
基于协同过滤算法的电子商务推荐系统①
2018-08-03 05:22,
佳木斯大学学报(自然科学版) 2018年4期
,
(三明学院 信息工程学院,福建 三明 365004)
0 引 言
由于互联网上的信息数据以爆炸性的速度快速增长,使得用户无法区分和获取有效信息,导致信息利用率低下并且信息超载。因此,许多学者已将注意力转向研究根据网站收集的用户信息给用户自动推荐商品。推荐系统可以通过对目标用户精准投放兴趣信息来减少无用信息量,提高用户点击转换率。目前主流的推荐算法都是基于协同过滤算法,该算法在预测用户的兴趣度时会不但单只利用该用户的信息,而是经由全部用户对物品的行动来计算用户之间、物品之间的类似度,经过聚合相似度和用户的行动数据来决议推荐内容。传统的协同过滤算法基于邻近用户域来预测用户个性。基本原理是使用所有用户的历史数据来计算各用户的邻居,并将类似的最近邻居分数数据给目标用户,这是为了产生目标用户的推荐信息[2]。随用户规模和项目规模的爆炸式增长,如何下降算法的复杂度、同时不影响算法的推荐精度是协同过滤算法面临的一个挑战。为了因对这些挑战,本文提出了一种基于物品协同过滤算法的电子商务推荐系统,通过分析用户行为日志挖掘用户物品间的相关度,据此预测用户偏好,形成推荐清单。并针对电子商务的特性,考虑用户行为时间上下文关系对用户兴趣度影响,对算法细节上进行了调整,使得推荐结果更加精准。
1 基于物品协同过滤算法
基于物品的协同过滤算法会向用户们提供符合用户偏好的物品。算法会分析网站收集的所有用户历史行为数据,并从用户对物品行为中提炼出物品间的类似度。
1.1 传统相似度度量方法
基于物品协同过滤算法首先需要计算物品之间的相似度,计算相似性有几种方法:
1)基于余弦(Cosine-based)的相似度计算,
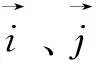
(1)
2)基于皮尔森相关性(PearsonCorrelation-based)的相似度计算
两个连续变量(X,Y)的pearson相关性系数(Px,y)等于它们之间的协方差cov(X,Y)除以它们各自标准偏差(σX,σY)的乘积[5]。系数的取值域为-1至1,它反应变量间线性相关度。相似度计量公式为:
(2)
1.2 采用的物品相似度度量方法
传统基于物品协同过滤算法描述物品相似度的基本思想为“如果大部分购买物品A的人同时也购买了物品B,则说明物品A和物品B的相似度非常高”[6]。用公式表达为:
(3)
该公式计算相似度时,当物品j被大部分用户有过行为时,两个用户集的交集可能会接近目标物品的用户集,这导致物品j与任何其他物品的相似度都非常高,这对其他非热门商品是非常不利的。所以我们对公式(3)作出了改进,采用
(4)
分母惩罚项目j的权重,避免了热门项目的推荐,从而使推荐系统更专注于挖掘长尾信息[ 7 ]。
这个公式可以用余弦相似度计算物品之间的相似度,但还是过于简单。针对电子商务的特性对公式作出了以下改进:
(1)用户活跃度对物品相似度的影响
从公式(3)得知,物品间的相似度来源于这两个物品具有共同的行为用户集。然而,这些来自不同用户的贡献却并不一定是完全相同的。如果一个用户购买了商城里大部分的书籍,说明这个用户可能是开书店的,并不能说明这些书之间有很强的相似度。因此引入了论文[8]中提出的IUF参数,通过该参数惩罚过于活跃的用户,得到了新的度量公式:
(5)
其中u为同时购买物品i物品j的用户,N(u)是用户u的活跃度,通过乘以用户活跃度对数的倒数来惩罚高活跃度用户对物品相似度的贡献[8]。
(2)时间上下文对物品相似度的影响
用户偏好是随时间变化的,时间因素对用户偏好的影响应当被添加到计算公式中。在用户行为日志中挖掘出行为的时间信息,并考虑了其对物品相似度计算的影响,用下面的公式改进了相似度计算:
(6)
公式加入了时间因素项f(|tui-tuj|),其中|tui-tuj|越大,f(|tui-tuj|)值越小。这样惩罚了时间过于久远的用户行为,提高了用户近期行为在用户偏好评估中的权重。本文采 用的衰减函数如下:
(7)
其中a是时间衰减参数,这是提前设定好的超参数。当a的值比较大时,用户的偏好和时间因素相关性较强。在调优后使用的a的取值为0.7。
1.3 用户兴趣度计算
用户u对目标物品j的兴趣度通过以下公式计算:
(8)
其中N(u)代表用户有过行为的所有物品,S(i,k)代表和物品i最临近的K个物品,wji代表物品j和物品i的相似度,rui代表用户u对物品i的兴趣度[6]。
在度量兴趣度时,添加了时间因素项,在计算用户的偏好时,给予用户比最近行为的类似物品更高的权重。用户兴趣度量公式为:
(9)
其中,t0是当前时间。b是时间衰减参数。该公式表明,tuj和t0相隔越短,和物品j相似的物品权重就越高。
2 电子商务推荐算法
在传统的基于物品协同过滤算法的基础上针对电子商务进行优化,通过在网站保存的用户行为日志中挖掘相关数据并进行数据清洗和分析,提取有效数据计算出物品之间的类似度,并结合用户历史行为生成离线推荐清单,实现对登陆用户的实时推荐。完整的算法流程如图1所示:
2.1 数据处理
采用嵌套字典结构储存用户-物品评分表,从用户行为日志中提取用户对物品的所有行为类型和时间信息并通过加权相加的方式作为用户对物品的评分和时间,并通过键-值方式储存在嵌套字典中。
2.2 物品倒排表
如果计算所有物品间的相似度,这样在计算中会存在大量的冗余计算,加大算法的时间复杂度。事实上,部分物品的行为用户集间不存在交集。即很多时候N(i)∩N(j)=0。所以可以首先计算出N(i)∩N(j)不等于零的物品,建立物品到用户的倒排表[9],减少计算的时间复杂度。
2.3 共现矩阵
共现矩阵是物品和物品之间的关系矩阵,用来计算物品相关度。
图1简单的展示了数据的处理过程。如图2所示将用户-物品评分表转化成物品倒排表,并最终生成物品之间的共现矩阵。得到共现矩阵后,通过上部分所讲的物品相似度计算方法计算出各物品之间的相似度,运用上部分所讲的用户兴趣度计算方法,可以计算出最终的推荐列表并将其储存为本地文件。当用户登陆时,可以对用户进行实时推荐。
3 实验结果及其分析
3.1 数据集
采用阿里天池提供的数据集,包括用户在阿里巴巴移动电商平台的真实用户-商品行为数据以及百万级的商品信息。其数据结构如下表1所示

表1 用户消费数据表
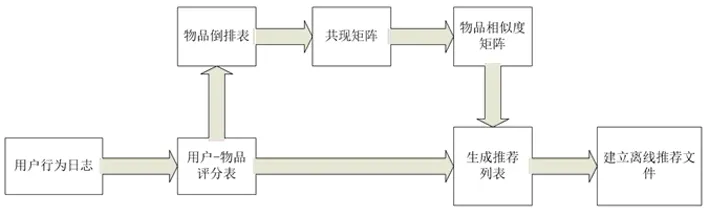
图1 电子商务算法推荐流程图
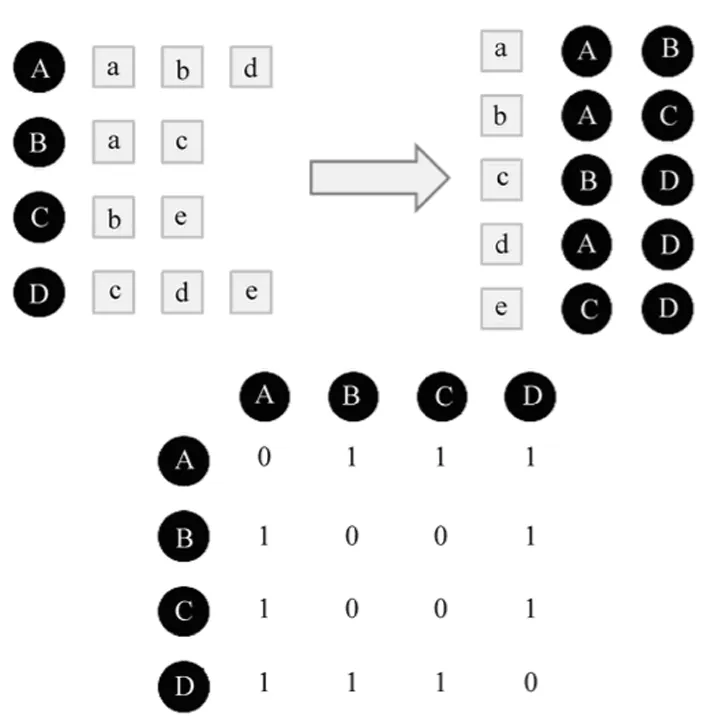
图2 用户物品关系矩阵
从原始数据中提取了用户行为数据和物品信息重叠的部分,先根据用户将行为数据汇总,以9比1的比例划分用户设定训练集与测试集。 根据行动时间进一步划分为训练集和验证集,其中将2017年11月18日至12月18日的行为数据作为训练集,2017年12月18日后的行为数据用作验证集。
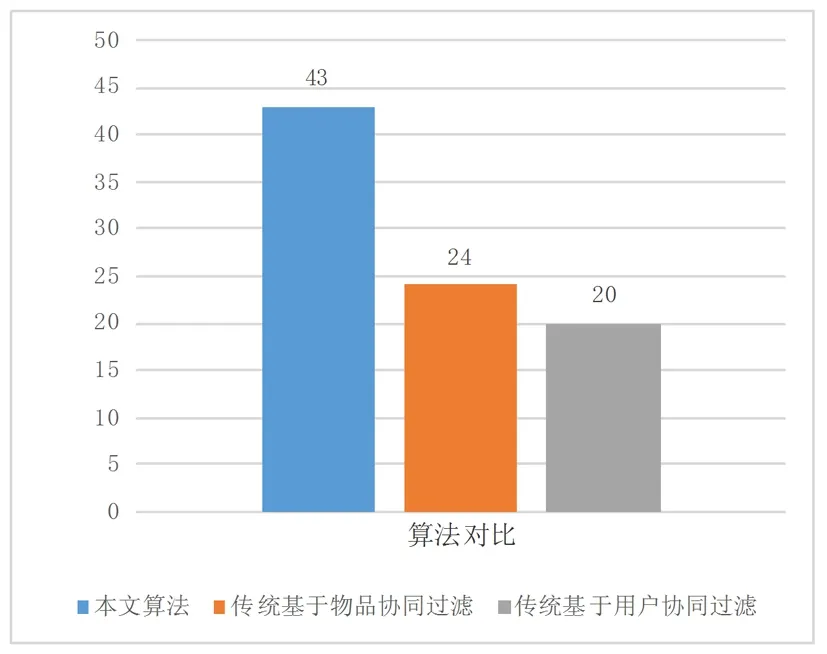
图3 算法比对结果
3.2 度量标准
采用平均绝对偏差MAE的倒数作为度量标准。平均绝对偏差MAE一种常用的精度评估方法,它有解释性强的优点,其度量公式为:
(9)
其中P代表算法预测的用户对物品兴趣度,q代表用户对物品的真实兴趣度,N为物品的数量。
3.3 实验结果
图3是算法与传统算法的性能比较,通过比较不同算法在验证集上的表现来验证算法的性能。文中电子商务系统算法的改进确实提高了推荐的有效性。
3.4 实验结果分析
提出的基于物品协同过滤算法,在传统算法基础上改进了具有电子商务特征的相似度计算和兴趣度计算。 在数据挖掘中,提取用户关于商品行为的时间信息,并进一步利用用户行为信息。实验表明这种改进的算法相对传统的算法在推荐精度上确实有所提升。实验结果说明了充分利用用户信息对于提高预测效果确实有帮助。
4 结 语
设计了一种基于物品协同过滤算法的电子商务推荐算法,通过网站记录的用户行为日志挖掘用户-物品信息,计算物品相似度,通过用户对物品的兴趣度给用户推荐商品。通过对时间上下文的考虑,进一步提高了推荐的效果,通过离线算法保存用户推荐列表,做到了对用户的实时推荐。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
小学生学习指导(低年级)(2022年5期)2022-05-31
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
疯狂英语·初中天地(2021年11期)2021-02-16
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
少年漫画(艺术创想)(2019年2期)2019-06-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
