1)和公式(2),可看出,传统卷积层是通过使用非线性激活函数(如ReLU)的线性组合来产生特征图,而MLP卷积层中特征图 fn的计算依赖于 fn-1,从而实现多个特征图的线性组合,达到跨通道信息整合的目的。因此使用形如MlpConv1的结构代替传统的卷积层,使得网络实现跨通道信息整合,并提高非线性特征的提取能力。
在此基础上,本文依次堆叠了3个相似的MlpConv1单元。鉴于CNN层数越高视野域越大的特性,这样的堆叠方式既考虑了底层(靠近输入层)结构单元对车辆局部特征的学习,又兼顾了高层结构单元对车辆全局特征的提取,也为下文的特征融合提供了多尺度的特征选择。同时,由于这种堆叠结构中大量使用了1×1的卷积核,使得在增加网络深度的同时,有效降低了网络的参数量。
MS-CNN模型中另一个关键的结构是实现对特征的融合操作。如图1所示,全连接层fc1同时与MlpConv2结构单元的池化层pool2和MlpConv3结构单元的池化层pool3连接,并且将fc1的输出固定为一个160维的向量。这种设计的目的是因为随着下采样的逐步推进,pool3层含有的神经元个数太少,从而成为网络信息传递的瓶颈;另一方面,pool3层提取到的特征比pool2层具备更多的全局性特征,即越往后的卷积层具备越大的视野。因此这种特征的融合操作,既考虑了车辆局部的特征(pool2层),又兼顾了车辆全局的视野(pool3层)。在具体实现时,如表1所示,增加了一个concat层,用于拼接pool2和pool3层的输出,并与fc1全连接,使得每个图像最终学习到一个160维的特征向量。
最后将fc1层的输出送入Softmax层[8]进行分类,并给出各类别的概率值。此外,MS-CNN模型还在fc1层后插入一个dropout层[13],用以避免某些特征仅仅在与其他特定特征组合下才有效果的情况,从而提升防止模型过拟合的能力。
3.2 网络构建策略的分析
相对于其他经典卷积神经网络,本文在构建MS-CNN模型时力求在保证模型精度的同时使用最少的参数。基于这个思想,在上述网络构建过程中使用了以下设计策略。
3.2.1 减少大尺寸卷积核的使用
从理论上来讲,使用小尺寸卷积核更有利于压缩模型的规模,如使用1个3×3的卷积核所需要的参数量是1×1卷积核的9倍。因此在构建MS-CNN模型过程中,避免了使用像AlexNet模型中11×11的这种大尺寸卷积核。MS-CNN模型除了在网络开始阶段使用一个5×5的卷积核对样本进行特征的粗略提取外,其余都是3×3和1×1的小尺寸卷积核。
3.2.2 减少输入输出通道数量
对于一个使用卷积核大小为D×D的卷积层,在不考虑偏置的情况下,当前卷积层所有参数的数量可由公式(3)计算:

公式中,D是卷积核尺寸,C是输入通道数量,N是输出通道数量。由公式(3)可看出,模型压缩不仅需要减少大尺寸卷积核的使用,还需要减少当前层特征图的输入输出通道数量。因此,在MS-CNN模型构建过程中,合理设计了一系列相对偏小的通道数量,而不使用像NIN模型中1 024这种数量较大的输入输出通道数。
3.2.3跨通道信息整合
传统的CNN模型是卷积层和池化层交替堆叠,而在MS-CNN模型中,使用了MLP卷积结构,即一个3×3的卷积层后紧随两个1×1的卷积层的形式。在这种结构中,输入特征图经过3×3的卷积层后,延迟最大池化的操作,然后再使用1×1的卷积核实跨通道的信息整合。在结构的最后,才进行池化操作。这种结构能够使得模型对样本的非线性特征具有更好的表达能力。
上述3个策略中,前两个策略都是针对降低模型参数规模而设计的,第三个策略则是针对提升模型精度而提出的,再结合3.3节中对多尺度特征融合的分析,使得MS-CNN模型在保证模型精度的同时使用最少的参数。
3.3 多尺度特征的融合
实际卡口监控场景中,被拍摄到的车辆正脸图片除了车身轮廓外,还包含了车灯、车标、散热器格栅等丰富的局部特征,因此在提取车辆特征时,就需要兼顾车辆的局部特征和全局特征。如表1所示,pool2层的输出包含96个大小为6×6的特征图,将每个特征图转换为一维向量并按序拼接成一个3 456维的向量,记为向量A。同理,将pool3的输出拼接成一个1 152维的向量,记为向量B。然后将向量A和向量B再拼接后形成一个长为4 608的一维向量C,则该向量C即作为fc1层的输入。向量C经过fc1层后降维到160维,这个降维后的向量就是从样本中提取到的车辆的最终特征表示。
由于越高的卷积层具有越大的视野,因此提取自pool3的向量B比提取自pool2的向量A具有更全局性的车辆特征。考虑到相比车身的全局轮廓特征,车辆精细型号分类更应该关心车辆的局部特征提取,因此拼接后的向量C中提取自pool2的向量A具有更大的比重。这种全局特征和局部特征的融合,从不同尺度上尽可能地保留了车辆的特征信息,从而提高了网络的特征表达能力。
4 实验与分析
为了验证本文提出的基于多尺度特征融合的车辆精细型号识别方法的有效性,将文中提出的方法在公开数据集上进行了测试,并将测试结果与其他几种方法进行了对比。实验中使用Caffe[14]平台训练MS-CNN模型,训练过程中采用了带冲量的随机梯度下降法(Momentum SGD),其中初始学习率为0.001,衰减因子为0.000 5,冲量值为0.9。采用多分步(Multistep)策略更新学习率,实验最大迭代次数为250 000次,并分别在第150 000和200 000更新学习率。
4.1 平台与数据集
实验平台为一台8卡GPU服务器,配有2颗Intel XeonE5-2620 v2 2.1 GHz CPU及126 GB内存。GPU是NVIDIA Tesla K40 m,单精度峰值为4.29 Tflops,显存为12 GB GDDR5,显存带宽为288 GB/s。
实验采用了由香港中文大学提供的CompCars数据集[6]。CompCars数据集包括两类图片:一类是从互联网收集的车辆各个角度的图片;另一类是通过监控探头所捕获的车辆正脸图片。本文选择了后者作为实验的数据集,包括281个车辆精细型号的44 481张车辆正脸图像。实验中,根据Fang等人在文献[7]中的数据集切分方式,将数据集按7∶3的比例随机划分为训练集和测试集。CompCars数据集的特点是图像采集环境变化较大,覆盖了白天、黑夜、雨天和雾天等多种情况,其部分样本如图2所示。

图2 CompCars数据集样例
4.2 结果与分析
基于上述同一数据集,设计了几组对比实验,以验证本文所提出的方法的先进性。以下将从模型分类效率和分类准确率两方面来描述。
4.2.1 模型分类效率
表2对比了4种方法的模型参数大小和分类效率。其中,模型参数大小是在Caffe平台中训练得到的CNN模型大小,而分类效率指模型对一张图片进行分类的时间开销,也即是Caffe平台中每张图片在前向(Forward)计算过程中的平均用时。模型参数规模越小则其需要的内存开销也越小,模型分类效率越高则其实用性也越强。

表2 卷积神经网络模型参数大小
表2中,前三行是采用AlexNet[11]、NIN[12]和GoogLeNet[15]这3种经典的CNN模型对CompCars数据集进行分类的结果。从表中可以看出,本文所提出的MS-CNN模型对一张图片的前向计算只需0.83 ms。相对于表中另外3种CNN模型,其分类效率分别提高了2.80倍、3.80倍和9.52倍,同时模型参数大小仅为3.93 MB。因此,MS-CNN模型相对于表中另外2种CNN模型具有更小的模型参数规模和更高的分类效率。
4.2.2 模型分类准确率
为了验证本文提出的方法在车辆精细型号分类问题上的准确率,除了对比表2中3种经典的CNN模型的分类结果外,还引入了同样基于CompCars数据集的3篇文献中的识别结果,对比结果如表3所示。表中Acc1和Acc2分别表示两种不同的分类准确率。由于实验所采用的CompCars数据集中,各类样本数目很不均衡(类别样本数目平均为158张,而最少的类别仅有14张图片,最多的类别却有565张),因此如果只采用如公式(4)所示的传统准确率Acc1的计算方法就会忽略样本数量少的类别分类准确率差的情况。为避免这种情况,本文引入了Fang等人在文献[7]中提出的一种新的准确率Acc2。如公式(5)所示,Acc2等价于各类别准确率之和的算术平均值。

表3 分类准确率对比

其中,ti是第i类预测正确的样本个数,ni是第i类样本总数,N是样本的类别个数。
图3中展示了MS-CNN与3种经典CNN模型随着迭代次数的增加,分类准确率的变化情况。结合表3中的识别结果,可以看出,在3种经典CNN模型中GoogLeNet的识别结果最佳,其Acc1和Acc2分别达到了98.36%和97.83%。表中第4、5、6行是文献[16-17]和文献[7]同样基于CompCars监控数据集上所提出的方法的分类性能,其中第4、5行的实验结果是Fang等人在文献[7]中复现了文献[16-17]的实验结果。实验结果表明,文献[16]和文献[17]所提出的方法在CompCars上数据集上效果不佳。Fang等人在文献[7]中提出的方法取得了较高的准确率,Acc1达到了98.63%,Acc2达到了98.29%。综合表3的实验结果可看出,本文所提出的MS-CNN模型无论是Acc1还是Acc2都优于其他6种方法。
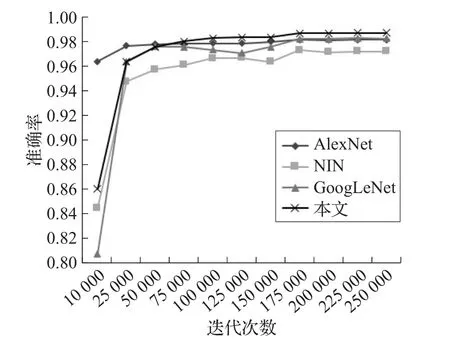
图3 分类准确率对比
结合表2和表3,进一步综合考虑模型分类效率和分类准确率两个方面。与3种经典CNN模型中准确率最高的GoogLeNet相比,MS-CNN模型的Acc1和Acc2分别提升了0.44%和0.60%,分类效率提高了9.55倍,且模型参数大小仅为GoogLeNet的1/12。此外,本文提出的端到端MS-CNN模型不同于表3中Fang等人在文献[7]中提出的方法,后者提出的方法需要单独训练一个SVM分类器来对提取出的车辆特征进行分类。因此相比文献[7]中的方法,端到端的MS-CNN模型不仅在准确率上有所提升,而且模型更为小巧简洁。
由于每个样本最后仅用一个160维的特征向量表示,因此即使MS-CNN模型中存在全连接层,也能够有效降低网络中的参数规模。此外MS-CNN中还大量采用了小尺寸卷积核,使得最终模型参数大小不到NIN[12]模型的1/6。同时,对车辆局部特征和全局特征的有效融合,增强了网络对车辆特征的表达能力,使得在网络参数规模大幅度降低的同时,模型的两种分类准确率均有所提高。
4.3 1×1卷积核数量影响网络性能的评估
MS-CNN模型中依次堆叠了3个相似的MlpConv1单元,虽然其在增加网络深度的同时,有效降低了网络的参数量,但过多的1×1卷积核数量可能会对模型分类精度造成影响。为对不同数量的1×1卷积核下的模型识别性能进行评估,本节分别对不同组合情况下的模型识别精度进行了测试,测试结果如表4所示。表中N_stack表示当前模型堆叠的MlpConv单元个数,N_kernel表示在当前模型的每个MlpConv单元中,3×3的卷积层后连接的1×1卷积层个数。特别的是,当N_kernel为0时,当前MlpConv单元可视为传统的卷积结构,即对3×3卷积层的输出直接进行池化操作。
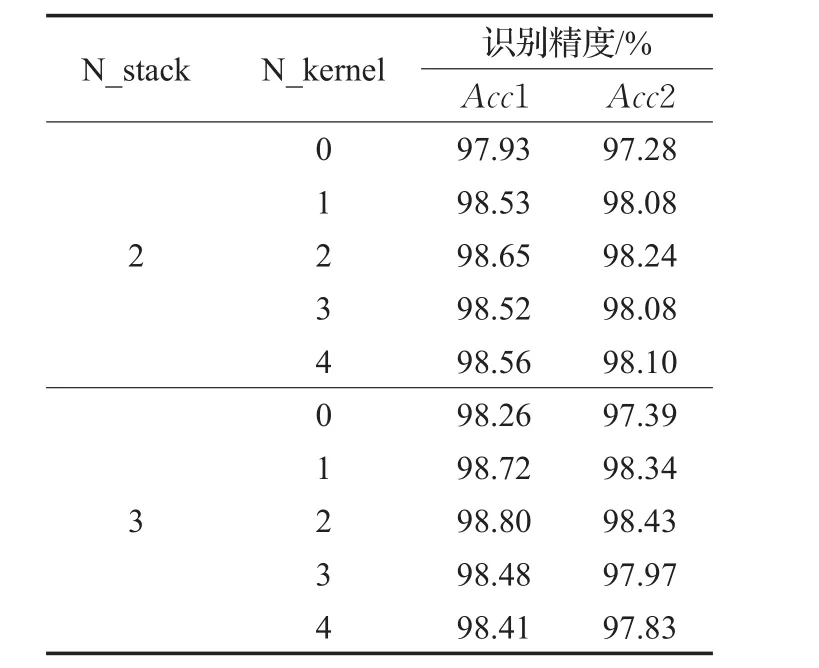
表4 不同的1×1卷积核数量的识别结果
在保持与各组对比实验无关条件不变的前提下,共设置10组对比实验,分为两大类。第一类是堆叠两个相似的MlpConv单元,第二类是堆叠3个相似的MlpConv单元。对于每一类,再分别对模型中每个MlpConv单元中1×1卷积核个数统一从0到4逐个实验,每类共计5组实验。实验中,fc1层的融合操作的输入来自靠近fc1层的两个MlpConv单元的池化层输出。
观察表4可发现,无论N_stack的值等于2还是3,一方面,模型准确率最低的情况都发生在N_kernel为0时,这也从侧面印证了前文中提出的“使用形如MlpConv1的结构代替传统的卷积结构,有助于改善模型对非线性特征的表达能力”的观点;另一方面,当N_kernel的值等于2时模型识别精度最佳,N_kernel的值大于2时,模型精度不升反降,说明过多的1×1的卷积核确实会对模型的精度造成影响。并且,当N_kernel为0、1、2时,相比堆叠两个MlpConv单元,3个单元的堆叠能够取得更高的识别精度。这说明,在一定程度上,增加网络的深度,有助于改善模型的识别准确率。最终,模型在堆叠3个MlpConv单元,每个单元包含两个1×1卷积层后取得了最佳的模型识别精度,这个模型即为本文所提出的MS-CNN模型。
4.4 网络特征可视化
为了进一步直观地说明本文提出的MS-CNN模型相对于其他方法的优势,本文使用t-SNE(t-distributed stochastic neighbor embedding)[18]方法对AlexNet、NIN、GoogLeNet以及MS-CNN模型基于CompCars相同测试集上所提取的特征降维到平面空间进而实现可视化,可视化结果如图4所示。实际可视化过程中,为便于观察,在CompCars测试集281类样本上随机选取了30个类别,每类40张样本(若同一类别样本量少于40,则全部取完)。CNN模型的最后一层通常用于给出各类别的概率值,因此实验中可视化的对象为该层的前一层所提取的特征。图中,一个小点代表一个样本,同一类别的样本聚集成簇。

图4 模型的特征可视化
图4 (a)中,各类所有样本点整体呈现一种聚类趋势,然而存在同类样本聚集成簇但比较松散的现象,即类内距离不够小,这说明了NIN对同类样本的聚合能力还有待提升;相比图4(a),图4(b)的类间间距更为明显,且同类样本的聚合能力也得到一定程度的改善;图4(c)是对GoogLeNet所提取特征的可视化结果,可以看出,相比前两种模型,GoogLeNet对同类样本点具有更强的聚合能力;而本文提出的MS-CNN模型所提取特征的可视化结果如图4(d)所示,对比NIN、AlexNet和GoogLeNet,MS-CNN类内样本点聚合程度更高,说明对属于同一类样本的识别能力更强;同时类间间距更大,意味着MS-CNN模型所提取的特征对不同类别具有更好的区分度。
5 结束语
针对卡口监控场景下的车辆精细型号识别的问题,本文提出一种基于多尺度特征融合的卷积神经网络MS-CNN。该方法对每个样本提取固定的160维特征向量,且该向量既考虑了车辆的局部特征又兼顾了车辆的全局特征。实验表明,MS-CNN模型在车型精细型号识别测试中分类准确率达到了98.43%。与其他方法相比,MS-CNN模型不仅在识别准确率上有所提高,而且模型参数规模大幅度降低到3.93 MB,平均每张图片的分类时间仅为0.83 ms,具有良好的实用价值。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
航天工业管理(2020年11期)2021-01-04
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年4期)2020-06-16
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
铁道通信信号(2016年8期)2016-06-01
