
基于多粒度特征表示的知识图谱问答
2018-09-17 04:32黄廷磊
计算机与现代化 2018年9期
申 存,黄廷磊,梁 霄
(1.中国科学院大学电子电气与通信工程学院,北京 100049; 2.中国科学院电子学研究所,北京 100190; 3.中国科学院空间信息处理与应用系统技术重点实验室,北京 100190)
0 引 言
开放域知识图谱问答是一项具有挑战性的任务,其旨在结合知识图谱为自然语言问题提供相应的答案。近年来,大规模的高质量知识图谱发展迅速,并在许多领域得到了广泛的应用,典型的包括如Freebase[1]、DBpedia[2]等英文知识图谱以及Zhishi.me[3]、XLore[4]等中文知识图谱。由于知识的结构化形式,知识图谱已经成为开放领域问答的重要资源,越来越多的研究工作也集中在知识图谱问答上[5-6]。对于知识图谱问答,其主要挑战是对问句的语义理解,因为给定的问句是自然语言的形式,而知识图谱是结构化的信息存储,两者的表述存在差异,需要对问句和知识图谱的文本进行深入的语义关联,以从知识图谱中选取出与问句表述最为匹配的三元组作为候选答案。例如给定问句“你知道哈姆雷特是哪个国家的电影吗?”,首先需要从知识图谱中确定问句所包含的主题实体“哈姆雷特(1964年美国电影)”,然后从实体的属性中选出与表述“是哪个国家的电影”最为相关的属性“制片地区”以得到三元组“哈姆雷特(1964年美国电影)|||制片地区|||美国”。该过程主要包含2部分工作:实体抽取以及属性选择。
实体抽取主要是从问句中识别出实体提及并链接至知识图谱的过程。目前传统的研究主要通过搜索知识图谱中每个问句的n元语法(n-gram)来实现实体抽取[8-9],这种方法通常需要较大的搜索空间。Berant等人[5]使用语言学工具来完成实体抽取工作,而通常语言学工具依赖于逻辑表达式以及预定义规则,不具有广泛的适应性。
属性选择则是在抽取出问句的实体之后,从实体的所有属性中选取出与问句描述最为匹配的属性,并将属性值作为候选答案。这一任务的难点在于自然语言问句的表述与属性的文本表述存在差异性,如何有效地将两者关联并选出置信度最高的属性直接影响到结果的准确率。在相关工作中,深度学习的方法正逐渐应用于知识图谱问答的属性选择中。Yih等人[10]利用卷积神经网络(Convolutional Neural Network, CNN)对问句和属性进行字符级别三元语法的建模。Golub等人[9]将关系和问句作为字符序列进行处理并提出基于注意力的长短期记忆(Long Short-Term Memory, LSTM)网络的方法。Yin等人[11]采用注意力池化方法来学习属性的嵌入表示。这些属性选择方法都利用神经网络分别学习问句和属性的向量表示,然后计算向量之间的相似度作为其语义相似度。这些方法在实验中仅使用词级别嵌入,没有充分利用实验数据的语义信息。且与英文知识图谱问答不同的是,在中文里单个汉字通常也含有特定的语义,因此可以考虑结合字符级别的嵌入进行属性选择的实验。
针对上述问题,在实体抽取任务中,本文采用双向长短期记忆条件随机场(Bi-LSTM-CRF)模型来进行实体识别,取得了较高的链接至知识图谱的准确性。对于属性选择任务,本文采用结合字符级别、词级别以及属性级别的文本嵌入的多粒度方法,充分利用图谱的可用信息,并与其他模型方法进行对比,以验证方法的有效性。
1 相关工作
基于知识图谱的问答在自然语言处理领域拥有很长的研究历史。早在20世纪60年代,就有研究人员针对领域内小规模知识库进行问答系统的研究以回答领域内的一些专业问答。早期的研究主要采用语义解析(Semantic Parsing)的方法[5,10,12],其主要思想是按照特定的文法,将自然语言问句转化为等价的逻辑表达式,以完成对知识库的查询。除此之外,信息检索方法[6,8,13]也常用于知识图谱问答,与语义解析不同的是,它将问句转化为了检索问题。该方法从知识图谱中搜索问句中涉及的所有相关信息,并构建排序算法从候选答案中选择最佳候选答案。相比于语义解析,其优点是不必手动设计词汇表且领域迁移能力较强。Bordes等人[8]的结果表明,信息检索方法在问答结果中也有着较好的表现。
近年来,随着人工智能的发展,神经网络的方法也开始应用于知识图谱问答,并取得了相比于传统方法更好的实验结果。在实体抽取中,Bordes等人[8]和Golub等人[9]搜索给定问题的所有n元语法单词,然后链接到知识图谱。Berant等人[5]使用语言学工具,其很大程度上依赖于逻辑表达式和预定义规则。Dai等人[14]将中心实体映射回问句文本作为标注数据,并构建双向门控循环单元条件随机场(Bi-GRU-CRF)序列标注模型以进行实体识别。Yin等人[11]则采用Bi-LSTM-CRF序列标注模型来提高该方法的性能。对于属性选择任务,Bordes等人[15]首先采用深度学习方法并取得了较好的实验结果,之后各种基于深度学习的模型也逐渐涌现出来。这些方法大都是将给定问题和候选关系分别映射到向量,然后计算向量之间的相似度作为它们的语义相似度。在Dai等人[14]的研究中,属性被视为整体的符号,并采用TransE[16]学习的预训练向量初始化。文献[9]采用了字符级别表示法,以减小参数的大小并提高处理未登录词的鲁棒性,而Yin等人[11]则提出了注意力机制的最大池化的CNN模型。
2 基本框架
2.1 问题定义与建模
给定目标问句,实体抽取的目的是找到实体提及并正确链接至知识图谱,从而得到主题实体和候选属性Cp={prop1,prop2,…,propn}。属性选择的目的是识别问句中表述的属性,即找到与问句中除主题实体以外的文本描述最相符的实体属性。通常将属性选择任务考虑为排序问题,对于问句q候选属性集合Cp中的每个属性p,模型计算其与问题S(q,p)的语义相似度,并且选择置信度最高的属性作为候选,有:
p+=arg max S(q,p)
(1)
2.2 知识图谱问答流程
对于中文知识图谱问答,其流程如图1所示,主要包括以下几个步骤:1)对知识图谱进行规范化处理,主要包括删除三元组中属性之间的空格、前缀以及后缀,对于某些属性和属性值相同的无效三元组,直接删除该条记录;2)对问句进行主题实体的识别,并利用规范化的知识图谱进行实体链接;3)检索知识图谱得到链接实体的所有候选属性,并利用设计的属性选择模型进行比较排序,选出置信度最高的候选属性,得到预测答案。
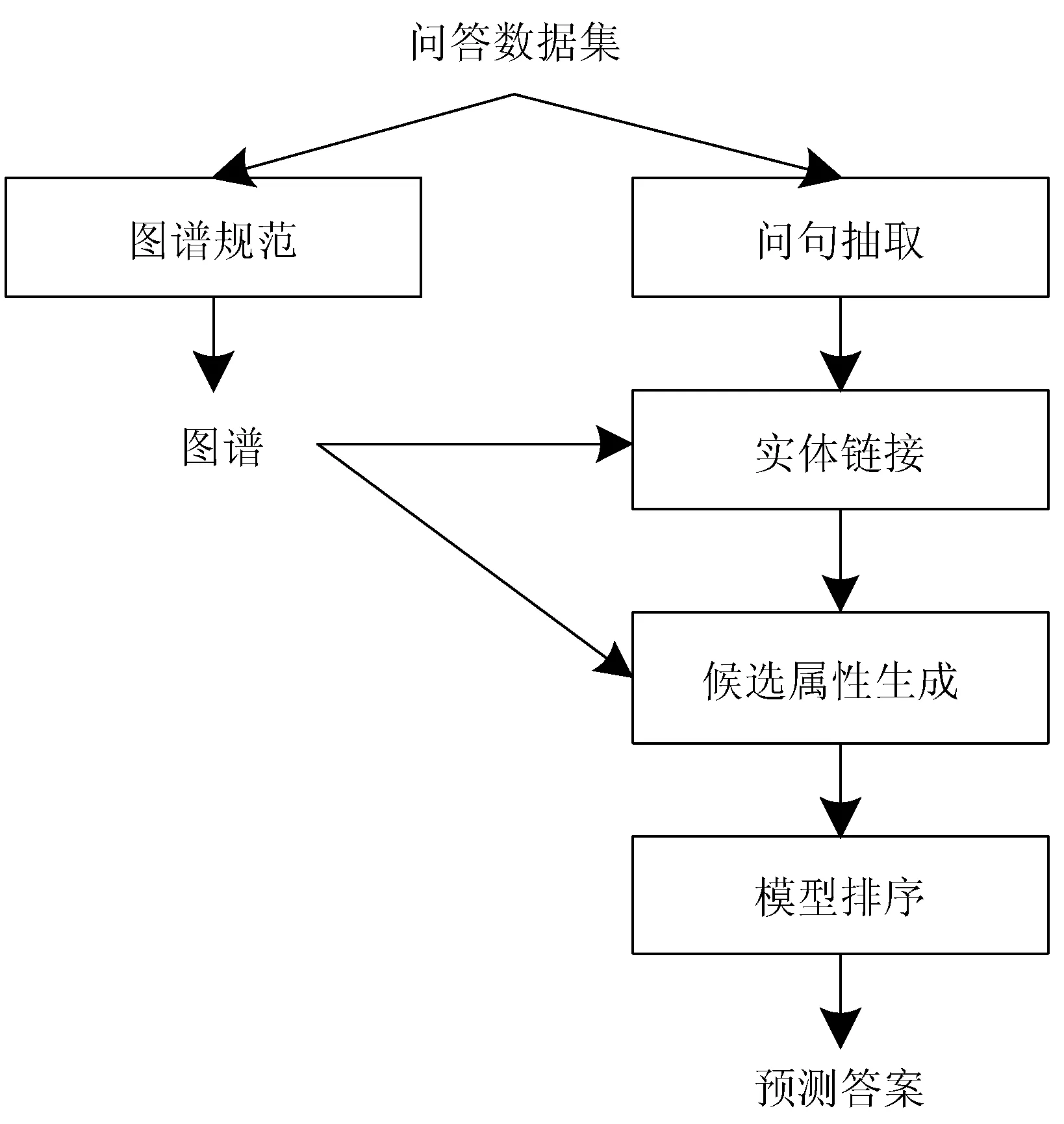
图1 知识图谱问答流程图
3 实体链接模型
对于实体抽取模型,其主要难点是识别问句中的主题实体,以便进一步链接至知识图谱,检索相应候选属性,以确定最终答案。笔者发现该任务与命名实体识别任务有着很大的共同点,因此本文采用由Bi-LSTM和CRF模型组成的Bi-LSTM-CRF模型[17]。基本思想是使用LSTM层来考虑先前的输入特征并从CRF层获得句子级别标签信息。因此,输出是一个最佳的标签序列,而不是相互独立的标签。
形式上,输入一个问句序列X={X1,X2,…,Xn}, y={y1,y2,…,yn}表示X的标签序列,Pn×k表示概率矩阵,其中k是标签类型的数量。最佳标签序列可通过最大化如下目标函数来获得。
(2)
其中Pi,j是第i个单词被标记为第j个标签的概率,A是状态转移矩阵,其中元素Ai,j是从第i个标签转移到第j个标签的概率。
整体实体抽取模型如图2所示。问句以字序列文本嵌入,并与额外的特征连接作为循环层的输入。本文采用代表文字边界特征的一个热点向量来进行说明。循环层为双向LSTM,其将前向和后向隐层表示的输出连接并投影到每个标签以计算得分,CRF层主要用于解决参数偏倚问题。
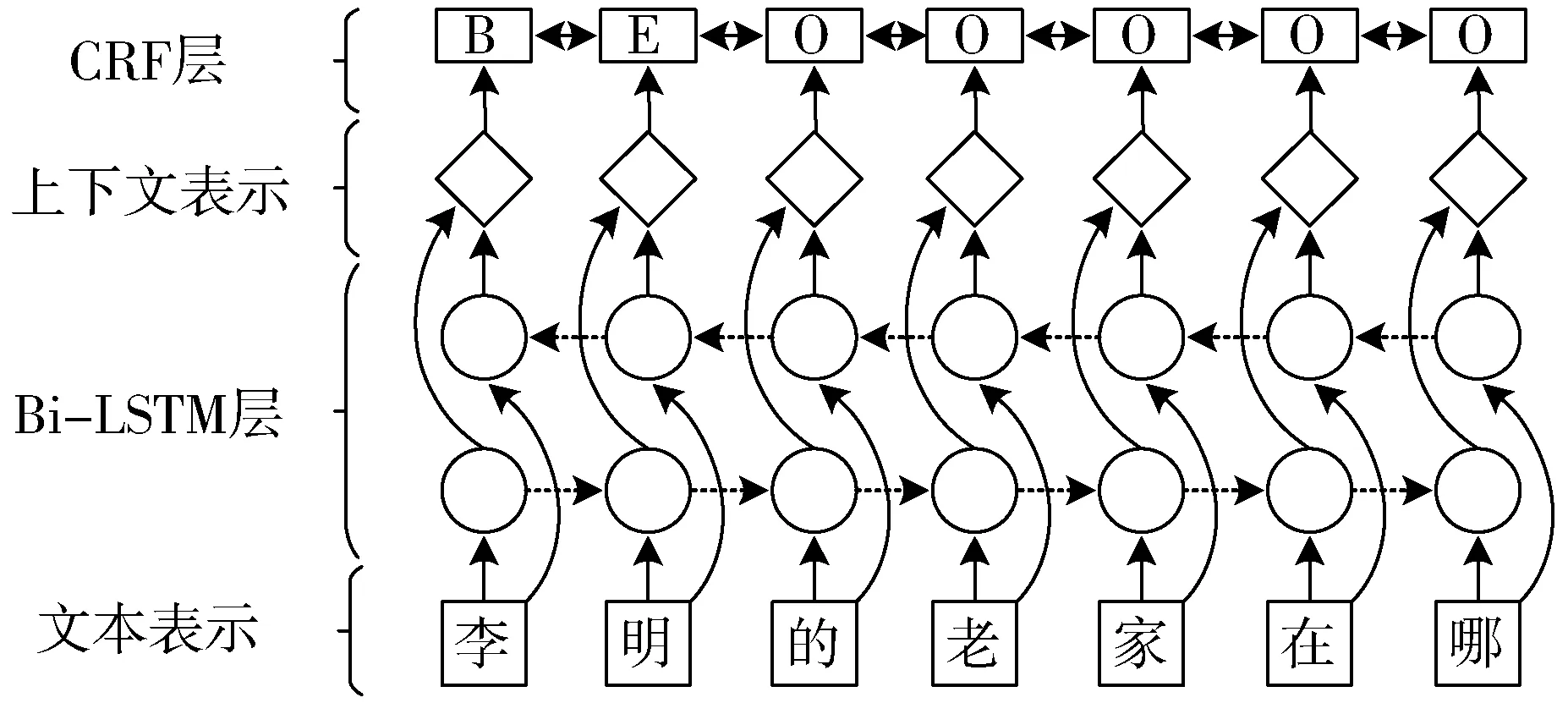
图2 实体抽取模型
4 多粒度特征表示属性选择模型
属性选择中,其主要难点是问句中属性描述可能与知识图谱中的属性名称存在着较大的差异,例如“请问红楼梦是什么时候写的?”就需要与知识图谱中的“创作年代”相关联。因此,如何设计有效的模型以最高的置信度将问句与属性进行关联是本文研究重点。对此,本文提出一种多粒度特征表示模型,采用GRU编码器来获得问句和属性的隐层表示。在文本表示中,模型考虑字符级别和词级别以获得更丰富的语义信息。最后使用余弦相似度来计算问句与属性之间的语义相似度度量。
与英文不同的是,中文里单个的汉字通常具有语义,而英文孤立的字母通常并没有具体的含义。因此在中文知识图谱问答中,对于属性p,本文考虑不同的粒度来表示特征:字符级别、词级别以及属性级别。字级别的建模将属性拆为单个汉字进行嵌入式表达,词级别则是通常意义下的进行分词后引入词嵌入,而属性级别的表示是将属性整体视为唯一符号。3种类型的属性表示包含不同层次的抽象意义,各粒度层次都有其自身的优缺点。在实验中属性级别表示采用随机初始化,它更多地关注全局信息,但其存在数据稀疏性的缺点。单词级别更注重局部信息,如单词和短语等。然而,这2个级别都受到未登录词问题的影响,字符级别没有这样的问题,并且通常在预测正确的实体和属性方面也有着较高的准确率。
以下详细介绍多粒度特征表示模型。为了利用属性不同粒度的信息并将其结合,本文采用嵌套的连接方法,将预训练的字嵌入和词嵌入经过GRU的编码并进行组合,其网络表示如图3所示。
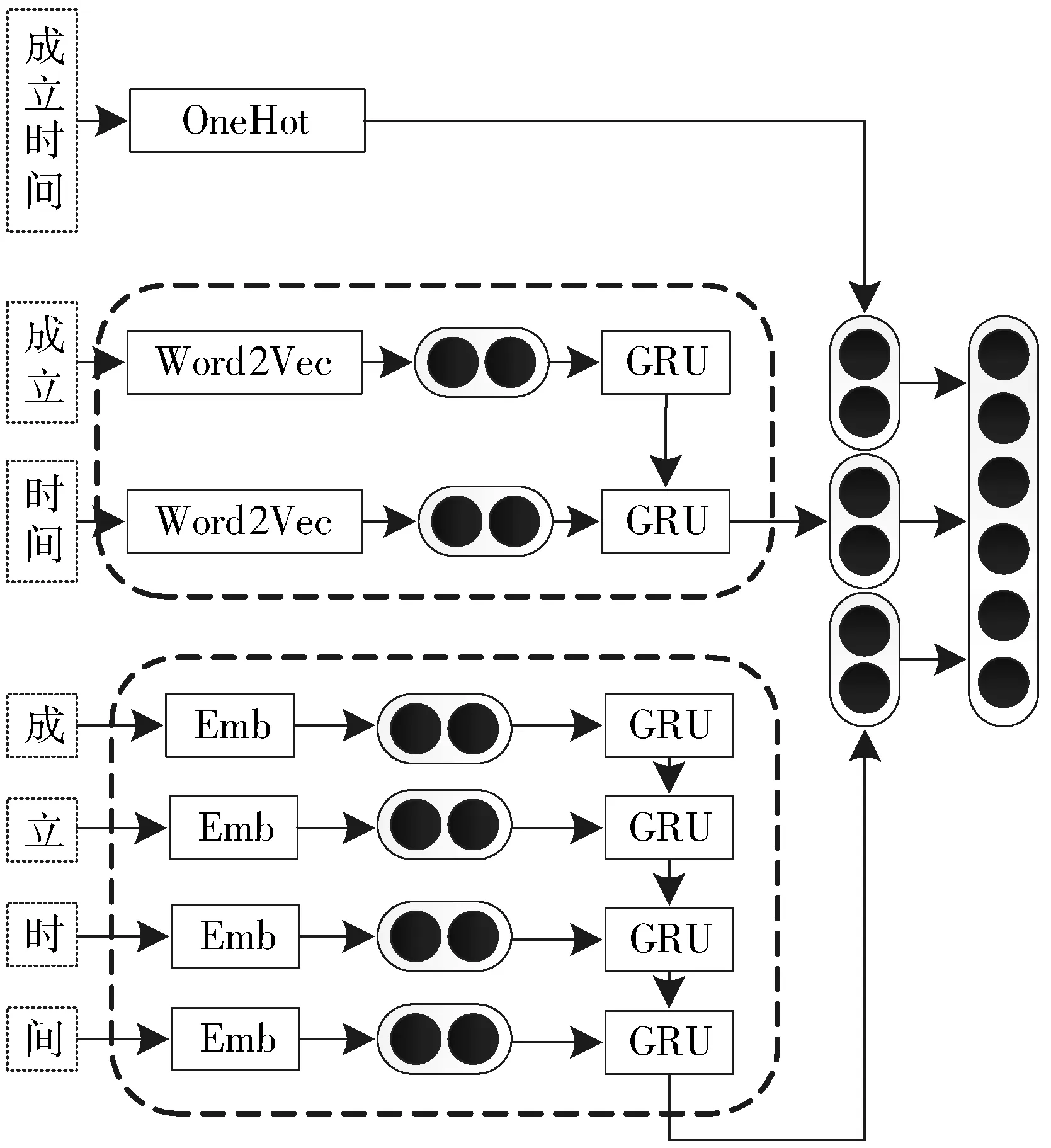
图3 多粒度特征表示模型
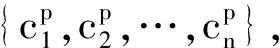
(3)
(4)
(5)
(6)
最终得到3种不同粒度的属性表示为:
(7)
(8)
S(q,p)=cos (rq,rp)
(9)
其中余弦相似度函数cos定义为:
(10)
5 实验分析
5.1 实验数据
本文实验使用的数据集为NLPCC-ICCPOL 2016 KBQA数据集。该数据集是目前最大的公开中文知识图谱问答数据集,其包含大约4300万个三元组和600万个实体。该知识图谱的三元组大部分来自百度百科的属性表格。在数据集中,14609条问答对作为训练数据以及9870条问句作为测试数据。
5.2 实验设置
对于上述表示模型,本文采用排序模型进行训练,该方法驱动模型输出包含在训练集中的问题实体和问题谓词对的高分,同时为不合理配对产生较低分数。在训练期间最小化的损失函数由下式给出:
(11)
因此在训练中,模型主要关注负例和正例得分之差小于边界γ的数据对,以使得正例和负例得分相差越大越好。
5.3 实验结果
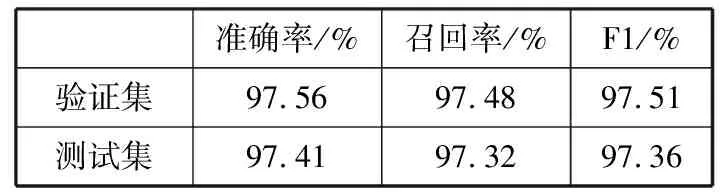
对于实体识别模型,本文采用的是100维的字符级别向量。LSTM隐层维度为100, dropout为0.5,学习率为0.001,本文采用反向传播算法来更新训练中的参数。实验中,随机选取10%训练数据作为验证集[19],结果如表1所示,可以看出在测试集上,实体识别F1值为97.36%,取得了较好的识别率,证明该模型的有效性,也为属性选择实验提供了有效的实验结果。
表1 实体抽取实验结果
准确率/%召回率/%F1/%验证集97.5697.4897.51测试集97.4197.3297.36
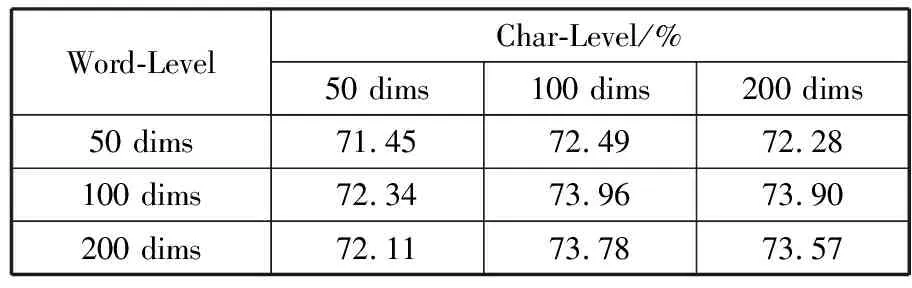
属性选择实验中,本文对比了选择不同词向量和字向量时的实验结果,如表2所示。可以看出词嵌入和字嵌入采用50维时并不能较好地表示汉字,其实验结果甚至低于对比实验中单独采用100维的词向量的结果。对于本实验,词向量和字向量分别取100维时得到最优实验结果,而随着维度的增加,属性选择模型的F1并没有明显的提升。因此,最终本文选择词向量和字向量维度都为100。其他参数如GRU编码器隐层维度为200,dropout设置为0.3。
表2 不同维度字向量与词向量实验结果
Word-LevelChar-Level/%50 dims100 dims200 dims50 dims71.4572.4972.28100 dims72.3473.9673.90200 dims72.1173.7873.57
本文同时与NLPCC官方提供的基线模型以及只采用词级别嵌入表示并通过GRU进行编码的模型进行对比。实验结果如表3所示,可以看出本文模型在最终结果上比基线模型有了很大的提高,且与只采用词级别信息表示模型相比,结合字符级别、词级别以及独热编码信息的组合模型,更能充分对数据进行表示。相比于词级别模型,多粒度模型包含更加丰富的表示信息,其包含的字符级别模型可以更好地处理单个汉字的语义信息,例如对问句“列克星敦号航空母舰能载多少人?”,字级别信息的引入能够使得属性“人员编制”的置信度更加准确,同时对于未登录词,字符级别模型也能较好地进行处理;而独热编码更关注全局信息,对于问句“陈浩民的家庭成员有哪些?”,独热信息可以直接与属性“家庭成员”进行匹配。因此相比于词级别模型,多粒度表示模型可以达到比采用单一表示更好的实验结果。
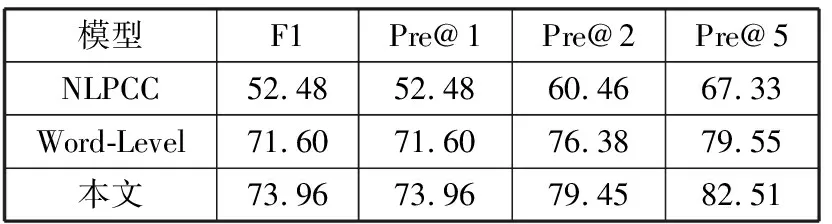
表3 问答实验结果对比 单位:%
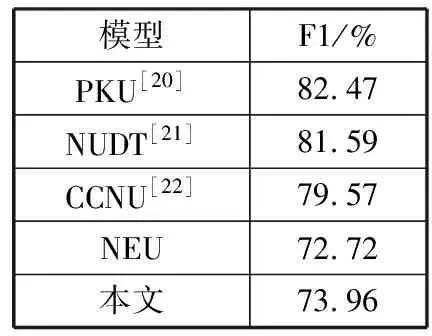
同时,本文也将实验结果与其他在该中文知识图谱问答数据集上进行实验的论文结果进行对比,如表4所示。前3名的结果分别为82.47%、81.59%、79.57%,且作者在实验中基本都采用了一些预定义的规则以及集成方法对模型进行优化。本文在仅使用单一神经网络模型、结构尽量简单的情况下,也取得了较好的实验结果,验证了模型的有效性。
表4 不同实验结果比较
模型F1/%PKU[20]82.47NUDT[21]81.59CCNU[22]79.57NEU72.72本文73.96
6 结束语
本文提出了一种中文知识图谱问答的方法,有效地解决了其中实体抽取和属性选择2个主要任务。在实体抽取中,本文采用命名实体识别的方法,训练Bi-LSTM-CRF模型以获得问句主题实体。在属性选择任务中,本文提出多粒度特征表示模型,将字符级别、词级别的文本表示进行编码,并考虑属性的独热编码信息,将不同粒度的信息进行结合,充分利用数据特征。实验结果表明本文的模型在中文知识图谱问答中取得了较好的效果。
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28
少先队活动(2020年12期)2021-01-14
晚晴(2018年3期)2018-12-06
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
中学生(2017年13期)2017-06-15
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
浙江大学学报(工学版)(2016年11期)2016-06-05
应用海洋学学报(2015年3期)2015-11-22
