
基于文本相似度计算的兴趣网络构建方法研究
2018-09-07 06:34王远志张海坤高海标陆文成
安庆师范大学学报(自然科学版) 2018年3期
王远志 ,张海坤,高海标,陆文成
(1.中国科学院合肥智能机械研究所,安徽合肥230031;2.安庆师范大学计算机与信息学院,安徽安庆246133)
伴随着互联网技术的不断发展及互联网应用规模的爆发式增长,网络已成为人们日常生活中信息传播和交流的新媒介。据相关统计,目前我国微博用户注册数量已超过5亿,互联网中的文档、数据信息量以爆炸式的趋势增长,中文微博数据量呈指数增长。如何从这些海量的非结构化的文本中抽取真正需要的、有用的信息,日益成为研究的焦点。实体关系提取正是信息抽取中的重要任务,对信息过滤、篇章理解、问答系统、机器翻译等有重要的意义。通过实体关系提取能够将微博用户连接成一个社会网络,在一定程度上促进了现实社会关系向网络社会关系的转化进程,同时对网络知识挖掘、网络信息行为研究以及知识管理的发展起到重大的作用。针对微博的短文本分类可用于个性化推荐、舆情分析等领域。
近年来,中文文本分类受到学术界的关注。文本相似度计算作为文本分类过程中的核心之一,经过众多学者的探索研究已经取得了丰硕的成果。毕海滨等提出了一种基于词汇语义的文本特征提取方法,采用基于特征向量的机器学习算法支持向量机(SVM)进行实体关系抽取实验,该方法明显提高关系抽取性能[1];王兰成等结合情感本体构建和基于HowNet与主题领域语料的情感概念选择方法对Web文本进行倾向性分析[2],实验表明,该方法有效地提高了分类的准确率和召回率;甘丽新等将不同实体各自的依存句法关系进行两两组合,再将组合特征和动词特征加入到基于特征关系抽取中[3];刘怀亮等利用TFIDF算法计算特征词项权值,并借助知网分析词频间的语义关系,提出一种基于知网语义相似度的文本相似度加权算法,该方法能够有效提升中文文本分类的精度[4];闫红等在计算句子相似度时考虑了词语定义的关系义原与待比较的词的某个义原相等的情况,并加大关系义原的权重来计算句子相似度[5],但该方法未考虑词性对句子相似度的影响;薛竹君等在解析微博文本语法的基础上,结合实体关系的定义和形式化表示,提出了采用关系网络有向图模型的方法来反映文本之间的结构关系,较好地表达了文本的语义信息[6];阳小兰等提出一种将HowNet语义库和BTM主题模型进行线性组合的相似度计算方法[7];在构建兴趣网络方面,施佺等以云计算平台为基础,利用Mapreduce框架对Digg新闻网站的评论进行关系提取,获得用户的兴趣关系网络[8]。传统的计算文本相似度的方式是利用向量空间模型表示文本,然后用余弦相似度来表示文本间的相似性,但是该方法忽略词语语义对相似度的影响。对微博等短文本而言,由于含有的词语少,这导致其向量空间模型的表示十分稀疏,因此可提供的信息也很匮乏,使得传统的方式不能很好反映文本间的相似性。本文对新浪微博用户共同兴趣网络进行探究,针对测试集中关键词的不同词性给予关键词不同的权重系数,结合知网词汇语义相似度计算用户之间的共同兴趣强度,用共同兴趣强度作为用户相似性的衡量标准,最终构建目标网络。
1 共同兴趣网络提取方法
1.1 知网义原相似度计算
知网是以“概念”属性之间的关系为基本内容的一个知识网络[9],它有两个主要概念:“概念”和“义原”。“概念”是对词汇语义的一种描述,每个词可以表达为几个概念。“概念”是用一种“义原”表达式来描述的,“义原”是知网中用来描述一个词语的最小意义单位。本文采用张泸寅等定义的义原相似度计算公式[10]:
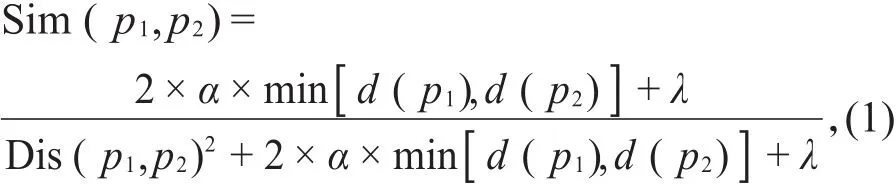
其中,Dis(p1,p2)表示义原p1和p2在义原层次体系中路径长度,若两个义原不在同一棵层次树中,Dis(p1,p2)设为固定值20;d(p1)和d(p2)指义原深度,分别表示义原p1和p2在整个义原层次体系中所处的层数位置。在计算过程中,将任何义原或具体词与空值的相似度和义原与具体词的相似度设定为两个较小的常数δ和γ,并规定两个相同具体词的相似度为1,否则为0。
1.2 知网词语相似度计算
词语W1和W2的相似度是指这两个词在不同的上下文中可以互相替换使用且不改变文本的句法语义结构的程度[9],用Sim(W1,W2)表示。如果给定词语W1有m个概念:D11,D12,…,D1m,词语W2有n个概念:D21,D22,…,D2n,则定义词语W1和W2的相似度为这些概念之间的最大相似度值[11-15]:
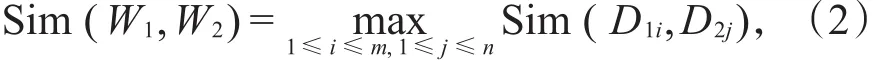
其中,D1i,D2j分别表示 W1,W2的第 i个和第 j个概念,Sim(D1i,D2j)表示两个词语的概念相似度。
知网中义原之间最主要的关系是上下位关系。只考虑义原间上下位关系,将基本义原组成一个树状义原层次关系,语义相似度的计算便是基于这种层次关系。刘群等提出的先分再合的思想,将概念的义项描述式分为第一基本义原描述式、其他基本义原描述式、关系义原描述式和符号义原描述式[9]。概念的相似度就可以通过这4个部分相似度加权求和得到。假设有两个概念D1和D2,这两个概念的4个部分相似度计算方法如下:
(1)第一基本义原描述式相似度:概念的第一基本义原描述式只有一个基本义原,可直接采用(1)式计算,记为Sim1(D1,D2);
(2)其他基本义原描述式相似度由多个基本义原组成,将两个概念描述表达式中的所有其他基本义原看成两个集合中的元素并任意配对,计算出所有可能配对的义原的相似度,取出相似度最大的一对,得到两个新的集合。对新集合重复上述方法,直到集合为空。
假设两个概念D1,D2的其他基本义原表达式分别为 V1={p11,p12,…,p1m}和 V2={p21,p22,…,p2n},|V1|和|V2|表示概念拥有的其他基本义原数,则其他基本义原相似度的计算算法如下:
输入:两个概念的其他基本义原描述式
输出:两个概念的其他基本义原相似度
令Size=max{|V1|,|V2|};num=0.0;
while(|V1|>0 or|V2|>0){
求出两个集合所有组合中相似度最大的一组义原 p1i∈V1和p2j∈V2;
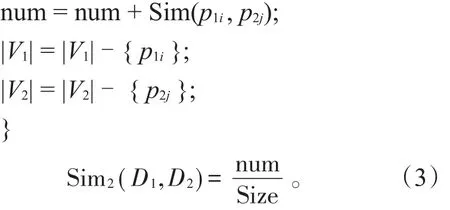
(3)关系义原描述式相似度计算方法与(2)类似,不同点是先把关系义原相同的描述式分为一组,然后计算描述式的基本义原之间的相似度作为关系义原描述式的相似度,记为Sim3(D1,D2)。若关系义原不同,其相似度取较小常数。
(4)符号义原描述式相似度的计算与(3)类似,只在符号相同时计算相似度,记为Sim4(D1,D2)。
通过上述4个部分相似度的加权求和计算概念相似度为
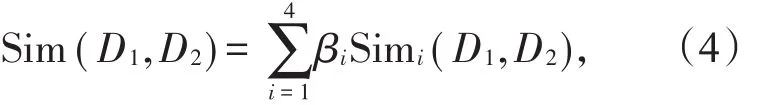
其中,βi(1≤i≤4)表示各部分的权值,β1+β2+β3+β4=1,且β1>β2>β3>β4。
1.3 结合词性的共同兴趣网络构建
本文的共同兴趣网络用无向图G(I,S)表示,其中I表示微博用户节点,S表示用户之间的笛卡尔积。共同兴趣网络的构建主要是通过用户之间的共同兴趣强度的比较,若该值大于等于参数θ,就在用户节点之间添加一个边。阈值θ根据文本相似度值选定,使得用户类别鉴定的准确率最大。用户相似度计算过程中,不同词性的关键词对文本的贡献度是不同的。如果不同词性的关键词给定相同的权重系数,使得文本分类的准确性降低。针对兴趣而言,名词的表征能力最强,动词次之,其他词性可忽略不计。本文在预处理阶段根据词性对特征词进行了筛选,只保留名词和动词。这里以两个微博用户A和B为例,假设A和B的特征词集合分别为(W11,W12,…,W1m)和(W21,W21,…,W2n),则微博用户共同兴趣网络构建步骤如下:
输入:微博用户文本特征词集
输出:微博用户兴趣网络
Step1:对A、B中特征词两两组合;
Step2:计算所有组合的词语相似度并取出相似度最大的组合;
Step3:去除A、B集合中上述最大相似度组合所对应的特征词,计算两集合剩下的特征词两两组合的相似度;
Step4:重复Step2,直至A中特征词为空;Step5:根据词性对所有取出的特征词组合的相似度加权求和计算用户共同兴趣强度;
Step6:根据共同兴趣强度判断用户是否具有共同兴趣,对用户进行分类,进而构建兴趣网络。
上述算法中用户共同兴趣强度为:

式中,IND(A,B)表示用户共同兴趣强度,其值越大反映用户间的兴趣相似程度越高;max[Sim(W1i,W2j)]表示计算文本A中的特征词W1i与文本B中特征词相似度的最大值,1≤i≤m,ρ为权重系数,且0<τ<μ<1。对于µ和τ依据不同词性的特征词对文本信息表征能力不同的规则设定权值[14],µ和τ分别从0.6和0.3开始取值且权值系数增大的步长为0.1,并以0<τ<μ<1为约束条件,分别计算两权重系数不同取值所对应的微博用户文本相似度值。
1.4 预处理及实验流程
文本预处理的主要目的就是对原始非结构化或半结构化文本中的一些杂乱和噪音数据信息进行初步的过滤和规范化处理,得到较为“纯净”的文本。这一阶段步骤为
(1)采用Python编写一个网络爬虫程序来获取新浪微博网站上用户的微博数据,将这些微博文本数据存入用户名命名的文件目录中,并运用正则表达式去除文本中的表情符号、发表人附的超链接、转发标签和日期标签等噪音。
(2)中文文本中的词是连续书写的形式,一句话中的词与词之间没有空格分隔,故而采用词语作为特征必须先将连续的字符串分成一个个词语。本文采用中科院分词系统(NLPIR)对文本进行分词处理并进行词性标注。
(3)根据词性对文本词语筛选,只保留名词和动词。利用哈工大停用词表去除分词后的文本停用词。
(4)选择特征词。统计文本中各词词频,降序排序并去除词频较小的词语,最终得到文本数据格式为((W1,verb,w1),(W2,verb,w2),…,(Wn,verb,wi)),其中,Wi表示该用户的特征词,verb表示该特征词的词性,wi为该词的词频。具体实验流程如图1所示。
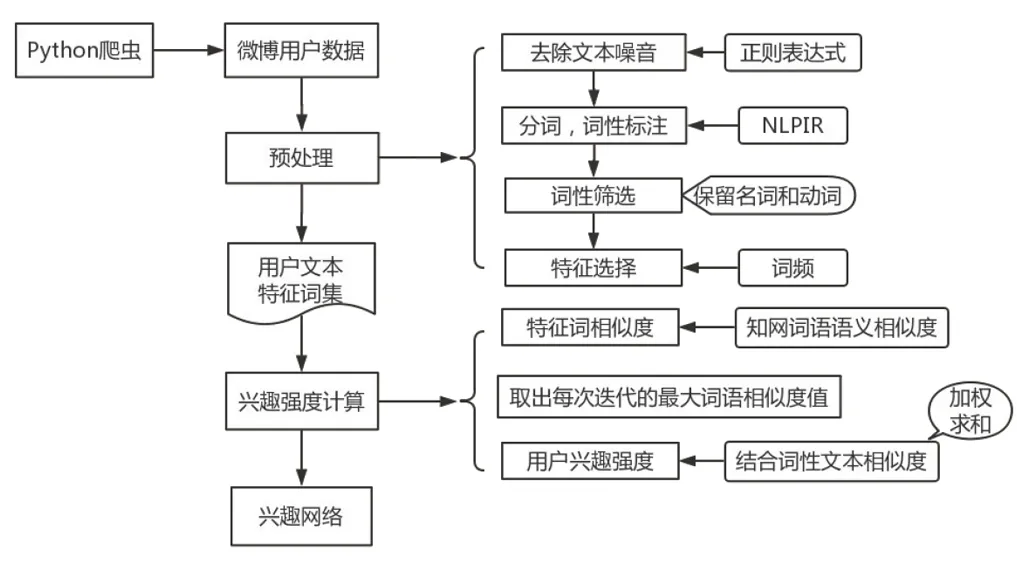
图1 实验流程图
2 实验
2.1 实验平台与实验数据
本文实验以Windows系统为平台,以Pycharm作为实验环境。实验数据采用Python编写的爬虫程序从新浪微博网站上爬取得400个用户的所有微博,分为军事、健身、财经、旅游4个类别,每个类别100个实体。从这4个类别中各选取80个用户共计320个作为类别鉴定集,其余80个用户作为待确定类别集。实验各参数设置为α=1.6,β1=0.5,β2=0.2,β3=0.17,β4=0.13,δ=γ=0.2,λ=2.0,θ=0.8,μ=0.9,τ=0.7。表1为采用文献[5]中的方法和本文方法计算军事待定类别用户集与4个类别鉴定集相似度的结果。
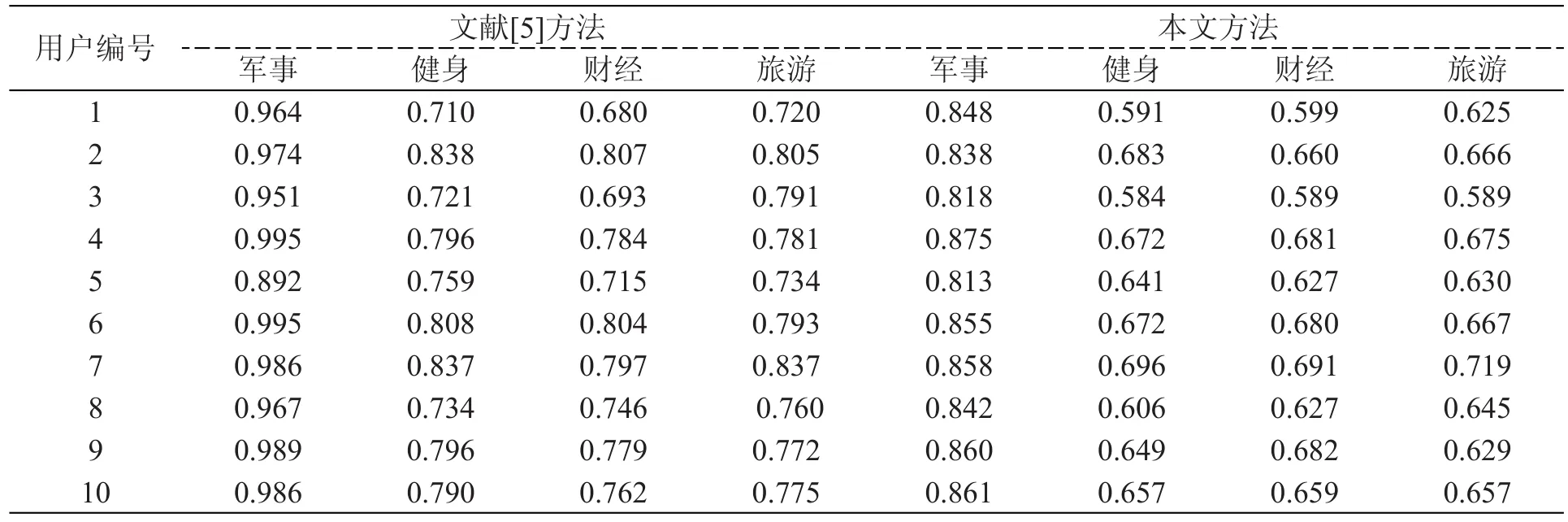
表1 用户相似度计算结果对比
2.2 实验评价指标及实验结果

本文采用用户类别判定的准确率P作为实验评价指标,式中,a表示真正属于该类别并且判断为属于该类别的用户数,b表示本不属于该类别却被误判为该类别的用户数。用文献[5]方法和本文方法对4个类别所有用户鉴定类别的准确率对比如图2所示。图2表明,在判定用户类别时,相对于文献[5]算法,本文算法类别判定的准确率有所改善。图3为4个类别所有用户共同兴趣网络,图4是从图3中提取的军事类别用户共同兴趣网络。节点M、E、F、T分别表示军事、健身、财经、旅游4个类别,数字节点表示用户编号。
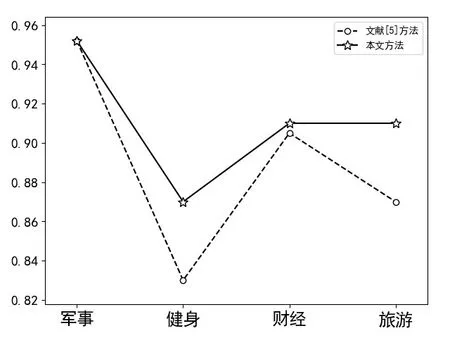
图2 准确率对比
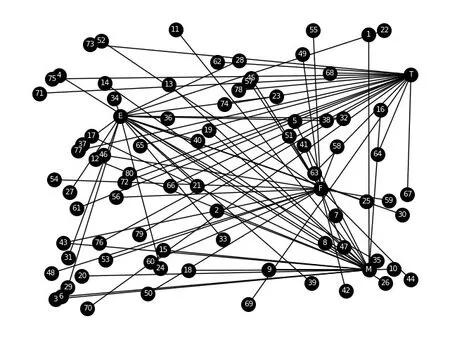
图3 所有待定类用户共同兴趣网络
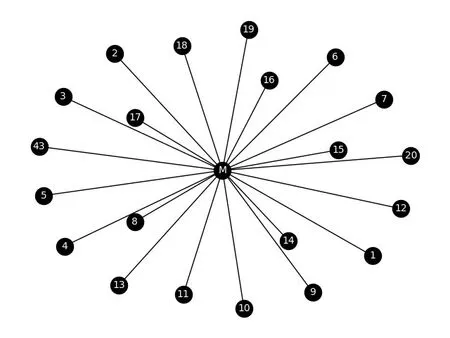
图4 军事待定类用户共同兴趣网络
3 结束语
面对海量中文数据,关系提取不仅能提高文本分类的精度,而且对社会网络构建起到了有效的推动作用。本文针对微博用户兴趣,提出一种结合词性的用户相似度计算方法构建兴趣网络。实验表明,这种方法为兴趣网络提取提供了一种新的思路。但在计算词语相似度时,未考虑知网未收录词对相似度的影响,只将其值设为-2,可能导致在选取最大词语相似度时存在误差。笔者接下来会对知网未收录词和构建得到的兴趣网络做进一步探究。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
计算机技术与发展(2022年8期)2022-08-23
陶瓷学报(2021年4期)2021-10-14
计算机系统应用(2021年9期)2021-10-11
小天使·一年级语数英综合(2020年4期)2020-12-16
少儿画王(3-6岁)(2020年4期)2020-09-13
现代信息科技(2020年18期)2020-02-22
计算机应用与软件(2018年1期)2018-02-27
传奇故事(破茧成蝶)(2015年7期)2015-02-28
微型计算机(2009年4期)2009-12-23
