
软件测试质量评价方法
2018-09-17 04:32李军锋顾滨兵李海浩
计算机与现代化 2018年9期
李军锋,顾滨兵,李海浩
(中国人民解放军91404部队,河北 秦皇岛 066000)
0 引 言
软件测试作为提高软件质量的重要手段,测试质量与软件质量有着直接的关系,国内外测试质量评价的相关研究也提出了不少方法模型[1-2],但是没有给出明确、一致的定义[3-16]。软件测试质量评价,作为测试过程总结阶段的一项工作,本身需要快速、准确地得出结果,如果需要建立庞大的模型,进行大量度量元采集和计算[3-12],在可行性和资源成本[17]等方面往往会受到限制。因此需要一种度量采集简便、计算方法合理、实施过程可行、评价结果准确的软件测试质量评价方法。
1 测试质量评价的几个误区
1.1 将软件缺陷数量纳入测试质量评价
不少评价模型中,将测试过程中能够发现的软件缺陷数量作为测试质量评价标准之一,但这一点只适用于单独项目的评价,如果需要对不同项目之间进行测试质量评价对比,除非各个被测软件的规模、需求点及隐含的缺陷数等都完全相同,否则是不适用的。
软件缺陷的量级是衡量软件质量的,软件开发过程是否严谨规范,开发人员水平的高低,软件调试、自测试是否充分,这些都会直接影响最终提交测试的软件质量。
软件质量好,本身隐含缺陷极少,测试能够发现的缺陷也就越少,不能说明测试质量差;反之软件质量极差,在测试过程中缺陷频繁出现,也不能代表测试质量高。
1.2 将测试用例数量纳入测试质量评价
测试用例是指为特定目的而编写的一组测试输入、执行条件以及预期结果。这里的编写基本是通过自然语言描述,根据不同测试人员的个人习惯,会存在不同的语言描述粒度。仅以一个简单的输入框功能测试为例,软件需求是在输入A、B、C时应分别对应输出a、b、c,在设计正常的输入/输出测试用例时会出现2种极端情况:
1)1个测试用例:测试输入描述为“分别输入A、B、C”,预期输出为“分别对应输出a、b、c”;
2)3个测试用例:测试输入分别描述为“A、B、C”,预期输出分别为“a、b、c”。
以此为例,拓展至一个完整的软件,这类不同的设计描述习惯,虽然最终的测试效果相同,但用例数可能会相差数倍。很显然,测试用例数量不适合作为测试质量评价的标准之一。
2 本文提出的测试质量评价方法
通过对当前多种软件测试质量评价方法的研究,结合软件测试工作实践经验,提出如图1所示的软件测试质量评价模型[4-5,13],评价内容的选取原则为在保证结果相对合理的前提下,尽量易于获取,其中各评价标准对应的权重值的选择参考当前不同评价模型[4,13],并根据测试实践经验进行总结,在实际使用过程中,可在符合普遍标准的前提下进行适当调整,参评项目组达成一致即可。各评价标准的评价内容、取值范围及权重见表1。
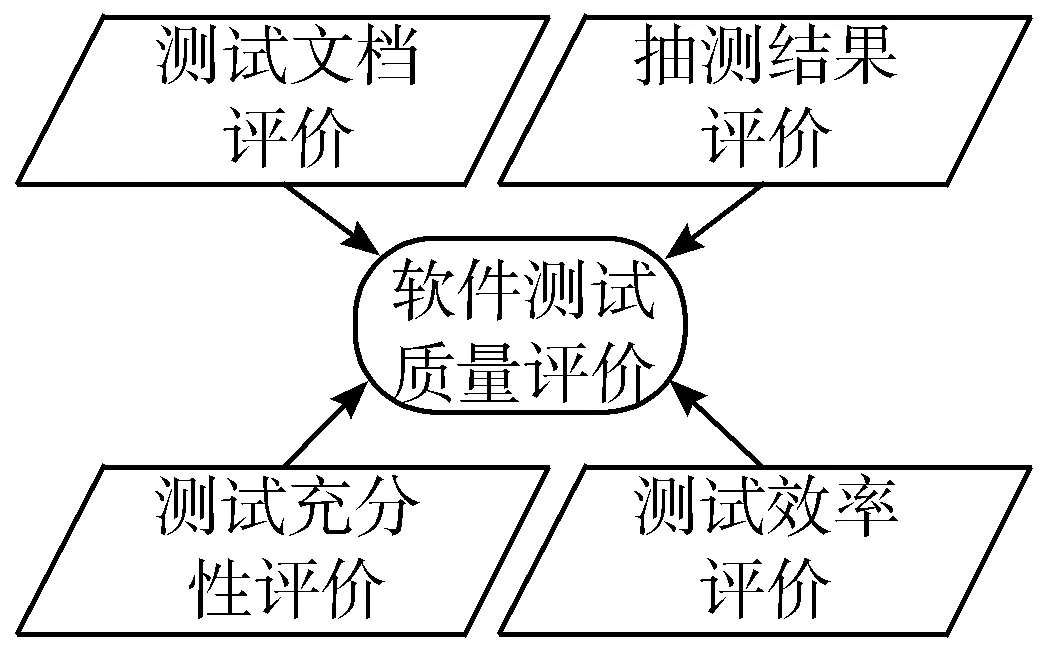
图1 软件测试质量评价模型
表1 软件测试质量评价
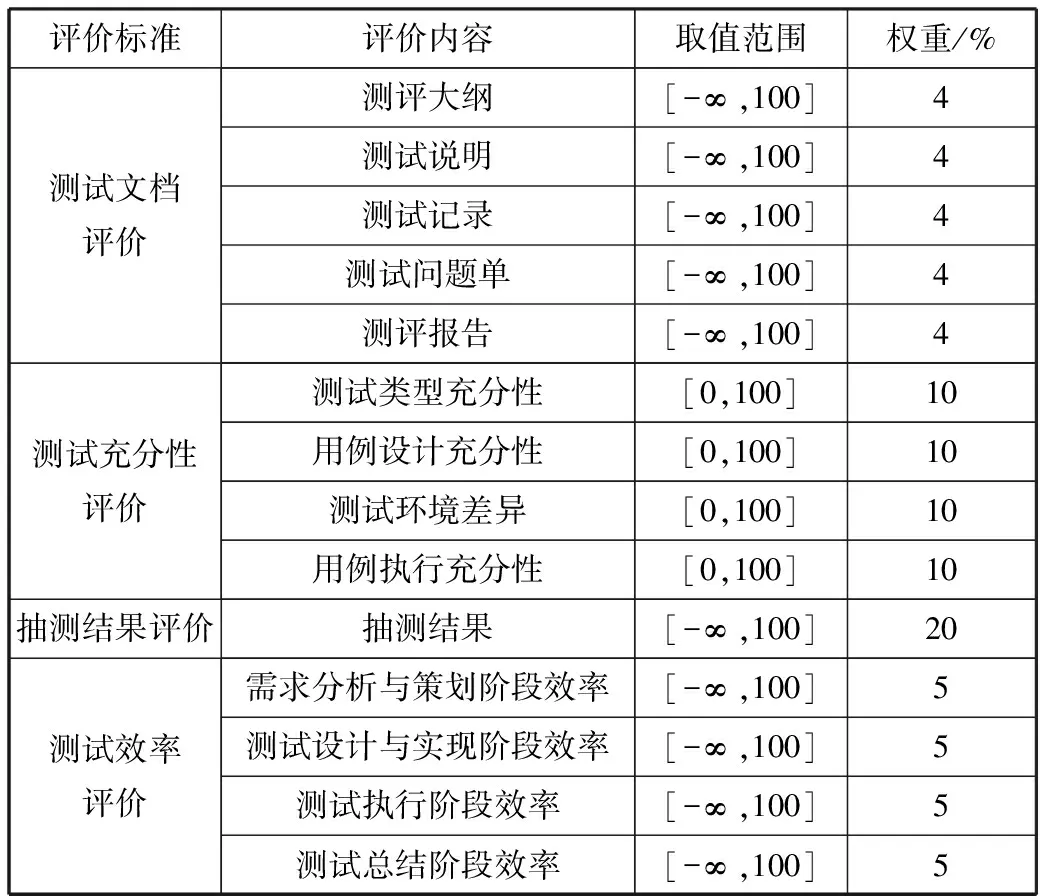
评价标准评价内容取值范围权重/%测试文档评价测评大纲[-∞,100]4测试说明[-∞,100]4测试记录[-∞,100]4测试问题单[-∞,100]4测评报告[-∞,100]4测试充分性评价测试类型充分性[0,100]10用例设计充分性[0,100]10测试环境差异[0,100]10用例执行充分性[0,100]10抽测结果评价抽测结果[-∞,100]20测试效率评价需求分析与策划阶段效率[-∞,100]5测试设计与实现阶段效率[-∞,100]5测试执行阶段效率[-∞,100]5测试总结阶段效率[-∞,100]5
2.1 测试文档评价
测试文档评价(DQ),主要是指对测评大纲、测试说明、测试记录、测试问题单及测评报告共5类测试文档工作产品,依据评审会及测试质量评价组织的审查提出的文档问题进行评价,问题级别定义见表2,各问题的分值据实际经验而来,计算方式如下:
测试文档评价=100-(致命问题×100+严重问题×10+一般问题×3+轻微问题)
表2 测试文档问题级别定义
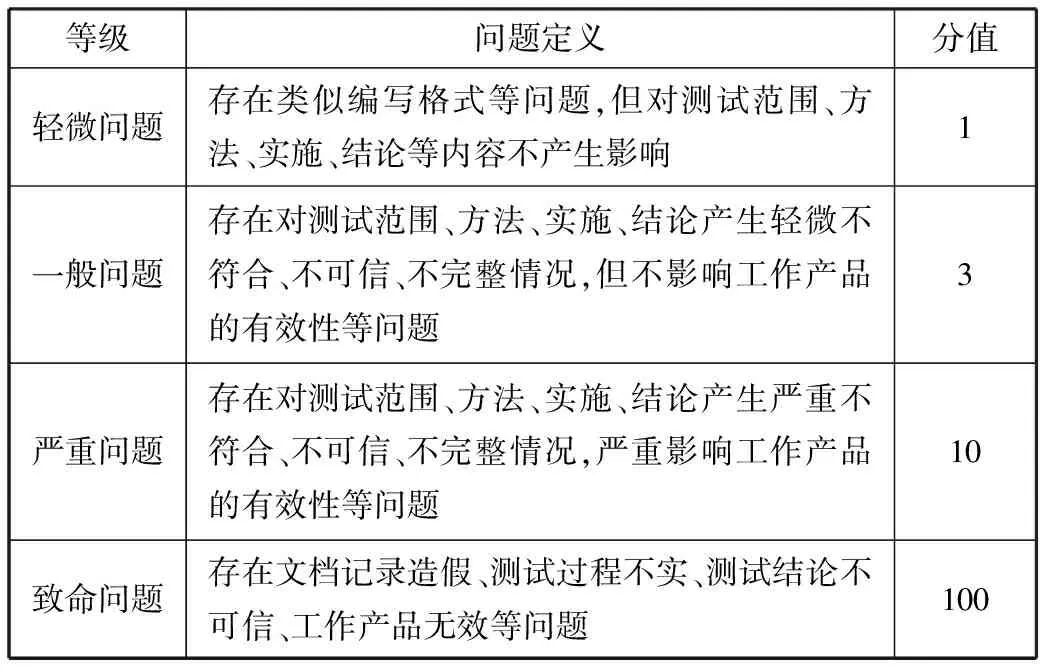
等级问题定义分值轻微问题存在类似编写格式等问题,但对测试范围、方法、实施、结论等内容不产生影响1一般问题存在对测试范围、方法、实施、结论产生轻微不符合、不可信、不完整情况,但不影响工作产品的有效性等问题3严重问题存在对测试范围、方法、实施、结论产生严重不符合、不可信、不完整情况,严重影响工作产品的有效性等问题10致命问题存在文档记录造假、测试过程不实、测试结论不可信、工作产品无效等问题100
定义评价对象集合,测试文档={测评大纲,测试说明,测试记录,测试问题单,测评报告},即D={d1, d2, d3, d4, d5},可计算出测试文档评价:
DQ=(d1+d2+d3+d4+d5)×4%
2.2 测试充分性评价
测试充分性评价(AQ)的内容包括测试类型、用例设计、测试环境建立及用例执行4个方面。
1)测试类型充分性。
测试类型的选取通常主要依据软件的等级、测试级别及测试委托方要求,根据软件需求本身可进行相应裁剪。测试对象明确后,测试类型的基准值相应地就可以确定。
已选取测试类型覆盖或多于应选取测试类型时,可认为测试类型充分性为100。
已选取测试类型少于应选取测试类型时,在认为各类型的权重相同的情况下,可进行如下计算:
测试类型充分性=
2)用例设计充分性。
测试用例充分性主要考核用例设计是否覆盖软件所有需求的功能点、是否覆盖异常情况、是否覆盖边界情况,计算方式如下:
测试设计充分性=100-(未覆盖功能点×2+未覆盖异常情况×2+未覆盖边界值情况)
功能点是指广义的功能,含功能、性能、接口、安全性等所有软件需求。
3)测试环境差异。
测试环境充分性主要是从搭建的环境是否与软件运行实际环境一致,环境差异在采取弥补措施后是否仍会影响测试结果的角度考虑,计算方式如下:
测试环境充分性=
4)用例执行充分性。
未执行用例数与数量庞大的总设计用例数进行单纯的比较得出的结果,并不能直接反映测试的充分性,这里选取“未执行测试用例涉及的功能点”作为评价内容,计算方式如下:
用例执行充分性=
5)测试充分性评价[14]。
定义评价内容集合,测试充分性={测试类型充分性,用例设计充分性,测试环境充分性,用例执行充分性},即A={a1, a2, a3, a4},可计算得出测试充分性评价:
AQ=(a1+a2+a3+a4)×10%
2.3 抽测结果评价
抽测结果评价(RQ)主要是从抽测考核的角度,由专家组主要结合自身工作经验采用猜错法,对软件部分主要需求指标进行抽选并重新测试,再次确认是否存在未发现的软件问题,用例的选择具有主观性,但需覆盖软件重要功能、工作流程及技术指标等,通过抽测发现的问题数量、级别加权、抽测问题系数计算评价结果,问题级别参见统一行业的标准。
抽测结果(R)=100-(致命问题×100+严重问题×10+一般问题×3+轻微问题)×抽测问题系数
依据评价标准权重,可计算得出抽测结果评价:
RQ=R×20%
2.4 测试效率评价[13]
实践经验表明,测试的时间越长,发现的缺陷就会越多,软件的质量也就越好。经过测试的各个阶段后,会发现软件的大部分缺陷,在测试结束后软件交付使用的过程中,随着时间的推移和用户对软件的频繁使用,仍旧会不断发现软件缺陷。理论上只要有足够的时间,就能不断趋近于发现软件的所有缺陷,软件的质量将趋近于完美。
但这样的测试过程并不是高质量的测试,人们常说的测试工作作为软件生命周期的一部分,无论是从项目管理角度还是实际的实施过程考虑,终归是有时间限制的。这就不得不将测试效率纳入测试质量评价标准。
测试效率评价(EQ)基准值的来源为软件测评大纲的进度安排,要求在大纲评审时需要慎重考虑工作量、软件状态、测试环境、管理成本等多方面因素制定合理的进度计划,以便对需求分析与策划、测试设计与实现、测试执行及测试总结4个阶段的效率进行评价,计算方式如下:
1)当实际完成阶段工作的时间≤计划完成阶段工作的时间,可直接给出该阶段测试效率评价结果=100。
2)当实际完成阶段工作的时间>计划完成阶段工作的时间,计算方式如下:
阶段测试效率评价=
这里需要注意,测试进度计划的制定仅考虑有效测试工作量,以工作日/人为单位,不包括软件问题整改周期等不可控因素。
3)当实际时间超过计划时间2倍时,阶段测试效率评价会出现负值,同测试文档评价标准负值一样,正常纳入最终的测试质量评价结果计算。
定义评价内容集合,测试阶段效率={需求分析与策划阶段效率,测试设计与实现阶段效率,测试执行阶段效率,测试总结阶段效率},即E={e1, e2, e3, e4},可计算出测试效率评价:
EQ=(e1+e2+e3+e4)×5%
2.5 测试质量评价
根据以上评价标准、内容及方法定义,得到测试质量评价(TQ)结果:
TQ=DQ+AQ+RQ+EQ
以2个软件测试项目A、B为例进行示意验证,比如通过各项评价内容采集计算分别得到如表3所示的评价结果。
项目A测试质量评价总分为69.3,根据具体评价结果来看,在“抽测结果评价”过程中因发现的软件问题较多导致评价结果为0分,同时“测试执行阶段效率”因实际工作时间超出计划工作时间50%,导致该阶段测试效率评价为50分,在测试效果和效率上均不够理想。项目B测试质量评价总分为91.2,从评价结果来看,各项评价内容得分确实均较高。综上,这种方法得到的评价结果能够相对合理地体现出各软件测试项目之间测试质量的差别。
表3 项目A、B测试质量评价结果
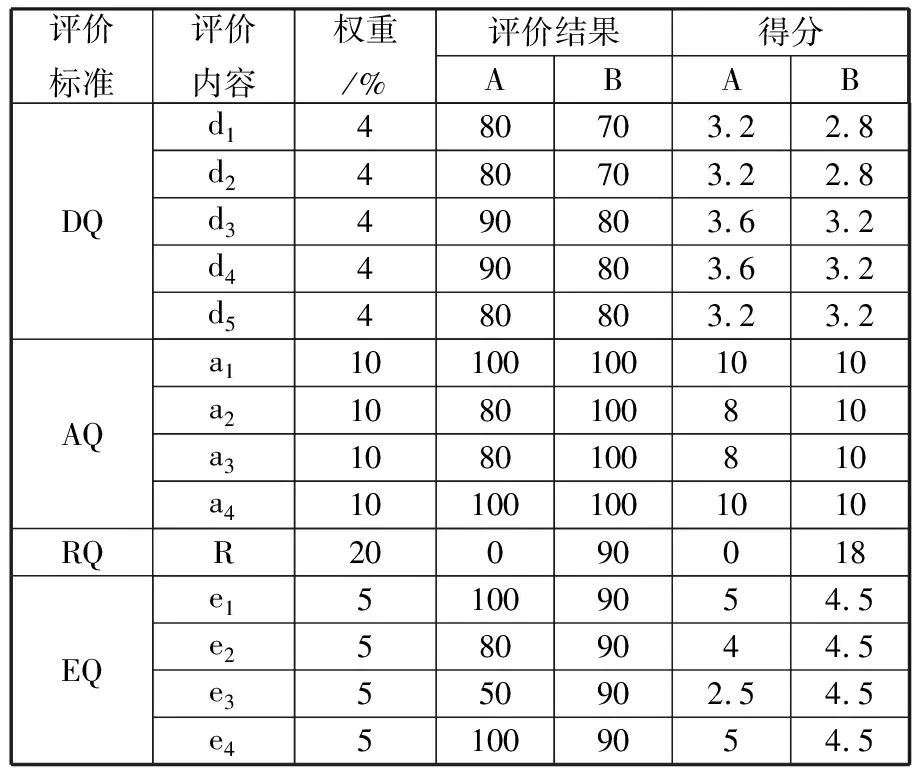
评价标准评价内容权重/%评价结果得分ABABDQd1480703.22.8d2480703.22.8d3490803.63.2d4490803.63.2d5480803.23.2AQa1101001001010a21080100810a31080100810a4101001001010RQR20090018EQe151009054.5e25809044.5e3550902.54.5e451009054.5
但很明显,以上评价结果还存在一个问题,即某一项评价内容得分过低甚至为0或者负数时,受权重计算方式的影响,最后的测试质量评价结果仍可能是较高的分值,导致评价结果不能完全准确地反映测试的质量。所以最后还需要再增加一个附加条件,如果某一单项评价结果<60分,则要求测试项目组整改相应问题或进行解释,并由测试质量评价组进行补充检查,将首次评价及补充整改情况一并纳入评价结论。
3 结束语
本文提出的软件测试质量评价方法,在大幅简化评价过程的同时,能够得到合理的评价结论。以促进软件测试质量的提升为目标,可以与测评机构内部质量管理体系相结合,对各项目测试情况进行打分评价;也可以在多家测评机构联合完成大规模软件测试项目后,作为不同测评机构间软件测试质量比对的主要依据。本文方法还需要进一步研究,重点将在如何使各项评价内容取值的权重更加科学合理,进一步规范后可制定一定范围内的评价标准。
猜你喜欢
科学与信息化(2021年15期)2021-12-30
科学与信息化(2021年12期)2021-12-27
扬州大学学报(自然科学版)(2020年2期)2020-09-08
计算机教育(2020年5期)2020-07-24
软件(2020年3期)2020-04-20
铁道通信信号(2019年11期)2019-05-21
数理医药学杂志(2019年3期)2019-03-13
出土文献与古文字研究(2018年0期)2018-11-04
电子制作(2018年16期)2018-09-26
成长·读写月刊(2017年7期)2017-07-13
