
基于CTC模型的无分割文本验证码识别
2018-09-17 04:32周武能
计算机与现代化 2018年9期
杜 薇,周武能
(东华大学信息科学与技术学院,上海 201620)
0 引 言
防止不必要的机器访问Web服务,保证网站资源使用的公平性和服务提供方的盈利性,通过自动公共测试来区分计算机和人类,验证码系统被广泛使用[1]。现在验证码的安全性已经成为网络安全应用的焦点。主流文本验证码的特点总结如下:
1)由0~9阿拉伯数字和26个英文字母组成;
2)验证码长度4位到6位,随机生成;
3)随机生成干扰项点和横线;
4)字体使用统一字体,大小和扭曲角度在设置范围内随机生成;
5)随机设置字体颜色和背景颜色。
验证码一般分为传统验证码、点选验证码、滑动验证码和智能验证码。还有一些借助辅助设备验证码,比如语音验证码[2]、短信回执验证码等。传统验证码也称文本验证码,是目前运用最广泛的验证码方式。文本验证码用户接受度高,但是安全系数低[3]。
为增强网站的安全系数,现在的验证码中加了很多噪声等干扰因素。文本验证码抗机器识别的主要方式是加入典型扭曲的应用[4],以及多颜色、多纹理背景、重叠字母[5]、变形字体[6]等应用。文本识别通常涉及2个步骤:字符分割和字符识别[7-14],文本验证码识别是文本识别的一种,通常验证码识别流程分为4个步骤,如图1实线所示。字符分割有很明显的弊端,如在文字重叠度高且文字结构不规范时分割难度较大,导致识别不准确等。
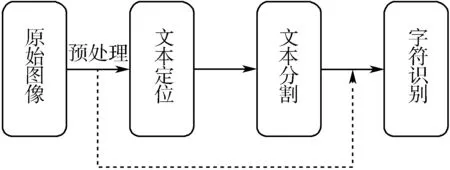
图1 验证码识别过程
随着深度学习的发展,基于卷积神经网络(Convolutional Neural Networks, CNN)的分类器在ICDAR 2013比赛中表现出优越的性能[15],在图像识别中CNN的精度远高于传统分类器。Zhang等人[16]将传统的归一化协作方向分解特征图与深度CNN相结合获得了最高的精度。但当数据集较小时,CNN在图像识别领域中性能受到影响。
针对上述现有验证码识别模型的缺点,本文提出的模型可以在较小的训练集、无文本分割的情况下达到较高的验证码识别精度。
1 模型介绍
1.1 LSTM
长短期记忆(Long Short-Term Memory, LSTM)网络由Hochreiter & Schmidhuber于1997年提出,并在近期被Alex Graves[17]进行了改良和推广,解决了RNN (Recurrent Neural Network)梯度消失问题。与传统RNN相比,LSTM的主要区别在于LSTM中的递归连接是线性的。LSTM通过设计一个cell来避免长期以来的问题,一个cell当中被放置了3扇门,分别叫做输入门、遗忘门和输出门。LSTM把隐藏层单元内部结构复杂精细化[18]。通过这种方式,模型可以学习长时间的依赖关系。LSTM结构如图2所示。
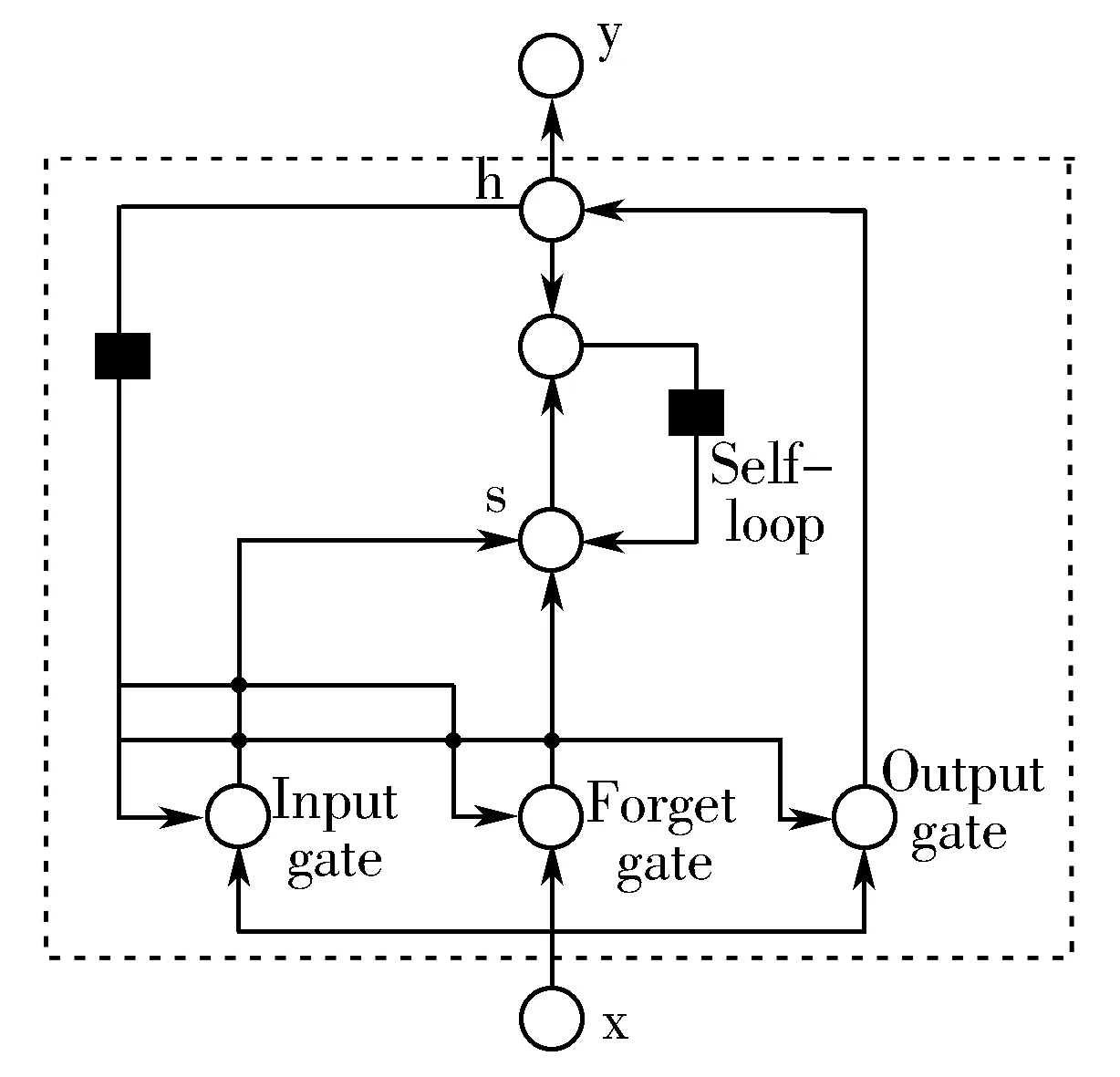
图2 LSTM结构
从图2可以看出,LSTM的自循环结构状态s由当前时刻遗忘门f和输入门i控制,遗忘门f用来确定是否重置存储的存储器,设置遗忘门有助于RNN记住上下文信息,并在学习过程中撤回错误。输入门i、遗忘门f和输出门o的结构类似,都与当前时刻输入x与LSTM结构的cell输出h有关。
1.2 CTC
CTC(Connectionist Temporal Classification)模型接在RNN网络的最后一层用于序列学习。CTC主要的优点是可以对没有对齐的数据进行自动对齐,主要用在没有事先对齐的序列化数据训练上。特点是增加的“空白”输出标签被添加到RNN输出层,它的作用是减轻网络预测不确定标签的压力,较好地解决2个单元之间的混淆性。
训练样本可以被视为输入列特征和目标字串(C, W), CTC的目标函数定义如下[19]:
ο=-∑(C,W)∈Sln p(W|C)
(1)
其中S表示整个训练集,p(W|C)表示在输入列特征的条件下得到目标字串W的概率,其定义如下:
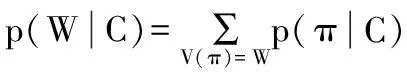
(2)
其中V表示将输出路径π转换为目标字串W的运算符,p(π|C)是指给定输入序列C的输出路径为π的条件概率,其定义如下:
(3)
其中L表示输出路径的长度,πt表示在t时刻的输出路径π, yt表示在时刻t的RNN的网络输出。
使用LSTM+CTC的模型识别验证码图片,将单词图像转换为用于验证码识别的顺序信号,把图片看成是列特征向量组成的有空间顺序并且内容相关联的集合。这避免了对训练数据预先分隔以及输出后处理的要求,仅采用一个单独的网络架构对序列的全部方面进行建模,在数据集较小的情况下,能够准确地识别验证码。
2 验证码识别模型构建
为最大限度利用已有的有限数据集,就需要充分利用图像内上下文关系。CTC模型在上下文关系紧密的语音识别中有着优秀的识别性能[17],而循环神经网络RNN识别结果不仅根据当前状态,还与过去的状态有关,可以用于处理序列数据。所以本文提出循环神经网络结合CTC模型识别验证码的方法,利用上下文强关系可以省去文本定位和文本分割环节,如图1虚线所示。
整个模型由3个部分组成,如图3所示。
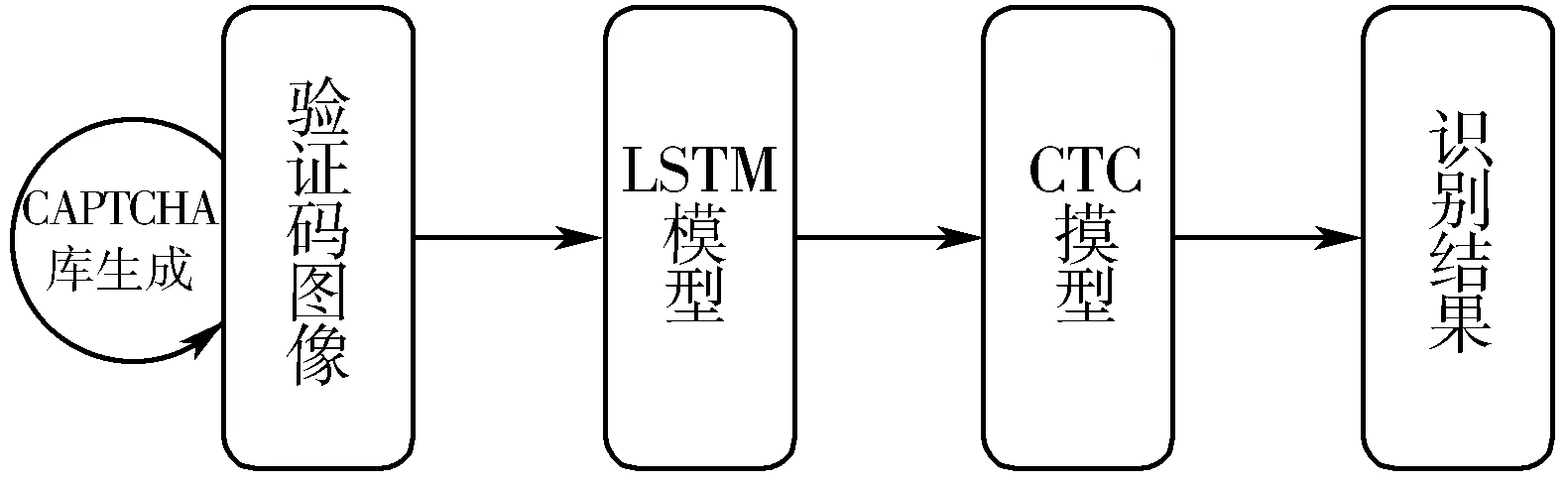
图3 验证码识别模型构成
本文提出的模型有如下4个特点。
1)简化了验证码识别常用模型,统一了语音识别和文本识别方法,实现端到端模型识别。
2)提出的验证码识别模型对验证码长度无限制,更符合现有的网站验证码图片特点。
3)加入CTC之后,本文提出的模型对那些难以分割字符的验证码图片有很高的识别精度,简化了现在用来识别验证码的主流模型。
4)模型在训练集较小的情况下,能保持较高的识别精度。
3 实验和结果分析
3.1 实验设置
本文的实验环境主要参数:CPU为Intel(R) Core(TM) i5-4200U CPU @ 1.60 GHz & 2.30 GHz,操作系统为Windows10 64位,基于x64的处理器。在TensorFlow上搭建LSTM和CTC模型,TensorFlow是一个开源的深度学习框架,提供了非常丰富的深度学习相关的API。
因为验证码识别没有公开的数据集,本文利用开源的Python版的CAPTCHA库生成如图4所示的数据集:数据集1包括训练集10000张图片,验证集1000张图片;数据集2包括训练集1000张图片,验证集100张图片;数据集3包括训练集100张图片,验证集30张图片。生成的验证码样本示例如图4所示。

图4 验证码样本示例
在深度学习的过程中,优化方法选择RMSProp,这种方法很好地解决了深度学习中过早结束的问题,适合处理非平稳目标,对于RNN效果很好。具体实现时需要的参数设置为:全局学习速率=1e-3,衰减速率ρ=0.93。验证码图片设置image_width=120, image_height=45。LSTM神经网络设计为2层,每层有128个隐藏层。
在性能评估中,本文提出的方法是根据字符串识别精度进行评估,定义如下:
(4)
3.2 实验设计及结果分析
为验证本文提出的模型的优越性,分别选择了在图像识别领域应用比较广泛的CNN的方法、LSTM方法与本文提出的方法进行验证码识别。图5为3种不同数据集的实验结果,每15次迭代记录一次识别结果,纵坐标为识别精度(acc)。本文提出的方法在横坐标为30次时结果趋于稳定,取出实验结果与其他识别方法进行比较,比较结果如表1所示。从表1可以看出,数据集1中识别精度方面CNN>LSTM+CTC>LSTM,在单个样本识别时间方面LSTM+CTC>CNN>LSTM,可以得出结论,数据集较大时,CNN识别精度最高计算成本居中,CTC模型需要耗费较多的时间。在数据集2和数据集3中识别精度方面LSTM+CTC>LSTM>CNN,在单个样本识别时间方面LSTM+CTC>LSTM>CNN,但相差不大,可以得出结论,数据集较小时,LSTM+CTC方法能更准确识别出验证码,LSTM方法次之,弥补了CNN的不足,并且三者计算成本上差距逐渐缩小。
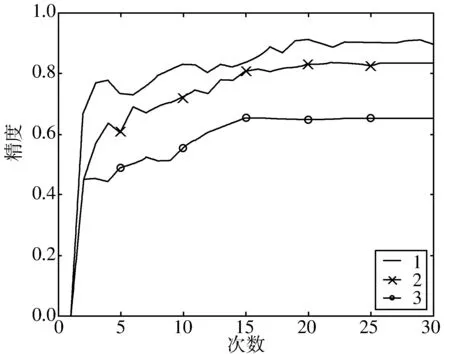
图5 不同数据集实验结果
表1 实验结果比较

识别方法识别精度acc/%单个样本识别时间/s数据集1数据集2数据集3数据集1数据集2数据集3CNN94.678.553.31.0421.1311.275LSTM89.183.456.61.0361.1721.277LSTM+CTC93.483.563.31.2621.2011.310
综上,LSTM+CTC方法在小数据集上有着优秀的性能,虽然CTC需要消耗一定的计算成本,但是其较高的识别精度使得数据库不充足时,依然可以识别出文本内容。
4 结束语
本文针对小数据集,根据目前文本验证码的特点,设计了LSTM+CTC模型的验证码识别系统,该系统能在数据不充足的情况下获得高识别精度,同时模型变得更加简洁,使语音识别和文本识别等模块都融为一体。然而,CTC在识别验证码时需要的时间较长,可以尝试对图像进行一些能提取特征的预处理以减少识别的时间。
最后通过本文的实验论证,说明在验证码安全性方面,扭曲、透明度高和噪声多等特点已经不能保证网站安全,应通过其它和用户互动的方式来提高验证码的安全性能。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
一重技术(2021年5期)2022-01-18
艺术评论(2020年3期)2020-02-06
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
制造技术与机床(2019年10期)2019-10-26
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年18期)2018-11-14
电子制作(2018年11期)2018-08-04
Coco薇(2016年2期)2016-03-22
Coco薇(2015年1期)2015-08-13
