
材料呈现方式对高功能孤独症儿童面部表情识别的影响
2018-09-04 10:32:08丁芳龙曦陈冰月
心理研究 2018年4期
丁芳 龙曦 陈冰月
(苏州大学教育学院心理学系,苏州 215123)
1 引言
面部表情是一种重要的非言语交流的信息表征(Batty& Taylor,2003),是成功进行社会互动的必备条件。它通过眼部肌肉、颜面肌肉和口部肌肉的变化来表现各种情绪状态。眼、眉部为表情识别的最重要线索区域,其次为嘴部线索,再次为鼻部线索(彭聃龄, 2004)。 Ekman 和 Friesen(1978)总结出人类具有6种最基本面部表情,分别为高兴、悲伤、惊讶、恐惧、愤怒和厌恶。它们完全是人类对生物刺激进行快速反应的情绪,而且能够在不同的文化背景中得到共同的识别与确认。面部表情识别指当面部表情呈现时,个体运用一定的知识对其进行具体判断的过程。它不仅有助于判断个体所传达的内部情绪状态和意图,而且还可以对其进行回馈,产生社会互动(Erickson& Schulkin,2003)。面部表情识别包括面部表情的感知与理解两个过程(Adolphs,2002)。面部表情的感知依赖于早期感觉皮层对刺激呈现所进行的早期加工,主要获取面部表情相关的视觉特性和构形加工。而面部表情的理解则需要调动头脑中储存的图式来进行判断,依赖于相关的记忆和经验。
孤独症是一种广泛性发展障碍,以明显的社会和沟通技能缺陷及刻板的兴趣和行为模式为特征(Cohen& Volkmar,1997)。孤独症儿童在社会交往中(比如用眼神察觉、互动以及对他人的情绪线索觉察方面)存在困难。Langdell(1978)指出,孤独症儿童在表情识别上与正常儿童有很大差异。Baron-Cohen(1992)研究发现,孤独症儿童并不是在所有的表情识别上都存在困难,他们对他人由外部情境引发的简单面部表情识别较好(如高兴),基本与正常儿童无异,但难以识别由信念和愿望引发的面部表情(如惊讶、窘迫等),他们对于恐惧、不安、悲伤等表达消极情绪的表情更不敏感,在这些复杂表情的识别上,其正确率普遍低于正常儿童。Humphreys,Avidan和Behrmann(2007)发现,孤独症儿童在恐惧表情的识别上有非常显著的困难。Lacroix,Guidetti, Rogé和 Reilly(2014)也发现,孤独症儿童在对消极情绪及惊讶情绪识别时表现出困难。因此,有研究者提出了孤独症的选择性识别缺陷假说(Baron-Cohen et al., 1999; Howard et al., 2000)。但李咏梅、静进、邹小兵、金宇和五十岚一枝(2009)的研究并没有证实这一假说,因为孤独症儿童不仅对恐惧表情的视觉注意减少,而且对其他情绪表情的视觉注意也减少。顾莉萍等(2012)的研究结果也显示孤独症幼儿对悲伤、恐惧、惊讶等消极情绪的识别较好,并认为这可能与孤独症儿童的异常感觉行为有关,导致他们经历了更多的消极情绪体验,因而对消极的面部表情识别较好。前人研究结果的不一致,可能与其研究工具不同或者被试量较少等有关。
国内外研究者在进行孤独症儿童面部表情识别研究时,使用的实验材料多为人物静态的基本面部表情照片 (Baron-Cohen,1992;顾莉萍等,2012;武厚,刘明矾,胡盛华,2014;王磊,冯建新,范勇,2017)。然而,在我们日常社会生活中,更多涉及的是活生生的、动态的、复杂的面部表情。所以,表情图片的静态特征使其与现实刺激的差距较大,如果能够对面部表情采用动态的呈现方式,可以更好地模拟社交情境、贴近生活。Nelson和de Haan(1996)的研究证明了面部运动对于婴儿的面部表情识别有很重要的作用。Fitzgerald,Angstadt,Jelsone,Nathan和Phan(2006)认为,动态表情作为人类的一种非言语性信号,可将情绪传递到社会交往中,准确识别这些信号对成功的人际交往至关重要。Clenney和Neiss(1989)研究显示,高兴情绪与悲伤情绪的姿态表情识别率都高于相应情绪的面部表情。姚雪(2010)研究发现,大学生对动态视频面部表情的识别成绩优于静态图片面部表情识别成绩,而且无论在识别正确率方面还是反应时方面,愤怒、厌恶、恐惧和惊讶表情的动态视频识别成绩均高于同类表情的静态图片识别成绩。陈阳、李文辉和陈俊嬴(2014)研究了孤独症儿童、智力障碍儿童、正常儿童在呈现静态与动态表情时对高兴、中性和生气表情的识别能力,发现孤独症儿童对积极表情的识别能力优于消极表情,同时对静态表情的识别能力优于动态表情。但该研究采用的是使用静态表情图片生成20%强度、40%强度、80%强度、100%强度的表情图片,动态表情的呈现方式就是以静态表情图片从20%强度递进到100%强度的形式连续呈现。这种动态表情的呈现方式人为性较大,无法展现客观真实的动态表情。另外,该研究只考察了对高兴和生气两种表情的识别,需要进一步拓展。
可以看出,已有国内外有关面部表情识别的研究多选用静态图片,而孤独症儿童所接触的世界并非静止而是动态的。有研究发现,通过图片训练,孤独症儿童对静态图片面部表情识别能力有所提高,但却无法泛化到生活中 (Golan& Baron-Cohen,2006)。孤独症是一种谱系障碍,它的症状模式、能力范围和特征以不同的组合和不同的严重程度表现出来(Lord, Cook, Leventhal, & Amaral, 2000)。 孤独症儿童不仅在认知、语言和社会能力方面差异很大,而且还表现出许多孤独症非特有的特征,最常见的是智力落后和癫痫。因此,同被诊断为孤独症的儿童,他们之间可能会存在很大的差别。孤独症儿童可能拥有不同程度的智力水平,从极重度的智力低下到高于智力的平均水平。大约80%孤独症儿童有智力缺陷,剩下的20%智力在平均水平或高于平均水平(Fombonne,1998)。孤独症儿童中低智力的,特别是言语IQ分数低的,通常与较严重的症状和较差的长期预后有关(Bolton,et al.,1994)。 只有那些在平均智力水平或高于平均水平的儿童,才有可能达到和成年人一样的独立生活状态。孤独症儿童的IQ分数是稳定的,能很好地预测将来可以达到的受教育水平。发育年龄接近实际年龄或者IQ高于70的孤独症患儿被称为高功能孤独症儿童 (李晶,朱莉琪,2014),反之则被称为低功能孤独症儿童。由于智力障碍,低功能孤独症儿童在所有领域上的发展速度是缓慢的,在兴趣和活动方面表现得更为狭窄。有研究表明高功能孤独症儿童和低功能孤独症儿童在表情识别上有显著差异 (秦颖,李志猛,2010),这就需要在对两类儿童进行区分的前提下进行研究。鉴于此,本研究拟比较高功能孤独症儿童和正常儿童在静态图片和动态视频两种呈现方式下对6种面部表情(高兴、愤怒、悲伤、恐惧、惊讶、厌恶)识别的正确率是否存在差异,这不仅有助于深化对孤独症儿童面部表情识别特点的认识,同时也为在现实中寻找对孤独症儿童社会交往能力的更有效干预方式提供依据。
2 研究方法
2.1 被试
采取方便取样的方式,从江苏省内特殊教育学校和普通学校选取29名儿童,其中高功能孤独症儿童 13 人(男 7 人,女 6 人),平均年龄 8.15±1.59 岁;正常儿童16人(男9人,女7人),平均年龄7.69±1.40岁。参加实验的高功能孤独症儿童均经医疗机构确诊。 实验前对高功能孤独症儿童(81.62±6.51)和正常儿童(84.81±8.77)进行韦氏儿童智力量表测试与匹配工作,没有发现两组被试在智力方面存在显著差异(t(27)=-1.09,p=0.286)。
2.2 实验设计
本研究采用6×2×2的混合实验设计。6种面部表情(高兴、愤怒、悲伤、恐惧、惊讶、厌恶)和2种材料呈现方式(静态图片、动态视频)为被试内变量,2类儿童(高功能孤独症儿童、正常儿童)为被试间变量。因变量为面部表情识别的正确率。
2.3 实验程序
2.3.1 面部表情图片与视频的拍摄与筛选
拍摄。研究者采用佳能600D数码相机对面部表情的图片与视频进行拍摄。拍摄对象为1男1女共2名在校大学生。拍摄共分三个步骤进行:6种基本面部表情的特点介绍、预拍摄、正式拍摄。拍摄地点是以白墙为背景。拍摄对象对头发进行一定的整理,女生将长发盘起,不遮住眉毛、眼睛、嘴巴等部位,头上不带任何头饰。端坐在指定位置,两眼平视前方。拍摄图片过程中,研究者要求拍摄对象的表情幅度较大,共拍摄230张照片;拍摄视频过程中,要求拍摄对象的表情经历由弱到强的过程,共获得30段视频。
筛选。首先由研究者和一位心理学研究生对所拍摄的230张照片进行筛选,获得60张照片。然后,通过PPT方式将这60张照片逐一展示给10名心理学研究生与5名特殊教育教师,请他们逐一评定每张照片属于哪一种面部表情,共7个选项:“高兴”、“愤怒”、“悲伤”、“恐惧”、“惊讶”、“厌恶”、“中性”。表情评定一致性超过70%的照片被保留,最终确定18张面部表情照片用于实验。视频筛选的过程与照片相似,最终确定12段面部表情视频用于实验。
2.3.2 面部表情图片和视频识别的施测
对面部表情图片(视频)进行随机排序后,逐一施测被试,要求被试告知每张图片(视频)上的表情种类。能正确命名表情或者能正确描述表情记为通过;否则记为不通过。比如,高兴表述为“高兴、开心、心情好、兴高采烈、兴奋、非常好、喜悦、笑”等;愤怒表述为“愤怒、生气、恼了、发脾气、脾气坏”等;悲伤表述为“悲伤、难过、哭、难受、伤心、不高兴”等;恐惧表述为“恐惧、害怕、担心、担忧、惊慌、畏惧”等;惊讶表述为“惊讶、吃惊”等;厌恶表述为“厌恶、讨厌、厌烦、憎恶、反感”等。

表1 高功能孤独症儿童与正常儿童在两种呈现方式下对6种面部表情识别的正确率(M±SD)
3 结果
为了考察高功能孤独症儿童与正常儿童在静态图片和动态视频两种呈现方式下对6种面部表情识别的正确率是否存在差异,以面部表情类型和材料呈现方式为被试内变量,儿童类型为被试间变量,面部表情识别正确率为因变量,进行6×2×2三因素重复测量方差分析。结果发现:面部表情类型的主效应显著(F(5,135)=32.10,p=0.000,η2=0.54);儿童类型的主效应显著(F(1,27)=8.88,p=0.006,η2=0.25),正常儿童的面部表情识别正确率显著高于高功能孤独症儿童;材料呈现方式的主效应显著(F(1,27)=11.24,p=0.002,η2=0.29), 儿童在动态视频下的面部表情识别正确率显著高于在静态图片下。
面部表情类型与材料呈现方式的交互作用显著(F(5,135)=2.49,p=0.034,η2=0.08)。 进一步进行简单效应检验(见图1):在厌恶表情上,儿童在动态视频(M=0.28,SD=0.39) 下的表情识别正确率显著高于在 静 态 图 片 (M=0.10,SD=0.28)下 (F(1,27)=4.93,p=0.035,η2=0.15); 在恐惧表情上, 儿童在动态视频(M=0.47,SD=0.46) 下的表情识别正确率显著高于在静态图片(M=0.21,SD=0.39)下(F(1,27)=11.19,p=0.002,η2=0.29);而在悲伤、愤怒、惊讶、高兴 4 种表情上,儿童在动态视频下的表情识别正确率均与在静态图片下不存在显著差异(p>0.05)。面部表情类型与儿童类型的交互作用(F(5,135)=1.59,p=0.167)、儿童类型与材料呈现方式的交互作用(F(1,27)=0.21,p=0.654)以及面部表情类型、儿童类型与材料呈现方式三者的交互作用(F(5,135)=0.53,p=0.752)均不显著。
从图1还可以看出,无论是在静态图片下还是在动态视频下,儿童对高兴表情的识别正确率均高于其他5种表情。方差分析表明,在静态图片下,儿童对6种面部表情的识别正确率存在显著差异(F(5,135)=30.50,p=0.000,η2=0.53)。进一步事后检验(LSD)发现,他们对高兴表情的识别正确率显著高于其他 5 种表情(MD(高兴-愤怒)=0.84,MD(高兴-悲伤)=0.60, MD(高兴-恐惧)=2.26,MD(高兴-惊讶)=1.85,MD(高兴-厌恶)=2.60,p<0.05)。在动态视频下,儿童对6种面部表情的识别正确率存在显著差异 (F(5,135)=17.86,p=0.000,η2=0.40)。 进一步事后检验(LSD)发现,他们对高兴表情的识别正确率显著高于其他5种表情(MD(高兴-愤怒)=0.66, MD(高兴-悲伤)=0.27,MD(高兴-恐惧)=1.04,MD(高兴-惊讶)=1.20, MD(高兴-厌恶)=1.42,p<0.05)。
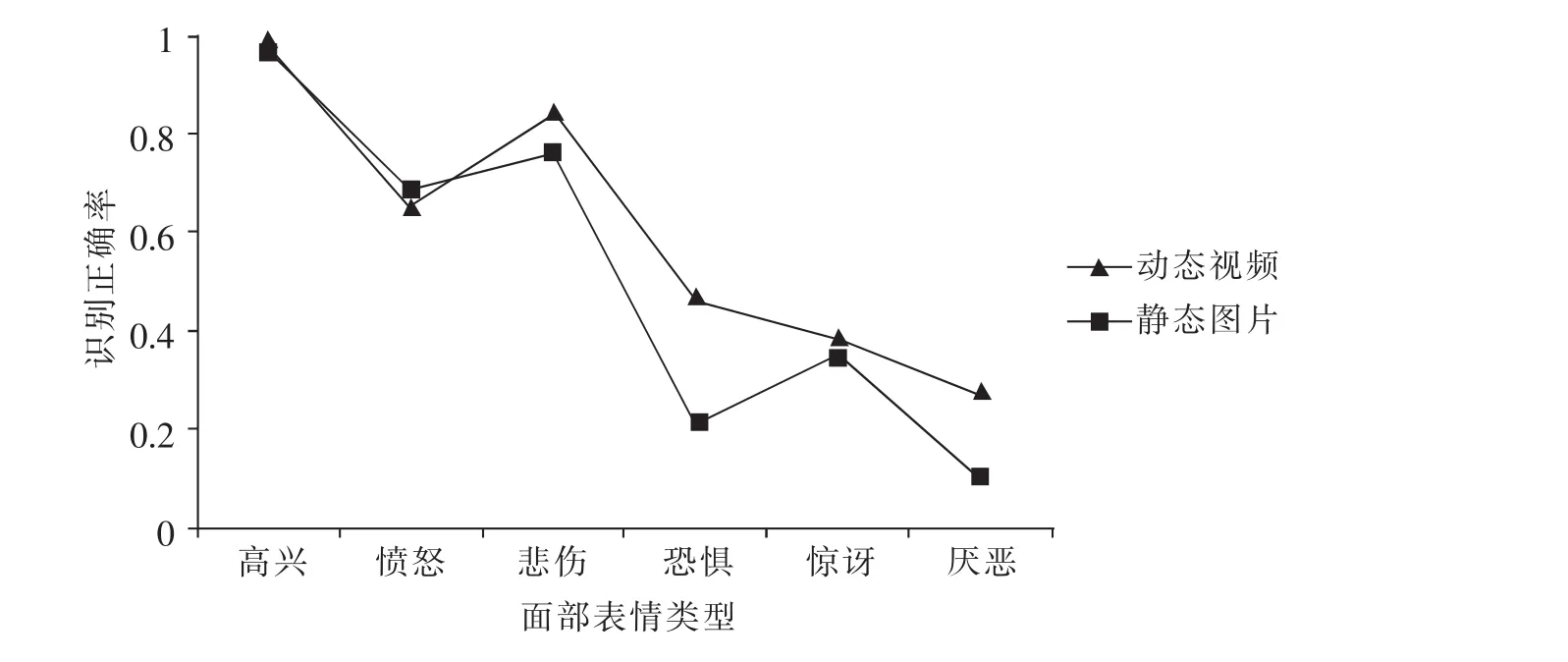
图1 面部表情类型与材料呈现方式在面部表情识别正确率上的交互作用
4 讨论
4.1 高功能孤独症儿童的面部表情识别能力较弱
本研究发现,高功能孤独症儿童的面部表情识别正确率显著低于正常儿童,高功能孤独症儿童面部表情识别能力较弱,这与前人的研究结果一致。Langdell(1978)的研究表明孤独症儿童在表情识别上与正常儿童有很大差异。周念丽和方俊明(2003)也发现孤独症儿童面部表情识别得分低于正常儿童。孤独症儿童的表情识别能力较弱或许是其社会交往存在缺陷的原因之一。他们在目光接触、共同注视等方面都有明显的发展障碍(Baron-Cohen,1992),由此可见,孤独症儿童或许缺乏对面部信息的加工能力。另外,在本研究中,虽然面部表情类型与儿童类型的交互作用不显著,但从表1可以看出,高功能孤独症儿童除了对高兴表情识别的正确率与正常儿童基本相同外,其他5种表情(悲伤、愤怒、恐惧、厌恶、惊讶)的识别正确率均低于正常儿童。Baron-Cohen(1992)提出孤独症儿童对他人由外部情境引发的简单表情识别较好,但难以识别由信念和愿望引发的面部表情。本研究进一步分析发现,高功能孤独症儿童和正常儿童对于高兴这一积极表情的识别正确率,无论在动态视频还是静态图片的条件下,都显著高于其他5种表情,基本上达到完全识别的水平,这说明高功能孤独症儿童像正常儿童一样对于简单积极表情的识别趋于成熟。这与Calvo和Lundqvist(2008)所提出的“高兴面部表情的优势效应”一致,即个体对高兴面部表情的觉察比其他表情的识别能力更快速和高效。另外,这也可能是因为特殊学校的老师们在教学过程中更多呈现出来的是积极情绪,让高功能孤独症儿童长期耳濡目染,对于他们识别高兴表情有很大帮助。而高功能孤独症儿童对惊讶表情的识别正确率较低,这可能是由于惊讶表情本身属于中性,不具有强烈的正性或负性信息,因而在没有情境条件的配合下,无论是在动态视频还是静态图片下,他们对于惊讶表情的识别正确率均较低。在以后的教学中,可以加入情境模拟,这样也许可以更好地帮助高功能孤独症儿童对于惊讶表情的识别与理解。最后,高功能孤独症儿童对于消极情绪的识别弱于对积极情绪的识别,其中对于悲伤表情的识别正确率优于其他3种消极情绪(愤怒、厌恶、恐惧),这与前人(Viville et al., 2000)的研究结果一致。这可能与孤独症儿童在日常生活中感受到更多的难过与挫折经历,而很少注意愤怒、厌恶、恐惧等消极情绪有关。另外,这也可能是由于准确识别愤怒、厌恶和恐惧等比较复杂的面部表情是极具挑战性的任务,需要较高的社会认知水平,比如心理理论。已有研究发现孤独症儿童缺乏心理理论(Baron-Cohen, Leslie, & Frith, 1985; Pilowsky, Yirmiya, Arbelle, & Mozes, 2000; Kleinman, Marciano,& Ault,2001)。另外,孤独症儿童在执行功能这一高级认知能力上也表现出缺陷 (丁芳,熊哲宏,2003)。抑制控制是执行功能的重要成分,孤独症儿童可能由于对情绪干扰信息的抑制能力较弱,所以在识别较复杂的表情时产生了困难。
4.2 儿童在静态图片和动态视频两种材料呈现方式下对6种面部表情的识别能力
本研究发现,无论是高功能孤独症儿童还是正常儿童,他们在动态视频下的面部表情识别正确率显著高于在静态图片下,可以说存在“动态加工优势效应”。杨国亮、王志良和王国江(2006)提出,由于静态面部表情识别只考虑图像的空间信息,而动态图像面部表情既考虑空间信息又考虑时间信息,因此在同样前提下,动态图像的识别率应高于静态图像。张琪、尹天子和冉光明(2015)认为相比静态表情,动态表情会诱发个体产生更强、更频繁的面孔模仿,从而使个体能够更加准确地理解他人面部所传递的信息。而陈阳等(2014)的研究则发现孤独症儿童对于静态表情的识别优于动态表情,这与我们的研究结果不一致,可能是由于所采用的动态表情材料不同所致。陈阳等研究中所采用的动态表情材料是由不同强度的表情快速地、连续地呈现来实现动态的效果,而且是模拟人脸;而我们的研究材料则是采用真人动态视频的形式,更接近于儿童的现实生活场景,能够提供更加自然连续的信息,所以在识别动态视频时,儿童可能会将视频内容与实际生活场景相匹配,从而提高了他们对于面部表情识别的正确率。另外,本研究发现,儿童在厌恶与恐惧这两个表情上对动态视频表情的识别正确率均显著高于对静态图片表情的识别正确率,可以看出动态视频可以在一定程度上提高儿童对于比较复杂的消极面部表情的识别正确率。如前所述,面部表情的理解需要调动个体头脑中储存的图式进行判断,要依赖于相关面部表情的记忆和经验,而动态视频相较静态图片更加契合儿童的现实生活场景,从而唤醒他们头脑中对于这些消极面部表情的记忆和经验做出识别。
5 结论
5.1 高功能孤独症儿童对面部表情的识别能力较弱,其面部表情识别正确率显著低于正常儿童,对高兴表情的识别正确率显著高于其他5种表情,证明存在“高兴面部表情的优势效应”。
5.2 高功能孤独症儿童和正常儿童对面部表情的识别受材料呈现方式的影响,对动态视频下的面部表情识别正确率显著高于静态图片下,存在“动态加工优势效应”,尤其是在动态视频下对厌恶和恐惧两种表情的识别正确率显著高于在静态图片下。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
中华养生保健(2020年7期)2020-11-16 01:14:26
当代陕西(2019年12期)2019-07-12 09:12:12
特别健康(2018年9期)2018-09-26 05:45:32
读友·少年文学(清雅版)(2018年2期)2018-09-10 06:00:20
特别健康(2018年2期)2018-06-29 06:13:42
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
故事会(2016年15期)2016-08-23 13:48:41
机电信息(2015年9期)2015-02-27 15:55:56
