
基于MR-FCM的区域交通状态识别方法*
2018-08-29 10:24杨庆芳
武汉理工大学学报(交通科学与工程版) 2018年4期
梅 朵 杨庆芳 鄂 旭
(渤海大学信息科学与技术学院1) 锦州 121013) (辽宁省农产品质量安全追溯工程技术研究中心2) 锦州 121013) (吉林大学交通学院3) 长春 130012)
0 引 言
交通状态识别一直是智能交通领域的研究热点,如何准确地识别当前的交通状态,并可以预测未来时段的交通状态,是实现交通控制与管理的前提[1].随着城市路网规模的不断扩大,传统的针对路段或者交叉口的交通状态识别方法,由于运行效率非常低,面对路网数据量的增大,显然力不从心,已经无法满足当前交通控制与管理的需求.
针对路网规模的扩大,一些专家学者已经研究出了一些解决区域路网交通状态识别的方法,大致可以分为三类:①统计学方法,即通过设计路网交通状态评价体系,宏观地实现路网交通状态识别;②基于聚类、模式识别的方法[2-3],即通过交通流参数分析得到交通状态;③基于路网拓扑特征的方法[4-5],即通过分析路网连通性,并设计交通状态判别系数,从而得到区域交通状态.
这些方法在一定程度上实现了区域路网的交通状态识别,但是仍然有一些不足,如对路网交通信息考虑不全面、算法运行效率低等问题,导致无法满足智能交通控制与管理的实时性需求.云计算,自诞生之日起,就是为了解决数据量大、处理困难的问题而生,其MapReduce并行编程模型可以很好地实现大数据集的并行化处理,有效地避免通信瓶颈,为进一步解决区域路网交通状态识别中的数据量大、求解难的问题提供了契机[6].因此,本文针对模糊C-均值(fuzzy C-means,FCM)聚类算法存在的不足之处,结合云计算的MapReduce并行编程模型,对该算法进行改进,提出基于MR-FCM的区域交通状态识别方法,在保证区域路网交通状态识别的准确性前提下,进一步提高区域路网交通状态识别的效率,从而更好地满足智能交通控制与管理的需求.
1 模糊C均值聚类算法
模糊聚类分析源于多元统计分析,由于模糊聚类分析可以获得对象隶属于不同类的不确定程度,更客观地反映对象的实际属性,被广泛应用于处理具有模糊关系的对象数据集[7-8].针对分类数可以确定的对象集合,基于目标函数聚类的模糊C均值聚类(FCM)是分析事物的最佳算法.
Balafar等[9]提出FCM算法,该算法可以把聚类问题转化为非线性规划问题,通过迭代优化,糊划分和聚类结果.FCM算法的基本思想是:分类数确定的情况下,通过算法的不断迭代,将数据集进行分类,使同类中的数据相似度最大,非同类中的数据相似度最小[10].
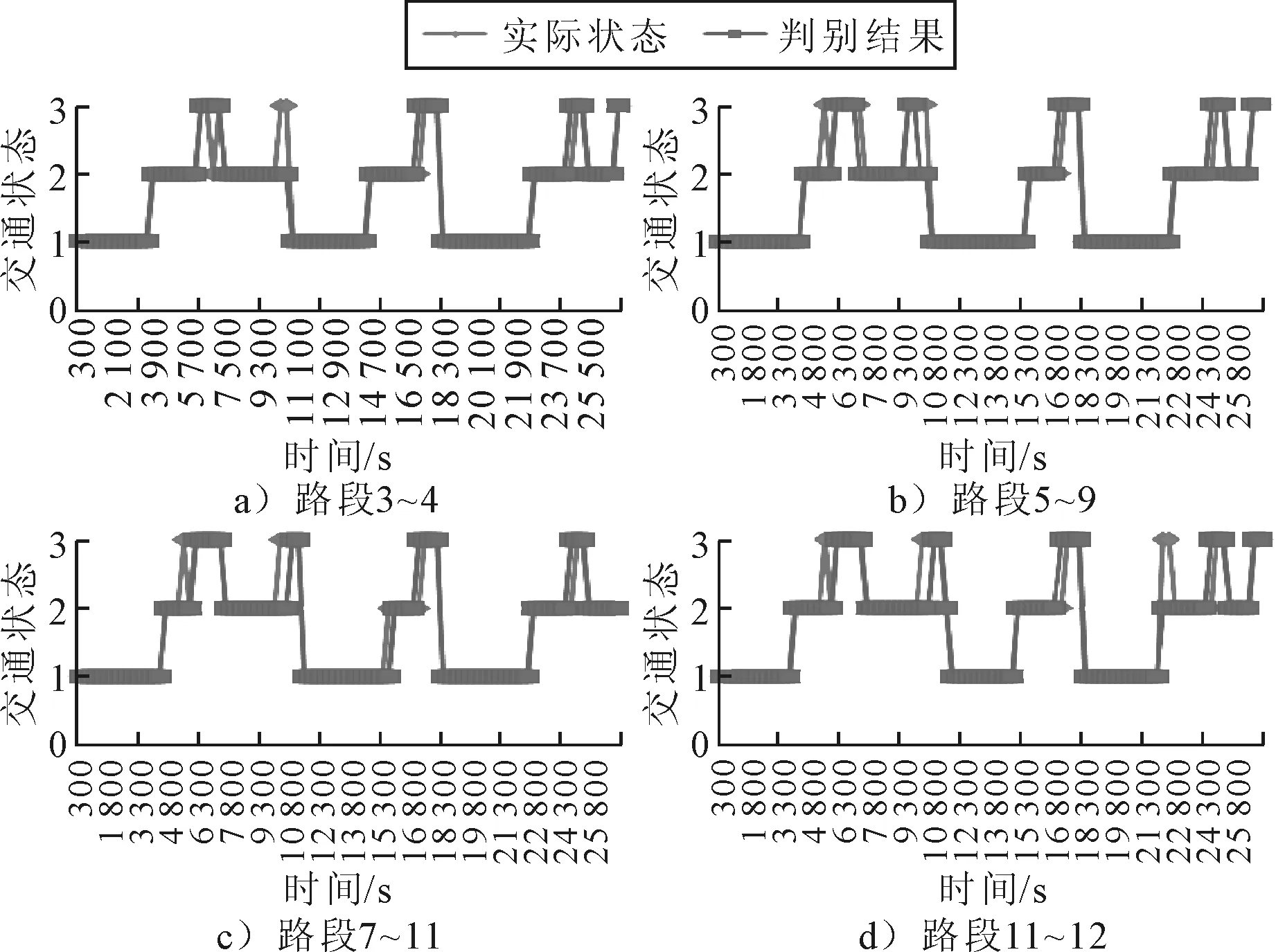
设聚类样本X={x1,x2,…,xn}.其中n为样本中数据的个数,将样本分为C(1 目标函数为 (1) 约束条件为 (2) 式中:V=[V1,V2,…,VC]为每一类的聚类中心;dij2=‖xj-υi‖=(xj-υi)TA(xj-υi)为第j个数据到第i个聚类中心的欧式距离;m为模糊加权指数,m越大,U的模糊程度越高[12]. 用拉格朗日乘法求解(1),可得 (3) 对式(3)所有变量求导可得 (4) (5) 由FCM算法的基本思想可以看出,FCM算法的聚类效果和初始聚类中心、聚类个数C,以及加权指数m三个参数有关;FCM算法的运行时间主要消耗在求解式(4)~(5)上.其中,聚类个数C根据实际需求而定,对于区域交通状态判别问题来说,C=3;关于m的取值,Pal等[13]通过实验发现,m的最佳取值范围为[1.5,2.5],本文取中间值2.为避免初始聚类中心的噪声影响,导致算法陷入局部最优,基于均值-标准差确定初始聚类中心. 均值-标准差的思想来自于随机函数的分布知识,聚类样本是均匀分布在样本均值附近的.假设分类数为C,则第i类的初始聚类中心mi为 (6) 式中:μ为样本均值;σ为样本标准差. 此外,为了提高整个算法的速度,引入MapReduce编程模型对FCM进行并行化处理. MapReduce并行编程模型是一种开源的、精简的计算模型,其实现过程需要两个函数:映射(Map)和归约(Reduce)[14].映射函数负责将大数据集划分成多个小数据集来处理,归约函数负责对中间结果进行汇总.具体实现过程见图1 . 图1 MapReduce的实现过程 MapReduce的实现过程分为数据分割、任务指派、Map执行、保存中间结果、Reduce执行、输出最终结果等阶段[15].主控程序负责数据分割和任务分配;工作机负责接收数据片段和任务,并完成Map函数和Reduce函数的调用,对数据进行处理,并输出中间结果和最终结果.MapReduce的实现过程中,数据都是以键值对 MR-FCM算法的基本流程如下. 1) 数据准备 获取交通状态参数的数据样本,定义数据样本的初始键值对格式为<路段编号,记录属性向量>,并将数据集保存到本地磁盘上. 2) 数据样本分割 将M+1台机器中的一台既作为主机器又作为从机器,其余M台均为从机器.主机器将数据集分割为M个小数据块,并发送到M台从机器上. 3) 初始聚类中心的确定 主机器基于均值-标准差确定的初始聚类中心,并将初始聚类中心、聚类个数、迭代次数、算法终止阈值、加权指数等参数发送到M个从机器上. 4) Map阶段,计算隶属度 从机器调用Map()函数,按照式(5)计算每一个样本点对初始聚类中心的欧氏距离和隶属度,并以键值对(key,value)的形式输出中间结果. 5) 合并操作 为了降低网络的通信成本,执行Combine操作.此时,具有相同key值的参数合并起来,使具有具有相同交通状态的路段聚成一类,共形成C类. 6) Reduce阶段 计算新的聚类中心.从机器调用Reduce函数,按照式(4)计算C个类的新聚类中心. 7) 判断算法是否收敛 比较新聚类中心和初始聚类中心,如果变化小于给定阈值,则输出聚类中心;否则用新聚类中心替代初始聚类中心,重复执行4)~6),直到满足条件或达到最大迭代次数,输出聚类中心. 8) 主机器将聚类中心分配到M台从机器上,从机器调用Map()函数,按照式(5)计算每一个样本点对初始聚类中心的欧氏距离和隶属度,经主机器汇总,输出最终交通状态判别的结果. 区域路网交通状态判别方法的验证数据来自于VISSIM仿真软件,仿真路网见图2,该路网共12个交叉口,其中交叉口6,8为两相位,其余均为三相位.该路网共17条双向路段,1-2-3-4,1-5-9,3-7-11和9-10-11-12均为双向6车道,其余为双向4车道.通过VISSIM仿真采集平均路段行程速度、饱和度、时间占有率、排队长度等交通状态参数.仿真时长27 000 s,采集数据间隔300 s,共采集到3 060条交通状态参数数据. 图2 仿真路网 选取对交通状态影响比较显著的四个交通参数:平均路段行程速度、路段饱和度、时间占有率和排队长度比为区域路网交通状态的指标. 平均行程车速的表达式为 (7) 式中:Li为路段长度;Ti(t)为路段形成时间. 路段饱和度的表达式为 (8) 式中:V为路段实际流量;C为路段通行能力. 时间占有率的表达式为 (9) 式中:Δti为第i辆车通过检测器需要的时间,s;Ti(t)为检测器检测总时间,s. 排队长度比的表达式为 (10) 式中:Q为检测时间内的平均排队长度,m;L为路段长度,m. 由VISSIM仿真确定阈值表,分别改变路段的流量输入以模拟出畅通、拥挤、严重拥挤的交通状况,同时记录车辆的运行数据包,按照式(7)~(10)计算单个探测车拥堵表征量.标定后的道路交通拥堵状态特征量阈值见表1. 表1 判别指标阈值表 定义区域路网的交通状态有三种,即C=3.为了验证所提出的基于MR-FCM算法的有效性和高效性,与串行FCM算法进行对比.采用8台计算机搭建Hadoop实验平台,其中一台计算机既为主机器也为从机器,其余均为从机器.取并行节点数为1,2,4,6,8,当并行节点数为1时是串行算法. 1) 聚类中心的确定 采用均值-标准差方法确定的初始聚类中心为 分别采用并行算法和串行算法对采集到的3 060组评价指标数据进行聚类分析.并行算法得到的三种交通状态的聚类中心用矩阵表示为 串行算法得到的三种交通状态的聚类中心用矩阵表示为 聚类中心矩阵的三行分别表示畅通、拥挤、严重拥挤三种交通状态的聚类中心,聚类中心由平均路段行程速度、路段饱和度、时间占有率和排队长度比组成.对比并行算法和串行算法得到的聚类中心矩阵可以看出,两种算法得到的聚类中心比较接近,说明并行算法的并行环境,以及中间结果合并、传递和最终结果汇总等过程并没有影响聚类质量. 2) 判别结果分析 以采集的指标数据为基础,实现34条路段在90个时段的交通状态判别,并对比串行算法和并行算法的判别结果.通过实验发现,并行算法和串行算法的判别结果基本相同,说明并行算法的中间结果传递和最终结果汇总等过程并没有影响判别效果,验证了所提出的并行FCM算法的正确性.通过计算统计,发现并行算法的路网交通状态判别准确率大于90%,验证了所提出的并行FCM算法的有效性.图3为随机选取的四条路段在90个时段内的判别结果,并与仿真运行的实际交通状态进行相应的对比图,其中纵坐标1,2,3分别表示畅通状态,拥挤状态和严重拥挤状态. 图3 路网交通状态判别结果 3) 运行时间分析 以运行时间(聚类时间和区域交通状态判别时间的总和)和加速比(Sn)为指标对所提出算法进行评价.图4~5为运行时间对比图和加速比曲线图.由图4可知,当并行节点数为2时,所提出的并行FCM算法的运行时间小于串行FCM算法,但是运行时间减小的幅度较小,运行效率提高得不明显,原因是并行节点数太少,增加了Map阶段耗时.当并行节点数继续增加以后,运行时间减少的幅度增大,但是当并行节点数增加到8时,运行时间减少的幅度又变小,原因是并行节点数增加的过程,也增加了并行节点之间的通信负荷,并不是并行节点数越多越好,该实例中并行节点数取6时可以得到最佳性能比.可见,在交通状态判别过程中,根据区域路网的规模,合理地选择并行节点数,才能达到提高判别效率、节省资源的目的. 由图5可知,所提出并行算法的加速比逐渐增加,说明其具有良好的扩展性.当并行节点数为8时,算法获得最大的加速比,S8=Ts/Tp=378.24 s/50.46 s=7.49,即并行算法是串行算法的运行效率的7.49倍,最小运行时间50.46 s,满足区域路网交通状态判别的需求. 图4 运行时间对比图 图5 加速比曲线图 本文通过分析FCM算法的初始聚类中心、聚类个数、加权指数等参数以及算法的并行性,对FCM算法进行了改进,提出了一种基于MapReduce的FCM并行算法,弥补了FCM算法在解决区域路网交通状态判别时存在的困难.通过实验发现,与串行FCM算法相比,本文所提出的基于MapReduce和FCM的区域交通状态判别方法具有高效性、可行性和可扩展性,更好地满足了城市路网区域交通状态判别的需求.2 MapReduce并行编程模型
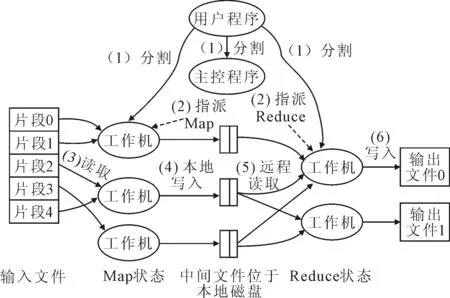
3 基于MR的FCM算法
4 实例验证
4.1 数据来源

4.2 确定评价指标及其阈值表

4.3 基于MR-FCM的路网交通状态判别

5 结 束 语
猜你喜欢
工会博览(2022年5期)2022-06-30
科技创新导报(2021年31期)2021-05-10
建材发展导向(2019年11期)2019-08-24
中国交通信息化(2019年12期)2019-08-13
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
环球飞行(2018年7期)2018-06-27
中国公路(2017年11期)2017-07-31
中国公路(2017年7期)2017-07-24
中国公路(2017年10期)2017-07-21
