
基于符号执行的底层虚拟机混淆器反混淆框架
2018-08-28 08:52:54肖顺陶周安民刘露平
计算机应用 2018年6期
肖顺陶,周安民,刘 亮,贾 鹏,刘露平
(四川大学电子信息学院,成都610065)
(*通信作者电子邮箱906120662@qq.com)
0 引言
底层虚拟机混淆器(Obfuscator Low Level Virtual Machine,OLLVM)[1]是瑞士西部应用科技大学信息安全小组于2010年6月发起的一个项目,该项目的目的是提供一个基于LLVM编译套件的开源工具,通过代码混淆和防篡改来提高软件安全性。凭借其出色的混淆效果、自定义的混淆方案、不依赖编程语言和平台架构等特性,OLLVM在软件安全领域得到了广泛运用。恶意软件开发者也逐步在自己的软件中使用该混淆技术,以增加安全人员的分析难度,防止自己的恶意软件被破解。由于目前关于OLLVM的资料比较少,加上反混淆受OLLVM保护的程序难度较大,极少数大型杀毒公司虽有相应的OLLVM反混淆方案,但出于商业目的,并未开源自己的反混淆方案,因此实现OLLVM反混淆对于保护软件用户的合法权益和维护健康的软件安全生态环境都具有重要的现实意义,也是一个亟需解决的问题。
在OLLVM反混淆方面,目前多采用基于符号执行的方法来消除控制流平展化[2]。该方面研究比较出色的是国外的Quarkslab团队,该团队提出了一种基于Python的逆向工程框架 Miasm[3],其支持可执行的可移植(Portable Executable,PE)文件、可执行与可链接格式 (Executable and Linkable Format,ELF)等多种文件格式解析,并且支持x86、高级精简指令系统处理器(Advanced RISC Machines,ARM)、无互锁管道微处理器(Microprocessor without Interlocked Piped Stages,MIPS)等多种架构平台,可以通过中间表示(Intermediate Representation,IR)[4-5]表征汇编指令语义,并使用 JIT(Just In Time)[4]技术进行代码的模拟执行。
Miasm虽然为目前最出色的针对OLLVM的反混淆工具,但其依然存在许多问题,如反混淆后的图形颜色粗陋、基本块中的IR中间表示晦涩难懂、反混淆后的图形无法反编译恢复程序源码等。针对这些缺点,本文在研究符号执行工具angr[6]和二进制分析逆向工程框架(Binary Analysis and Reverse engineering Framework,BARF)[7]逆向框架的基础上,在x86架构的Linux平台下,提出了一种基于符号执行的OLLVM自动化反混淆框架。该框架以C/C++文件经OLLVM混淆后得到的ELF文件作为输入,利用BARF框架进行反汇编和基本块的分析,并结合自定义的基本块识别算法确定序言、主分发器、相关块、预分发器、返回块等基本块;接着,使用符号执行工具angr从各基本块起始地址开始符号执行,确定真实的可达路径以及各基本块之间的前后关系;最后,修复二进制程序,包括使用无操作(No OPeration,NOP)指令填充无用基本块、有用块(包含序言、相关块、返回块)指令替换、有用块跳转偏移量修正这三个方面。由于所有的修改都是直接针对混淆后程序的汇编代码进行的,因此经过反混淆后,最终得到一个可执行文件,并能实现反编译恢复出未混淆程序的原始代码。
1 背景知识
1.1 控制流平展化
控制流平展化(Control Flow Flattening)[8]思想最先由美国维吉尼亚大学的Wang等[9]提出,早在2008年便有学者将控制流平展化技术运用于C/C++代码的保护[2]。控制流平展化是在不改变源程序功能的前提下,将C/C++代码中的if/while/for/do等控制语句转换为等价的switch分支结构,以消除case代码块之间原有的逻辑调用关系,使得所有代码块看起来都为平行关系,从而达到对程序控制流混淆的目的。
控制流平展化的思想是将源程序函数分成一个入口块和多个相邻的基本块(case代码块),每个基本块都有相应编号,并且这些基本块都有相同的前驱和后驱模块。前驱模块也叫主分发器,通过表征程序状态的控制变量(switch变量)来完成基本块的分发,这使得基本块的分支目标不能轻易地通过静态分析方式来确定,从而阻碍逆向分析者对程序的理解,增加逆向分析者分析时间,其模型如图1所示。
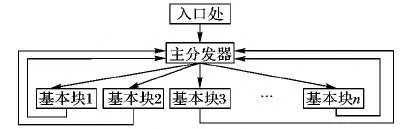
图1 控制流平展化模型Fig.1 Control flow flattening model
目前OLLVM提供了三种混淆编译选项,本文主要使用控制流平展化选项,其可以使用-mllvm、-perFLA两个参数来自定义控制流平展化程度,如设置参数-perFLA的值为100对源程序所有函数开启控制流平展化保护。
1.2 符号执行框架angr
符号执行(symbolic execution)[10-11]就是把程序输入和程序变量都视为符号,并在符号执行时,更新每个变量的符号表达式。本文提出的反混淆方案使用angr符号执行框架,angr是一款基于python的二进制文件分析框架,兼具静态分析和动态符号执行功能,其由 angr、simuvex、claripy、cle、pyvex、archinfo[6]六大模块组成,本文主要使用前五个模块。
angr模块是angr框架的分析和协调中心模块,用于完成二进制文件的分析和路径探索,本文提出的反混淆框架使用了Project/Factory/Path这3个容器。其中:Project容器用于给待分析的二进制文件创建一个angr的Project对象;Factory容器有多种类型,如:factory.block、factory.blank_state 等,本文则使用相应的factory类型来获取程序执行过程中生成的SimState对象。SimState对象跟踪并记录着程序动态执行过程中的符号信息、符号对应的寄存器信息和符号对应的内存信息等;Path容器用于存放程序动态执行过程中的path对象,本文使用factory.path(state)来获取以指定程序状态state为起点的path对象,该path对象代表从state状态起点到程序执行终点的完整路径信息。
simuvex模块是angr框架的VEX IR模拟执行引擎,负责记录程序运行状态并进行代码模拟执行。在给定VEX IRSB(IR基本块)和内存、寄存器的初始状态后,它可以进行静态分析和动态符号执行。
claripy模块是angr框架的求解引擎,它将程序中的一些状态用符号表示,并将程序的每一个路径都翻译为一个逻辑表达式,形成表达式树(expression tree)[12],最终得到一个非常大的路径公式,在完成公式求解后,就能得到覆盖所有路径的输入变量。本文提出的反混淆框架主要使用了claripy的位向量值(Bit Vector Value,BVV)构造函数claripy.BVV(),用于指定表达式中临时变量的值,从而使程序选择不同的分支进行符号执行。
cle模块是angr框架的文件解析加载器,angr使用一个精简的加载器“CLE Loads Everything”[6],该加载器并非完全精确,但是能加载ELF/ARM等可执行文件。
pyvex模块则为angr框架提供了将二进制代码转换为VEX IR中间表示的接口。
1.3 逆向框架BARF
BARF是一个基于Python的,支持多平台和二进制指令转换为中间表示的逆向工具,其主要由 Core、Arch、Analysis[7]三个模块组成。本文主要使用BARF对混淆后的二进制文件进行反汇编、生成包含逆向工程中间语言(Reverse Engineering Intermediate Language,REIL)[5]表示的控制流图(Control Flow Graph,CFG)[13],并提供相应的 IR 基本块分析功能。
Core模块是BARF框架的核心模块,它定义了REIL中间表示、可满足性理论(Satisfiability Modulo Theories,SMT)求解器和二进制接口(Binary Interface,BI)。
Arch模块指出了该框架所支持的平台架构,目前支持x86和arm两种平台。
Analysis模块是本文提出的反混淆框架的核心功能模块,主要由 Basic Block和 Code Analyzer两部分组成,Basic Block主要用于对生成的CFG进行分析,如获取基本块地址等,Code Analyzer主要用于获取相应的 SMT[14-15]表达式。
2 反混淆框架设计与实现
要实现OLLVM的反混淆,主要面临以下三个问题:
1)识别出有用块和无用块。经OLLVM控制流平展化混淆的程序中会增加很多无用的基本块以混淆程序逻辑,这就需要设计有效的基本块识别算法,找出有用的基本块和无用的基本块。
2)确定有用块之间的前后关系,得到真实有效的程序执行路径,因为混淆程序中的很多基本块跳转逻辑并不是程序的实际执行流程。
3)修复二进制程序。在使用NOP指令填充无用基本块后,为使程序正常运行,我们需要对跳转指令的跳转偏移量进行修正;同时,还需要将cmov条件传送指令改写成相应的条件跳转指令,并在其后添加一条jmp指令,使其跳向另一分支。
围绕以上三个问题,本文提出了一种基于符号执行的OLLVM自动化反混淆框架,其架构如图2所示。

图2 OLLVM自动化反混淆框架架构图Fig.2 Architecture diagram of OLLVM automatic deobfuscation framework
2.1 基本块识别模块
为了得到有效的反混淆结果,需要找到混淆程序中的有用块和无用块,这里的有用块是指对恢复原始控制流图有用的基本块,包含序言、相关块、返回块,而无用块是指OLLVM混淆后添加的无用基本块,详细定义如下:
1)序言块:函数的起始块;
2)主分发器:序言块的直接后继块;
3)预分发器:后继为主分发器的块(非序言块);
4)相关块:后继为预分发器的块;
5)无后继的块为返回块;
6)剩下的为无用块。
其次,BARF框架Analysis模块中的Basic Block子模块提供了CFG控制流图恢复功能,由该模块即可获得基本块的首地址、基本块指令、基本块分支等信息,因此可结合BARF框架的基本块分析功能设计相应的基本块识别算法。在对OLLVM控制流平展化混淆策略进行深入研究后,根据上述基本块定义,设计了如下的基本块识别算法:算法中 cfg为BARF框架解析输入文件后得到的程序控制流图;blocks代表程序控制流图中的所有基本代码块;predispatcher_Retn(cfg)用来获取返回块、预分发器的首地址;relevant_NOP_Blks(cfg)用来获取相关块、无用块的首地址,算法具体描述如下。
输入 OLLVM混淆后的ELF文件;
输出 各基本块首地址。
Begin
序言←sys.argv[2] /* 序言块首地址*/
主分发器←序言直接后继
function predispatcher_Retn(cfg)
for each block∈blocks do
if block没有分支then
返回块←block
elif block直接后继为主分发器then
预分发器←block
end if
end for
return预分发器,返回块
end function
function relevant_NOP_Blks(cfg)
相关块←[]
无用块←[]
for each block∈blocks do
if block直接后继为预分发器and
block指令条数>2 then
添加block到相关块
elif block非序言非返回块then
添加block到无用块
end if
end for
return相关块,无用块
end function
End
相比Miasm,本文提出的基本块识别算法,采用了更严格的相关块定义(指令数大于2条的后继为预分发器的块才是相关块,指令数小于等于2条的后继为预分发器的块只是完成到预分发器的跳转,对恢复程序控制流图没有意义,Miasm在后续处理中也删除了这些无用的相关块),因而能在保证基本块完备性的前提下,得到真实有用的相关块。
由于在运行框架之初就会给定混淆文件特定函数入口地址(即序言块首地址),而且经OLLVM混淆后,序言块只有1个后继块,因此通过BARF框架获得的序言块直接后继块地址、以及没有后继分支的基本块地址(分别对应主分发器首地址、返回块首地址)都是正确的;依此类推,后续得到的基本块地址也都是正确的,这就保证了所得基本块首地址的正确性。
综上,经过上述算法的处理,即可得到完备的、正确的有用块和无用块的首地址列表,这为下一步的符号执行做好了准备。
2.2 符号执行模块
OLLVM将源程序的控制流打乱了,因此需要找到真实的控制流,这里采用符号执行的方式进行路径探索,确定各个有用块之间的前后顺序以及分支关系。
虽然Miasm和angr两种符号执行引擎都能得到混淆程序的控制流字典变量{父节点:(子节点集合)},但Miasm所获得的控制流字典变量中,当父节点有2个子节点(即有分支)时,并不能看出子节点是满足条件的分支,还是不满足条件的分支,必须结合其符号执行的约束条件才能判断;而本文基于angr的符号执行模块,在符号执行过程中,当遇到有分支的相关块时,首先将存在分支的指令保留下来,然后利用angr的求解引擎Claripy设置两个1 b的位向量值〈BV1 1〉、〈BV1 0〉,分别进行符号执行,从而得到父节点的满足条件的左子节点和不满足条件的右子节点,即意义明确的控制流字典变量{父节点:(子节点集合)}。由于基本块识别模块已经得到完备的正确的有用块地址列表,因而能保证符号执行后得到正确的有用块之间的拓扑关系,详细实现过程如下:
首先,利用符号执行工具angr,从基本块识别模块得到的有用块地址列表中的每一个地址(除去返回块首地址,因为返回块没有后续分支)处开始符号执行,一旦遇到cmov类型的条件传送指令,就将该基本块指令保存下来,并设置基本块分支标志位has_branches为True,并且通过angr的求解引擎Claripy设置两个1 b的位向量值〈BV1 1〉、〈BV1 0〉,分别代表条件满足和条件不满足时的约束条件,用于在符号执行过程中改变临时变量的值,从而强行使程序走右侧条件满足时的分支或者走左侧条件不满足时的分支,以达到完整路径遍历的目的;接着,在符号执行函数 symbexec()中,调用BP_inspect()函数监控angr IR基本块中是否出现ITE(If-Then-Else)[16]条件表达式,一旦出现ITE条件表达式便在此处设置断点,并依次将ITE条件表达式中临时变量的值修改为〈BV1 1〉、〈BV1 0〉,继续符号执行,分别得到左右两侧不同分支对应的基本块首地址。当依次完成有用块地址列表中地址的遍历后,就能得到有用块之间的前后顺序及其分支关系了。
另外,如果遇到call指令,则将该call指令地址保存下来作为hook函数的hook地址,并使用hook的方式直接返回,而不去执行call指令调用的子程序,因为我们更关注的是该基本块的整体轮廓。经过上述步骤后,即可得到有用块之间正确的拓扑关系,但无用的基本块仍然存在,为了还原程序真实的控制流图,还需使用NOP指令填充无用的基本块,并完成有用块的指令修复,这就是指令修复模块的主要工作。
2.3 指令修复模块
混淆后的程序从一个有用块跳转至下一个有用块时,它们之间隔着许多无用的基本块,因此在使用NOP指令填充无用块后,还需修正跳转指令的跳转偏移量,使其能正常跳转到下一个有用块,所以指令修复模块主要完成无用块指令填充、有用块指令修复两方面的工作。
在指令修复模块中创新性地使用指令修复技术,通过对无用块进行NOP指令填充;对有用块(含直接跳转块(只有一个子节点)、有分支块(有两个子节点))进行指令替换、指令填充、偏移修正,最终得到一个可执行的反混淆文件,从而克服了Miasm由于反混淆后的结果是一种图片、无法进行反编译等缺点。由于符号执行模块已经得到了有用块之间正确的拓扑关系并且保存下了有分支的指令,因此可依据符号执行结果进行指令修复工作,并能确保指令替换、偏移修正工作的有效性,从而保证反混淆结果能正常运行,并完成对程序语义的完整还原,得到正确的反混淆结果。
为此,本文提出的反混淆框架编写了2个具有通用性的指令修复函数以自动完成指令修复工作。nop_padding()用于向指定地址填充0x90;jmp_padding()用于填充新的跳转偏移量。对于无用块,只需调用nop_padding()函数使用NOP指令填充该基本块;对于有用块则须进行直接跳转块指令修复、有分支块指令修复。
2.3.1 直接跳转块
对于直接跳转块,只需将该基本块的最后一条指令改写为jmp指令,并完成跳转偏移量的修正。具体如下:首先,向该基本块最后一条指令首地址填充jmp的opcode值;接着调用nop_padding()函数向其后4个地址填充0x90;然后按照下一跳有用块首地址,计算出修正的跳转偏移量,并调jmp_padding()函数填充新的跳转偏移量即可。
2.3.2 有分支块
对于含有分支的基本块,须将cmov指令改写成相应的条件跳转指令跳至符合条件的分支(如:cmovx指令可改写成jx指令),并在其后添加一条jmp指令。jx指令的下一跳是满足X条件的右分支基本块,jmp指令的下一跳是不满足X条件的左分支基本块,然后分别根据两个分支基本块首地址进行跳转偏移量修正即可,分支基本块的首地址可从符号执行模块中获取。
3 实验评估
测试环境为装有最新版LLVM-4.0混淆框架、本文提出的OLLVM反混淆框架、Miasm反混淆框架的 Ubuntu16.04 amd64系统计算机,详细配置为:CPU型号Intel Core i7-4790@3.60 GHz,内存 12 GB。
3.1 反混淆用时测试
经OLLVM混淆后的程序(为ELF文件)含有非常多的分支,在对其进行反混淆,特别是符号执行时势必会造成时间开销,因此本节就从反混淆用时指标上对本文提出的反混淆框架性能进行测试,并与Miasm反混淆框架性能进行对比。
测试方法一 将从 SPECint-2000[17](https://www.spec.org/cpu2000/CINT2000/)下载的200个C/C++程序使用相同的OLLVM混淆策略进行混淆后,便得到了200个ELF格式的样本程序。首先使用本文提出的反混淆框架对每个测试样本进行反混淆,为减小误差,取20次反混淆时间的平均值作为该样本最终的反混淆用时,直至完成所有样本的测试;然后,重启电脑,改用Miasm反混淆框架,仍采用上述的测试方案,完成所有样本的反混淆用时测试。为方便展示,此处从200个样本程序中选取10个具有较大范围覆盖率并具有代表性的样本程序进行结果展示,实验结果如图3所示。
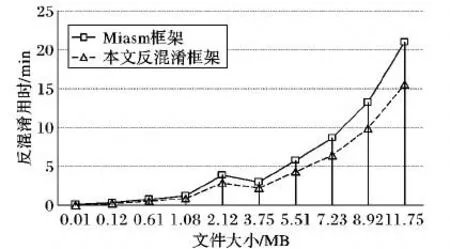
图3 两种框架反混淆用时对比Fig.3 Time consumption comparison of deobfuscation for two frameworks
表1详细列出了测试时使用的10个样本程序大小,及各程序所包含的分支循环数。由图3可知,ELF文件大小为2.12 MB时,两个框架的反混淆用时增幅均较为明显,对比表1发现,该ELF文件对应的分支循环个数为2427个,远远多于大小为1.08 MB和3.75 MB的ELF文件的分支循环个数。综合各实验数据可知,反混淆用时和ELF文件大小无关,而与分支循环个数呈正相关,分支循环个数越多,符号执行时耗费的时间也越多。
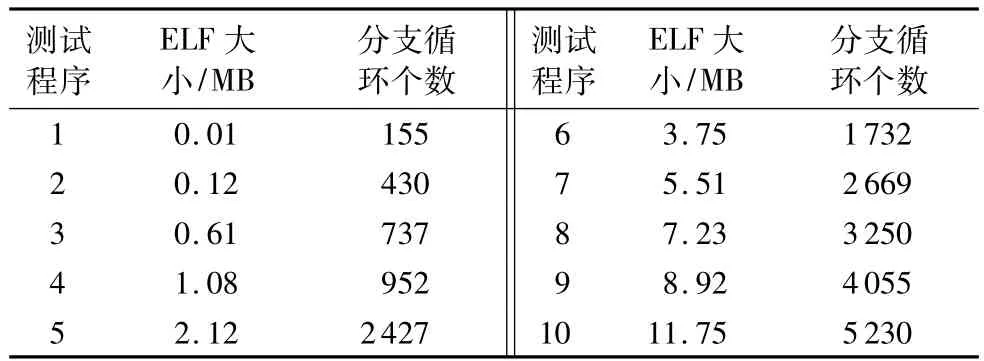
表1 OLLVM混淆后的ELF文件Tab.1 OLLVM obfuscated ELF files
其次,本实验中Miasm框架反混淆用时为7 s~21 min不等,而本文提出的反混淆框架为5 s~16 min不等,在混淆程序分支个数不多的情况下,二者反混淆用时较为接近,但随着分支循环个数的不断增加,本文提出的反混淆框架反混淆用时优势越发明显。
综上所述,本文提出的反混淆框架相比Miasm框架具有更优秀的反混淆用时表现。
3.2 反混淆结果代码相似性测试
反混淆中最关心的是反混淆结果的正确性,因此为验证本文提出的反混淆框架的正确性,将从反混淆结果程序语义正确性(以代码相似性来衡量)、反混淆结果运行正确性两个方面进行测试。
由于Miasm框架反混淆后得到的只是保留程序语义的Miasm IR Graph,无法比较代码相似性,因此只对本文提出的反混淆框架做该项测试。
测试方法二 使用GNU编译套件(GNU Compiler Collection,GCC)依次将3.1节中的200个C/C++文件编译为可执行文件,并使用二进制文件对比工具 BinDiff[18-19](http://www.zynamics.com/bindiff.html)逐个比较反混淆后程序与未混淆源程序的代码相似性。为进一步凸显本文提出的反混淆框架性能以及方便展示,这里仅展示3.1节中分支最多的10个程序的代码相似性对比结果,如图4所示。
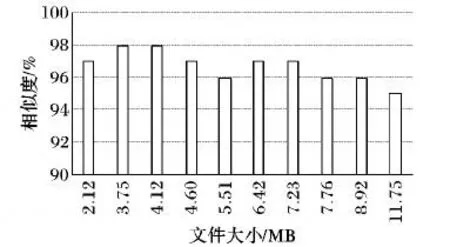
图4 代码相似性Fig.4 Code similarity
从图4数据可知,10个测试样本的平均代码相似度为96.7%,表明反混淆后的程序与未混淆源程序具有极高的代码相似度。
3.3 反混淆结果运行正确性测试
由于反混淆后的程序均为可执行文件,因此可以通过对比未混淆程序和反混淆后程序的运行结果,来判断反混淆结果的正确性。
测试方法三 分别运行3.2节中的200个未混淆源程序及与之对应的反混淆后的程序,对比二者的运行结果一致度。为方便展示,此处仅展示分支循环个数最多的10个程序的未混淆程序与反混淆后程序运行对比结果,如表2所示。
由表2可知,未混淆源程序与反混淆后程序的执行结果完全一致,这说明反混淆结果是正确的,加之反混淆后的程序与未混淆源程序具有极高的代码相似度(见图4),因此可以利用IDA等工具对反混淆后的程序进行反编译以恢复源程序代码。
3.4 对比分析
本节将从多文件格式支持、多平台架构支持、反混淆效果三方面对Miasm框架和本文提出的反混淆框架进行对比,详细的对比结果如表3所示。
由表3可知,本文提出的OLLVM反混淆框架的反混淆效果明显优于Miasm反混淆框架,特别是在反混淆结果的后续处理上,Miasm反混淆后得到的只是保留程序语义的Miasm IR Graph,不仅图形粗陋,而且图形中使用晦涩难懂的Miasm IR语言;更重要的是,其反混淆结果无法反编译以恢复未混淆程序源代码,而本文提出的通用型自动化反混淆框架直接针对OLLVM混淆后的程序的汇编代码进行操作,在保证程序语义完整性前提下,最终得到一个结果正确的可执行文件,因而可通过使用IDA进行加载,获得颜色分明、层次清晰的程序控制流图,并且控制流图中的代码块采用易懂的汇编语言;另外,还能通过IDA对反混淆后的程序进行反编译以恢复源程序的C/C++代码。这些都说明了本文提出的反混淆框架相比Miasm框架具有更出色的反混淆性能。
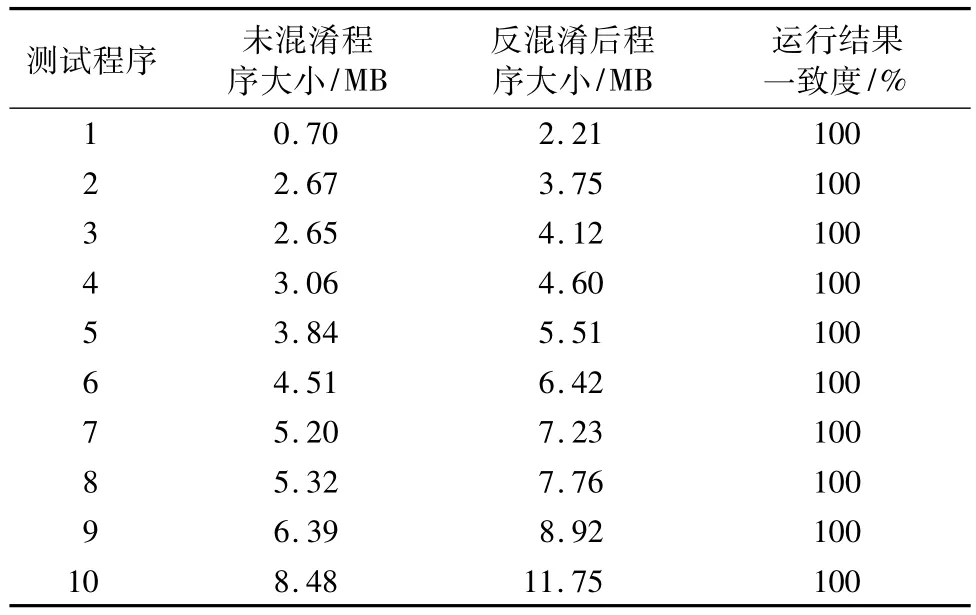
表2 未混淆程序与反混淆后程序运行结果一致度Tab.2 Consistency of non-obfuscated and deobfuscated program in operation result

表3 不同框架反混淆性能对比Tab.3 Deobfuscation performance comparison of different frameworks
4 结语
OLLVM混淆技术的流行为恶意软件的肆虐提供了土壤,针对这一问题以及Miasm框架在OLLVM反混淆方面的缺陷,本文提出了一种基于符号执行的OLLVM通用型自动化反混淆框架,该框架结合符号执行、指令修复技术很好地克服了Miasm框架的缺点,并能恢复出未混淆程序源代码,实验结果表明该框架相比Miasm框架具有更优秀的反混淆性能。
目前本文提出的反混淆框架只能很好地实现x86架构下C/C++文件的OLLVM反混淆,而Android SO文件因采用arm指令,其在基本块识别上与x86指令具有不同的规则,但二者在反混淆的思路、核心技术上具有共通性,下一步将以此为基础研究Android SO文件的OLLVM反混淆。
猜你喜欢
小型微型计算机系统(2022年5期)2022-05-10 08:45:42
数字技术与应用(2021年5期)2021-06-29 10:33:46
计算机工程(2021年3期)2021-03-18 08:03:34
电子科技(2021年2期)2021-01-08 02:25:58
计算机工程与设计(2020年11期)2020-11-17 06:56:00
计算机与现代化(2020年8期)2020-08-17 13:59:50
学生天地(2019年28期)2019-08-25 08:50:54
数学物理学报(2018年1期)2018-03-26 08:16:36
电子设计工程(2015年6期)2015-02-27 12:04:56
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
