
基于自然语言处理技术的电力客户投诉工单文本挖掘分析
2018-09-06 08:33吴刚勇张千斌吴恒超顾冰
中国设备工程 2018年17期
吴刚勇,张千斌,吴恒超,顾冰
(国网浙江省湖州供电公司,浙江 湖州 313000)
随着配售电市场的不断开放,新增配网将允许外部资本投资,各地售电公司纷纷成立,将来将成为电力公司的售电竞争者,由此如何减少客户资源流失将是亟待解决的问题。而保障客户稳固的首要措施是提高客户满意度,意味着客户投诉减少。因此,利用自然语言处理技术对客户投诉工单进行文本挖掘分析,了解客户投诉的主要问题,并针对性的提高差异化的服务策略是当下提高客户满意度,增加客户粘性的重要举措。
1 应用技术
1.1 自然语言处理
在计算机科学与人工智能中自然语言处理(NLP)是一个重要的研究方向。它是一种能实现在计算机与人之间用自然语言进行高效沟通的理论和方法。
自然语言处理涉及到多种统计的方法,并在此基础上发展衍生出多种模型:最大熵模型、双向搜索算法、隐马尔可夫模型、A⋆搜索算法、概率上下文无关语法、贝叶斯方法、n元语法、噪声信道理论、最小编辑距离算法、Viterbi算法、加权自动机、支持向量机等。本文主要对隐马尔可夫模型在自然语言处理中的应用进行介绍。
隐马尔可夫模型(HMM)是用来描述包含隐含未知参数的马尔可夫过程,该模型是关于时序的概率模型。隐马尔可夫模型的状态不能直接观察到,但是,它能够以观测向量序列观察到,每个观测向量的各种表现状态都是通过概率密度呈现的,每一个观测向量是基于相应概率密度分布的状态序列产生。
隐马尔可夫模型是一个五元组<S,O,A,B,π>:
S:状态集合:由四种状态构成:词头(标记为F),词中(标记为M)、词尾(标记为E)、单字成词(标记为 W)。
A:状态转移分布,即S中各元素中,两两之间转移的概率值。比如当前是s2,下一个状态是s9的转移概率为s2,9(小于1)。
B:每种状态出现的概率分布。
π:初始的状态分布。
按照机器学习方式的不同,求取参数A、B、π的方法大体上分为两类,监督学习和非监督学习。
(1)监督学习方法
如果训练数据集已经给出观测序列及相应的路径序列:
基于统计分析,对每个句子开头第一个字出现频率进行统计,以其统计数除以句子总数,即可计算得到该字的初始状态F、W的概率情况。
假设学习状态转移矩阵A的子元素为a(i->j),那么,子元素a(i->j)=(由qi状态变到qj状态的次数)/(状态变化总次数)。本文只考虑元素的状态变化,而不考虑观测值变化。
假设观测概率分布B的子元素为bj(k),那么,bj(k)=(j状态下观测为k的次数)/(所有状态的总次数)。
总而言之,监督学习方法主要是基于统计频数除以总数,得到相应的概率,以此构成模型参数。
(2)非监督学习方法
由于监督学习方法需要进行人工标注,这样往往会付出很大的代价,因此,可采用非监督学习的算法来实现。
最后基于维特比算法:基于动态规划算法挖掘出最优路径,即:从t=1开始递归计算,得出在t时刻状态为i的各条路径的最大概率,到t=T时终止,从而实现最终分词。
1.2 文本挖掘技术
近几年来,数据挖掘领域出现了一个新兴分支-文本挖掘,它是以文本类型的数据作为特定的分析挖掘对象的知识挖掘。本文的挖掘对象是基于抽取的95598投诉工单中有效、有用、散布在工单中的有价值知识,并且利用这些知识更好的了解客户需求。对投诉内容进行分词是文本挖掘的要点,根据分词结果,从文本数据中抽取出客户投诉特征信息,从而形成文本的中间表示。把原来的非结构化的客户投诉文本数据以结构化的数据呈现,再利用分类、聚类等数据挖掘技术转化为结构化文本,并根据该结构化的文本发现新的概念和相应的关系。
1.3 TF-IDF算法
TF-IDF是一种统计方法,是通过分析挖掘一字(词)对于一个文件集(语料库)中的其中的重要程度。字(词)的重要性与它在文件中出现的次数成正比例关系,与它在语料库中出现的频率成反比关系。实际上TF-IDF是:TF表示词频,IDF表示逆向文件频率,TF表示分词后的词汇T在文本中出现的次数。DF表示的文本频率,即文本集合中含有的文本频率。IDF表示的逆文本频率,公式如下:
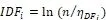
式中:n为文本总数。
对字词的重要性进行权重计算,计算公式如下:

在实际应用中,需要对进行归一化处理,
2 实证研究
基于自然语言处理技术出发,对电力客户投诉工单进行深入文本挖掘,利用分词技术分析投诉工单中的受理内容,对分词结果开展特征选取与降维处理,并进行词频统计,运用词云分析技术进行分析结果可视化展示,把控住当下电力客户投诉的主要问题,针对性的为不同类型的电力客户提供差异化的服务策略,从而提高客户满意度和忠诚度。如下图1为文本挖掘过程。
2.1 文本分词实现
文本分词是指使用计算机自动对文本进行词语的切分。通过大数据软件Python中的Jieba包,运用隐马尔可夫模型,实现对客户投诉受理内容的分词。分词结果如下图2所示。

图1 文本挖掘过程

图2 投诉文本的分词结果
2.2 特征选取与降维
(1)特征选取
通过对255条投诉工单文本数据进行分词,将每个词作为标识文本的特征,通过对各特征在整个文本集合进行统计分析,结果如图3所示。
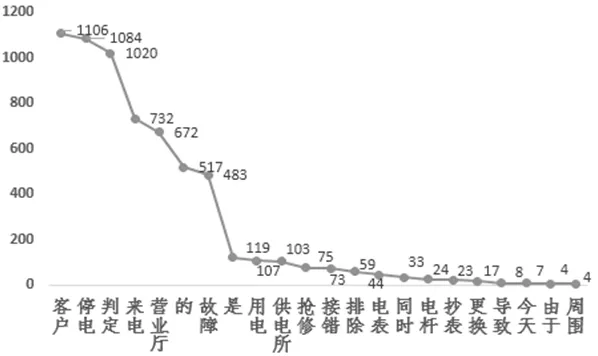
图3 投诉文本的分词结果
(2)特征降维
特征降维主要是为了对特征进行识别剔除,剔除掉对文本区分程度很少的特征,如与电力业务关系不大的特征,以降低后续文本聚类的算法复杂度,主要包括以下情形:
①剔除掉几乎每条文本都出现的词,如:“客户”、“来电”、“判定”等在255多条文本数据中出现200次以上的高频无用词汇。
②剔除掉常用特殊词,主要包括常见的称谓词、结构词、语气助词,如“我”、“你”、“是”、“啊”等与电力业务无关词汇。
③去除一些词频很小的特征,如“导致”、“今天”、“由于”、“周围”等在255多条文本数据中出现次数少于10的低频词汇。
通过对出现频率设定相应的阈值(上限,下限)来自动实现特征的降维。
2.3 关键词频提取
通过上述对分词结果进行特征选取与降维,实现对无关词汇的过滤,留下与电力业务相关的关键词。结合实际电力业务,对现有关键词进一步筛选,通过TFIDF(词频-逆文档频率)算法计算关键词重要性权重值,提取权重值大的关键词频作为客户投诉文本挖掘的最终结果。
2.4 可视化展示
通过Python软件,运用词云分析实现投诉工单文本挖掘结果展示如下图4。

图4 投诉文本词云
由图可知在客户投诉中,词语“营业厅”、“停电”、“故障”等出现频数较多,表明客户主要对营业厅、停电、故障等意见较大,可从这几个方面入手,如提高营业厅服务水平、减少停电或停电信息通知到位、加强故障检修减少故障发生等等措施,从而提高客户满意度,改善客户投诉问题。
3 应用价值
95598投诉工单的深入分析与研究是基于“客户诉求”出发,深入客户投诉工单受理内容,挖掘客户的真实需求与投诉原因。应用大数据分析技术,采取隐马尔可夫模型、分词等分析方法对投诉工单开展文本挖掘,打破原有对客户投诉需求模糊不清的壁垒,把控住当下电力客户投诉的主要问题,针对性的为不同类型的电力客户提供差异化的服务策略,提高客户粘性和满意度。
4 结语
本文利用基于自然语言处理的文本挖掘技术,结合浙江湖州电力业务需求,热点业务工单专题研究,打破了客户对用电诉求存在的盲区,提高对用户用电需求的管理程度,实现热点投诉业务工单的原因挖掘。专题的应用,将会提高客服部门的工作效率,为实现主动、精准的客户服务提供决策支持,以提升客户服务能力。
猜你喜欢
科技与创新(2022年22期)2022-11-18
车主之友(2022年4期)2022-08-27
电子测试(2022年7期)2022-04-22
海峡姐妹(2019年12期)2020-01-14
计算技术与自动化(2019年3期)2019-11-05
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中国核电(2017年1期)2017-05-17
火控雷达技术(2016年1期)2016-02-06
