
一种基于流计算的铁路车流推算架构模型研究
2018-08-03 06:48金福才谢玉霞
铁道运输与经济 2018年7期
王 斌,金福才,谢玉霞
(1.西南交通大学 交通运输与物流学院,四川 成都 610031;2.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
0 引言
车流推算是依据当前铁路车辆状态预测其未来变化的状态,既是编制调度工作计划和车流调整计划的依据,也是建立铁路电子商务平台的重要信息支撑[1]。我国铁路存在资源分布不均衡、重去空回较多、运输距离长等现象,都会造成铁路车流不均衡,使得车流推算与调整工作更加复杂[2]。
为了更准确地进行车流推算,很多学者对此进行了研究。Liu[3]对车流编制过程中的干扰因素进行研究,主要包括列车到达时间、分类时间、编组时间等,构建了多目标随机机会约束模糊模型,采用人工智能中的启发式方法求解。Jing[4]对车流推算模型进行设计,使用改进蚁群算法进行求解。Hu[5]在车流调度实际需求的基础之上,结合遗传算法和神经网络算法的混合智能算法,建立一个随机机会约束模型解决车流推算问题。金福才等[6]对重车的车流推算方法进行研究,确定车流推算中关键要素的计算方法,在计算货车在车站停留时间时,针对不同类型车站设计了不同的计算方法。陈东等[7]研究了铁路技术站车流接续的列车运行调整问题,利用分步计算、指标评估的求解思路,建立赶流调整综合模型,该模型对于局部范围内的线流匹配优化计算做了尝试。
传统的车流推算研究重点是对车站级推算,主要是依据编组计划和车流情况推算列车发车计划,对于大规模的列车运行推算并没有涉及。随着铁路信息化建设的加快,目前铁路网车辆实时状态信息可以被探测并收集汇总到中国铁路总公司的数据中心,使得实现更加宏观的车流推算成为可能。由于铁路上运行的车辆数量大,车辆状态变化快,因而车流推算计算必须及时处理,以便更好地处理数据量大、复杂的车流推算。为保证计算的时效性,最好的方法是在数据接收过程中就进行计算处理,这种计算方式就是流计算[8-9]的处理模式。
流计算是将传统的计算过程转化为以流动数据为基本处理对象的计算应用,基本思想是把具体应用分解成数据流和数据计算核心 2 级[10],数据流被视为处理的基本数据单位,各种计算可视为对整条数据流的操作。为此,提出一种基于流计算的车流推算框架模型,该框架模型用于处理来自底层的实时变化的车辆状态信息流,同时结合微应用架构,实现对车流的综合分析、车流预测、能力预警及车流调整。
1 车流推算应用分析
车流推算是以当前车辆状态推算其未来的走行状态。车辆当前状态包括在站和在途 2 种,在站车辆信息是独立的车辆信息,在途车辆信息则跟随着列车的信息。被采集到的车辆状态信息包括车辆装车、车辆卸车、列车出发、列车到达等信息,这些信息都从车站采集并向数据中心传送,这些信息汇聚成了路网车辆的当前状态信息。
根据车流推算业务处理过程的分析,按照模块低度耦合、高度内聚的要求,设计了数据采集、车流推算、能力预警和车流调整 4 个主要计算业务过程。
(1)数据采集应用过程。负责对车站上报的车辆状态信息进行采集和预处理,根据推算要求筛选出格式和内容都合格的推算数据。
(2)车流推算计算过程。执行具体的推算计算任务,包括走行过程推算、运行时间推算、作业时间推算等。车流推算应用支持推算结果存储持久化,通知暴露数据接口,为能力预警、车流调整提供数据服务。
(3)能力预警过程。包括分界口车流能力预警、卸车站车流能力预警、限制区段车流能力预警等。首先对困难车站或区段设定处理车流能力值,如果推算结果超过这个能力范围,就进行相应的能力预警。同时也设计暴露数据接口,为车流调整等应用提供数据服务。
(4)车流调整过程。包含分界口车流调整、卸车站车流调整及货运计划调整等。针对不同类型的超能力情况设计相应的自动车流调整过程,给出车流调整的相关建议,供调度员决策。
2 车流推算的流计算处理架构
2.1 架构设计
为解决车流推算过程的大量计算瓶颈问题,避免传统构架使计算割裂的弊端,设计了基于微服务的流计算处理架构。使用微服务的目的是对原应用进行有效的拆分,使得计算应用可以更方便地实现开发和部署。微服务可以在自己的程序中运行,不需要像传统服务那样成为一种独立的功能或者独立的资源,通过灵活组装微服务,能够满足大量数据计算的需要。
铁路网上的车辆状态处于实时变化之中,每个表征车辆状态更新的数据都需要快速进行计算以保证计算结果的有效性,同时需要为其他应用程序提供访问最新状态后计算的结果。这种业务需求就要求车流数据需要在短时间内传递给推算系统进行处理,推算完成后也要将处理结果快速向后传递,并最终提交到数据库进行实体化存储,减少其他应用在使用推算结果数据时所产生的延迟。根据上小节所述的车流推算应用模型,设计车流推算流计算架构如图1 所示。
整体的流计算过程需要处理 3 个来源的数据:①来自服务总线的计算任务,即被分配的工作任务;②通过数据总线,从数据库集群调取的参数数据;③来自车站的车辆报告数据,它是流数据的主要输入。
流计算过程中产生的中间数据结果有 2 种处理方法:①返回服务总线,继续实时计算。流计算集群响应服务总线计算任务,经过流计算后的结果返回到服务总线,支持车流推算应用的实时计算。②存入数据库,实现数据持久化。流计算集群对铁路局集团公司报表数据接受和处理,通过服务总线支持数据采集应用的数据需求;通过数据总线存入对应的数据库,进行数据的持久化。同时,通过服务总线和数据总线,计算应用能够与数据库群进行数据交互的操作,如实现历史数据查询、历史参数查询等操作。
2.2 系统实现
在流处理框架下,推算作业将被分为数据源单元和处理单元,车流推算应用部署如图2 所示。
车站上报的车辆报告数据全部放入中国铁路总公司一个专门的信息队列 (MQ)中,流计算采用并行计算工具 STORM 中的喷嘴控件 (Spout) 接收这些车流报告。Spout 控件担任了计算数据协调处理的角色,发现新报告后先简要解析报告,判断报告的类型,然后根据类型提交给相应的计算控件 (Bolt)去处理。喷嘴控件不参加具体计算,只是对数据进行分类后直接传递给负责计算的 Bolt 控件,因而其处理效率非常高。从实际应用效果分析,MQ 队列的深度通常维持在 1 个消息,即其处理能力远大于MQ 消息的接收效率。Bolt 控件担任了具体计算作业的角色,按照微服务的架构设计,此处将一个复杂的推算分解成多层 Bolt 来计算,每层 Bolt 的计算简单快捷。第一层 Bolt 针对不同类型的报告有不同的解析方式,有些也会经过多个 Bolt 进行处理。这层 Bolt 处理速度要很快,然后都汇聚到下一个路径计算调用的 Bolt,这个 Bolt 主要是负责用解析后的报告数据进行路径计算。路径计算调用完成之后,计算结果继续传递给后续的 Bolt 进行运行时间计算,计算完成后提交给数据库管理系统 Oracle 的远程存储服务,将推算结果数据存储到内存中,同时也将自己持久化到 Oracle 数据库中。
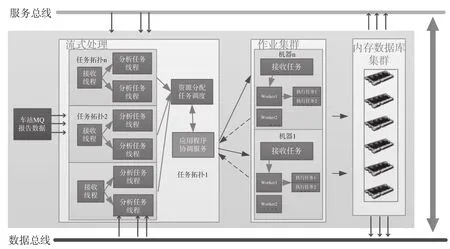
图1 车流推算流计算架构Fig.1 Calculation architecture of train fl ow estimation
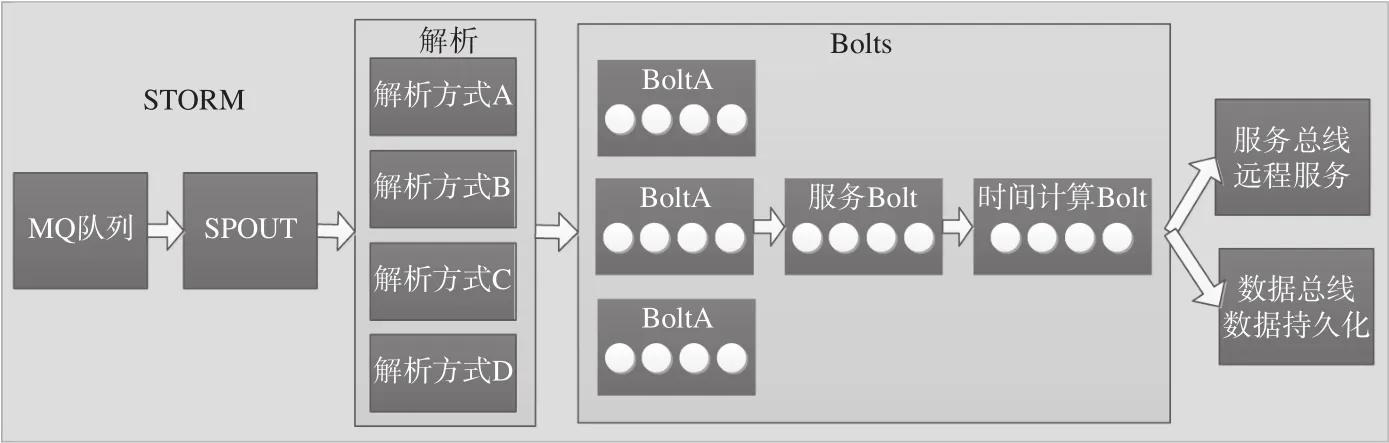
图2 车流推算应用部署Fig.2 Application deployment of train fl ow estimation
Bolt 计算不仅速度快,而且能够配置,可以根据计算量的大小设定 Bolt 的上限值。在计算时能够根据需要计算数据量的大小自动调整参加计算的Bolt 数量,以满足快速计算的需要。使用这种微应用的流计算架构方式使得数据在传送的过程中就被计算,计算结果在内存得到快速处理,外部应用直接在内存中读取相应的结果,这种架构极大提高了数据处理效率,也有效减小数据更新的延迟。
3 结束语
车流推算由于计算复杂,难以用计算机实现。通过将计算过程与流计算架构相结合,提出一种基于流计算的车流推算架构模型,这种架构使得数据计算和处理的效率大大提升,可以真正实现宏观级的车流推算。该计算模型将一个整体计算分成若干个小的计算单元,利用多个计算节点分别完成各自运算,计算能力得到大幅提升,使车流推算可以更好地为运输计划调整提供数据服务。
猜你喜欢
工会博览(2022年33期)2023-01-12
智慧少年·故事叮当(2021年4期)2021-05-06
中文信息(2020年10期)2020-11-30
扬子江(2019年3期)2019-05-24
软件(2018年7期)2018-08-13
领导决策信息(2017年17期)2017-06-21
浙江大学学报(工学版)(2016年9期)2016-06-05
数学教学通讯·初中版(2015年5期)2015-06-17
中国新技术新产品(2011年3期)2011-01-23
中华少年(2009年9期)2009-09-14
