
基于二次特征提取的表情识别
2018-08-17 03:01梁华刚李怀德
计算机工程与设计 2018年8期
梁华刚,孙 凯,李怀德
(长安大学 电子与控制工程学院,陕西 西安 710064)
0 引 言
对于表情分类问题,主要集中在表情特征提取和特征分类两个方面[1]。表情特征主要分为纹理特征和几何特征,包括Gabor特征[2]、LBP特征[3,4]、主动形状模型[5]等,分类器有支持向量机[6]、最近邻分类器[7]等。随着对神经网络的深入研究,深度神经网络也被直接用于特征自动提取和分类[8,9],由于单一算法提取特征程度有限,特征融合的算法也备受关注[10,11]。虽然合适的特征获取方法和分类器设计使得表情识别成功率在各大表情库中得到极大提升,然而由于表情库较小、样本代表性不足、模型鲁棒性不足等原因,数据集训练并得到高准确率测试结果并不意味着已经胜任真实的面部情感识别任务[12]。设计泛化性更强的特征提取方式和表情分类模型对表情识别实际应用具有重大意义。
本文深入分析LBP特征的局限性,提出自适应阈值LBP特征描述方式,采用基于Kirsch的Canny特征作为表情辅助描述特征,然后分析面部不同区域对表情特征描述的影响,剔除无用区域,再使用DBN网络对特征图谱进行二次特征提取,使用加权方式进行最终分类,实现表情识别。表情识别过程如图1所示。
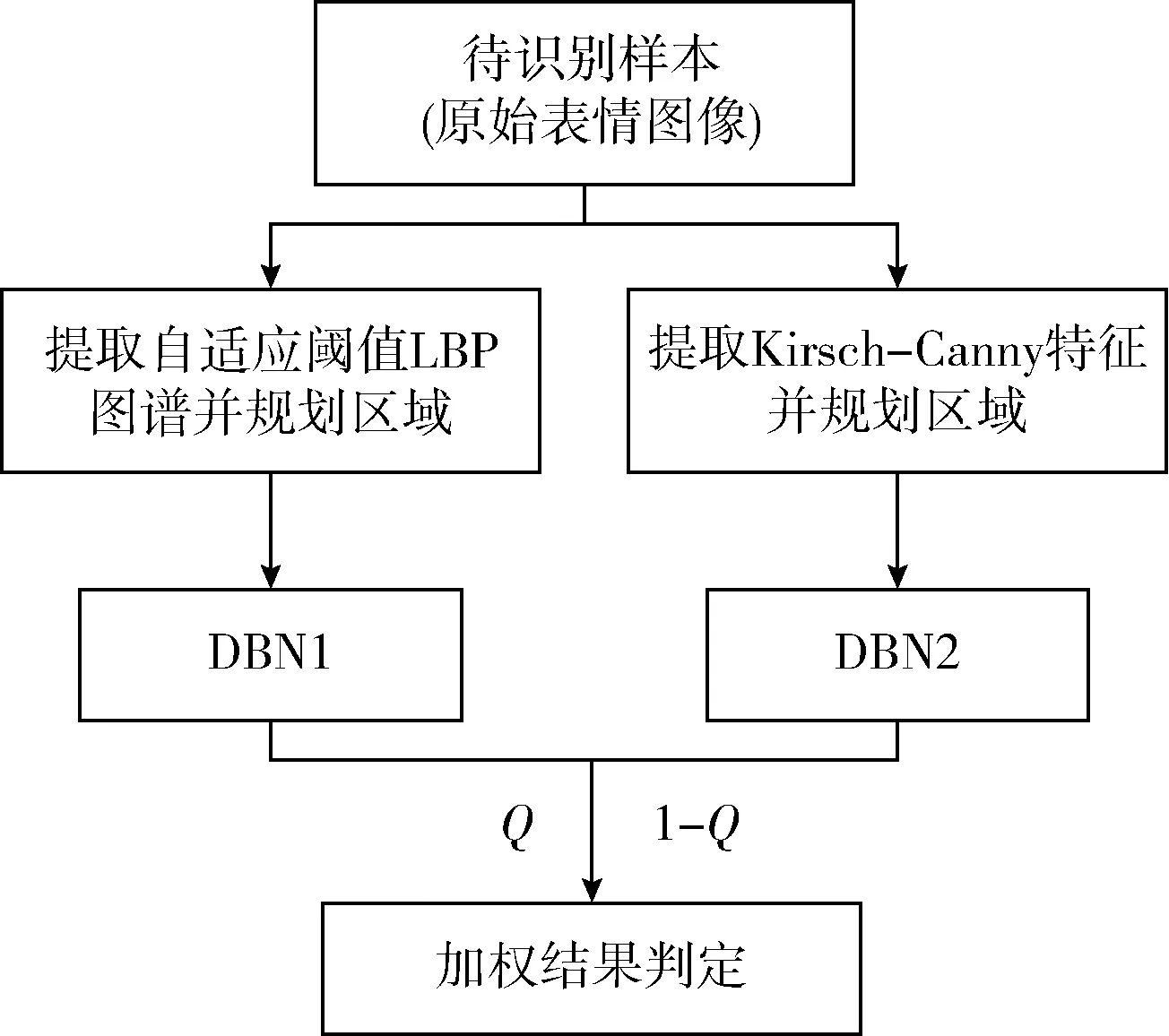
图1 整体算法流程
1 初次特征提取
1.1 自适应阈值LBP特征
旋转不变LBP目标位置的像素值由相邻8个像素决定,对中心像素的3*3邻域进行操作,大于中心像素的标记为1,小于中心像素标记为0,进行对于8个标记点循环位移,取最小值作为中心像素的LBP特征。LBP算子定义如式(1)和式(2)
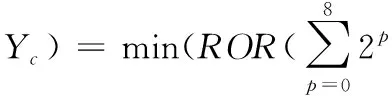
(1)
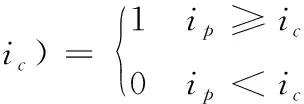
(2)
为本文叙述方便,式(2)变为
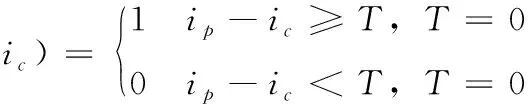
(3)
式(1)中,Xc和Yc为图像坐标,其像素值为ic,ip为邻域p个点像素值,ROR为循环位移,式(3)中T为阈值。
LBP对旋转具有一定的鲁棒性,在光照强度变化不大时,具有一定的鲁棒性。然而由式(1)可以看出,当灰度值变化非严格均匀的时候,可能导致特征差异巨大。事实上,由于人脸表面的不同部位对光线反射不同,在光照变化时灰度值变化通常不同,如图2(a)过程所示,微小的灰度不均匀变化可能导致特征值差异巨大。
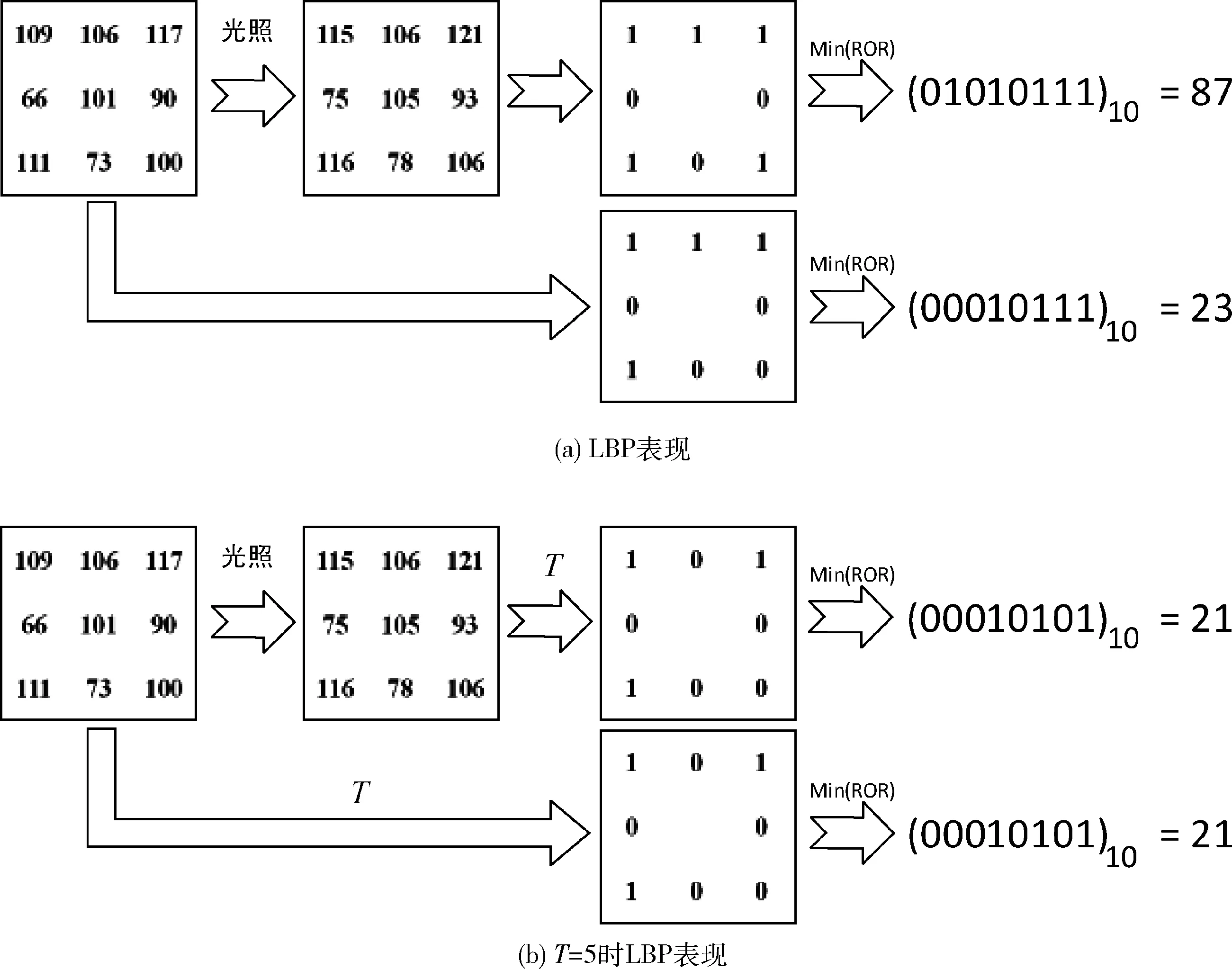
图2 非均匀光照下LBP表现
对式(3)中T做出改变,能够有效增强LBP特征对光照强度改变的鲁棒性,如图2(b)所示,取T为5,灰度的非均匀变化对LBP特征值没有影响。不同个体、光照、人种、设备等条件采集的人脸表情图像灰度差异性很大,固定LBP的阈值T无法保证不同情况下的LBP图谱表现良好,因此本文提出自适应阈值LBP,以增强模型的泛化性。
自适应阈值选取和图像灰度有关,合适的阈值能得到良好的LBP图谱,保留表情主要信息,忽略次要信息。由式(3)和图2知,阈值T增大,图像对灰度的非均匀变化容忍度提高,即较大的非均匀变化也不影响特征值的大小。由于式(2)和式(3)产生较多的0,所以会丢失部分信息,当阈值增大到255时,图像对于光照改变的鲁棒性达到最强,即光照改变对LBP图谱不再产生影响,但同时丢失原始图像全部信息。如图3所示,当T为0时,为传统LBP特征,特征表现不明显,无法直接将LBP图谱作特征使用,当阈值T增大到3,特征逐渐明显,表情信息被提取出来,然而仍有较多的干扰信息,当T增大到12,表情信息明显,干扰信息较少,可直接将LBP图谱作为表情特征使用。当T增大到30,表情信息丢失,眼睛等区域丢失严重,当T增大到255,图像完全丢失信息,由式(3)可知,此时图像像素值全部为0。

图3 不同阈值产生的特征图谱
当图像灰度分布集中时,由于灰度分布紧凑,较大的阈值使得图像丢失信息严重,图4(a)中T为12时,嘴巴区域特征几近消失,当T为9时,虽然有较多冗余信息,但是保证了表情信息完整。如图4(b)所示,当图像灰度分布均匀时,较小的阈值使得图像中表情信息不够突出,冗余信息较多,当T为12时,冗余信息基本去除,而表情主要特征也得以保留。因此对于灰度分布集中的图像应采用较小的阈值才能保证保留足够的表情信息,对于灰度分布均匀的图像采用较大的阈值以保证去除冗余信息,保留表情主要特征。
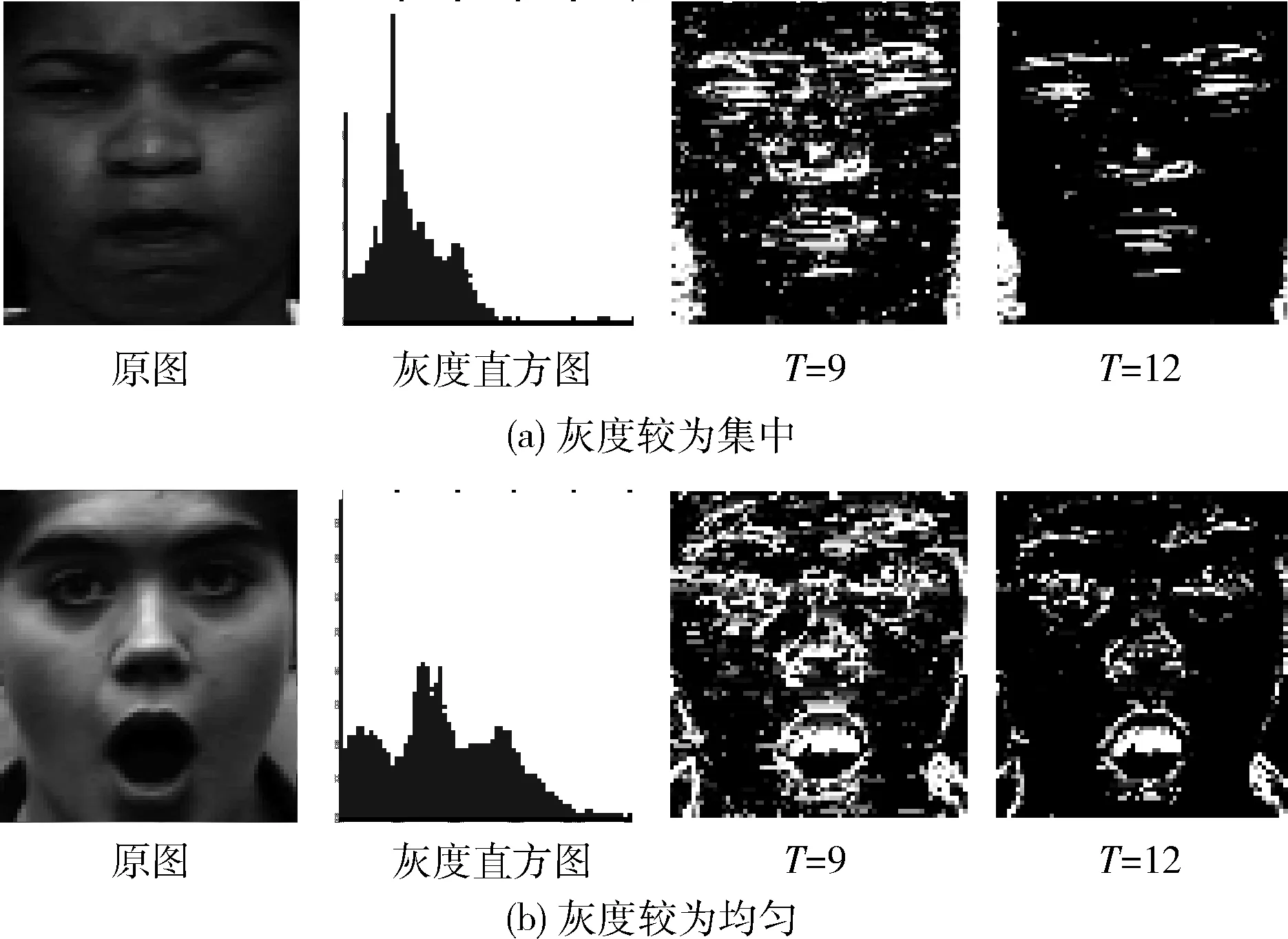
图4 不同灰度分布对阈值选取的影响
过强曝光、曝光不足、极端、肤色、不同表情所致嘴巴内反射光线不足等,导致的表情图像灰度直方图在直方图两端出现突变,使得图像灰度在直方图两端集中,也会造成阈值选取出现偏差。
本文综合人种、光照改变、机器差别等各种情况,提出自适应阈值LBP特征,使特征图谱更能适应非限制条件下的特征抽取。阈值选取步骤如下。
自适应阈值选取算法:
输入:图像I,边界阈值b(boundary),比例pr(proportion),缩小系数r(ratio)。
输出:阈值T
(1)获取图像灰度直方图g1;
(2)g1两端各前进b个灰度,舍弃其中像素,即舍弃灰度0至b之间和灰度255-b至255之间的灰度,得到新的灰度直方图g2,其统计像素总数暂记为M;
(3)g2两端各前进M*pr个灰度,舍弃其中像素,即自左而右和自右而左舍弃灰度等级个数均为M*pr,得到新的灰度直方图g3,其剩余灰度等级数为long;
(4)由公式T=long/r计算阈值T,输出T;
(5)结束算法。
上述算法步骤可由图5表示,步骤(2)舍弃灰度直方图左端和右端的灰度可剔除图像中因人种、过度曝光等因素使直方图出现的灰度突变,如图4(b)中,由于吃惊表情张大嘴部区域,光线反射不足,导致灰度0的像素个数极大增多,此部分为表情种类判别的干扰信息。对于g2中像素总数M为
(4)
图5 自适应阈值选取过程
由于人脸像素分布相对集中,不考虑灰度等级出现大的断层的基础上,由两端向中间各剔除占比为pr的像素个数,得到g3中为表情图像主要特征灰度分布区间。对于大部分图像,如图4(a)所示,除主要灰度分布区间,其它灰度区间也有部分像素分布,步骤(3)去除此部分灰度像素。剩余灰度区间的区间上界up区间下界down满足
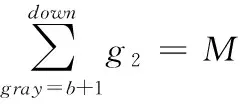
(5)
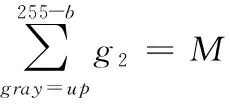
(6)
g3和g2间像素个数关系为
(7)
最后区间长度和缩小系数r相乘得到自适应LBP特征的最终阈值。
此方法中用到3个参数,边界阈值b,比例pr,缩小系数r,b由实际环境决定,pr决定了g3中信息保留程度,r直接决定阈值大小。
图3中就表明合理选择参数值得到的自适应阈值LBP特征图谱比LBP特征图谱更能反映表情特征,且上文已分析出自适应阈值LBP特征比LBP特征对于灰度改变具有更强的鲁棒性。本文通过随机抽取数据库中表情进行对比实验,确定采用参数(5,0.05,7),即剔除灰度等级0-5和灰度250-255之间的像素,保留剩余像素90%,剩余灰度等级长度缩小7倍。
1.2 Kirsch-Canny特征
自适应阈值LBP特征图谱增强了对表情图像灰度变化的鲁棒性和非限制条件下表情特征提取的适应性,但由于参数选择的特殊性,图像仍会丢失部分信息,或残余较多干扰信息,因此采用其它特征进行辅助表情种类判定。本文采用Kirsch特征和Canny特征结合的特征图谱作辅助判定。
表情信息主要包含在面部器官的相对分布和纹理上,Kirsch算子和Canny算子是提取表情纹理的很好方式。Kirsch算子采用8个卷积核对周围卷积,最大响应作相应输出。Canny算子是多级边缘检测算法,对图像进行高斯滤波,然后采用sobel算子求取图像横向边缘响应和竖向边缘响应,求取两种边缘响应的模,即为图像的Canny响应。Kirsch算子对于弱边缘提取响应不强,而对噪声点响应强烈,Canny算法由于对图像进行高斯滤波,因此对单个噪声点响应不强,而对边缘响应强烈。本文对表情图像进行Kirsch特征处理之后进行Canny边缘检测,得到的Kirsch-Canny特征图像做表情识别的辅助判定。如图6所示,Canny响应对表情纹理描述清晰,Canny-Kirsch特征描述模糊,如眼睛区域已经无法进行辨认,但Kirsch-Canny特征保留了Canny特征对纹理描述清晰的优点同时增大了边缘响应,即边缘点灰度值更高。
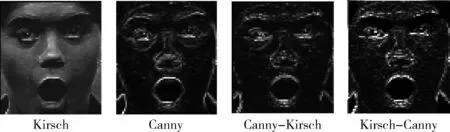
图6 特征比较
1.3 面部区域划分
除肤色、光照等条件不同导致的表情识别泛化性差,其它个体差异和背景差异也是重要原因。
如图7所示,将表情划分16个区域,表情特征主要分布于区域1、2、3、4、5、6、7、8、10、11、14、15,少部分分布于区域9、12,而区域13、16,对于同一个体的表情或同一背景环境下的判别有帮助,而不同个体之间或不同背景,即使表情类别相同,也有较大差异。

图7 面部区域划分
当样本足够大的时候,深度神经网络忽略非主要特征而寻找表情标签和表情图像之间的关系,将自动学习背景,背景也是必须学习的部分,因此深度学习中样本数量级多在105以上。当样本不够大的时候,表情非主要特征将影响表情图像和表情类别之间的映射关系,本文实验采用CK+数据库和各大搜索引擎上搜索自制的数据库,样本基数不够大,因此剔除对表情识别作用不够的区域13和区域16,减小因个体差异引起的误判,此方法亦应用于自适应阈值LBP特征和Kirsch-Canny特征。
2 DBN网络
DBN网络是由多层限制玻尔兹曼机(restricted Boltzmann machines,RBM)组成[13],由RBM的能量模型和贝叶斯公式,得到隐含层的概率模型和输入层概率模型[14],见式(8)、式(9)
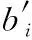
(8)
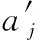
(9)
式中:H为隐含层矩阵,V为可见层矩阵,W为可见层和隐含层权重矩阵,a为可见层偏置变量,b为隐含层偏置变量。
为提高RBM模型训练效率,采用对比散度的方法更新参数[15]
ΔWij=ε(
(10)
Δai=ε(
(11)
Δbi=ε(
(12)
式中:ε为学习效率,<·>data和<·>recon分别为当前模型和重构模型上的数学期望。
RBM逐层训练称为DBN的预训练,预训练完成后使用反向传播算法对参数进行微调。
3 实 验
本文实验Matlab平台上进行实验验证,采用CK+数据库验证算法有效性,在自制表情库中验证算法泛化性。在327个有标签表情序列中,选取表情明显而剔除表情中间过程和表情不明显的图片,对表情序列取最后几帧图片,且框选出人脸区域。由于数据库采集表情的环境固定,为验证算法泛化性和鲁棒性,从各大互联网引擎搜集害怕、高兴、悲伤、愤怒、吃惊、轻蔑、厌恶7种表情各150张再从多个实验个体采集7种表情各150张图像构成Wild数据库,即2187样本的CK+库和2100个样本的Wild数据库。Wild数据库同CK+库相比,实验个体完全不同,背景环境不同,光照条件不统一,因此比CK+库更具普遍性。部分对比如图8所示。

图8 部分样本对比
对2187个样本的每一张表情图片,随机取7种表情各60张作为验证集,在剩余样本中再随机取7种表情各60张作测试集。其它1347个样本,首先扩大训练集数据集,以滑窗的方法以5像素为步长,从图像中心向8个方向滑动,再分别做镜像操作,得到18张图像,总共得到24 246张表情图像,打乱顺序构成训练集。
训练过程如图9所示,分别获取图像两种特征,均归一化至28*28,按照面部区域划分,剔除区域13和16的干扰信息,剩余区域构成两个686维行向量,分别作为两个DBN网络输入,训练出两个DBN网络,然后使验证集正确率最大以确定权重Q。本文实验DBN网络可见层686个神经元,3层隐含层分别有400、200、100个神经元,由文献[14-16],设定学习率0.5,BP网络的学习率7.5,顶层采用sigmoid函数。
3.1 实验结果
为降低实验偶然性,对实验进行5次,每次均在CK+数据库中随机抽取验证集和测试集,CK+数据库中的测试集结果见表1,Wild测试集结果见表2,其中同比下降百分比为表2中平均识别率比表1中平均识别率的下降百分比。
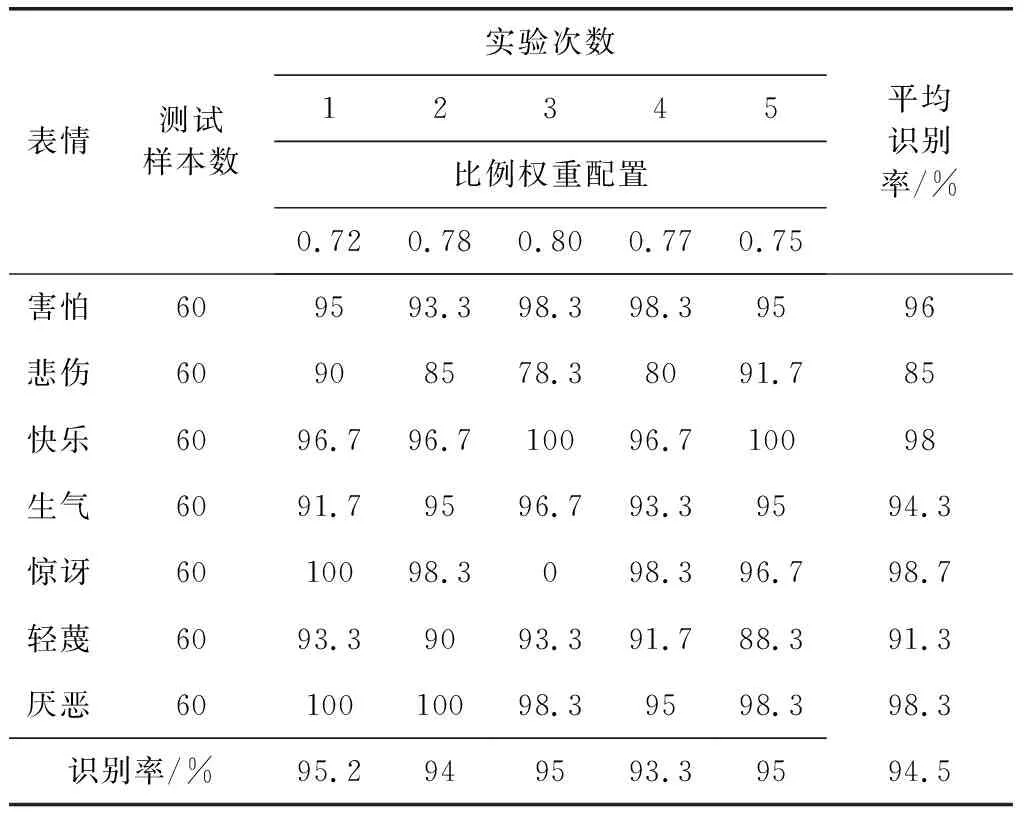
表1 CK+数据库实验结果
由表1比例权重配置,可知,自适应阈值LBP图谱所训练得到的DBN网络权重占比在70%以上,即以网络1结果为主,以网络2结果为辅,得到的成功率最高,平均识别率达到945%,验证了算法的有效性。同时,厌恶、惊讶、快乐、害怕的平均识别率均达到95%以上,对悲伤的识别率最低,本文认为是由于悲伤特征不够明显的同时,样本数量较少,每次抽取验证集和测试集后仅剩余108个原始样本,而惊讶样本虽然较少,但是特征极为明显,因此正确率很高。
由表2可以看出,使用新的测试集识别率全部下降,平均识别率下降至81%,比CK+库中识别率均下降10%以上,本文认为有两个原因:一是CK+库中采集环境极为正规,背景环境相对很少,且相同表情对同一个体采集的图像相似度极高;二是训练样本太小,对于DBN网络而言信息量太小,尤其特征不明显的表情需要大量样本进行训练,而数据库无法提供。虽然使用了交叉验证,但也因此掩盖了过拟合现象。对于害怕表情,正确率下降232%,本文认为是由于CK+库中害怕表情引导明显,肌肉组织运动幅度大,而Wild数据中特征不如CK+库中明显所致。
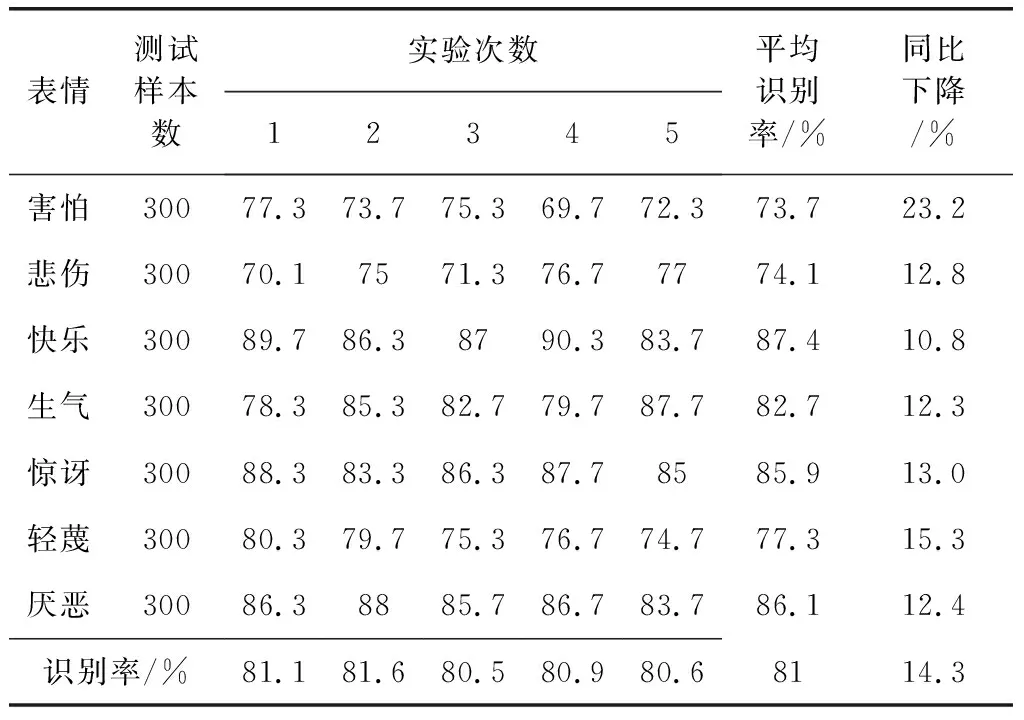
表2 Wild数据库实验结果
3.2 对比实验
为验证本文所述方法泛化性更强,实验设置了与其它方法的对比。对比实验数据采用相同训练集和两个相同测试集,实验结果见表3。
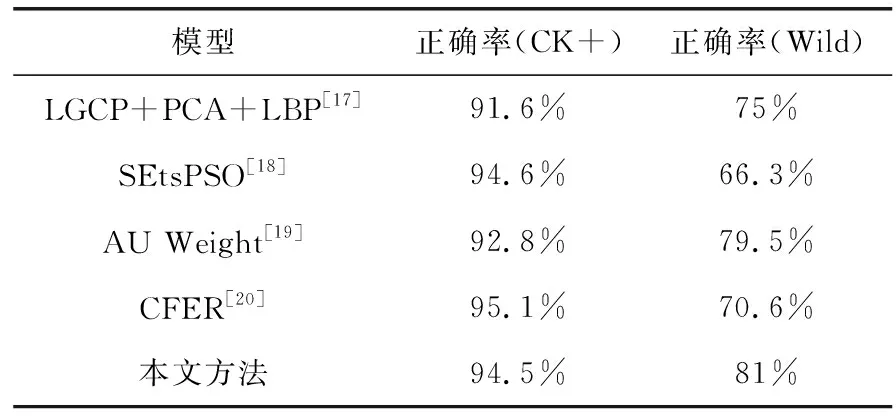
表3 对比实验
由对比实验可以看出,文献[18,20]中方法在CK+数据库中正确率略高于本文方法,但在Wild数据库中表现明显比本文方法差,文献[19]中方法在CK+数据库中正确率比文献[18,20]中正确率低,但是在Wild数据库中表现较好。对比实验中在Wild数据库中的表现说明本文方法在保持高正确率的同时泛化性更强。
4 结束语
本文改进LBP特征,使自适应阈值LBP特征图谱可直接用于表情分类,优化表情识别模型,使基于DBN的表情识别泛化性更强。
在实验中发现,自适应LBP特征的阈值选取对于大多数图像能够保留主要特征的同时剔除冗余信息,而对于灰度直方图有较大断层的图像表现较差,造成冗余信息较多,是影响识别率进一步提升的主要障碍,辅助判断特征的选择也是值得探讨的问题。且本算法时间代价远大于其它方法,对时间代价进行优化是下一步进行的研究。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
小哥白尼(军事科学)(2022年2期)2022-05-25
天津医科大学学报(2021年1期)2021-01-26
少先队活动(2020年12期)2021-01-14
红领巾·萌芽(2019年8期)2019-08-27
中国与非洲(法文版)(2017年10期)2017-11-23
中成药(2017年3期)2017-05-17
自动化学报(2017年5期)2017-05-14
领导科学论坛(2016年9期)2016-06-05
CHIP新电脑(2016年3期)2016-03-10
