
基于XGBoost的跨境电商企业征信等级预测研究
2018-07-21 02:20王珊珊查林涛
韶关学院学报 2018年6期
王珊珊,查林涛
(安徽国际商务职业学院 商贸流通学院,安徽 合肥230011)
在国内,对于跨境电子商务平台研究有很多,主要集中在模式选择、发展路径研究方面.付蔚蔚[1]提出了利用AHP评价法用于中小企业跨境电商平台选择.宛建伟[2]分析了目前已经成型的进口跨境电商发展模式的利弊以及跨境电商网站运营建设等问题.刘晋飞[3]利用因子分析法构建了电商采纳及企业发展指标体系,探讨电子商务采纳及对跨境电商制造型企业成长的影响和作用机理.但对供应商建立完善的信用评价体系的研究则较少.
本文根据数据分析基本流程构建大数据环境下的指标体系.流程如下:(1)数据采集.面对互联网海量的数据,在确定基本评价指标的基础上,利用爬虫工具对数据进行获取,使得数据充足并具有时效性.(2)数据清洗.虽然在互联网上获取的数据是海量的,但也存在着大量的噪音.为了去除这些噪音,需要对数据进行了清洗[4].(3)数据标准化.最后在构建指标之前,采用Z标准化来对数据进行处理[5].通过以上步骤,本文构建供应商信用指标:企业基本指标(销售额、从业人员数)、产品质量(产品与描述相符程度、信息完整性、好评率)、服务质量(服务细节评分、客服首次响应时间)、顾客满意度(新客增长率、老客回头率).
1 信用评估模型
Boosting算法是一种机器学习方法[6],其主要作用是将弱分类转化为强分类,达到有效分类的目的,其中GBDT就是一种有代表性的Boosting算法[7].算法计算流程如下:
(1)根据最大熵理论,初始化为各训练样本赋予相同的权重,如:;
(2)迭代训练模型,每次迭代都使用一种弱分类器对训练样本进行分类,并计算分类错误率:

其中ωi:第i个训练样本在本次迭代中的权重,Gm:第m个弱分类器;
(3)计算分类器权重:am=log((1-errm)/errm);
(4) 在第 m+1 次迭代时,修改样本权重,将 ωi重置为可以看出,在第 m+1 次迭代中,对于第m次迭代分类错误的样本会得到更多的权重;
(5)全部迭代完成后,把所有弱分类器集成在一起,构成完整的分类模型,其最终效果采用投票方式计算.
XGBoost[8]算法在GBDT基础上对性能的一种改进,可以稳定高效的在大数据环境下执行,其中最基本的组成结构为回归树(CART).XGBoost模型可以表示为:
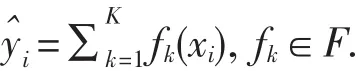
其中,i=1,2,…,n为特征数据,F为所有弱分类器的集合,可以为各种回归树,弱分类器由fk表示.二分类中,定义≥0.5 的为正类,<0.5 为反类.
建立模型需要寻找使目标函数最小化的前提下,所能找到的最优参数,目标函数fobj(θ)由误差项L(θ)和正则化项Ω(θ)组合构成,其中L(θ)表示函数的损失,即预测结果与真值之间的差距,Ω(θ)用于降低模型复杂度,避免出现过拟合.定义目标函数fobj(θ)表达式:

定义:

建模时,除了对现有模型进行训练以外,XGBoost增加了一个函数f(x),新函数的加入有助于最小化目标函数,将该新加入的函数引入模型中,主要计算过程如下:
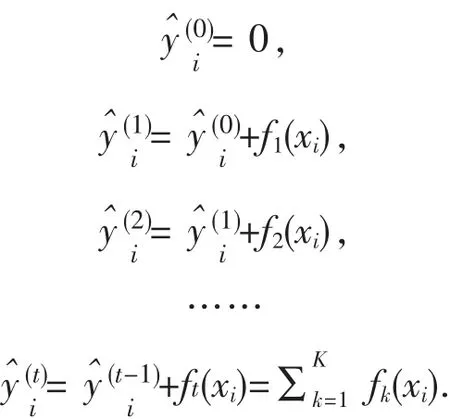

式中,C表示与f(x)无关的常数项.
利用泰勒公式对目标函数进行展开,目标函数可以近似为:

可见,特征点在误差函数上的一阶和二阶导数可以决定目标函数的值.
2 模型复杂度及评价标准
为了计算模型复杂度,将f(x)细化:划分回归树为两部分,一部分表示树结构本身,用q表示,另一部分表示叶子节点的权重,用w表示,因此f(x)表示为:

输入变量特征被树结构映射到叶子节点索引id上,同时为每个叶子节点赋予了一个权重w作为叶子节点的得分.因此,定义XGBoost模型复杂度为每棵弱分类器树中节点的个数与其对应叶子节点得分的平方和:

式中,γ,T是超参数,用于防止模型过拟合.目标函数可以改写成:

式中,Ij={i|q(xi)=j}表示第j棵树中所有叶子节点集合.
令:

目标函数变化为:
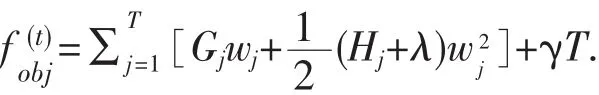
假设,树结构q已知,通过优化目标函数寻找最好的参数w,以及对应的目标函数最大值,问题便转换为求解二次函数最小值问题,可以得到:

其中,fobj作为模型评价函数,fobj值与模型效果成反比.
以本文构建的大数据环境下的征信体系作为特征,使用XGBoost模型为每个样本用户预测一个征信等级,建立信用评估等级,由差、中、良和优表示,为了便于计算,分别为各等级设定取值1~4.本文使用相应类别的准确率(precision)和召回率(recall)作为评价指标,定义为.其中,Tp为正确预测真实目标类别的样本数量,Np为错误预测真实目标类别的样本数量,FN为错误预测非真实目标类别的样本数量.
3 实验效果
本文选取的跨境平台供应商样本数2 752条,取90%的样本作为训练集,剩下10%作为测试集,训练集用于模型训练,测试集用来衡量模型效果.
首先将样本都进行随机处理,充分的随机处理可以保证效果的客观.XGBoost模型本身就有相应的正则化项用于防止模型过拟合,设置学习率0.3,最大深度3,经过138次迭代后,训练集损失持续下降,但测试集损失开始上升,模型效果达到最佳,如图1所示.
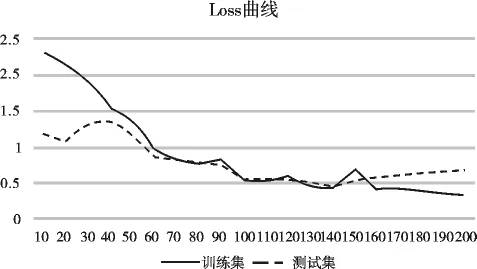
图1 loss曲线
最终模型准确度均值如表2所示,召回率如表3所示.表2的数据表示了多分类任务下,对各真实类别预测的准确度,矩阵中每一元素对应着模型预测类别为该实际类别的概率.对角线上元素代表了该类被正确预测的概率,且每一行加总为1.可以看出,本文建立的对企业信用预测的模型效果较好,可以精确预测目标所属类别.

表2 信用等级查准率均值

表3 信用等级召回率均值
4 结语
本文从数据分析的基本流程出发.在建立XGBoost模型前,对跨境电商平台供应商的信用特征进行分析,有效地获取多维数据,并对数据进行清洗和处理.据此建立了针对跨境电商平台供应商信用指标体系,相信对跨境电商平台信用评价起到指导作用.
从XGBoost模型搭建分类预测模式看来,该模型虽在人工智能领域应用较多,但是在跨境电商供应商信用评价过程中也表现出良好的稳定性和泛化性,可以推广到实际问题中.下一步可以扩大样本数据,构建更为精确的分类模型,对改模型进行更进一步的优化.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国外汇(2019年20期)2019-11-25
中国外汇(2019年14期)2019-10-14
中国外汇(2019年21期)2019-05-21
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
