
BN-cluster:基于批归一化的集成算法实例分析
2018-07-30 02:43张德园李照奎石祥滨
沈阳航空航天大学学报 2018年3期
张德园,杨 柳,李照奎,石祥滨
(沈阳航空航天大学 计算机学院,沈阳 110136)
深度学习[1-2]正在被越来越多地应用到各个领域的新应用和新问题上,并取得了令人瞩目的性能。深度神经网络以其优异的性能表现,在机器视觉领域得到广泛关注并掀起一阵热潮。近年来,卷积神经网络[3-5](Convolution Neural Network,CNN)在图像分类和识别领域取得了许多实质性进展,并已经在手写数字识别、人脸检测领域展现了其优异的性能。Krizhevsky[6]使用深度卷积神经网络在ImageNet分类任务中得到了83.6%准确率的标志性成果。Zisserman[7]等人使用卷积神经网络在LFW人脸数据集上得到97%的识别率。
然而在卷积神经网络训练过程中,每层输入数据的分布随上一层的参数变化而发生变化,每次调整网络时要使每一层去适应输入的分布变化。这会导致神经网络很难训练得到一组性能最优的参数。在网络初始化时仔细地调整参数和降低训练过程中使用的学习率可以在一定程度上降低这种由分布变化带来的影响,但同时也会降低网络的训练速度。在传统的深度网络中,学习率太高可能会导致梯度爆炸或消失,以及陷入局部最小值的问题。通过归一化整个网络中的激活,可以防止参数的微小变化通过深层网络扩大为梯度的次优变化。文献[8]中通过在网络隐藏层中对每一块输入数据进行归一化处理来解决这一问题,称之为批归一化(batch normalization),并将批归一化技术应用到图像分类模型中,获取了相同的分类精度并且训练次数减少了14倍,大幅度优于原始模型。文献[9]中对AlexNet 和 VGG19均做了批归一化处理,发现网络的训练时间和分类错误率都有所下降。
近年来,批归一化已经成为训练深度神经网络的标准工具包的一部分[10]。批归一化使模型训练时内部激活的分布更加稳定,令训练时使用更高的学习率成为可能,并减少了模型对初始化参数的敏感度。这些影响可以加快训练速度,而且有时候甚至可以急剧增加训练速度。目前,批归一化已经成功地应用于最先进的架构中,比如残差网络[11](residual networks)。但是在实际应用中,批归一化高度依赖于数据块(mini-batch)的大小,训练网络时要对数据块大小进行约束,并且涉及很多矩阵运算,导致训练时间过长。本文针对神经网络训练时间长、难以调整的问题,研究了批归一化集成算法。分析了导致加入批归一化的神经网络在训练时收敛不稳定的原因,并采用集成网络的方法在不降低原有性能的同时使网络的收敛更加稳定、快速。
1 网络结构设计
本文实验中使用的LeNet[12]网络结构如表1所示。

表1 LeNet网络结构表
网络主要基于构建块的方式进行设计,是由五个部分(block)组成的16层卷积神经网络,每个部分的基本结构为:线性运算(conv)-批归一化(bnorm)-非线性运算(relu或pool)。block1、block2和block3中的线性操作类型为卷积操作,每个卷积操作采用5×5大小的卷积核来感知图像上的局部信息。为了能够在训练网络时快速得到一个局部最优的网络,每个卷积操作后添加了一个批归一化操作来提高网络在优化时目标函数的收敛速度。网络的最后两个block中的线性操作为全连接操作。全连接运算与卷积运算相似,只是卷积核的大小与本层输入的大小相同,这样每个卷积核可以将全部的信息整合到一起,感知整张图像的信息。第一个全连接部分(block4)输出为一个512维的向量,最后一个全连接(block5)输出对应于训练数据集中类别标签的数量。同时,block5也可以看作一个多路分类预测器,根据block4提取出的512维的特征向量预测出表示每个类别可能性的预测向量。输出的预测向量最终通过损失层(loss)的softmax函数计算得出一个对每个类别的后验概率,并得到优化目标进而通过反向传播调整网络。
2 批归一化问题分析
2.1 批归一化技术介绍
在训练神经网络时,一般会对输入数据进行取均值处理或白化[13](whiten)处理来加快训练。常用的白化方法是在对数据进行主成分分析[14-15](PCA)操作后进行归一化操作。如图1所示,左边的图像是原始数据的分布图像;中间的图像是使用PCA处理后的数据分布图像,数据分布的均值变为0并且被旋转到特征向量上,去除了数据的相关性;右边的图像是在中间数据分布的基础上进一步归一化处理,使数据服从高斯分布。
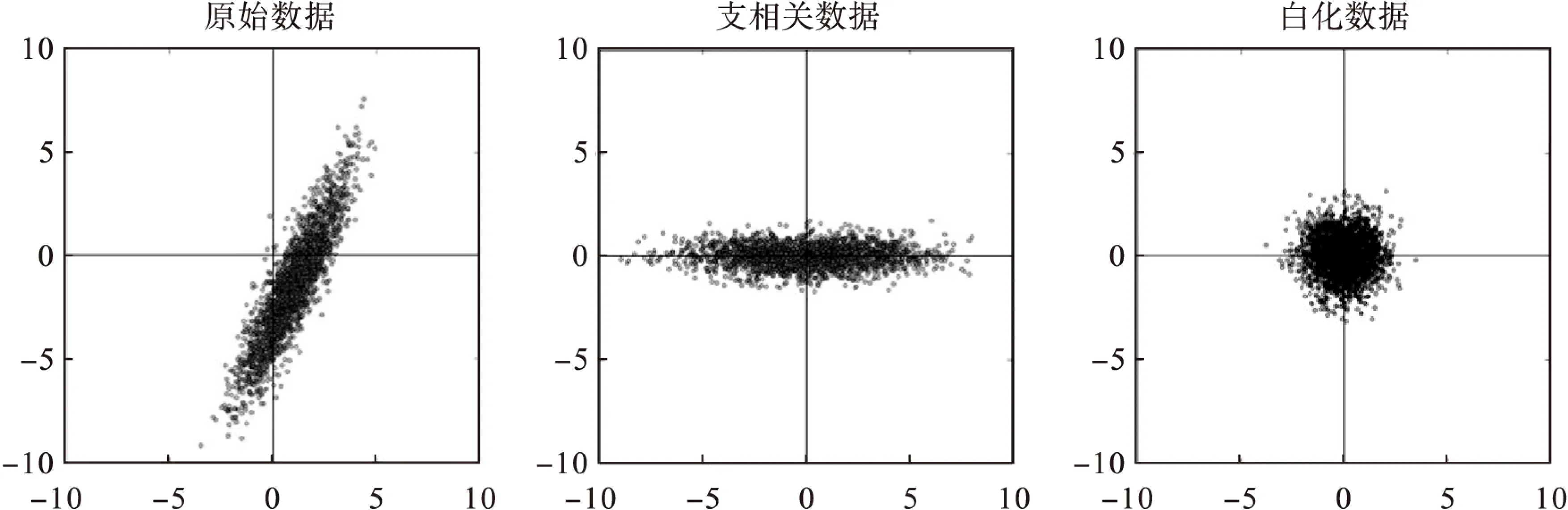
图1 数据白化示意图
虽然在神经网络中通过对每一层的输入数据进行白化处理可以很好地控制数据的分布变化,加快网络的训练速度。但是数据白化操作在反向传播过程中并不一定能够求得导数,且计算协方差矩阵和求逆的操作开销巨大,导致这种方法并不是实际可行的。
批归一化技术对数据白化的方法进行简化,单独地对每一个神经元的特征进行归一化处理并且每次只在一个训练用的数据块上计算均值和方差。对数据归一化的处理就是让数据的均值为0,方差为1,计算公式如式(1)所示。
(1)
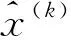
(2)
公式(1)和公式(2)的批归一化算法中的变换操作具体算法如表2所示。

表2 批归一化算法
在训练时需要计算损失函数对批归一化变换中参数的梯度,根据链式法则可以求得损失函数对批归一化中参数的导数,计算方法如公式(3)所示。
(3)
这样确保了网络在训练过程中,每层都能够对输入数据的分布进行学习。同时,减弱了数据中分布的变化,提高训练速度。在实际使用过程中,批归一化大多放在激活函数之前、卷积操作之后。采用了批归一化的网络有如下优点:
(1)网络中可以使用更大的学习率去学习参数;
(2)不需要考虑网络中参数初始化的问题;
(3)在一定程度上消除了使用Dropout的情况;
(4)与不加批归一化的网络相比,达到相同的精度减少了14倍的训练次数。
2.2 批归一化方差统计分析
批归一化是在数据集的每个子数据集(batch)上进行归一化计算,其中的两个关键参数均值和方差在测试时和实际应用中需要固定下来。根据训练数据集的每个子数据集上的结果可以计算出批归一化操作中的均值和方差这两个参数。常用的批归一化中均值和方差采用随机梯度下降法根据每个子数据集上的均值和方差进行更新,若每个子数据集计算得到的均值和方差差异较大就会导致批归一化中均值和方差在每轮迭代后的波动较大,使网络的错误率产生波动。
本文分别从Mnist数据集、Cifar-10数据集和Sat-4数据集上训练的LeNet网络中选取性能最优的模型进行统计分析。在每个数据块上分别计算对应的网络模型中四个批归一化输出结果的均值并分别统计每一个批归一化输出结果均值的方差。图2和图3分别为在Mnist数据集和Cifar-10数据集上得到的统计结果,图4为在Sat-4数据集上得到的统计结果,采用直方图的方式显示。
对于Mnist、Cifar-10和Sat-4三个数据集,网络中每个批归一化的输出结果数据分布都有一定的波动。其中,由于第一个批归一化操作和最后一个批归一化操作靠近输入和输出的位置,计算出的分布波动较大;中间两层批归一化操作输出结果的波动相对稳定。并且批归一化在Cifar-10数据集上得到的统计结果比Mnist数据集上的统计结果算出的方差较大,说明批归一化在Cifar-10数据集上每个数据块的计算输出结果差异更大。批归一化在Sat-4数据集上得到的统计结果较为接近。网络在Mnist数据集上的训练曲线比Cifar-10数据集上的训练曲线更加稳定。
由于这种波动是批归一化在确定公式中均值和方差时的波动所导致的,通过合理地设置批归一化中的两个常量、减少输出结果的波动,可以在一定程度上使网络的收敛更加稳定。

图2 批归一化在Mnist上的统计结果

图3批归一化在Cifar-10上的统计结果

图4 批归一化在Sat-4上的统计结果
3 BN-Cluster基于批归一化参数聚类的DNN集成算法
现有的批归一化方法中的均值和方差通常采用梯度下降法,根据每一轮中每一个数据块上计算得到的均值和方差来进行微调。由于每个数据块上得到的均值和方差的差异较大,通过这种方法计算得到的批归一化中的均值和方差波动较大,导致网络波动较大。因此,我们采用集成学习方法,对网络在多个数据块上计算批归一化的均值和方差得到多个子神经网络。每个子神经网络仅在批归一化的均值和方差设置上有差异,其余网络层完全相同。通过多个网络结果投票的方式决定最终的分类结果。
基于批归一化参数聚类的CNN集成算法具体如表3所示。

表3 基于批归一化参数聚类的CNN集成算法
4 实验
4.1 实验设置
本文选取了遥感图像数据集Sat-4、普通图像数据集Cifar-10和Mnist。Sat-4数据集图像包含4个通道,红(R)、绿、(G)、蓝(B)以及近红外(NIR)通道,每个图像大小均为28×28像素。Sat-4包含共50万张图片,共4个类别,分为贫瘠土地(barren)、树木(trees)、草地(grass)以及除了以上三种类别的其他类别(none)。Cifar-10数据集图像包含3个通道,分别是红(R)、绿、(G)、蓝(B),每个图像大小均为32×32像素。Mnist由7万张图片组成,共有10个类别。在 MNIST 数据集中每张图片由 28×28 个像素点构成,每个像素点用一个灰度值表示。
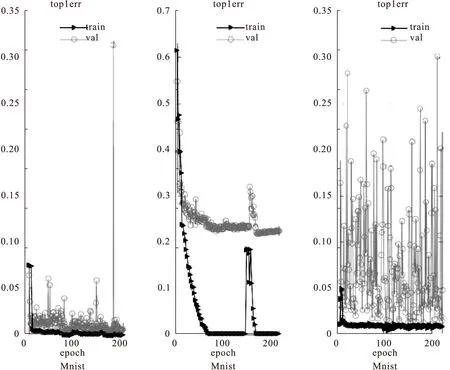
图5 LeNet在Mnist、Cifar-10和Sat-4数据集上的错误率曲线
4.2 实验结果分析
由于本文中使用的网络结构和数据集较大,不便于进行大量的运算。实验中首先采用了MatConvNet工具包中Mnist数据集上的LeNet网络进行验证实验,分析导致加入了批归一化的神经网络收敛不稳定的因素。Mnist数据集上使用的LeNet网络中包含四个部分,网络结构相对简单便于进行统计和分析。我们在每个部分包中添加一个批归一化操作,使用相同结构的LeNet网络分别在Mnist数据集和Cifar数据集上训练并选择性能最优的网络模型。为了得到较好的用于实验验证的网络模型,训练时将数据划分成每500个数据为一个数据块,采用0.1的学习率进行了共200轮的迭代。图5为LeNet在Mnist数据集、Cifar数据集和Sat-4数据集上训练时在训练数据集和验证数据集上的分类错误率曲线。图中三角形图例为模型在训练集上的分类错误率曲线,用于观察模型对训练数据的拟合程度;圆形图例为模型在验证集上的错误率曲线。在选择网络模型时我们更关注模型在验证时的分类精度,依据每一轮迭代得到的错误率曲线选择最优的参数模型。
通过200轮迭代的错误率曲线可以直观地看出网络在Mnist数据集上训练时的错误率曲线波动集中在0到0.05之间,误差波动较小,网络收敛相对稳定。在Cifar-10数据集上训练网络的错误率曲线波动集中在0.2到0.3之间,在Sat-4数据集上训练时的错误率曲线波动集中在0.05到0.2之间,在Sat-4数据集上的错误曲线波动幅度较大且频繁、无规律。根据网络训练时的错误率曲线对网络参数进行选择时,Mnist数据集在100轮迭代之前可以选出一个性能较好的网络,而在Cifar和Sat-4数据集上则需要接近200轮的迭代。
对每个网络计算每个数据块上的子网络时,需要花费大量的时间和存储空间去计算和保存每个子网络。实验中,我们分别从Mnist、Cifar-10和Sat-4数据集的前100轮迭代得到的网络中每轮迭代选取一个网络进行实验,共100个网络模型进行改进测试。对100个网络模型分别计算在各个数据块上的子网络,根据使用的数据块计算子网络中批归一化操作的均值和方差。计算完成后,分别将一个网络的每个子网络中所有的批归一化层的均值和方差展开成一个向量,每个子网络对应一个与批归一化参数设置相关的向量。采用k-center方法对所有子网络的参数向量聚类,得到100组参数设置,并根据相应的参数找到对应的子网络。在测试网络性能时对100个子网络的进行集成,将每个子网络计算得到的标签预测向量按照相应标签的预测值求和,得到一个新的标签预测向量作为最终的输出结果。集成后的神经网络由100个子网络组成,top1error的分类精度如图6所示。

图6 改进后神经网络的训练曲线
实验结果证明,采用集成学习的方法确定批归一化的参数,网络在Cifar数据集上训练时错误率曲线波动明显降低,在Mnist数据集上也有所减少。与图2中在Sat-4数据集上训练曲线相比,采用了集成批归一化后的网络在Sat-4数据集上训练时收敛更加稳定。同时,改进后的网络在验证集上的分类精度没有损失,而且能够在更短的时间得到表现更稳定、性能较好的网络模型。
5 结论
本文针对神经网络训练时间长、难以调整的问题,研究了批归一化集成算法。采用构建块的思想设计了面向图像分类的卷积神经网络框架,该网络分别在Mnist、Cifar-10和Sat-4三个数据集上训练,并在每个数据块上分别计算对应的网络模型中性能最优的四个批归一化输出结果的均值,并分别统计每一个批归一化输出结果均值的方差。分析了导致加入批归一化的神经网络在训练时收敛不稳定的原因,并采用集成网络的方法在不降低原有性能的同时使网络的收敛更加稳定、快速。
猜你喜欢
四川大学学报(自然科学版)(2021年6期)2021-12-27
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
新课程·上旬(2019年1期)2019-03-18
唐山师范学院学报(2018年6期)2018-12-25
初中生世界·九年级(2017年10期)2017-11-08
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
文苑(2015年9期)2015-09-10
