
基于CBR的儿科疾病诊疗系统的数据库设计和案例相似度算法研究
2018-07-21 02:20张德青
韶关学院学报 2018年6期
张德青
(安徽三联学院 计算机工程学院,安徽 合肥 230000)
案例推理(CBR)技术目前已成为人工智能领域中使用频率较高、发展成熟的智能知识推理技术之一,尤其是医疗诊断系统的设计中.笔者拟将这一智能术技引入至儿科疾病诊疗系统的设计,旨在提高儿科疾病诊疗的精准度和效率.
1 案例推理的基本原理和应用
1.1 案例推理的基本原理
案例推理是以过去已解决的问题的经验知识为基础,进一步推理出类似新问题的解决方案的过程[1].其中的知识是以案例的形式存储在系统数据库中,每次遇到新的问题时,便可在系统中搜索与该待解决问题最接近的案例(源案例),并以此为依据得到新问题(目标案例)的解.若该解决方案可以很好地处理新问题,则说明问题得到解决;否则需要对源案例作适当的修正,并将该问题也作为新案例存储到案例库中,完成案例学习的过程.
一个完整的案例推理应该包含:案例表示、案例检索、案例重用、案例学习等4个部分,过程见图1.

图1 完整的案例推理过程
整个过程可描述为:首先抽取问题的特征属性,通过GUI将问题表征成案例的形式输入系统并发起检索请求,然后系统根据事先设定的相似度匹配算法从源案例数据库中检索与之相匹配的案例.若检索成功,则案例得到重用,问题解决;若未检索到与之匹配的案例则需对该案例进行修正,通过案例学习之后作为新案例保存到案例库中去[2].案例检索方法的优劣将直接影响到系统检索的速度和精准度,案例检索是系统设计中的一个重要环节.
1.2 CBR应用于儿科医疗诊断系统中的必要性
案例推理主要适用于一些知识难以表示、难以获取,但又已积累了丰富经验的案例领域中.随着这一技术研究的不断深入,使得其在法律咨询、医疗系统、图像分割、商业决策等方面的应用日趋广泛,尤其是医疗系统中.医生进行临床诊断的过程恰好与案例推理的过程非常相似:医生具有的临床经验非常重要,因为经验丰富的医生在遇到新的病症时,可以很快地从经验中找出相同或类似的病症治疗方法,而每次成功的治疗又为将来积累了新的经验,达到精益求精的境界[3].
儿科向来是医院中的一个人满为患的科室,许多家长甚至因为孩子发烧而在诊室外排队等待数小时,尤其遇到一些病毒高发期时更是如此.对于一些常见的疾病,若使用这样一个CBR的医疗诊断系统,家长便可以通过系统的案例检索推理得到较为有效的解决方案,轻松应对常见疾病.儿科疾病诊疗本就属医疗诊疗中的一个分支,故案例推理技术亦可以很好地应用到儿科常见疾病的诊疗系统中.建立一个儿科常见疾病诊疗CBR系统可以适当地为家长们解决看病难的窘境.
2 案例推理技术在儿科疾病诊疗系统中的应用
2.1 案例推理在儿科常见疾病诊疗系统中的案例表示
将案例推理应用于儿科疾病诊疗系统的实质就是使用人工智能技术,用计算机来辅助模拟实现专家进行儿科疾病诊断的过程.对病症案例特征属性提取的效果,能直接影响病症的推理效率,要将案例推理技术引入儿科常见疾病诊疗系统,首要的是进行儿科常见疾病案例的知识表示[4].
案例表示就是根据疾病的特点,抽取其中的特征属性,使用一定的符号语言,借助于计算机技术把案例编码成特定的数据结构的形式,以便存入案例数据库中.本系统拟采用框架表示法进行案例表示,这一表示法的优点在于它可以很好地描述案例的细节,能更好地满足结构化的需求.假设文中对所属范围的儿科疾病案例表示为:X(p1,p2,p3,…,pn),其中:p1,p2,…,pn 表示儿科常见疾病案例的 n 个特征属性,若共有m条记录,则该案例库则可以表示成一个m*n的二维表.
2.2 儿科疾病诊疗系统案例数据库设计
案例数据库的基本数据表及其主要属性见表1.建立案例数据库的目的是存储源案例,记录每一源案例的各项属性值,以便检索匹配重用.案例数据库的逻辑设计将直接影响到案例检索的效率,另外还必须考虑到数据库中源案例的数量对检索效率的影响,本系统采集了近1 000条年龄段为0~14岁儿童的常见疾病案例数据信息.

表1 Case基本数据
要建立这样的一个儿科常见疾病诊疗案例数据库,则首先需要按照X(p1,p2,p3,…,pn)的数据结构建立一张案例的基本数据表,并列出主要属性.
2.2.1 数据采集
系统选择的DBMS为MSSQL Server,根据表1给出的字段建立表结构,同时确定并设置各字段的域.通过MSSQL Server的数据导入/导出功能,将数据标本按照以上属性要求优化,筛选并删除无效数据之后一次性导入至基本数据表中,即可得到最基本的案例表.由于数据较多,故只取前10组案例的部分属性数据为例(见图 2).
2.2.2 数据转换
为了进一步简化设计,首先对数据进行预处理,进而优化源案例库中的数据,最终保留m个有效案例,即CASE=(X1,X2,…,Xm).同时,考虑到度量各属性的数据类型有所不同,在数据处理中将除数值类型属性和Result、Plan之外的属性均转换为布尔类型,即将案例库中的基本数据转换为m*n大小的二维矩阵P,其中m为案例的个数,n为所有属性的个数,此时矩阵中任一元素Pij=1 or 0.
实现这一转换的最有效的方法是对基本数据表中的数据进行相应的转换计算.具体算法步骤为:
(1)新建数据库数据表,要求除主键字段、姓名字段、Result和Plan字段为varchar类型之外,其余所有字段的数据类型均设为Bit类型,字段值分别来自于基本数据表中相应字段值的计算结果;
(2)解决以上问题的有效方法可以借助于创建一个本地存储过程p_changedata来实现,通过执行存储过程得到待求解的结果,同时将求解结果写入至数据表2中,其算法描述为:
S1:声明n个变量,分别用于保存数据表中各字段的计算结果;
S2:使用T-SQL语句中的CASE…END语句对每一属性值的所属情况加以判断求解,对应结果只能为1或0,如:性别为男,则Sex=1,否则Sex=0;
S3:对于多值字段(如:Skin、Cough等),则使用模式匹配like+通配符%进行匹配,若匹配成功(即包含相应项的值),则对应字段取值为1,否则,取值为0;
S4:使用Select Top i查询得到经计算后的第i条结果记录,并使用insert语句将之写入数据表中;
S5:若i<=m则转S2,否则求解结束,新数据表记录写入完毕,完成数据转换.

图2 基本数据表中部分属性数
2.2.3 实验结果
此处仅以性别和鼻腔这两个属性为例,使用以上算法编写存储过程,主要代码如下:
create proc p_changedata
as
--声明所用到的记录总数、循环变量、性别和鼻腔属性
declare@cnt int,@i int,@sex bit,
@Nose131 bit,@Nose132 bit,@Nose133 bit
select@cnt=COUNT(*)from 基本数据表
select@i=1
while(@i<=@cnt)
begin
select top (@i)
@sex=case sex when'男 'then 1 end,--性别
@Nose131=case when Nose13 like'%1 鼻塞%'then 1 end,--鼻腔
@Nose132=case when Nose13 like'%2鼻翼扇动%'then 1 end,
@Nose133=case when Nose13 like'%3鼻腔有分泌物%'then 1 end
from基本数据
--将转换之后的数据写入新表
insert into数据表2
(sex,Nose131,Nose132,Nose133)
values(@sex,
@Nose131,@Nose132,@Nose133)
set@i=@i+1
end.
通过执行存储过程p_changedata,将转换后得到的布尔类型的数据写入新表中,其结果见图3.经过这一数据转换,既可以使得度量属性的数据类型统一,同时还可以简化案例检索的算法设计.

图3 转换后的数据表2中对应部分数
2.3 基于案例推理的儿科疾病诊疗系统的流程设计
将案例推理技术引入至儿科疾病诊疗系统的根本目的是为儿科医生对疾病诊断提供一定的诊断依据,当目标案例出现时,通过案例检索评估源案例与目标案例的相似度以获取相似案例,提高儿科常见疾病诊断的精准率,其系统设计的流程简要表示见图4[5].
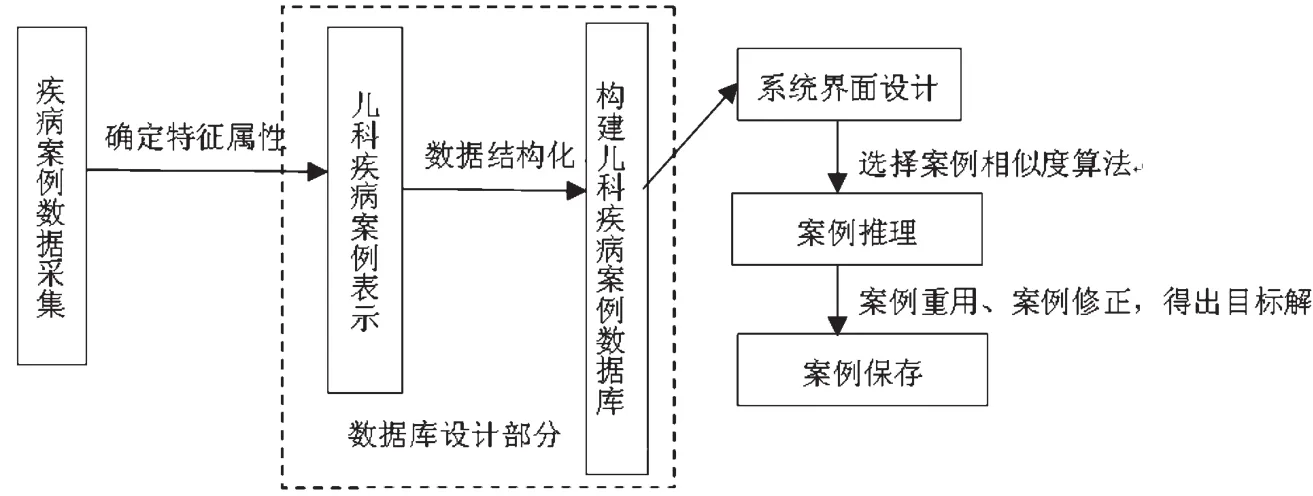
图4 引入案例推理的系统设计流程
3 儿科疾病诊疗系统中的案例检索
案例检索是案例推理中的关键环节,它是从案例库中检索与目标案例最为相似的源案例,并利用这些源案例的解来推理出目标案例的解,其实质就是通过比较目标案例和源案例的相似度来实现的.案例相似度算法选择的优劣将直接影响到所检索出的案例的匹配精确度,图4的案例推理系统设计流程中的相似度算法的选择显得尤为重要.
3.1 相似度计算方法介绍
常见的相似度计算方法主要有最近邻检索策略法、归纳推理法以及知识引导的检索方法等[6].最近邻检索方法是一项较为简单和成熟的检索方法,主要是通过计算目标案例和源案例的各属性之间的距离,进而得到案例整体相似度的一种检索方法[7].
3.2 采用的案例相似度计算方法
在求解相似度之前,通过主成分分析法来确定案例中每一特征属性的权重ωi,这里的ωi表示第i个属性 pi在当前案例中的权重,有:ωi∈(0,1),且ωi=1.首先采用欧几里得方法计算出相对应的两属性间的距离差异的结果作为目标案例 Y(yp1,yp2,…,ypn)和源案例 Xi(xp1,xp2,…,xpn)(Xi∈CASE)中各自的第 i个属性的相似度,有:

设Sim(Y,Xi)为目标案例Y和源案例Xi两案例的整体相似度,则根据最近邻检索方法的计算公式[5],有:
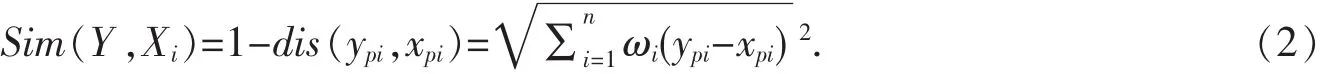
通过公式(1)和(2)可知:两属性之间的距离越小说明属性越相似,案例相似度Sim值越大说明两案例间的相似度越高.按此方法进行计算,在源案例库中检索出一个相似度最高的案例作为目标案例的建议解.若要进一步提高案例检索的精准性,还取决于各权重的确定及属性的局部相似性.
3.3 存在的问题与改进
3.3.1 问题与改进
虽然此方法在案例检索中被使用的频率较高,但也存在着一定的弊端,如:权重的确定、度量各属性的数据类型不统一等.这里主要考虑度量属性的数据类型的问题.公式(2)一般只适用于数值类型数据的计算,故具体计算中还应考虑增加非数值类型数据的相似度计算,即采用混合型的计算方法.;已转换为布尔值类型的属性只需对比相应值是否相同即可;字符串类型的属性可采用表2中的相应计算公式进行计算求解.
数值类型的属性可以直接采用欧式距离计算公式进行计算,即:

表2 不同类型的相似度计算方法
最后将本案例库中的数据按照此前所提及的主成分分析法得到的各属性的权值ωi,进行综合计算得到两案例间的总体相似度:该式中第一部分为数值类型属性的相似度,第二部分为所有布尔类型属性的相似度,第三部分为所有字符串类型属性的相似度.
通过这一修正避免了布尔类型属性间原先的相似度只能为0或1的情况,可以更为精确地求解出布尔类型属性间的相似度;增加了字符串类型属性的计算,解决了原先数值距离计算所不能实现的相似度的求解.
4 结语
本文分析了一个基于案例推理的儿科诊疗系统设计的整个流程,特别是案例数据库的设计及数据处理操作过程,以及最近邻这一案例检索方法在本诊断系统中的改进应用,提出了案例检索方法中存在的度量方法不统一的问题并提出了相应的解决方法,以期能为该系统的进一步研究和后期的推广使用奠定了基础.
猜你喜欢
中国毕业后医学教育(2022年4期)2022-11-29
水上消防(2021年4期)2021-11-05
现代畜牧科技(2021年5期)2021-07-20
现代畜牧科技(2021年2期)2021-03-19
内蒙古教育(2021年2期)2021-02-12
党员生活·下(2020年3期)2020-04-20
党员生活(2020年2期)2020-04-17
铁道通信信号(2018年10期)2018-12-06
韩国语教学与研究(2017年1期)2017-11-12
中国石油企业(2014年4期)2014-11-30
