
基于演绎长度的学习子句删除策略
2018-08-20 03:42:30常文静吴贯锋
计算机工程与应用 2018年16期
常文静,徐 扬,吴贯锋
CHANG Wenjing1,3,XU Yang2,3,WU Guanfeng1,3
1.西南交通大学 信息科学与技术学院,成都 610036
2.西南交通大学 数学学院,成都 610036
3.系统可信性自动验证国家地方联合工程实验室,成都 610036
1.School of Information Science and Technology,Southwest Jiaotong University,Chengdu 610036,China
2.School of Mathematics,Southwest Jiaotong University,Chengdu 610036,China
3.National-Local Joint Engineering Laboratory of System Credibility Automatic Verification,Chengdu 610036,China
1 引言
布尔可满足问题(Boolean Satisfiability Problem,SAT问题)是首个被证明是NP完全的问题[1],具有十分重要的理论意义。布尔变量x可以被赋值为true(1)或false(0),由一个或多个变量的析取组成一个子句,若子句中至少存在一个变量赋值为1,则该子句是可满足的。由一个或多个子句的合取构成合取范式(Conjunction Normal Form,CNF),SAT问题一般可转化成CNF表示。判定SAT问题的满足性是指若存在一组变量赋值{x1,x2,…,xN}(N为子句集F中的变量个数),使得子句集F中所有的子句都是可满足的,则子句集F是可满足的,或者给出证明,对于变量的任何赋值,子句集F都是不可满足的。近年来,SAT问题的判定技术也应用在实际领域中,如人工智能规划(AI Planning)、定理证明、软件及硬件验证、集成电路设计与验证等。求解SAT问题的算法主要分为两类:完备算法和不完备算法。尽管不完备算法可快速求解,却不能证明问题是不可满足的。完备算法不仅能在问题的属性是可满足时给出问题的解,而且在问题无解时可以给出一个完备的证明,证明此问题是不可满足的。现实生活中许多实际应用问题需要证明问题的无解,因此本文主要介绍完备算法的相关内容。
当前主流的SAT完备求解算法几乎都是基于DPLL(Davis Putnam Longmann Loveland)算法[2]衍生而来,DPLL算法主要利用单文字规则、纯文字规则和分裂规则,通过深度优先搜索二叉树,求解子句集,但是由于SAT问题的特殊性,导致DPLL算法在最坏情况下具有以问题规模为指数的时间复杂性。因此,许多研究学者提出了改进算法。其中,冲突驱动子句学习(Conflict Driven Clause Learning,CDCL)算法[3]在DPLL算法基础框架上,主要在以下方面做出改进:变量决策[4-7],冲突分析与子句学习[3],重启[8]和数据结构[7,9]。
CDCL算法的主要思想是:当基于深度二叉树搜索时发生冲突,分析出冲突产生的原因,导致冲突产生的子句就会被记录下来,称为学习子句。每次冲突时,相应地产生一个学习子句,由于实际应用问题的规模较大,其冲突次数达到百万次,学习子句的数目会随着冲突数目的增加而不断增大,在最坏情况下这种增长速度是变量规模的指数级。学习子句数目的增加影响BCP的效率,并最终导致可用内存耗尽。Silva和Sakallah[3]曾证明,大量的已学习子句对于减小搜索树的空间并不是特别有用,有时只会对搜索过程带来额外的开销。因此现今的许多SAT求解器都添加了学习子句的删除功能,提高BCP的效率以及避免出现内存爆炸问题。
Silva和Sakallah设计的求解器GRASP[3]中提出一种基于大小边界(size-bounded)的学习子句删除策略:一旦学习子句中文字个数超过设定的整数k时,则删除这些子句。Bayardo和Schrag在求解器RelSAT[10]中提出一种基于相关性边界(relevance-bounded)的学习子句删除策略:当学习子句中未被赋值文字的个数超过设定的阈值i时,则删除这些学习子句。求解器Chaff[7]中采用一种“懒散”的学习子句删除策略,学习子句添加到子句数据库,当此学习子句中未被赋值的文字个数首次大于n个时(n一般取值范围为100~200),此学习子句被标记为需要“删除”的状态,在之后的内存清理过程中统一被删除。求解器BerkMin[11]的设计者认为最新得到的学习子句具有较大的价值,因为需要耗费更多的时间来推导出最新得到的学习子句。BerkMin中不仅考虑学习子句生成的先后顺序,即将学习子句存储在队列中(先进先出),删除队列中前1/16的学习子句(但是不包含那些文字个数小于8的学习子句);而且考虑学习子句的长度大小,当队列中后15/16的学习子句的文字个数大于42时,也会被删除。求解器Minisat[12]中为每个学习子句设置活跃值activity,当子句与冲突有关时(包括学习子句),增加其活跃值,认为活跃值小于其设定的边界值k的子句是不相关的,需要被删除。Glucose求解器[13]中使用一种新的评价学习子句的策略——文字块距离(Literals Blocks Distance,LBD),即子句中所有文字所在的不同的决策层个数。认为越小LBD值的子句的相关性越高,其价值越大,因此对学习子句按照LBD值的大小从大到小排序,删除一半的学习子句(但不包括LBD值为2的子句)。现有的大多数SAT求解器中也使用此子句策略,如Lingeling[14]求解器中动态地选择LBD和activity两种评估学习子句质量的标准,如果学习子句的LBD值过大或过小,选择activity评估标准;求解器MapleCOMSPS[15]中综合使用LBD和activity两种评估标准,只保留LBD值小于6的学习子句,其余子句按照activity评估。文献[16]建立一个基于过程保存的相关函数,此函数在搜索的某阶段动态地激活或者冻结子句。文献[17]提出一种基于回退层次(BackTracking Level,BTL)的方法,计算学习子句中不同的BTL大小,实验发现当BTL小于3时学习子句在布尔约束传播中使用频率高于其他子句,因此认为对求解过程具有更大的相关度,删除那些相关度小的子句。文献[18]认为学习子句的长度对求解过程有着重要的作用,基于此,提出一种基于随机有界长度的子句删除策略,定义短子句的长度为k(即子句中文字个数为k),随机删除子句长度大于k的子句,适当地保存一些长子句对于推演归结证明是必要的,实验表明增加随机性对于求解部分的SAT问题是有效的。文献[19]提出折中度的概念,综合考虑子句的长度(size)、活跃值(activity)和LBD,通过折中度的大小评估学习子句的质量。文献[20]针对现有Glucose中基于LBD的子句删除策略,通过大量实验发现对于LBD值为2的子句(Glue clause)的利用率过低,基于此,设置不同学习子句的生存时间是不同的。
尽管已存在多种管理学习子句策略,但由于实际问题的多样性,目前不存在一种管理学习子句策略适用于求解所有的实例问题。因此,本文提出一种基于归结演绎长度评估学习子句有效性方法,并通过举例与现有的基于LBD评估方法进行了测试分析,根据学习子句排序基准不同,提出两种不同的结合算法。对比实验结果表明,所提策略能更好地识别对求解过程有用的学习子句,显著地提高求解效率。
2 基础知识
算法1典型CDCL算法
输入:CNF公式Σ。
输出:可满足SAT或不可满足UNSAT。
1.ξ=Ф; //ζ表示变量赋值集合
2.Δ=Ф; //Δ表示学习子句数据库
3.dl=0; //dl表示决策层次
4.while(true)do
5.conflict=unit Propagation(Σ,ζ);
6. if(conflict!=null)then
7.learntclause=conflict Analysis(Σ,ζ);
8.btl=compute BackLevel(learntclause,ζ);
9. if(btl==0)then return UNSAT
10. Δ=Δ⋃{learntclause};
11.if(restart())thenbtl=0;
12. backjump(btl);
13.dl=btl;
14. else
15. if(ζ⊧Σ)then
16. return SAT;
17.if(time To Reduce())then reduce DB(Δ);
18.var=pick Decision Var(Σ);
19.dl=dl+1;
20.ξ=ξ⋃{select Phase(var)};
21.end
算法1为基于CDCL的SAT求解器的框架。通过变量决策分支函数pick DecisionVar()选择决策变量var,并通过函数select Phase()进行赋值(算法第18~20行),若所有变量都已被赋值,即ζ表示公式Σ的一个赋值集合,则可判定子句集Δ的属性是可满足的(SAT),并且终止算法(算法第15~16行)。unit Propagation()是单元传播函数,若单元传播过程中发生冲突conflict,则利用conflict Analysis()函数生成学习子句learntclause,且将学习子句添加到子句集F,并通过compute BackLevel()函数非时序回退到决策层次btl,如果btl=0,则说明子句集Δ为不可满足的,否则,利用backjump()函数,回退到btl,从新的决策层次重新开始搜索赋值。restart()表示重启函数,当求解器达到设置的触发重启条件时,则直接回退到第1决策层,撤销之前所有的变量赋值。算法第17行的timeToReduce()表示达到删除学习子句的条件,此时需要调用函数reduceDB()对学习子句数据库Δ进行删除。
删除学习子句时需考虑两方面:(1)选择需要删除的子句,即对应于算法1中reduce DB()函数;(2)删除子句的频率,即何时需要删除无用的学习子句,即对应于算法1中的time To Reduce()函数。Minisat和Glucose中函数timeToReduce()满足以下条件:冲突次数达到条件lfirst+linc×x,其中x为调用删除策略的次数,lfirst=2000,linc=300。当调用reduce DB()函数时,将子句按照某种评估标准的值从大到小排序,删除序列中前一半的子句。这里,依然保持time To Reduce()函数的条件不变,主要研究reduce DB()函数中学习子句质量的评估标准。
3 基于演绎长度的学习子句删除策略
对于一个以CNF形式表示的公式F和子句Ck,若存在一个子句序列Π={C1,C2,…,Ck},则称Π是由公式F推导出子句Ck的一个归结式。其中,∀Ci∈F,子句Ci满足以下任意条件即可:(1)Ci∈F;(2)Ci是由子句Cm和Cn(m,n≤i)推导出来的,其推导规则如下:
Cm=x∨A,Cn=-x∨B⇒Ci=A∨B其中A和B为子句,x为变量。
文献[21]已证明基于CDCL的SAT求解器可被形式化为归结演绎证明系统。因此,现有的CDCL-SAT求解器的求解过程可以是一个包含删除子句集策略的归结演绎过程。当有冲突发生时,通过学习子句确定搜索树的回退层次,若学习子句中每个变量相对应的赋值层次都较小(即距离二叉搜索树的根节点较近),确定的回退层次也越小,对搜索空间的约简能力也越强,因此认为这些学习子句对搜索过程是相关的、有效的。学习子句可以通过归结过程演绎得到,因此通过演绎的长度length来评估学习子句的相关性。设有学习子句Cl,假设Π={C1,C2,…,Cl}是由公式F推导出学习子句Cl的一个归结式,则称学习子句Cl的演绎长度length为l,记Cl(length)=l。若学习子句的l值越小,说明通过归结得到此学习子句演绎路径越短,进而此学习子句中的每个变量的决策层也较小,相对应的回退层次也越小,这些学习子句应该被保留。
3.1 举例说明
为了说明学习子句的演绎长度length和LBD值在求解过程中的变化规律,随机选取SAT竞赛库中的实例g2-ak128boothbg1btisc.cnf测试说明。
3.1.1 依据LBD值排序
首先,将生成的学习子句按照LBD值从大到小排序,如图1所示。X轴表示生成的学习子句数量,求解实例g2-ak128boothbg1btisc.cnf的冲突次数为954次,因此生成954个学习子句。Y轴表示学习子句分别对应的LBD值。从图1可以看出,生成的学习子句的LBD值的分布范围不连续,有一定的区间变化。当需要删除学习子句时,按照LBD值从大到小的排序顺序,删除一半的学习子句,即删除图1中1到477的子句。
当学习子句依据LBD值排序时,每条子句所对应的length值如图2所示。X轴表示生成学习子句数量,Y轴表示每条学习子句所对应的LBD值和length值。

图1 学习子句的LBD值的排序

图2 学习子句对应的LBD值和length值
同时统计了不同LBD值的学习子句在求解过程中被使用的次数(即参与单元传播和冲突分析的总次数),如图3所示。X轴表示每个学习子句相对应的LBD值,Y轴表示不同LBD值的学习子句在求解过程中被使用的次数。

图3 不同LBD值的学习子句被使用次数
从图3可以看出,LBD<10时学习子句被使用次数较多。当LBD=6时,其被使用次数多达291次。
3.1.2 依据length排序
类似于3.1.1小节,图4表示学习子句相对应的length值的排序变化。从图4可以看出,length值的变化范围广泛。
图5表示不同length值的学习子句被使用的次数情况。从图5可以看出,学习子句的length值越小,在求解过程中被使用的次数越多,随着length值的增大,大多数学习子句被使用的次数为1。
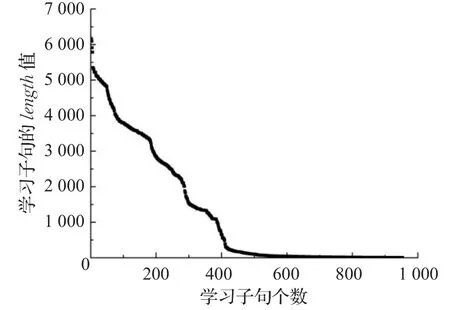
图4 学习子句的length值的排序
3.1.3 比较分析
当求解器执行删除操作时,进一步分析被删除的学习子句的LBD值与length值之间的关系。按照3.1.1小节中基于LBD值的评估方法,1到477范围的子句需要被删除。但是从图2得出,被删除子句的length值的变化范围较大,最小值为lengthmin=51,最大值为lengthmax=6169,因此,若这些被删除的学习子句按照length值评估其质量时,给出不同length值的被删除的学习子句在求解过程中被使用的次数在图5中的分布情况,如图6所示。图6中绿色的点表示被删除的学习子句的length值在求解过程中被使用的次数。从图6可以看出,当依据LBD值的评估方法删除学习子句时,仍有部分学习子句的length较小,被使用次数较高,当length=212时,使用次数为48次,这些子句的相关性较高,对求解作用较大,应该被保留。
同理,当按照3.1.2小节中length值的评估方法,1到477范围的子句需要被删除,为了方便观察,单独列出图4中被删除学习子句所对应的LBD值变化。如图7所示。
从图7可以看出,被删除的那些学习子句部分的LBD值较小,最小LBD=9,在图3中其对应的被使用次数为72次。同理,给出被删除的学习子句在依据LBD值评估时在求解过程中被使用的次数在图3中的分布情况,如图8所示。
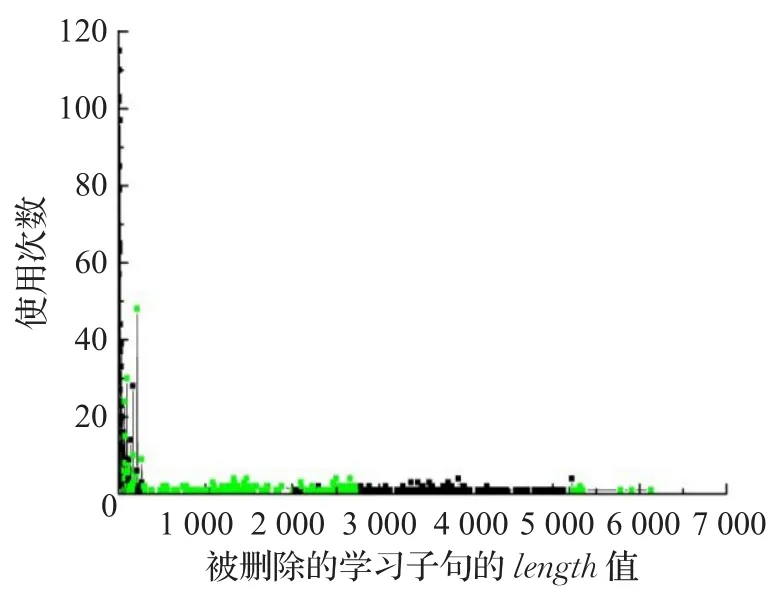
图6 被删除学习子句不同length值的被使用次数

图7 被删除学习子句的LBD值

图8 被删除学习子句不同LBD值的被使用次数
图8中绿色的点表示被删除的不同学习子句的LBD值被使用的次数。从图8得出,当依据length评估标准删除学习子句时,仍有部分子句的LBD值较小,这些子句在求解过程中被使用次数较多,当LBD=11时,其被使用次数为112次,这些子句应该被保留。
3.2 基于LBD和length的学习子句删除策略
由3.1节可知,评估学习子句的标准不同,相应删除的子句也是不同的。因此,本文综合考虑基于LBD值和length值两种评估标准,尽可能保留在求解过程中被频繁使用的子句。根据参照排序的基准值不同,给出两种不同的评估学习子句的方法。
策略1当学习子句依据LBD值的大小排序,删除学习子句时,同时考虑学习子句的length值,若C(length)<threshold1,保留此学习子句,其算法如下。
算法2删除学习子句算法reduce DB1()
输入:学习子句集合Δ,学习子句个数n。
输出:新的学习子句集合Δ,学习子句个数n/2。sort Learnt Clause(); //根据LBD值排序

算法2表示算法1中删除学习子句reduce DB()函数的执行过程。首先根据定义的排序标准——LBD值,对学习子句排序;假设学习子句的总数为n,需删除n/2的学习子句,即删除符合条件clause.length()≥threshold1的学习子句。
为了确定参数threshold1的值,测试2015年SAT竞赛的300个Application类型的实例,运行时间设置为2000 s。表1表示使用不同的threshold1所对应的求解实例个数。
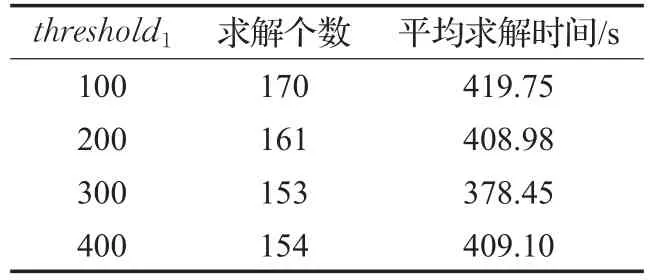
表1 不同threshold1的求解个数和时间
在求解过程中,每条学习子句的length值较大,因此设置threshold1的值从100开始起步测试。从表1可以看出,随着threshold1的值逐渐增大,其求解实例个数逐渐减少,当threshold1=300和threshold1=400时,其求解个数相差1个,但是其平均求解时间相差较多。当threshold1=100和threshold1=200时,二者的平均求解时间相差不大,但是threshold1=100的求解个数最多。因此,threshold1=100。
策略2当学习子句依据length值的大小排序,删除学习子句时,同时考虑学习子句的LBD值,若C(LBD)<threshold2,保留此学习子句,其算法如下。
算法3删除学习子句算法reduceDB2()
输入:学习子句集合Δ,学习子句个数n。
输出:新的学习子句集合Δ,学习子句个数n/2。
sort Learnt Clause(); //根据length值排序

ifclause.lbd()≥threshold2then
remove Clause();
else
save Clause();
init++;
returnΔ;
算法3同算法2一样,同样表示算法1中删除学习子句reduce DB()函数的执行过程,只是二者的排序标准不同和删除学习的条件不同。算法3中依据length排序,当符合条件clause.lbd()≥threshold2时,删除学习子句。在现有的CDCL SAT求解器中reduce DB()函数是根据LBD值排序,删除符合clause.lbd()≥2和clause.size()≥2的学习子句,但是通过3.1节的实验分析可知,此删除标准会删除部分对求解过程起到促进作用的子句,因此算法2和算法3综合考虑了两种标准,对学习子句进一步地删选,保留更多的有用子句。
同理,为了确定参数threshold2的值,测试2015年SAT竞赛的300个Application类型的实例,运行时间设置为2000 s。表2表示使用不同的threshold2所对应的求解实例个数。

表2 不同threshold2的求解个数和时间
从表2可以看出,不同threshold2相对应的求解个数相差较大,并不是随着threshold2增大而逐渐减少,当threshold2=20时的求解个数大于threshold2=15时的求解个数,但是当threshold2=10时,其求解个数最多,且平均求解时间最少。因此,threshold2=10。
4 实验
本文主要在求解器Glucose3.0版本的基础上进行实验测试,Glucose3.0是国际上知名的求解器,最近几年国际SAT竞赛专设一个基于Glucose3.0版本求解器改进的求解器分组比赛,测试求解器版本为4个,Glucose_lbd、Glucose_length、Glucose_lbd+len、Glucose_len+lbd。Glucose_lbd中单独使用基于LBD的学习子句删除策略,Glucose_length中单独使用基于length的学习子句删除策略,Glucose_lbd+len中实现策略1,参数threshold1设置为100,Glucose_len+lbd中实现策略2,参数threshold2设置为10。实验环境:Intel Core i3-3240 CPU,3.40 GHz处理器,8 GB内存,运行系统为Windows7+Cygwin2.8.1。实验中采用的测试实例来自于2015年SAT竞赛的300个Main-track组实例以及2016年SAT竞赛的Main-track组的300个Application类型的实例。这些实例来自于不同的实际问题,例如软件测试、硬件电路测试、图着色问题、网络安全等。实验中每个实例的求解时间不超过3600 s。表3表示使用4种求解器求解实例的个数对比情况。
从表3可以看出,求解器Glucose_len+lbd求解实例个数最多,Glucose_lbd求解个数最少。其中,求解器Glucose_length的求解个数较Glucose_lbd增加了1.9%,说明基于演绎长度length的学习子句管理优于基于LBD策略,增长个数主要体现在求解不可满足实例。求解器Glucose_len+lbd较Glucose_lbd求解个数增长了4.1%,较Glucose_length求解个数增长了2.1%;求解器Glucose_lbd+len较Glucose_lbd求解个数增长了2.5%,较Glucose_length求解个数增长了0.5%。说明综合考虑学习子句的评估标准的策略具有一定的优势。
图9表示4个求解器Glucose_lbd、Glucose_length、Glucose_lbd+len、Glucose_len+lbd分别求解600个实例的运行时间对比。图9中的波点曲线越靠近右边以及越靠近x轴时,说明此曲线表示的求解时间越小和求解个数越多。由图9可以看出,求解器Glucose_lbd+len和Glucose_len+lbd的求解性能均优于Glucose_lbd和Glucose_length,其中,求解器Glucose_lbd+len和Glucose_len+lbd二者的求解性能较相近,但是由表3和图9综合来看,求解器Glucose_len+lbd在求解个数和求解时间上均表现了一定的优势,其求解性能最优。

图9 不同求解器的求解性能
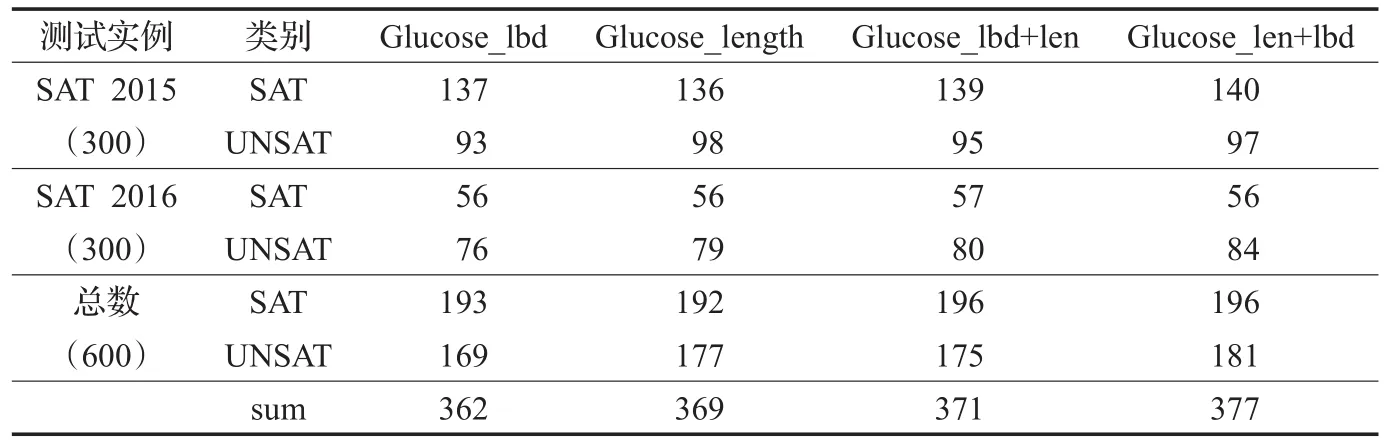
表3 不同求解器的求解实例个数
5 结束语
本文提出一种新的学习子句管理策略——基于归结演绎长度评估学习子句有效性,并与现有的基于LBD评估方法进行结合。实验结果表明,新结合算法能有效地识别出对求解过程有用的子句,提高求解效率。
本文中一些参数的设置是带有实验性质的,因此,之后可以针对参数设置做进一步的研究,更好地提升求解器的求解能力。
猜你喜欢
四川大学学报(自然科学版)(2023年1期)2023-04-29 00:44:03
四川师范大学学报(自然科学版)(2023年1期)2023-03-12 07:23:28
榆林学院学报(2022年4期)2022-08-02 14:30:42
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
计算机集成制造系统(2020年8期)2020-09-11 02:49:36
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
计算机与生活(2018年8期)2018-08-15 08:24:34
西夏学(2018年2期)2018-05-15 11:24:42
