
基于Hadoop的维吾尔文文本分类
2018-08-17 03:00艾比布拉阿不拉哈力旦阿布都热依木吴冰冰
计算机工程与设计 2018年8期
艾比布拉·阿不拉,马 振,哈力旦·阿布都热依木,吴冰冰
(新疆大学 电气工程学院,新疆 乌鲁木齐 830047)
0 引 言
对于文本分类,已有不少这方面的研究,但是利用大数据的处理方式来进行维吾尔文文本分类的研究还处于起步阶段。文献[1]提供了一种使用字符级卷积网络进行文本分类;文献[2]设计了一种适用于文本聚类任务的特征选择算法,提出词条属性的概念;文献[3]提出一种基于TextRank算法和互信息相似度的维吾尔文关键词提取及文本分类方法;文献[4]提出一种基于深度置信网络的维吾尔文短信文本分类模型;文献[5]使用了一种自动的维吾尔文组词算法dme-TS,该算法用一种组合统计量(dme)来度量文本中相邻单词之间的关联程度。
本文结合Hadoop分布式计算的特点与改进维吾尔文组词算法(DM算法)的优点,运用MapReduce并行计算模型,然后再利用Hadoop生态环境下的子项目Mahout来对组词后的文本进行维吾尔文文本分类计算,其中包括文本的序列化、向量化、训练贝叶斯分类器和分类器的测试,设计了基于Hadoop和改进维吾尔文组词算法的文本分类模型,并用实验进行验证。该模型在维吾尔文检索系统、舆情分析等方面具有重要的意义。
1 改进的维吾尔文组词算法
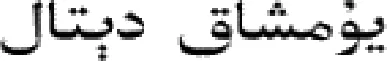
1.1 互信息(mutual information)
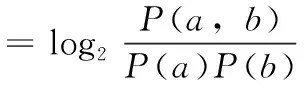
(1)

(2)
其中,T是阈值,当互信息值大于T时,即单词a,b之间是强关联,则表示单词a,b应该连在一起,作为一个特征单元。反之,则应该断开。
1.2 t-测试(difference of t-test)
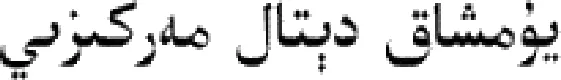
(3)
其中,P(c|b)、P(b|a)分别是b关于c和a关于b的条件概率。σ2(P(c|b))、σ2(P(b|a))是各自的方差。单词b与单词a和c的关系如式(4)
(4)
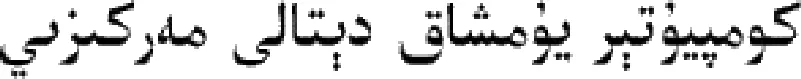
dts(x,y)=ta,y(x)-tx,b(y)
(5)
当dts(x,y)>α(α为阈值),则单词x,y之间是强关联,应该连在一起。
1.3 组合互信息和t-测试差的统计量
由于互信息反应的是两个单词之间的静态结合力,t-测试差考虑了上下文关系。这两种算法在一定程度形成优劣互补,因此可以将其线性组合成一种新的DM算法,首先考虑到MI和dts之间的变化范围不一样,因此现将其标准化,即分别算出其各自对应的标准差MI*(x,y)、dts*(x,y),然后按照一定的权重比值将其叠加在一起,如式(6)
dm(x,y)=α×MI*(x,y)+β×dts*(x,y)
(6)
α,β分别为互信息和t-测试差的权值系数。
1.4 DM分段式组词算法
在对维吾尔文文本进行预处理的时候,由于标点符号两边的单词不可能组成在一起,因此在组词前必须先保留标点符号,在组词结束后在对其去除。本文首先对文本按标点进行分段处理,然后在每一段分别进行组词。
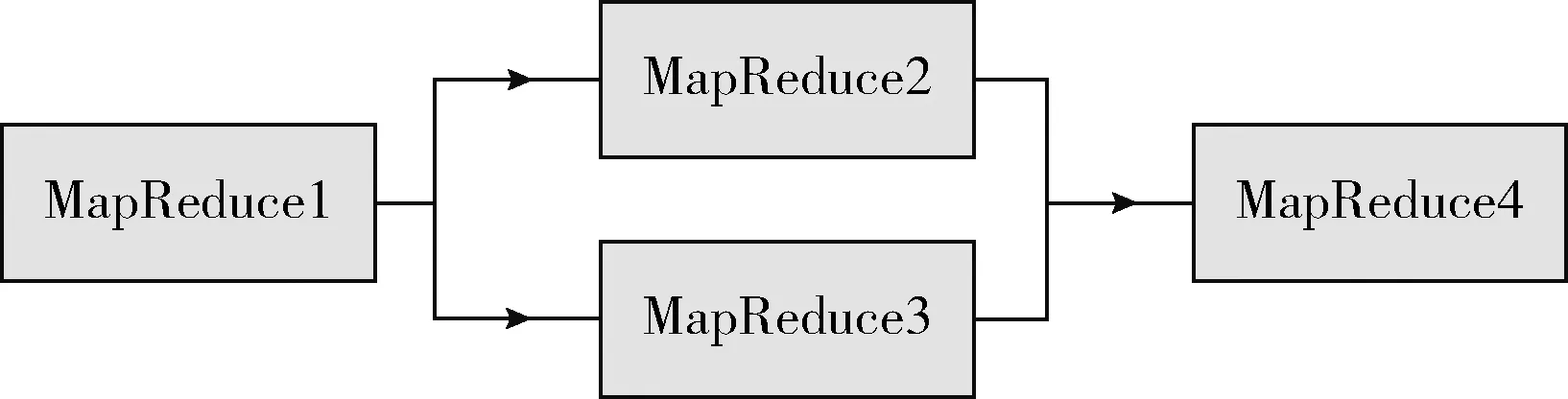
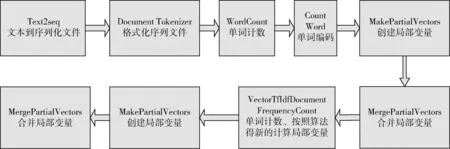
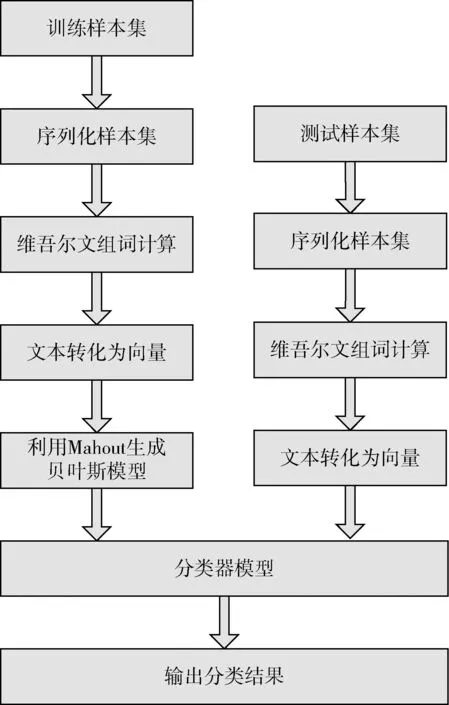
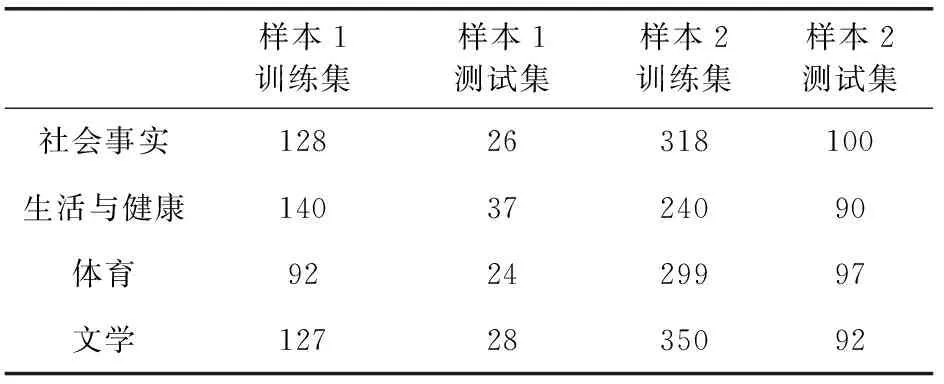
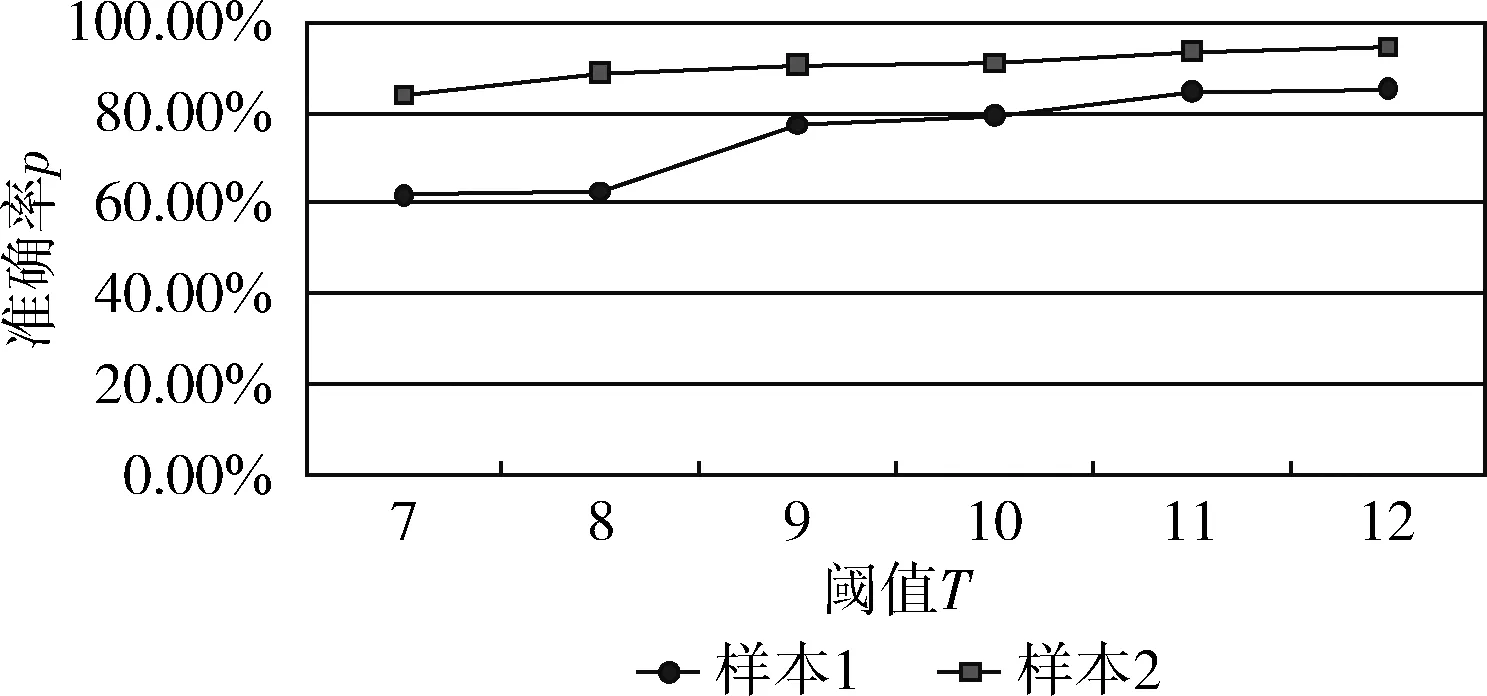
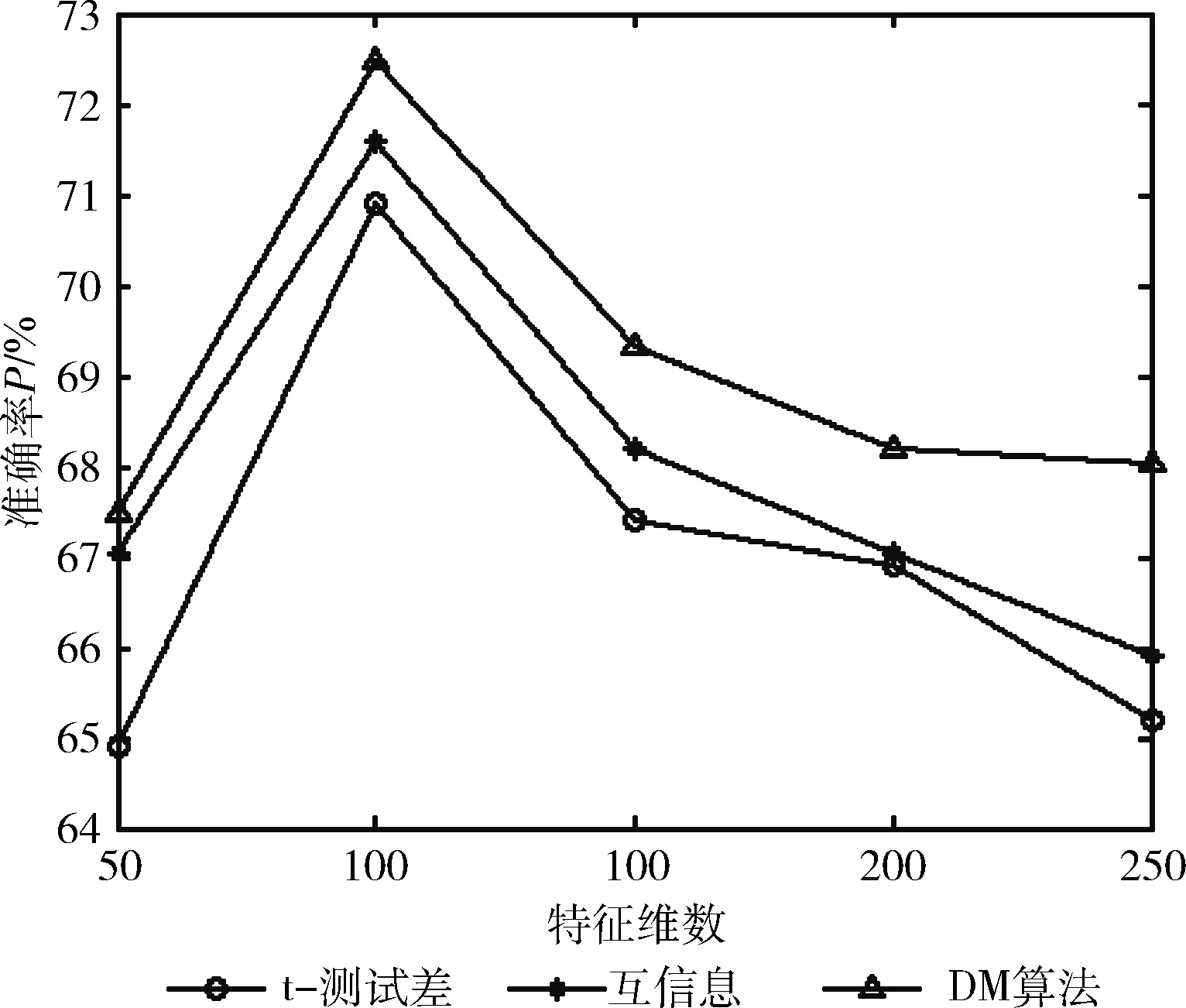
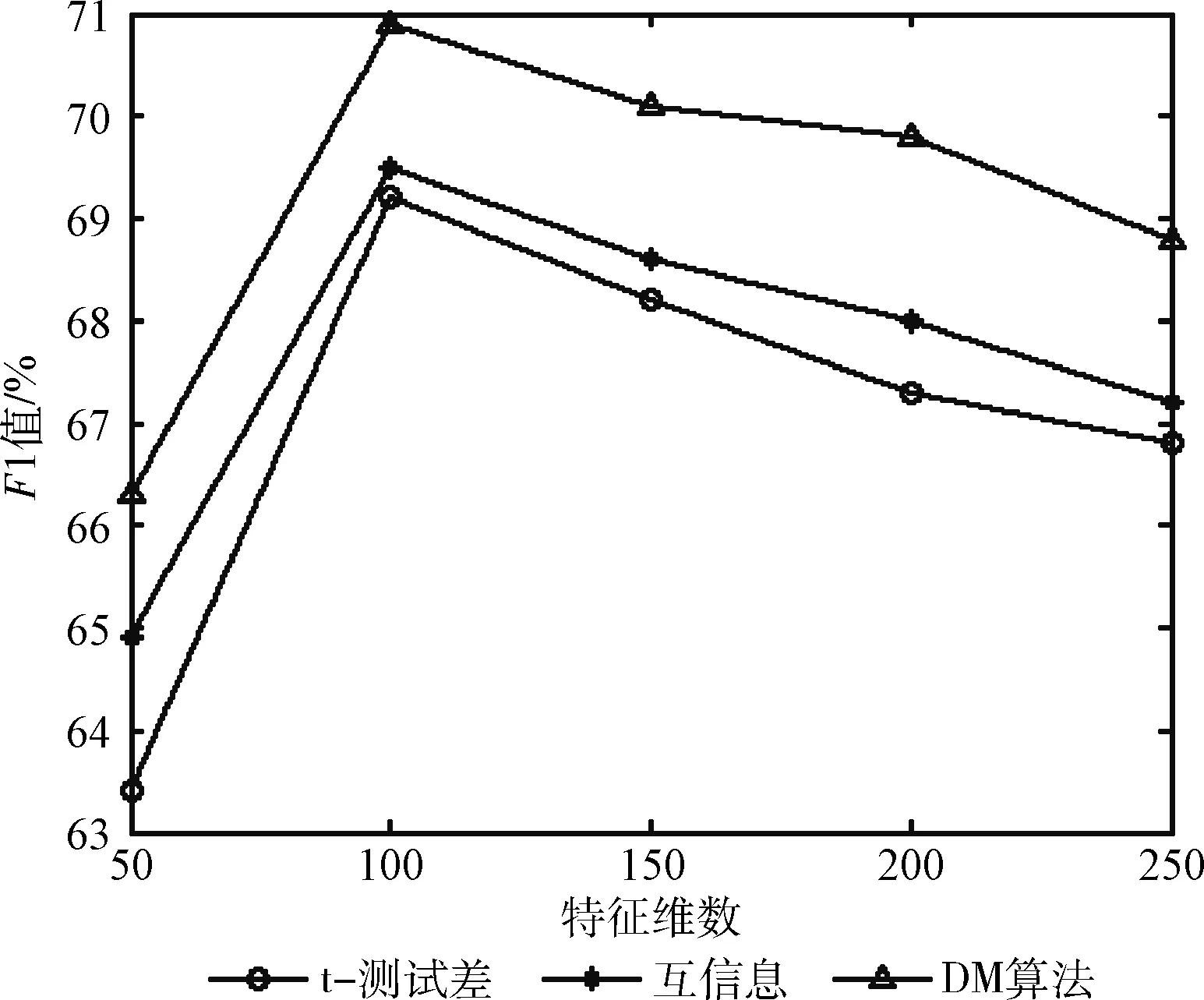
从文本集中读取一个文本,按标点符号将其才分成长度不同的m个字符串;然后依次计算出每个词串中的每个单词之间的dm值,并与给定的阈值进行比较。假定dm给定的阈值为T,如果dm(x,y)>T,则单词x和y之间应该组合在一起。反之,如果dm(x,y) 图1 语义划分实例 由于实验平台是以Hadoop为基础的,采用的是分布式文件处理系统HDFS,它处理的任务是用MapReduce进行编写程序的。因此特征抽取的并行化处理是必不可少的过程[6]。 并行DM算法在Hadoop平台上的实现步骤如下: 步骤1 初始化Hadoop任务。用户向ResourceMana-ger提交Job。 步骤2 读取并复制源数据。将源数据复制到Hadoop的分布式文件系统HDFS中,并合理分配到各个子节点。 步骤3 MapReduce过程。实现各个子节点映射数据集并处理。 特征抽取一共分为4个MapReduce任务,执行流程如图2所示。 图2 MapReduce任务执行流程 第一个MapReduce的任务是统计每类包含的文档数,文档总数,每个单词出现的频数; 第二个MapReduce的任务是计算相邻两个单词的互信息,输出键值对<(x,y),MI(x,y)>; 第三个MapReduce的任务是计算相邻两个单词的t-测试差,输出键值对<(x,y),dts(x,y)>; 第四个MapReduce的任务是计算dm(x,y),并根据其值组词输出。 组合式MapReduce计算作业每个子任务都需要提供独立的作业配置代码。MapReduce1的输出路径outpath1将作为MapReduce2和MapReduce3的输入路径。MapReduce4任务必须要等MapReduce2和MapReduce3执行完成后才能执行,其组合式MapReduce作业的配置和执行代码如下: //子任务mapreduce1配置执行代码 Configuration jobconf 1=new Configuration(); job1=new Job(jobconf1,“Job1”); job1.setJarByClass(jobclass1); … … //job1的其它设置 FileInputFormat.addInputPath(job1,input1); FileOutputFormat.setOutputPath(job1,outpath1); job1.waitForCompletion(true); //子任务mapreduce2配置执行代码 Configuration jobconf2=new Configuration(); job2=new Job(jobconf2,“Job2”); FileInputFormat.addInputPath(job2,outpath1); … … //job2的其它设置 //子任务mapreduce3配置执行代码 Configuration jobconf3=new Configuration(); job3=new Job(jobconf3,“Job3”); FileInputFormat.addInputPath(job3,outpath1); … … //job3的其它设置 //子任务mapreduce4配置执行代码 Configuration jobconf4=new Configuration(); job3=new Job(jobconf4,“Job4”); FileInputFormat.addInputPath(job4,outpath1); … … //job4的其它设置 //设置job4与job2的依赖关系,job4将等待job2执行完毕 Job4.addDependingJob(job2); //设置job4与job3的依赖关系,job4将等待job3执行完毕 Job4.addDependingJob(job3); //设置JobControl, 把job任务加入到jobControl JobControl JC=new JobControl(“sumJob”); … JC.run(); 基于Hadoop和DM算法的文本分类模型的方法包括文本序列化、改进维吾尔文组词算法、文件向量化、朴素贝叶斯分类算法,最终实现维吾尔文文本的准确分类。具体步骤如下: 步骤1 采用MapReduce计算模型将文本数据转化为Hadoop能够处理的SequenceFile文件。每一行的key值为每个文件夹的名字加上文件夹下面的文件名,value值为文件夹下面的文件内容[7]。 步骤2 利用MapReduce计算模型对序列化文件进行DM算法组词计算。 步骤3 把经过DM算法处理过的序列文件转化为向量文件。具体实现如下: (1)对序列化文件进行单词计数、单词编码。 (2)创建并合并局部变量。 (3)对局部变量采用TF-IDF算法计算得到新的局部变量。TF-IDF算法如下: 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率,如式(7)所示 (7) 其中,ni,j是该词ti在文件dj中出现的次数,而分母是在文件dj中所有字词的出现次数之和。 逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。如式(8)所示 (8) 其中,|D|是语料库的总数,|{j:ti∈dj}|包含词语ti的文件数目。 某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF,如式(9)所示 tfidfi,j=tfi,j×idfi (9) (4)创建局部变量并合并。 序列化文件到向量文件这步可分为8个小步骤,在Mahout中是由7个Job和1个reduce操作并分别执行的[8]。文本转化为向量流程如图3所示。 步骤4 利用Hadoop的子项目Mahout[9]训练朴素贝叶斯,生成分类器模型。 分类器生成之后,接着就是对分类器进行测试。基于Hadoop和DM算法的文本分类模型的整体处理流程如图4所示。 数据源来源于新疆维吾尔自治区人民政府网(http://www.xinjiang.gov.cn/)和Ulinix(http://www.ulinix.com/)等主要维吾尔文门户网站。实验数据描述见表1。 图3 文本转化为向量流程 图4 维吾尔文文本分类流程 样本1训练集样本1测试集样本2训练集样本2测试集社会事实12826318100生活与健康1403724090体育922429997文学1272835092 本次实验的实验环境为,采用的3台计算机,一个namenode,两个做datanode,操作系统为CentOS 7.0,Hadoop版本为2.7.0,Java安装的版本为jdk1.8.0-20,Mahout版本为0.9。Maven版本为3.2.3。 文本分类中对性能评估[10]的指标有很多,其中常用的有查全率(recall,R)、查准率(precision,P)和F1值等。P=分类正确的文本数目/所有的分类文本数目,R=分类正确的文本数目/应有的文本数目 实验1:DM算法阈值T的确定:将DM算法的阈值T设置为不同的数,得到相应的分类结果,实验结果如图5所示。在此,设置11为阈值T进行后续的实验。 图5 不同阈值下的维吾尔文文本分类的准确度 实验2:本文改进算法与互信息算法、t-测试差算法的比较。实验采用样本1和样本2数据,特征维数从1000到6000之间取值,对查准率(P)和平均值F1的值的变化进行了统计和对比,如图6、图7所示。 图6 改进算法与互信息、t-测试差的分类准确率 图7 改进算法与互信息、t-测试差的F1值 实验结果表明: (1)由图5可知,当样本数目确定的时候,维吾尔文文本分类的准确率跟组词时所取的阈值T有关,当T≥11时,分类的准确率趋于稳定。 (2)由图6可知,当特征维数小于100时,3种算法的准确性都是呈逐渐上升趋势。当特征维数大于100小于250时,3种算法都是缓慢下趋势。总体来看,本文改进算法优于互信息算法和t-测试差算法。 (3)由图7可知,从F1值方面来看,本文改进算法也在分类性能方面也都明显高于互信息算法和t-测试差算法。
2 DM算法的并行化
3 基于Hadoop和DM算法的文本分类模型
4 实验及结果分析
4.1 数据集
4.2 分类及性能评估
5 结束语

猜你喜欢
制造技术与机床(2019年9期)2019-09-10
成都信息工程大学学报(2019年5期)2019-05-21
小学生学习指导(低年级)(2019年5期)2019-04-29
西南交通大学学报(2018年6期)2018-12-18
小天使·一年级语数英综合(2018年1期)2018-06-22
计算机应用(2016年10期)2017-05-12
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
探测与控制学报(2015年4期)2015-12-15
遥感信息(2015年3期)2015-12-13
伴侣(2015年5期)2015-09-10
