
基于矩阵译码算法的改进研究
2018-08-15 08:15:06范迪萧枫唐聃
计算机应用与软件 2018年8期
范 迪 萧 枫 唐 聃
(成都信息工程大学软件工程学院 四川 成都 610225)
0 引 言
随着计算机技术的迅猛发展,信息技术在各个行业和领域都得到广泛的普及,数据也呈爆炸性的增长,使得人们对存储系统的要求越来越高。日益增长的存储需求使得存储系统中的存储节点数量和单节点容量都呈指数级增长,这就意味着发生节点失效的概率以及单节点中的扇区失效的概率越来越大,因此数据容错是存储系统中一项不可或缺的关键技术。目前使用较多的容错技术为多副本复制技术,通过复制副本进行容错。另外一种是纠删码容错技术,通过编码进行容错。编码理论始于1948年Claudo Shannon发表的著名文献[1]。最初编码理论的主要应用领域为通信,纠删码是为了解决网络传输问题中多址传送而提出来的,比较重要的一篇文献是 1997 年Luigi Rizzo的文献[2],该文主要提出了利用纠删码提高通信协议可靠性的方法,使用前向纠错码 Reed Solomon 来解决网络传输中一定数量的数据包丢失,原始数据还能恢复,并提出了一套可行的方案,同时该文提出纠删码可以应用于分布式存储系统。纠删码技术主要是依靠纠删码算法将原始的数据进行编码得到冗余元素后存储,以达到容错的目的。在存储系统中,它的主要思想是通过将k块原始的数据元素编码得到m块冗余元素,当其中有m块元素失效时,可以通过一定的解码算法利用余下的元素将丢失元素恢复出来。与多副本容错技术相比,纠删码容错技术可以在显著降低存储空间消耗的同时提供相同甚至较高的数据容错能力。
对于纠删码而言,最重要的就是其编解码算法,每一类纠删码都有本身所对应的解码算法,优秀的解码算法可以帮助提高存储系统故障恢复的效率。同时也存在一些通用性的解码算法。例如归并译码和矩阵译码等。文献[3]中提出的一种在二元域上的纠删码解码算法(简称归并译码),通过对校验矩阵分块并求逆来重建磁盘数据元素,但是此算法的运算过程涉及到逆矩阵的计算,因而当恢复单错时效率较高,一旦出现多错,求逆运算会很大程度影响到运算的速度,从而影响解码效率。文献[4]中提出一种针对纠删码的通用解码算法,这种算法基于生成矩阵及其伪逆矩阵(简称矩阵译码),对于丢失数据扇区,一般声明为两种结果,一种是算法可恢复即理论上可恢复,此时算法会提供一个由可读数据构成的公式来恢复丢失扇区,一种是理论上即不可恢复的扇区。对于阵列码,矩阵译码算法还可以恢复随机数据扇区的故障,解决了随机扇区丢失的问题,由此提供了更好的实用性,也提高了存储系统的性能。矩阵译码算法既解决了阵列码中随机扇区丢失的恢复问题,同时摒弃了求逆矩阵的运算,使其效率很高;同样是一种通用性的解码算法,适用于任意的纠删码,最适合用于阵列码。矩阵译码算法存在优点,同时也有不足,其不足之处在于当故障类型包含冗余节点错误时,不能随原始数据节点同时恢复,需要在数据节点恢复完成后利用编码将其恢复,由此会降低故障恢复的效率。本文将对矩阵译码算法的优势进行描述,然后对其不足进行改进研究,最后基于改进研究算法做出具体的实验分析。
1 矩阵译码算法
矩阵译码算法是一种通用的经典纠删码解码算法。其最大的特点在于:(1) 通用于任意纠删码;(2) 可以恢复随机数据节点扇区的丢失。因为阵列码特殊的矩阵结构,矩阵译码算法可以更好地应用在阵列码中。对于普通的纠删码解码,矩阵译码同时也消除了矩阵求逆的运算过程,另外其效率也较高。
1.1 基本概念及定义
为了更好地描述算法,更加清晰明白地了解算法,介绍本文中涉及的基本概念和原理。对于纠删码的基本概念本文将不再赘述,可参考文献[4-5]。
以下给出一些矩阵译码算法所用到的线性代数定义及原理。
定义1左伪逆矩阵:矩阵A右乘矩阵B得到单位阵I,则称B为A的右伪逆矩阵。当矩阵A行满秩且行数小于列数时,右伪逆矩阵一定存在。
定义2零空间:零空间是指与矩阵的每个行向量正交的所有向量的集合。零空间基则是指零空间中一个线性独立向量的最大集合。
假定G为大小为R×C的矩阵,为编码理论中的生成矩阵。H为编码理论中的伪逆矩阵且R≤C,当B为G的零空间基,U为G的右伪逆矩阵,X在大小C×(R-C)的二进制矩阵上变化时,其中Ok为半单位阵:
G·(U+(B·X))=Ok
(1)
式中:U+(B·X)在所有部分伪逆上运行,X是在U的每一列增加一个零空间向量。
在编码理论中存在两个重要等式,分别为D×G=T和T×H=0。其中D为编码前元素向量,T为编码后元素向量。由此可推出:
D×G×H==0
(2)
由式(2)即可看出H是G的零空间基,因此可以利用校验矩阵来求生成矩阵的伪逆矩阵。
原理1由矩阵译码算法得来的伪逆矩阵U中,任意理论可恢复的数据元素对应U中的一个非零列,列中每个非零位置对应哪些数据元素与冗余元素,它们的异或和即为该理论可恢复数据元素。一个直接可读的数据元素对应U中一个单位列(即只有一个1的列)。一个数据丢失事件(理论不可恢复数据)对应U中一个全零列。
证明令T代表编码后包含所有元素的向量,T′代表丢失后的编码向量,即丢失对应位置为零,很明显。
D·G′=T′
(3)
丢失元素在G′中对应全零列。因此有:
T′·U=D·G′·U=D·Ok=D′
(4)
式中:D′的零元素位置对应Ok对角线上为零的位置,同时Ok对应伪逆矩阵U中的全零列。Ok中对角线上的非零位置对应D′中的非零元素,而Ok中对角线上的非零位置同时对应伪逆矩阵U中的非零列,由此伪逆矩阵U的每一行就对应D′中的每一个元素。同时,因为T′·U=D′,所以伪逆矩阵U中的每一列,每一个位置对应T中的一个元素,由此每列对应一个数据元素,且每一非零位对应一个已知可得的元素。
1.2 矩阵译码算法核心
矩阵译码算法的核心为伪逆矩阵U的构造,因此接下来描述伪逆矩阵构造的过程。首先定义一个丢失元素列表L,记录丢失元素在D中的位置,H为校验矩阵。
步骤一:构造一个方阵W,W=(U|H),初始的伪逆矩阵U由一个单位阵和(R-C)行全0行构成。
步骤二:对于丢失元素列表L,另r表示丢失元素对应W中行向量,进行如下操作:
(1) 查找H中r行有1的列b,如果不存在,将U中b列对应有1的行置零,然后继续下一个冗余元素。
(2)W中r行有1的每个列c,如果c≠b,那么将列b加到列c上。
(3) 将H中列b置零。
步骤三:利用所得U将丢失数据元素恢复出来。
1.3 矩阵译码算法分析
矩阵译码算法作为一种纠删码译码算法,可以用于任意纠删码,更适用于二元域的阵列码。当其应用于阵列码时,该算法有两大优势:(1) 是一种通用性的解码算法,它可以适用于任意阵列码解码;(2) 可以恢复任意数据失效扇区。
矩阵译码算法可以用于所有阵列码,例如:STAR码[6]、EVENODD码[7]、RDP码[8]等。寻常的阵列码译码算法是利用循环迭代的方式进行解码,当一个节点中任意扇区失效时,都被认为是该节点失效,从而对整个节点进行恢复。但是随着数据量的不断增大,硬件不断增多,某个节点中扇区丢失的现象越来越多。当重建整个节点时,也会重建那些不必要重建的扇区从而造成重复,增加不必要的计算量,因此针对随机元素或扇区丢失的恢复也成为纠删码解码的一个重要问题。矩阵译码算法就可以实现这一目标,可以恢复理论可恢复的任意扇区失效。可以达到这一目标的译码算法还有一个比较有代表性的,是文献[3]中提出的归并译码算法。归并译码算法与矩阵译码算法的最大区别在于矩阵译码算法无需进行矩阵的求逆运算,计算的时间复杂度低,归并译码算法仍然涉及矩阵求逆运算,出现单个错误时,译码时间可以接受,但是当有两个及以上的错误时,译码的时间成本仍然很高。因此相比较来讲矩阵译码算法在时间复杂度上要更优一点。
矩阵译码算法也存在缺点,就是当错误元素中包含有冗余元素时,不能直接求出冗余元素,而需要在求出数据元素后利用编码计算出冗余元素。当出现冗余元素错误时,这个缺点也会在一定程度上影响计算的时间复杂度,因此如果可以在求解数据元素的同时将冗余元素求出,必将在一定程度上提高计算时间复杂度。
2 矩阵译码算法改进研究
上一节中对于矩阵译码算法进行了描述以及原理证明,又分别给出了算法的优缺点。本节中,针对矩阵译码算法的不足之处,提出本文的改进研究方案。该改进算法可以恢复任意理论可解的情况,减少了对于冗余元素的计算量,降低了计算时间复杂度。本节中,首先对改进算法步骤进行描述,并对其中冗余元素的求取进行正确性证明,最后根据情况举出具体的实例。
2.1 改进算法描述
为了与平时编码理论习惯相一致,在改进算法中,生成矩阵G采用纵向矩阵,校验矩阵H采用横向矩阵方式表示,因此伪逆矩阵变为右伪逆矩阵。将数据丢失元素列表记为L。以下描述本算法步骤:
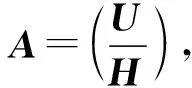
步骤二:判断构成A的校验矩阵H的右半部分是否为单位阵,若不是,通过校验矩阵行与行间初等行变换即异或将其变为单位阵后进行运算,如下例:
RDP(4,3)的校验矩阵如下:

由上式可看出RDP校验矩阵的右半部分并不是校验矩阵,因为进行初等行变换,将第一行与第二行进行异或并放置于第二行,则可得到单位阵,可得结果如下式:

步骤三:对工作空间A进行行变换也相当于求逆的过程,具体求逆过程在下面会进行描述;
步骤四:得出变换后的工作空间A即可恢复出丢失元素,A中一行代表一个数据元素,每行中非零位置代表已知可得的数据元素。
其中将工作空间A进行初等行变换求逆的具体步骤如下:
步骤一:对丢失元素列表L中的每个数据元素s,循环遍历L中s,首先判断数据元素s的类型,是属于原始数据的还是冗余数据,若为数据元素继续进行操作进入步骤二,若为冗余元素则跳过进行下一个元素的判断;
步骤二:在校验矩阵H中找s列为1的行h。如果不存在这样的行h,那么将U中s列有1的行置零(说明此元素s理论上不可恢复);
步骤三:若找到列表h后,如果L中没有包含冗余元素,即没有冗余元素丢失,那么就从找到的列表h中选择最稀疏的一行(即汉明重量最小的一行)f,如果L中包含冗余元素,则将L中丢失的冗余元素对应行号从找到的列表h中去除后再在列表h中选择最稀疏的一行f(为了保留丢失的冗余元素对应行的值,最后可以同时求出);
步骤四:对于工作空间A中第s列为1的行E列表,如果E中每一个元素e≠f,那么将f与e相加(异或)并替换掉e;
步骤五:将构成工作空间的行H中第f行置零;
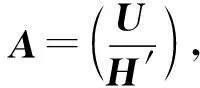
至此,对于算法改进的研究步骤基本描述完毕。最后得到的工作空间既可以恢复数据元素,又可以恢复校验元素,也就是可以恢复所有理论上可恢复的情况。
2.2 正确性证明
本文提出的改进研究算法中保留了对于数据元素恢复的伪逆矩阵,同时生成了一个新的用于恢复冗余元素的冗余矩阵,用H′表示。下面将对冗余矩阵进行正确性证明。
校验矩阵是用来检验码字是否正确的一种矩阵,它的每一列代表一个元素位置,每一行代表一个冗余元素,同时也是一个方程式(每一行中所有非0位置进行异或后结果为0)。上面所提到的冗余矩阵便是由校验矩阵变换得来。
原理2由本文的改进算法得出的冗余矩阵,它的非零行代表一个理论上可恢复的冗余元素,这一行中每个非零位置对应的元素异或和即为该行对应的冗余元素的值。每一个全零行代表一个已知可读的冗余元素。
证明校验矩阵的每一行异或结果均为零,因此将校验矩阵进行初等行变换后并不会改变此性质。而根据异或逻辑运算,如果两个值不相同,异或结果为1;如果两个值相同,则异或结果为0。当进行求冗余矩阵的步骤时,将丢失冗余元素对应列置零后,冗余矩阵中每一个非零行上其余元素的异或和应等于丢失元素的值,由此即可证明出原理即冗余矩阵的正确性。下面将给出一个例子说明。
以STAR(6,3)的校验矩阵为例,其校验矩阵如下:

校验矩阵的每一行都代表一个冗余元素,STAR(6,3)的冗余元素为(P0,P1|Q0,0,Q1,0|Q0,1,Q1,1)。假设丢失的冗余元素为P1,那么在算法的最后将P1对应的列也就是第7列置零,则第2行剩余非零位置所应对的元素异或和即为P1的值,公式如下:
d1,0+d1,1+d1,2=P1
2.3 具体实例
上一小节中证明了该算法的正确性,本小节将采用典型的实例来进一步分析和说明本算法。
例1:以EVENODD(5,3)[7]为例,将磁盘数据展开来排成一个行向量,可以写为T=(d0,0,d1,0|d0,1,d1,1|d0,2,d1,2|P0,P1|Q0,Q1),此时假设丢失元素为d0,0、d0,1、P1、Q0,则丢失元素列表为L=(0,2,7,8)。
首先构造一个10×10的工作单元A:
(5)
判断构成工作单元的校验矩阵右半部分是否为单位阵,由式(5)可以看出符合条件,那么继续进行操作,循环遍历丢失元素列表s。当s=0时,0属于数据元素,所以在H中找第0列为1的行h,可以找到h=6,8。因为8也是丢失元素,将其排除,选择h=6。将第6行分别加到第0行,第8行后,第6行置零,结果所得工作单元A为:

(6)
继续当s=2时,2属于数据元素,所以在H中找第2列为1的行h,可以找到h=8,9。因为8为丢失元素,将其排除,选择h=9。将第9行分别加到第0行,第2行和第8行后,第9行置零,结果所得工作单元A为:

(7)
当s=7时,7属于冗余元素,所以跳过;当s=8时,8属于冗余元素,所以跳过。丢失元素列表循环完毕,将7、8列置零。最终所得工作空间A为:

(8)
工作单元A中,上半部分为求解数据元素的伪逆矩阵,下半部分为求解冗余元素的冗余矩阵。因此可恢复出丢失的数据元素与冗余元素d0,0、d0,1、P1、Q0。具体公式如下:
(9)
例1:以RDP(4,3)为例,将磁盘数据展开来排成一个行向量,可以写为T=(d0,0,d1,0|d0,1,d1,1|P0,P1|Q0,Q1),此时假设丢失元素为d0,0、d0,1、P0、P1,则丢失元素列表为L=(0,2,4,5)。
首先构造一个8×8的工作单元:
(10)
判断构成工作单元的校验矩阵右半部分是否为单位阵,由式(10)可看出,不符合条件,因此将第5行加到第6行,使其变为单位阵:

(11)
开始循环遍历丢失元素列表。当s=0时,寻找H中第0列为1的行h,可得h=4,6。因为4同样为丢失元素,抛弃掉,选择h=6。将第6行分别加到第0行和第4行后,第6行置零。当s=2时,在H中找第2列中为1的行,h=(4,7),但是因为4在L中,所以排除4,选择h=7,选定后将第7行加到0、4行,然后第7行置零。当s=4时,4为冗余元素,跳过;当s=5时,5为冗余元素,跳过。丢失列表元素循环完毕,将4、5列置零,最后可得工作单元式(12):

(12)
工作单元A中,上半部分为求解数据元素的伪逆矩阵,下半部分为求解冗余元素的冗余矩阵。因此可恢复出丢失的数据元素与冗余元素d0,0、d0,1、P0、P1。具体公式如下:
(13)
3 实验分析
就纠删码的性能而言,关键还在于它的编解码,本文主要研究的是纠删码的解码算法。
阵列码是一种仅通过异或运算构造的码制,它本身的解码算法是利用循环迭代来进行解码。当一个条块中的一个元素丢失即认为是整个条块乃至整个磁盘的丢失,恢复时会重建整个磁盘,且每种阵列码的原始解码均不相同。文献[4]提出一种恢复随机数据元素的算法——矩阵译码,利用生成矩阵的伪逆理论重建数据元素,适用于任意的纠删码,但是却不能同时恢复冗余元素。而Tang在文献[3]中提出一种归并译码算法,通过对校验矩阵分块并求逆来重建磁盘数据元素,可以同时恢复数据元素和冗余元素,但是这种算法需要计算逆矩阵,增加了计算复杂度,效率不高。本文提出的改进解码算法是基于矩阵译码算法的改进,可以恢复理论上可以恢复的任一情况,包括同时恢复数据元素与冗余元素。因此本节将使用几种不同的纠删码译码方法作为容错方案构建存储仿真系统,在存储仿真系统中对失效数据进行重构。构建存储仿真系统所使用的语言平台为Python。构建存储仿真系统所用到的计算机主要配置为:CPU Inter Core i5-6200U,内存8 GB,磁盘容量250 GB。
对于EVENODD码,一般常用的解码算法为循环迭代的解码算法,因此我们在仿真存储系统中首先对EVENODD进行编码,素数选取5。模拟数据丢失事件,然后利用几种不同的译码算法对其进行比较分析。设置文件存储的块大小为10 240 B,对于不同文件的大小,分别利用四种解码算法进行对比实验分析。针对不同尺寸文件的单节点失效和双节点失效,其中双节点失效模拟节点0和节点5失效。
实验1在以上所描述的实验条件下,首先对于归并译码和改进方法进行对比,时间效率对比图如图1和图2所示。图1为单节点失效的时间效率对比图,图2为双节点时间效率对比图。在单节点失效时,归并译码与改进算法相差并不是很多,这也说明了归并译码方法在单节点失效时效率不低。但是从图2可以很明显看出文献[3]的归并译码效率远不及改进方法的时间效率。同样的前提下,当发生两个节点失效时,归并译码几乎是改进方法的1.5倍。之后随着文件尺寸的增大,归并译码有可能呈现指数级的增长,而本改进译码方法随着文件尺寸的增大,时间消耗呈直线性增长。
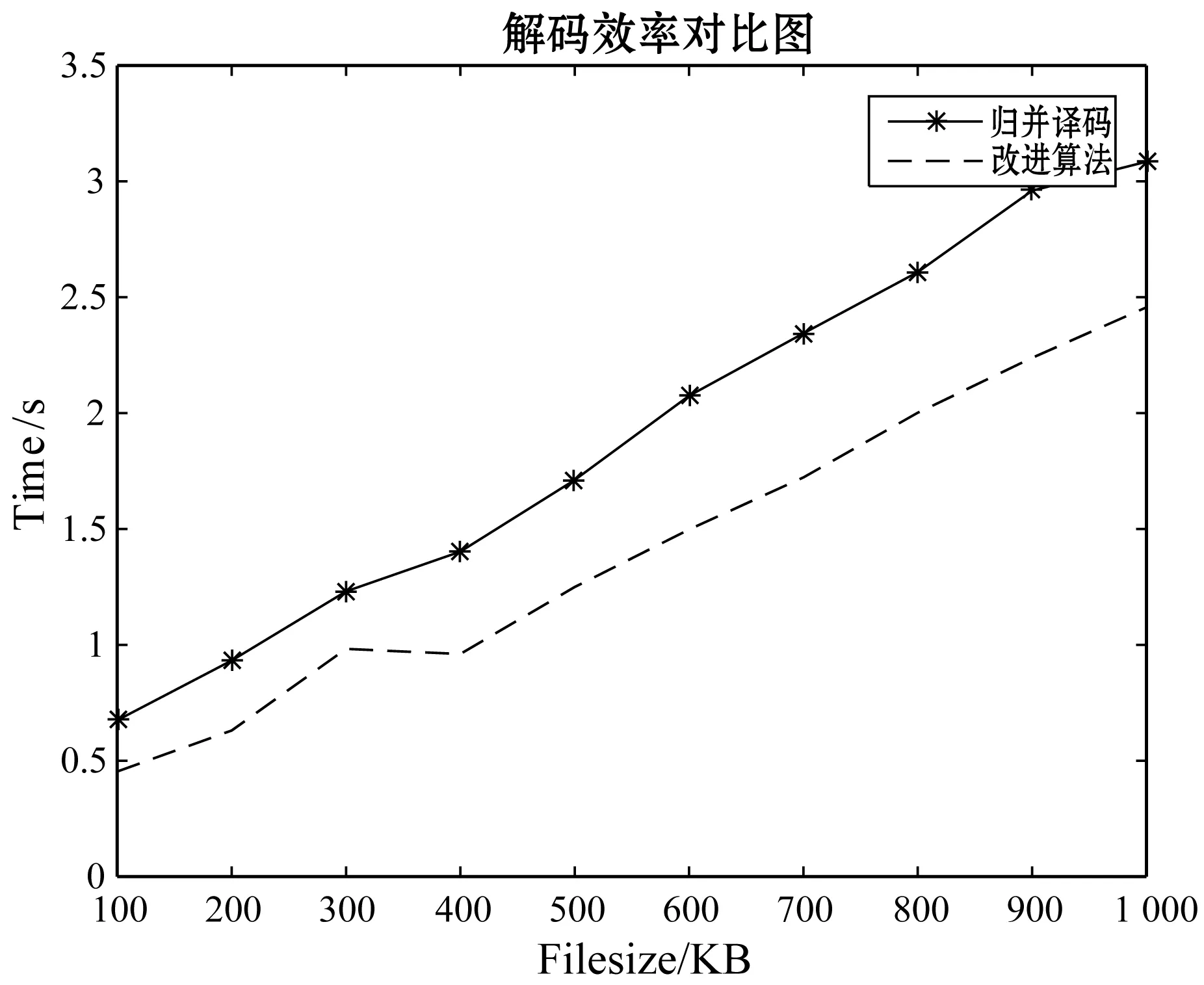
图1 单节点失效译码时间对比图
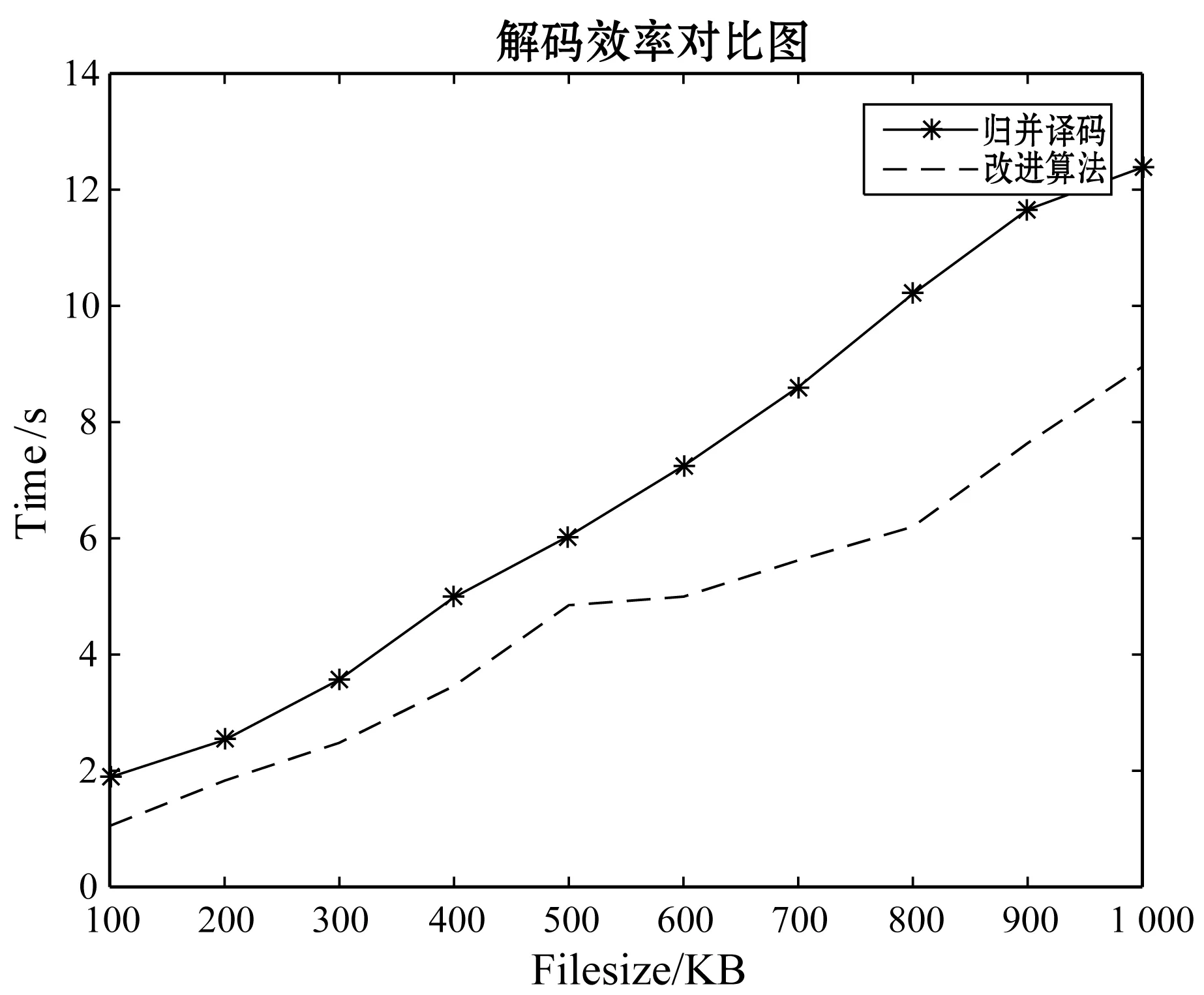
图2 双节点失效译码时间对比图
实验2在本节刚开始所描述的实验条件下,对矩阵译码方法和本改进译码方法进行时间效率的对比,对比时间效果图如图3和图4,图3为单节点失效时的时间对比图,图4为双节点失效的时间对比图。从图3可以看出,单节点时,因为只恢复一个数据节点,因此并不能体现出改进的优点。从图4双节点丢失的对比图可以看出两者的效率相差虽不多,但还是有一定的差别,本改进算法的时间消耗始终比矩阵译码方法的效率高,也说明了同时恢复数据元素和冗余元素比先恢复数据元素再根据编码恢复冗余元素效率要高。
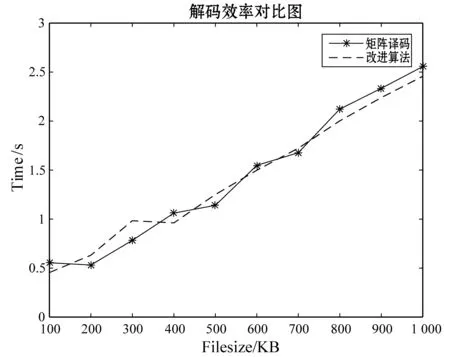
图3 单节点失效译码时间对比图
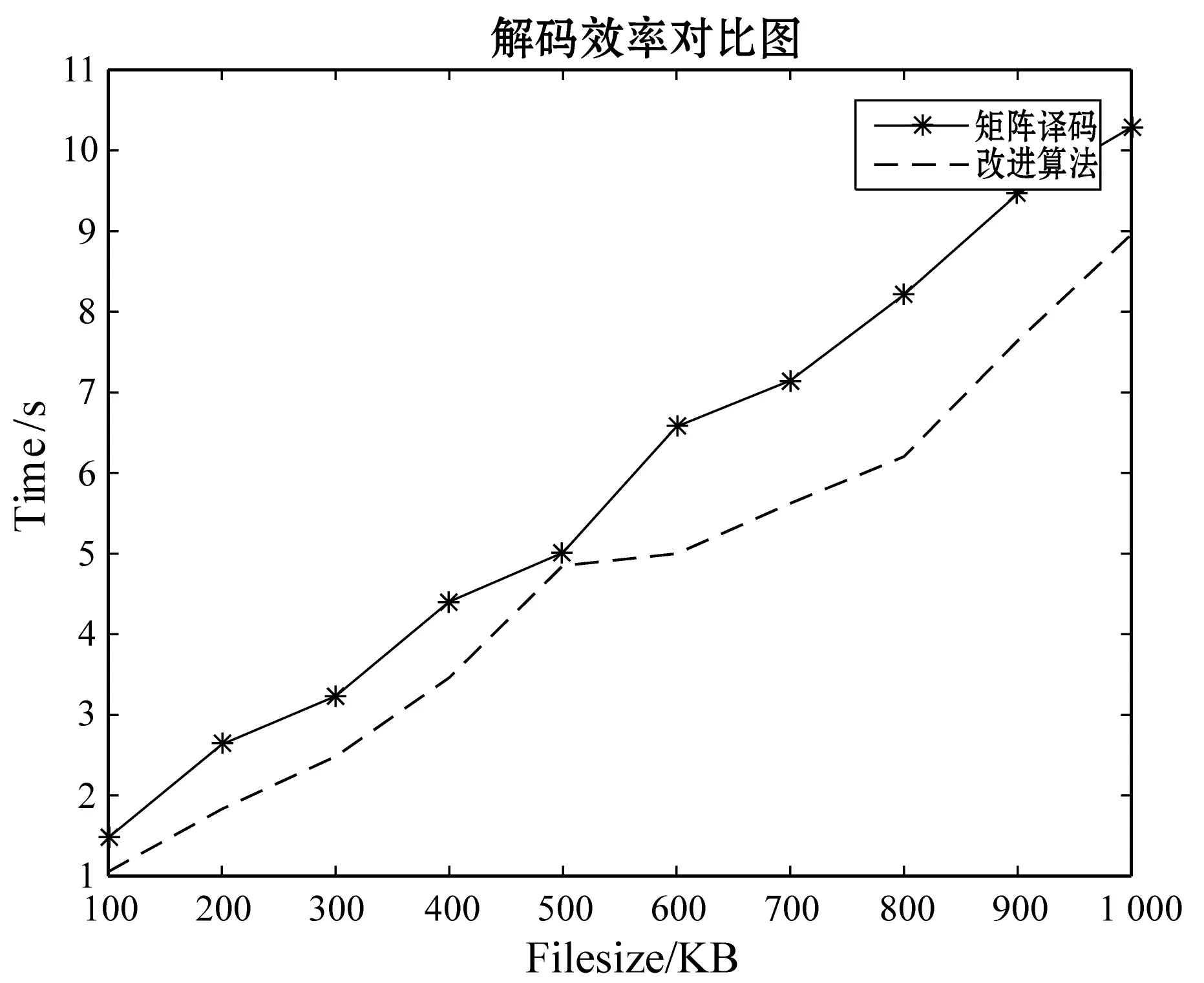
图4 双节点失效译码时间对比图
实验3仍然利用与前两个实验相同的实验条件,对循环迭代法和改进方法进行时间效率对比,对比图如图5和图6,图5为单节点失效的时间对比图,图6为双节点失效的对比图。两张图都可以很明显地看出循环迭代法的效率要比改进方法的效率高,但是相差不多。从另一个方法看,改进方法可以是对于不同节点中随机扇区进行理论可行的恢复,而循环迭代法只能针对节点进行恢复,当一个节点中某一个扇区丢失时,必须要恢复整个节点,增加了很多不必要的计算量。目前在存储系统中,发生扇区失误的概率很高,因此,两者平衡下,改进方法要相对好一些。
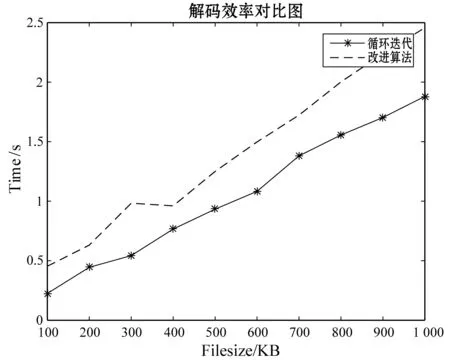
图5 单节点失效译码时间对比图
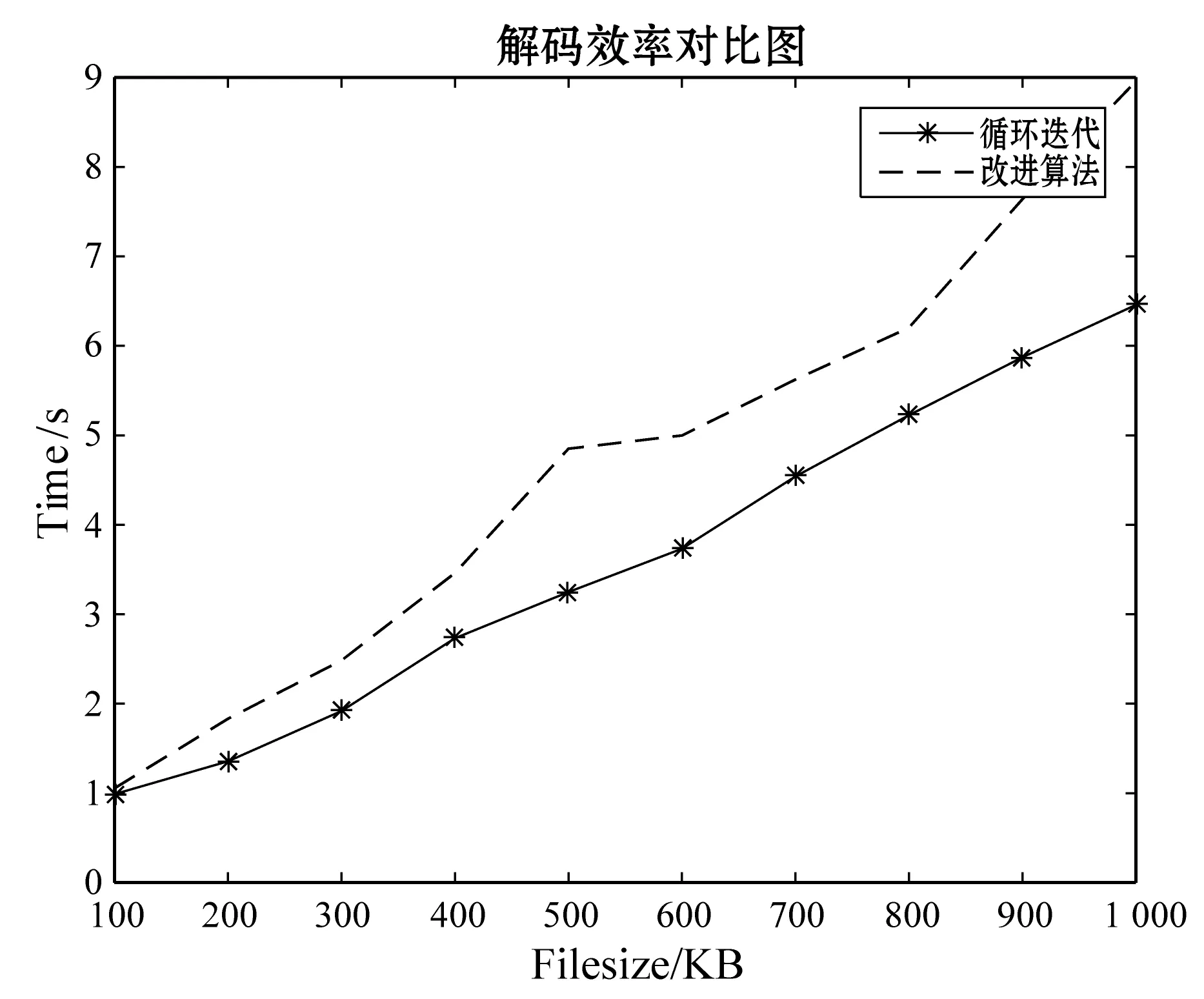
图6 双节点失效译码时间对比图
从以上三个实验可以很明显看出,本文提出的改进算法的计算效率比较优异且在各方面的性能比较均衡。
实验4为了证明本改进算法的通用性,利用与上面三个实验相同的实验条件,将改进方法应用于RDP码中,模拟双节点丢失的事件,并与其余三种译码方法进行对比。时间效果对比图如图7所示,也从另一方面验证了上述三个实验结果的正确性。
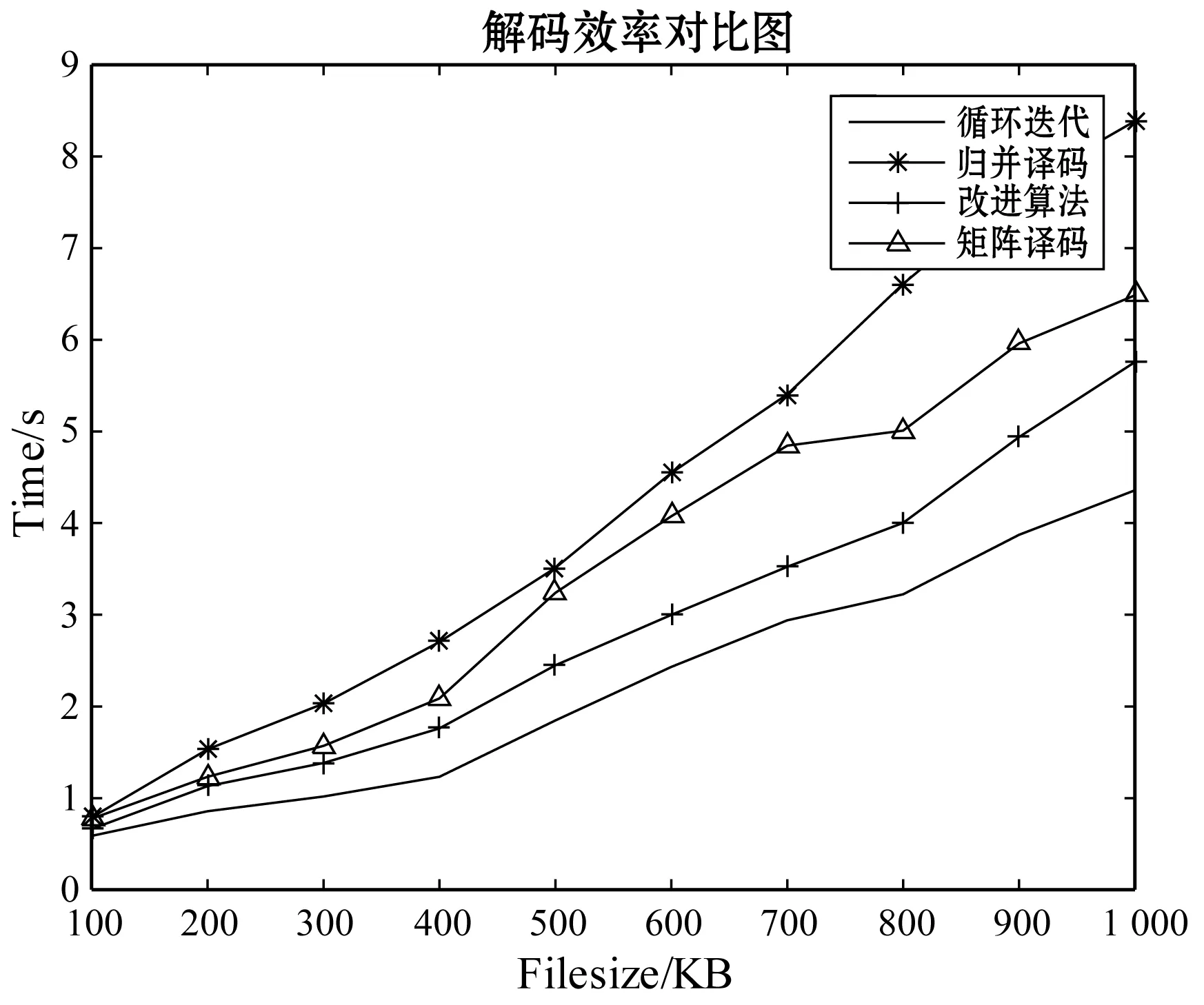
图7 RDP双节点失效译码时间对比图
4 结 语
针对纠删码解码算法,本文首先介绍了一种通用性的解码算法——矩阵译码,在保留了原算法的优势下,对其不足之处进行改进研究,最后在仿真存储系统中进行实验数据分析,可以看出确实在性能中有所改变,可以广泛应用于随机扇区丢失的场景。本文提出的这种改进算法目前是运行在二进制矩阵上的针对阵列码的运算,以后改进研究可以将此算法推广至非二进制上进行解码运算。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
南北桥(2022年2期)2022-05-31 04:28:07
现代计算机(2021年36期)2021-03-14 00:50:38
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
电脑知识与技术·经验技巧(2017年9期)2018-02-24 19:55:20
新闻传播(2016年3期)2016-07-12 12:55:27
西南交通大学学报(2016年4期)2016-06-15 20:29:36
计算机技术与发展(2016年10期)2016-02-27 00:44:08
