
基于细粒度分类的汽车家族化计算分析方法
2018-08-20 02:47李宝军赵德栋
汽车工程学报 2018年4期
李宝军,董 颖,赵德栋,王 博
(1.大连理工大学 汽车工程学院,辽宁,大连 116024;2.工业装备结构分析国家重点实验室,辽宁,大连 116024)
目前,产品的外观造型与设计越来越得到企业的重视,正如RAVASI等[1]在设计管理理念中提到的,产品的设计或者造型不仅体现在功能和外观上,同时也是表达并强化品牌独特内涵的一个强有力的、具有象征意义的媒介。PERSON等[2]指出,在商业环境中,品牌间激烈的竞争导致了品牌间造型的差异化和品牌内造型的统一性,目的是使品牌具有强烈的辨识度,从而保证市场中的品牌家族化对消费群体的影响。因此,产品的外观设计对于保持市场竞争力非常重要,尤其是独特的、家族化的造型设计。对于汽车行业来说,汽车厂家,尤其是国内自主品牌厂家,建立识别度高的家族化造型对提升品牌影响力具有重要意义。国内外已有大量针对汽车造型、品牌认知以及家族化设计等的研究工作。MCCORMACK等[3]以如何发展并维持品牌形象为出发点,以别克前脸造型为例,提出利用形状语法来分析品牌造型核心特征的方法。BLUNTZER等[4]利用造型线框等特征从汽车造型与国家文化关系的角度分析了法国车系的造型设计特点。HYUN等[5]基于层级聚类的方式分析车身侧面造型相似度,并可以预测设计趋势。BURNAP等[6]提出汽车前脸设计中对自由设计与保持品牌识别进行权衡,能够为企业造型设计决策提供帮助,反映了品牌家族化对于汽车前脸设计的重要性。
对于品牌的家族化造型,研究者通常采用分析特征线等造型基因的方式展开研究,如奥迪品牌的造型基因研究[7-8],刘澳[9]通过描绘前脸特征线分析了多个品牌前脸的家族化造型基因。
这些基于造型特征线的品牌基因分析方法虽然可行,但人工介入工作繁琐,需要根据人的主观感受对造型基因进行提取。同时,需要开展大量调研工作,调查消费者与设计师对汽车造型的认知。为了更好地解决这些问题,提出对前脸造型特征的计算化分析方法,即利用模式识别算法对汽车品牌造型特征进行分析与分类。该方法无需人工选择造型特征,而是用计算机视觉技术自动提取特征并进行分析。该分析方法能够提取品牌的核心基因,完整呈现家族化的前脸造型,并且将品牌造型相似分布可视化等。本研究为汽车前脸造型的家族化分析研究工作提供了新的思路。
1 基于前脸的汽车品牌细粒度分类
采用基于计算机视觉的汽车品牌分类方法进行汽车家族化造型分析有两方面原因:一方面,人工智能的兴起使基于计算机视觉的图像处理、机器学习等技术飞速发展,汽车品牌的分类识别问题得到了广泛的研究;另一方面,中国庞大的汽车市场为汽车的识别、造型分析等提供了大规模数据,为计算机视觉方法对汽车造型大数据进行分析和挖掘提供了基础。
在当今的汽车造型设计领域,造型家族化成为汽车企业关注的重点,也是品牌发展的重要战略之一。很多汽车品牌的造型设计已具有家族化特征,如奥迪、宝马、奔驰、大众、起亚等。因此,可以试图寻找品牌下所有车型共有的、家族化的造型模式,进行品牌家族化造型的识别与分析。由此提出了利用图像处理、深度学习等计算机视觉技术,对汽车前脸造型大数据进行精确分类,进而展开对品牌家族化造型的分析。
1.1 汽车前脸造型
选取汽车前脸造型作为汽车品牌家族化设计的研究对象,一方面在于汽车前脸造型对品牌家族化的体现、品牌认知等影响较大[3,6],比如RANSCOMBE等[10]采用造型分解法分析了汽车造型中审美特征对消费者认知汽车品牌的影响,结果表明,相对汽车侧视图和后视图,汽车前视图对消费者认知品牌的影响最大,说明汽车前脸造型是品牌家族化表达的重要媒介。
另一方面,在汽车品牌与型号的细粒度分类任务中,通常选取汽车前脸作为特征提取的对象。例如,PEARCE[11]比较了几个基于前脸造型的汽车品牌与型号识别方案,并提出了LNHS的特征表示方法。GAO等[12]基于汽车前脸造型提出了改进后的卷积神经网络LTCNN,实现了汽车品牌的细粒度分类。这些研究证明汽车前脸造型包含了能够区分汽车品牌或型号的特征,即家族化特征,而且可通过计算机视觉技术提取这些特征并用来分类。
综上所述,本研究选取汽车前脸作为研究对象,对汽车品牌家族化造型进行分析,并建立基于中国市场的大规模汽车前脸图像训练库,训练库的具体信息将在数值试验部分详细介绍。
1.2 汽车品牌细粒度分类
当前的汽车品牌分类方法通常包含两大技术组成部分:特征表示方法与分类器。传统的特征表示方法,如HOG等,具有特征信息少等缺点,而基于神经网络的深度学习方法,如卷积神经网络等,虽然特征信息丰富,但大量的参数调节以及多层的网络结构对计算性能要求较高。因此,选取CHAN等[13]提出的简单深度学习网络PCANet作为特征表示方法,同时选取FAN等[14]基于SVM开发的Liblinear工具包作为分类器,用于训练分类模型。PCANet所具备的层级结构能够提取到多级的特征表示,从而保证丰富的特征信息。同时,PCANet特征提取过程的计算成本较小,因此能够快速提取到充足的特征信息。而SVM是一种监督的学习模型,对高维度特征信息的分类具有一定优势。基于SVM开发的Liblinear工具包对具有高维度信息的大量样本线性分类效果好、速度快。
LI等[15]具体研究了基于PCANet与SVM的汽车品牌识别问题,在数据集的交叉验证测试中,达到了95%以上的正确率,验证了该方法的有效性。汽车品牌分类流程如图1所示。

图1 汽车品牌分类流程图
2 汽车品牌前脸造型的计算分析
确定了汽车前脸造型训练库和汽车品牌的细粒度分类方法后,首先用分类方法对汽车前脸造型训练库进行分类训练,得到分类模型;然后对汽车前脸造型训练库进行留一法交叉验证测试(leave-oneout cross validation)。基于分类模型以及交叉验证测试结果,可以做以下分析:(1)获得品牌造型核心基因表示。(2)获得品牌“家族化脸谱”。(3)实现品牌间前脸造型相似度分析与评估。基本的分析流程如图2所示。
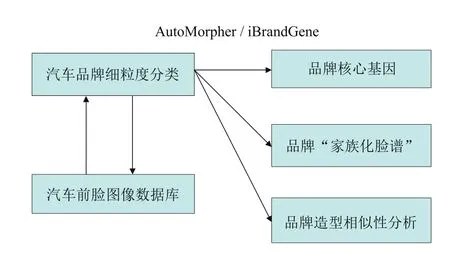
图2 汽车品牌前脸造型分析流程图
2.1 品牌造型核心基因
对汽车前脸造型训练库按品牌进行分类训练,将得到汽车品牌分类模型。利用SVM实现图像分类(one-vs-the rest)时,对应训练数据库的每个类别,分类模型中包含一个权值向量。通过这些权值向量与测试样本特征向量的乘积运算,将得到对应类别的分类识别判断值。找到其中的最大值,则认为对应最大值的权值向量的类别为识别的结果。
线性SVM的分类原理是寻找一个最优超平面,使某个类别的样本能够在最大程度上与其它类别得以区分。训练得到的权值向量则代表了每个类别的超平面信息,它们反映了每个类别中样本的共同特征,并且能用于区分其它类别的特征。
由于这些权值向量是在对汽车前脸造型特征的品牌分类训练中得到的,所以每个权值向量能够反映对应品牌下所有车型共有的造型特征和区别于其它品牌的造型特征。为此,在汽车品牌分类模型中,将这些权值向量称为品牌的造型核心基因。
基于品牌造型核心基因,一方面可以根据新一代车型的前脸造型判断该车型的品牌,评估其是否具备家族化的造型特征;另一方面,可以进一步比较和分析不同品牌的造型核心基因,进行品牌造型家族化的特征判定和品牌间家族特征的差异化分析。
2.2 家族化脸谱
在汽车品牌分类识别中,同一品牌内识别正确的汽车造型图片所对应的判断值大小并不相同,这些判断值的大小可认为是与品牌家族化造型设计的符合程度或相似度。某品牌一款车型的造型样本的判断值大,说明该车型的造型风格与该品牌的家族化风格符合程度大;而一款车型的造型样本的判断值小,则说明该车型的造型风格与该品牌的家族化风格符合程度较小。所以,将某品牌内的汽车前脸造型图片的判断值按降序排序,可得到代表家族化造型设计的车型排名。可选取前十个值对应的车型,并认为这十款车型的造型设计为该品牌前脸造型的家族化设计代表。为了更加明确地、唯一地和直观地表示出家族化造型设计,下一步可利用这十款车型构造出品牌的家族化前脸造型,即“家族化脸谱”。
2.3 品牌间前脸造型交叉分析
随着汽车品牌分类与识别技术的发展,品牌或车型的识别率不断提升。排除图片质量等原因对品牌识别带来的问题,可以认为分类识别“错误”的情况是由于品牌间车型造型较高的相似度[16]所造成的。因此,可以利用品牌分类识别错误的结果,分析品牌间家族化造型的相似性。
得到分类识别结果后,对某品牌识别成其它品牌以及其它品牌识别成该品牌的两组结果进行可视化处理,得到品牌间前脸造型交叉图(图3)。由图可知,粗线框围起的A-G区域分别代表识别为A-G不同汽车品牌的车型分布,其中,虚线围起的BA区域代表B品牌识别为A品牌的结果,AB区域则代表A品牌识别为B品牌的结果,其它同理。这样的品牌造型交叉融合图可以直观分析多个品牌间的造型相似情况。

图3 品牌间造型交叉示意图
3 数值试验
在此将结合建立的汽车前脸造型训练库,以及开发的汽车品牌前脸造型家族化分析系统(AutoMorpher/iBrandGene)进行实例分析。
3.1 汽车前脸造型训练库

图4 轿车前脸造型训练库奥迪品牌部分图片

图5 轿车前脸造型训练库大众品牌部分图片
建立汽车前脸造型训练库后,对数据库中所有车型年代信息的统计情况如图6所示。该年份统计整体上符合当前国内道路上的车辆年份分布。
与针对汽车细粒度分类任务所建的汽车数据库[17]不同,本文数据库包含只保留主要造型区域且去除背景后的汽车前脸正视图,不仅可以实现汽车品牌的细粒度分类问题,还能够根据分类结果对汽车前脸造型加以分析。
3.2 汽车品牌造型分析系统
根据本文采用的汽车品牌细粒度分类方法和创建的汽车前脸造型训练库,基于Matlab软件平台,开发了汽车品牌造型分析软件——AutoMorpher/iBrandGene,主界面如图7所示。该软件通过选取分类方法,对训练库进行分类训练以及留一法交叉验证后,便可直接对汽车品牌的造型基因、家族化造型脸谱以及品牌间造型的交叉融合进行分析。

图6 汽车前脸造型训练库年份统计

图7 汽车品牌造型分析软件界面
目前,基于PCANet与SVM的汽车品牌精确分类方法在轿车和SUV数据集中的交叉验证均达到95%以上的准确率[15],这在当前的汽车品牌分类与识别领域达到了较高甚至领先的水平。由此认为交叉验证中识别“错误”的结果,是由不同品牌间车型造型相似所导致的。因此,该方法具有较强的提取家族化造型特征,并进行特征分析、分类的能力,从而认为基于该方法所进行的品牌造型分析,包括核心基因分析、家族化脸谱分析及造型相似度分析是合理且有效的。
3.3 汽车品牌造型分析
首先利用分类方法对汽车前脸造型训练库进行分类训练,得到分类模型,然后基于汽车前脸造型训练库进行留一法交叉验证测试。最终得到的轿车品牌的综合识别率达到96.08%,其中各品牌识别率统计情况如图8所示。
通过图8可以初步判断德系、法系等欧洲汽车品牌,如奥迪、大众、沃尔沃等的品牌识别率较高,这与造型领域相关专家、研究者及社会消费者等对这些品牌前脸造型家族化程度较高的认知相符合。而日系、韩系,以及国产品牌等,它们的品牌识别率相对较低,反映出品牌前脸造型的家族化程度较低。这些结果可以由不同汽车品牌有不同的设计策略或市场策略[5]来解释。但另一方面,汽车造型向着家族化方向发展的潮流,反映出部分品牌仍然可以加强家族化造型的设计。本研究可为品牌家族化造型分析与设计提供依据与参考。根据分类模型和分类识别结果,下面进行具体的造型分析。

图8 轿车前脸造型训练库识别结果统计
3.3.1 品牌造型核心基因
以80例2型糖尿病合并胃溃疡患者作为该次研究对象,选择电脑分配方式作为分组原则,分为两组(观察组40例与对照组40例)。
以轿车品牌A、B为例,获得轿车前脸造型训练库的分类模型后,便可得到A、B两个品牌的造型核心基因,即用于分类的权重向量。由于PCANet所提取的造型特征参数的维度较高,所以SVM训练得到的品牌造型核心基因维度较高。为了直观反映这些品牌造型基因的特点与差异,进行简单的可视化处理,得到品牌造型核心基因表达图,如图9所示。根据不同品牌的造型核心基因的不同分布,分析不同品牌家族化造型之间的差异。例如,两个品牌造型基因表达图中红色矩形框区域呈现不同的分布,可根据这些信息对不同品牌的造型特征进行分析,寻找品牌家族造型的显著性特征。由于PCANet特征提取过程的复杂性,导致基因参数不能直接还原到造型图像中,所以将在下一步工作中具体研究品牌造型核心基因。此外,根据SVM分类识别的原理,品牌造型的核心基因可以用来判断与评估车型造型的家族归属和家族化程度。因此,可利用品牌造型核心基因为品牌家族化造型设计提供参考。


图9 轿车造型核心基因图
3.3.2 家族化脸谱
以国内某汽车品牌为例,根据车型造型图片识别判断值的车型图片排序如下。该品牌前十款代表车型造型图片见表1。根据表1中的10张车型图片,利用计算摄影学中的“平均脸”技术,可初步生成该品牌的家族化造型图像,称为品牌“平均车脸”,如图10所示。初步生成的家族化造型图像是模糊的,并不能清晰表达家族化造型特征信息。因此,得到代表家族化造型特征的图像后,请专业造型设计师从中提取特征,渲染后可得到家族化前脸造型图像,称为“家族化脸谱”,如图11所示。

表1 某品牌前十款代表车型图片

图10 某品牌“平均车脸”

图11 某品牌“家族化脸谱”
3.3.3 品牌间造型交叉分析
在留一法交叉验证的分类识别结果中存在“错误”识别的样本。而出现“错误”识别的原因主要有两方面:一方面,不同品牌间的车型造型存在相似情况;另一方面,由于数据库中车型的年份跨度较大,存在造型改变较大导致品牌造型核心基因变化的情况,此时可能会被识别为其它品牌的造型。
因此,为了更加直观地显示这些“错误”识别的车型,更加方便地分析品牌间的造型相似性,提出品牌间造型交叉分析,即得到分类结果后,对某品牌识别为其它品牌的样本分布,以及其它品牌识别为该品牌的样本分布进行可视化处理,得到某品牌与其它多个品牌的造型交叉融合图,如图12所示。通过图12可以整体上观察某品牌与其它品牌之间车型的造型相似情况,软件中还可以通过点击图中样本点来查看具体相似的车型。与量化分析汽车品牌间造型的相似度方法[5]不同,基于汽车品牌识别的品牌间造型交叉图并没有从数值计算的角度衡量品牌造型间的相似度大小,而是对品牌间造型相似情况进行直观呈现,以此辅助造型设计师进行分析。更重要的是,根据年份信息,可以分析每年品牌的核心基因、家族化脸谱和品牌间的造型相似性,以便对各品牌造型的演变趋势进行分析,预测下一代车型的造型设计。

图12 品牌造型交叉效果图
4 结论
明分使群:提出了基于汽车品牌细粒度分类的汽车品牌前脸造型计算分析方法,创建了汽车前脸造型训练库,并开发了汽车品牌造型分析软件。利用汽车品牌细粒度分类方法对训练库进行分类训练,得到分类模型;基于数据库对汽车品牌精确分类方法进行留一法交叉验证,得到分类识别结果。分类模型记录了能够区分品牌种群的造型模式,而分类识别结果则具体对品牌中每个个体进行归类。
和而不同:根据分类模型和分类识别结果,提出了品牌家族化造型的分析方案:(1)提取分类模型中品牌造型核心基因。(2)基于品牌内正确的分类识别结果,利用排序后的识别判断值选出家族化造型代表车型,进而生成“家族化脸谱”。(3)将品牌间“错误”的分类识别结果可视化,直观显示品牌间造型的相似性分布。由上述分析内容可知,(1)和(2)着重品牌的家族化造型,即品牌内车型共有的特征,称为“和”;(3)所呈现“错误”识别的造型,可以从品牌内造型设计创新的角度去分析,即“不同”。
与传统的分析品牌造型特征线等造型特征方法不同,基于汽车品牌细粒度分类的品牌家族化造型的计算分析方法,为汽车品牌的家族化造型分析提供了新思路。该方法能够根据汽车品牌前脸造型数据库,自动分析各品牌不同的造型特征,寻找品牌家族化的造型模式。基于该方法,提出了一系列具体分析方案,这些方案既可以将汽车品牌的家族化造型可视化,帮助造型设计师分析家族化造型特征;又可以帮助设计师分析当前的造型趋势,在设计新一代汽车前脸造型时为设计师提供参考。然而,该方法的局限性在于未能对造型元素定量化进行分析,从而为实现造型设计提供客观可能性,这将在未来的工作中加以探究。
此外,文中还有其它问题未予考虑,例如,车型销量对家族化造型设计的影响,基于造型特征线的造型基因分析等。
猜你喜欢
车主之友(2022年4期)2022-11-25
艺术科技(2019年21期)2019-01-06
现代商贸工业(2018年1期)2018-01-15
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
现代经济信息(2016年10期)2016-05-24
少儿科学周刊·少年版(2015年3期)2015-07-07
决策探索(2014年19期)2014-10-28
汽车之友(2014年19期)2014-10-11
