
基于三元纠错输出编码的偏标记学习算法*
2018-09-12 02:22:04周斌斌张敏灵刘胥影
计算机与生活 2018年9期
周斌斌,张敏灵+,刘胥影
1.东南大学 计算机科学与工程学院,南京 210096
2.东南大学 计算机网络和信息集成教育部重点实验室,南京 210096
1 引言
偏标记学习(partial label learning)是一类重要的弱监督学习(weakly supervised learning)框架,在该框架下,每个训练样本在输入空间由单个示例(特征向量)描述,而在输出空间与一组候选标记集合(candidate label set)相关联,其中有且仅有一个是其真实标记[1-2]。偏标记学习的目标是学习一个从输入空间到输出空间的多类分类器。最近几年,偏标记学习技术已经广泛应用于真实世界的问题中,例如文本挖掘[3]、图片分类[4]、生态信息学[5]等领域。
偏标记学习框架的形式化定义如下。设X=Rd代表样本特征空间,Y={y1,y2,…,yq}代表样本标记空间。给定偏标记训练集D={(xi,Si)|1≤i≤m},其中xi∈X为d维特征向量,Si⊆Y为xi的候选标记集合,xi的真实标记yi未知但满足条件yi∈Si。偏标记学习目标是基于训练集D学习得到多类分类器f:X→Y。
偏标记学习的难点在于样本的真实标记隐藏在候选标记集合中,样本的真实标记无法获得。目前解决这个问题的基本策略是消歧。消歧思想是消除偏标记对象候选标记中伪标记引起的歧义性。现有的消歧策略算法主要包括基于辨识的消歧(disambiguation of identification-based)和基于平均的消歧(disambiguation of averaging-based)。基于辨识的消歧将样本的真实标记当作隐变量,通过迭代方式优化内嵌隐变量来实现消歧。基于平均的消歧对偏标记样本的各个候选标记赋予相同的权重,通过综合学习模型在各候选标记上的输出来实现消歧[1,6-7]。
然而,基于消歧的偏标记学习技术很大程度上会受到伪标记(即Si∖{yi})带来的不利影响。为了缓解这个不利影响,Zhang提出了一种基于纠错输出编码(error-correcting output codes,ECOC[8-9])的非消歧策略的偏标记学习算法PL-ECOC[10](partial labelerror-correcting output codes),该方法将多类分类技术纠错输出编码应用到偏标记学习中,通过编码的方式将偏标记学习问题转换为多个二类学习问题,然后对多个二类分类器集成得到最终的分类器。
很明显,候选标记数目越多,偏标记对象的伪标记信息就会越多,偏标记学习问题的难度越大,从而不利于偏标记问题的学习。因此可以通过减少候选标记的数目来降低偏标记学习的难度,从而有利于偏标记问题的学习。本文从该角度出发,提出了一种基于三元纠错输出编码的偏标记学习算法(partial labelternary error-correcting output codes,PL-TECOC),该算法类似于但不同于PL-ECOC且能获得较好的分类性能,PL-TECOC算法采用三元编码方式,即使用{+1,-1,0}进行编码,在将偏标记学习问题转换为多个二类学习问题的过程中,编码“0”用于忽略相应的标记,只依靠非“0”标记完成二类学习问题训练数据的构建,从而减少候选标记个数以降低偏标记学习问题的难度。
本文的组织结构如下:第2章介绍偏标记学习的相关工作;第3章介绍本文提出的PL-TECOC算法;第4章是实验部分,最后对本文进行总结和展望。
2 相关工作
目前,关于偏标记学习的算法主要分为基于辨识的消歧策略、基于平均的消歧策略以及基于非消歧的策略。
基于辨识的消歧策略,现有方法将真实标记当作隐变量,然后通过迭代方式优化内嵌隐变量的目标函数来达成消歧。首先假设一个特定的参数模型F(x,y;θ)(θ为模型参数),然后把真实标记当作隐变量并且根据式子ŷi=argmaxy∈SiF(xi,y;θ)来确定真实标记,最后通过EM[11-12]算法(expectation maximization algorithm)或其他算法来优化基于最大似然准则函数或来优化基于最大化间隔的准则函数定义的目标函数来迭代改良隐变量(真实标记)。
基于平均的消歧策略,现有方法对偏标记样本的各个候选标记赋予相同的权重,通过综合学习模型在各候选标记上的输出来实现消歧。常见方法包括基于k近邻的偏标记方法,该方法通过对样本近邻的候选标记集合进行加权投票来预测样本的类别标记,即,其中 I(·)为指示函数,N(x*)为样本x*的近邻。基于凸优化的偏标记学习方法通过最小化偏标记样本在候选标记集合上经验损失(由决定)以及在非候选标记集合上的经验损失(由F(x,y;θ)y∉Si决定)[1]来进行偏标记学习。
以上是消歧策略,Zhang近年来提出了一种全新的非消歧策略算法PL-ECOC,它将多类学习的纠错输出编码应用到偏标记学习中,通过编码的方式将偏标记学习问题转换为多个二类学习问题,最后对多个二类分类器集成以得到最终的学习器。
3 基于三元纠错输出编码的偏标记学习算法
偏标记学习的任务是学习一个多类分类器f:X→Y,本质上这是一个多类学习问题。在传统监督学习框架下,解决多类学习问题一种常见方式就是将多类学习问题分解为多个二类学习问题进行求解。常见的分解方式有一对一(one-vs-one)、一对多(one-vs-rest)和纠错输出编码(ECOC),在偏标记学习问题中,由于训练样本的真实标记未知,无法直接使用一对一和一对多的分解策略,而纠错输出编码可以多对多,因此可用为分解策略。
本文提出的PL-TECOC算法旨在通过减少候选标记的数目来降低偏标记学习的难度。它对基于二元编码的PL-ECOC算法进行扩展,采用三元编码方式,即使用{+1,-1,0}进行编码。在将偏标记学习问题转换为多个二类学习问题的过程中,编码“0”用于忽略相应的标记,只依据非0标记完成二类学习问题训练数据的构造,从而减少候选标记个数以降低偏标记学习问题的难度。PL-TECOC算法主要分为编码和解码阶段。
在编码阶段,首先随机生成一个编码矩阵M∈{+1,0,-1}q×L,其中q为类别标记个数,L为编码长度。编码矩阵M的每一行即M(j,:)是类别yi的一个L位编码字,矩阵的每一列M(:,ℓ)=σ=[σ1,σ2,…,σq]T代表q位的列编码,其中 [σ1,σ2,…,σq]T∈{+1,0,-1}q,它根据式(1)将标记空间Y={y1,y2,…,yq}划分为3个部分

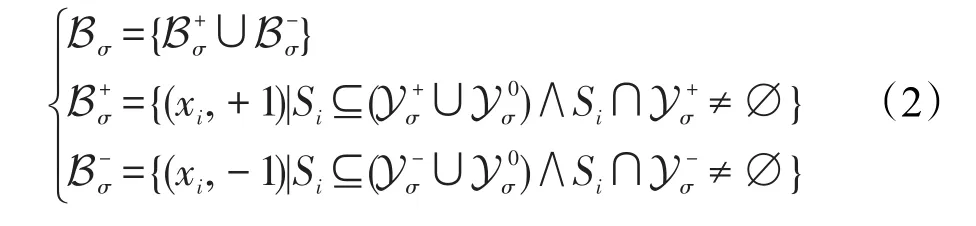
根据式(2)得知,对于偏标记训练集的每个样本xi,如果其候选标记集合包含于组成的并集合中且与的交集不为空时,则将该样本归为正类样本;如果其候选标记集合包含于组成的并集合中且与的交集不为空时,则将该样本归为负类样本,否则丢弃该样本。这样偏标记训练集中的部分样本可能既不属于也不属于因此,为了避免二类训练集样本数过少的问题,PL-TECOC设置一个阈值τ来减少其影响,即二类训练集大小须要大于等于阈值τ。此外构建的二类训练集存在类别不平衡问题,即一类样本明显少于另一类样本。PLTECOC设置阈值υ来解决这个问题,即二类训练集中两类样本数比例须小于等于参数υ。
在解码阶段,类似于ECOC的解码,将未知样本x*预测为其编码字h(x*)与标记编码字最近的标记,见式(3)。

其中h(x*)=[h1(x*),h2(x*),…,hL(x*)],关于如何计算h(x*)具体见算法1的算法伪码。dist(·,·)为距离函数,针对三元解码,常见的方式有减弱的欧式解码(attenuated Euclidean decoding,AED)、基于损失的解码(lossbased decoding)以及基于概率的解码(probabilisticbased decoding)等方式[15]。PL-TECOC采用减弱的欧式解码,其定义为:

PL-TECOC算法不同于PL-ECOC,主要体现在以下两方面:(1)本算法采用三元编码方式将偏标记学习问题转换为多个二类学习问题,编码“0”用于忽略相应的标记,只依据非0标记完成二类学习问题训练数据的构造,从而减少候选标记个数以降低偏标记学习问题的难度。(2)在构建的二类训练集存在类别不平衡问题,本算法通过设置一个阈值τ来减少其带来的影响。
算法1PL-TECOC算法
输入:D={(xi,Si)|1≤i≤m}为偏标记训练集,L为编码长度,Ψ为二类分类器,τ为二类训练集大小的阈值,υ为二类训练集不平衡比例的阈值,x*为测试样本。
输出:y*为样本x*的预测标记。
训练
1.ℓ=0
2.Whileℓ≠L
3. 随机生成q位的列编码σ=[σ1,σ2,…,σq]T∈{+1,0,-1}q
5.根据式(2)将偏标记训练集D={(xi,Si)|1≤i≤m}转换为二类训练集Bσ
6. If|Bσ|≥τ并且
7. ℓ=ℓ+1
8. 令M(:,ℓ)=σ
9.基于二类训练集Bσ学习一个二类分类器即hℓ←Ψ(Bσ)
10. End If
11.End While
测试
12.根据训练阶段学习的二类分类器得到样本x*的编码字h(x*)=[h1(x*),h2(x*),…,hL(x*)]
13.根据式(3)得到测试样本x*的标记y*=f(x*)
4 实验及实验结果
4.1 实验设置
本文在人工数据集[16]和真实数据集上分别进行了实验。数据集信息分别见表1和表2,包括样本数、属性数、类别数,另外真实数据集还给出了样本的平均候选标记集合大小。

Table 1 UCI datasets表1 人工数据集
对于人工数据集,根据常用的设置方法[1,5,10],通过控制ρ、r、ε这3个参数从多类数据集中生成人工偏标记数据集,其中ρ控制偏标记训练样本的比例(即|Si|>1),r控制候选标记中伪标记的个数(|Si|=r+1),ε控制一个额外候选标记y′≠y与真实标记y同时出现的概率。由表1可见,对于每个人工数据集,总共有28(4×7)个参数设置,于是生成28组不同设置的偏标记数据集。
对于真实数据集,Lost[1]、Soccer Player[4]、LYN(Labeled Yahoo!News)[17]数据集来自于自动人脸识别,MSRCv2[5]数据集来自于目标分类,BirdSong[18]数据集来自于鸟类音节分类。对于自动人脸识别任务,将图片或视频上出现的人脸作为示例,然后从标题或字幕上抽取的人名作为候选标记,特别地,保留LYN数据集出现数目最多的Num(Num∈{10,20,50,100,200})个人物名字作为标记空间,这样可以生成5个版本的LYN数据集,数据集命名为LYN Num。对于目标分类,MSRCv2数据集包括23个类别的1 758个图像分割区域,每个图分割区域代表一个示例,而其候选标记集合为出现在同一图像的所有对象类别。对于鸟类音节分类,BirdSong数据集将鸟叫声的音节作为一个示例,而将出现在音节10 s期间的鸟类当作候选标记集合。
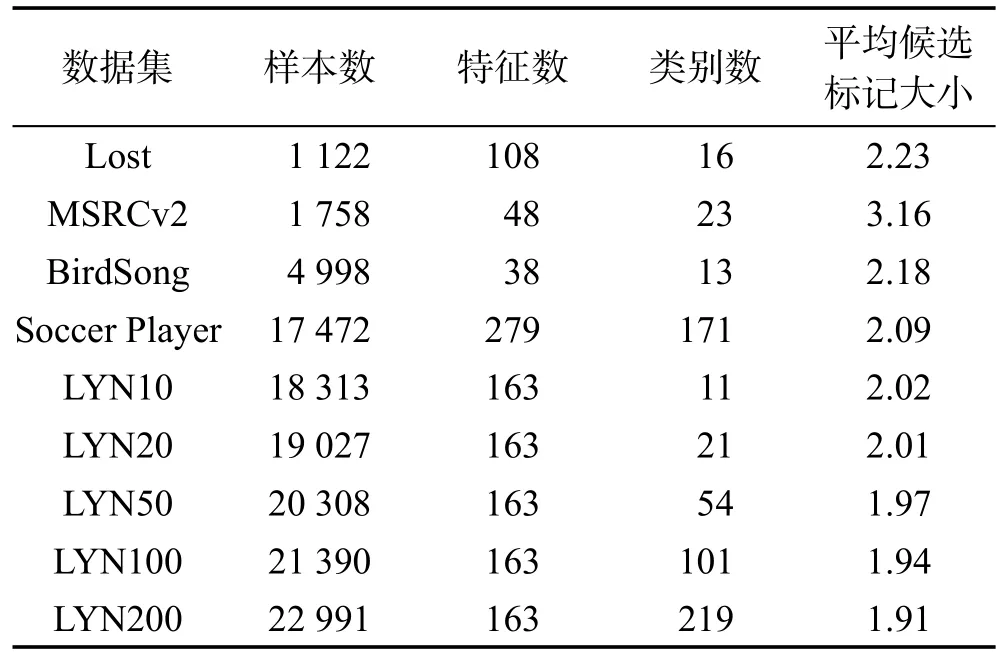
Tabel 2 Real-world datasets表2 真实数据集
为了验证提出算法的有效性,本文将和以下几个常用的偏标记学习算法进行对比。
(1)基于k近邻的偏标记学习算法PL-KNN(partial labelknearest neighbor)[6]:一种基于平均消歧策略的偏标记学习算法,参数k设置为10。
(2)基于凸优化的偏标记学习算法CLPL(convex learning from partial labels)[1]:一种基于平均消歧策略的偏标记学习算法,二类分类器采用基于L2正则化铰链损失(hingeloss)的SVM算法,使用Liblinear工具包实现。
(3)基于最大间隔的偏标记学习算法PL-SVM(partial label support vector machine)[14]:一种基于辨识策略的偏标记学习算法,正则化参数从{10-3,10-2,…,103}这个范围内选择,使用线性核。
(4)基于最大似然的偏标记学习算法LSB-CMM(logistic stick-breaking conditional multinomial model)[5]:一种基于辨识策略的偏标记学习算法,其中混合成分个数设为q(即类别标记个数)。
(5)基于非消歧策略的偏标记学习算法PLECOC[10]:编码长度设,二类训练集大小阈值设为
对于PL-TECOC算法,二类基分类器采用Libsvm[19]工具箱实现的支持向量机,二类训练集大小阈值参数τ设为偏标记训练集大小的1/10,即,编码长度设为,二类训练集不平衡的比例阈值υ设为4。在本文中,对于人工数据集和真实数据集均采用10倍交叉验证实验,并记录各对比算法的准确率以及标准差。
4.2 人工数据集实验
图1到图3展示了PL-TECOC和各种对比算法分别在r=1,2,3,ρ以步长0.1从0.1到0.7变化时的分类准确率。图4展示了PL-TECOC和各种对比算法在ρ=1,r=1,ε以步长0.1从0.1到0.7变化时的分类准确率。(a)~(d)分别是4个数据集上对应的结果图。
图1到图4表明在所有情况下PL-TECOC的性能优于或持平于其他对比算法。基于显著程度为0.05的成对t检验,表3给出了在4个数据集上所有设置情况下PL-TECOC优于/持平/劣于其各对比算法的次数。从表3可以得出以下结论:
(1)在所有参数设置下的人工数据集上,对比算法的性能劣于PL-TECOC。

Tabel 3 Win/tie/loss counts on classification performance of PL-TECOC against each compared algorithm表3 PL-TECOC分类性能优于/持平/劣于其他对比算法的次数统计
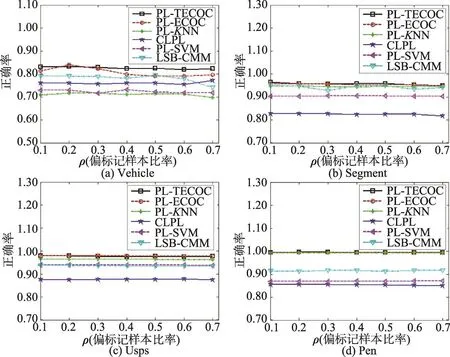
Fig.1 Classification accuracy of each compared algorithm under configurationr=1,ρ∈{0 .1,0.2,…,0.7}图1 对应设置为r=1,ρ∈{0 .1,0.2,…,0.7}时各种算法的分类准确率

Fig.2 Classification accuracy of each compared algorithm under configurationr=2,ρ∈{0 .1,0.2,…,0.7}图2 对应设置为r=2,ρ∈{0 .1,0.2,…,0.7}时各种算法的分类准确率

Fig.3 Classification accuracy of each compared algorithm under configurationr=3,ρ∈{0 .1,0.2,…,0.7}图3 对应设置为r=3,ρ∈{0 .1,0.2,…,0.7}时各种算法的分类准确率

Fig.4 Classification accuracy of each compared algorithm under configuration ρ=1,r=1,ε∈{0.1,0.2,…,0.7}图4 对应设置为 ρ=1,r=1,ε∈{0 .1,0.2,…,0.7}时各种算法的分类准确率
(2)和基于平均消歧策略方法相比,PL-TECOC分别在83.0%和86.6%的情况下优于PL-KNN和CLPL。
(3)和基于辨识消歧策略方法相比,PL-TECOC分别在100.0%和76.7%的情况下优于PL-SVM和LSB-CMM。
(4)和非消歧策略方法相比,PL-TECOC基本上与PL-ECOC持平。
4.3 真实数据集实验
基于显著程度为0.05时的成对t检验,表4给出了在真实数据集上PL-TECOC和各对比算法的性能表现。从表4可以看出:
(1)在MSRCv2数据集上,PL-TECOC算法性能优于其他所有对比算法。
(2)在LYN100和LYN200数据集上,PL-TECOC持平于PL-ECOC,优于其他对比算法。在LYN20数据集上,PL-TECOC持平于LSB-CMM,优于其他对比算法。在BirdSong数据集上,PL-TECOC持平于PL-ECOC和LSB-CMM,优于其他对比算法。
(3)在Lost数据集上,PL-TECOC劣于CLPL和PL-SVM,优于PL-KNN,持平于其他对比算法。在Soccer Player数据集上,PL-TECOC劣于PL-ECOC和LSB-CMM,优于CLPL,持平于其他对比算法。
(4)在LYN50数据集上,PL-TECOC劣于LSBCMM,优于其他对比算法。
4.4 算法的参数敏感性分析
对PL-TECOC算法关于参数υ及L的敏感性进行了分析,图5展示了PL-TECOC算法性能在不同参数设置下的变化情况。本文选择了Lost、MSRCv2、BirdSong 3个数据集来进行参数的敏感性分析,对于其他的数据集也有类似的观察结果。图5(a)表示PL-TECOC随着以步长10改变时分类准确率的变化。图5(b)表示PL-TECOC随着υ从3到7以步长1改变时分类准确率的变化。

Table 4 Classification accuracy of each algorithm on real-world datasets表4各算法在真实数据集上的分类准确度

Fig.5 Parameter sensitivity analysis for PL-TECOC on Lost,MSRCv2 and BirdSong datasets图5 PL-TECOC在Lost、MSRCv2、BirdSong 3个数据集上的参数敏感性分析
由图5可见:对于参数L,PL-TECOC性能先提高后趋于稳定。对于参数υ,PL-TECOC性能先呈现下降趋势,最终趋于稳定。总的来说,参数υ对于算法性能影响明显,因此对于该参数的选择非常重要。
5 总结与展望
为了减少候选标记的数目以降低偏标记学习的难度,本文提出了一种基于三元纠错输出编码技术的偏标记学习方法PL-TECOC。实验表明该算法在人工数据集和真实数据集上均表现良好的性能。
PL-TECOC算法的一个潜在缺点是在构建二类训练集时一些偏标记训练样本会被剔除(见算法1步骤5),未来工作方向之一是如何有效地利用这些被踢除的偏标记样本。另外,如何设计更好的编码方式来解决偏标记学习问题也是一个值得研究的方向。
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子测试(2018年1期)2018-04-18 11:52:35
电脑与电信(2018年12期)2018-03-23 02:37:20
数学物理学报(2017年5期)2017-11-23 07:51:31
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电测与仪表(2014年15期)2014-04-04 12:05:20
