
用于轴承表面缺陷分类的特征选择算法
2018-07-21 14:55宇文旋卢满怀
轴承 2018年1期
宇文旋,卢满怀
(1.电子科技大学 机械电子工程学院,成都 611731;2.电子科技大学中山学院 机电工程学院,广东 中山 528400)
基于机器视觉的检测方法是轴承表面缺陷检测的重要手段,其高速、无损、自动化等特点吸引了大批研究人员。作为企业的管理人员,往往不仅希望将缺陷产品剔除,还希望得到缺陷的类别信息,以改进生产工艺及设备。
为完成轴承表面缺陷类型的准确识别,需要选择高效的分类特征。文献[1-3]对轴承表面缺陷的检出方法进行了深入研究,为进一步的缺陷类型识别奠定了一定基础。文献[4]以轴承生产和装配过程中产生的锈斑、划痕、裂纹等缺陷为研究对象,采用缺陷区域的单一特征——圆度作为分类特征,可识别出差别明显的缺陷类型。文献[5]研究了铁路货车轴承常见的缺陷,以缺陷区域的面积、伸长度、厚实度、圆度、边缘平滑度等作为分类特征,但由于未进行专门的特征选择,分类正确率仅80%。文献[6]在研究轴承使用过程中产生的外观缺陷分类时,分析了表面缺陷二值图像的几何特征和形状矩特征,进行了简单的比较选择,识别率提高到88%。文献[7]提出的轴承表面缺陷识别算法考虑了定位、光照、放射不变性等因素,选择缺陷的7个Hu矩值作为分类特征,识别率进一步提高到90%。文献[8]在轴承钢球生产过程缺陷分类的研究中,深入分析了缺陷的面积、长短径比、欧拉数等特征,并用于点、凹坑、群点、划伤、擦伤这5类缺陷的分类中,准确率高达96%。
综上所述,随着研究的不断深入,缺陷的识别率不断提高,但缺陷分类特征的选择这一重要环节多依赖相关人员的经验,未引入有效的特征选择算法,导致所选特征易出现可分性差,特征之间相关性高等缺点,从而影响分类器的性能,有必要对特征选择算法进行专门研究。因此,基于上述分析提出了一种用于轴承表面缺陷分类的特征选择算法,并通过对比试验进行分析验证。
1 特征选择算法流程
特征选择算法整体流程如图1所示,主要分为以下4个步骤:1)特征池的建立,搜集分类对象尽可能多的特征,组合成一个备选特征集合;2)数据获取与处理,通过图像采集、图像处理、特征计算等步骤实现样本由图像到归一化特征向量的转化;3)降维目标确立,根据特征池所含特征维数、峰值现象和训练样本数量等因素综合决定最终用于分类的特征个数;4)特征选择,根据样本数据和降维目标用所设计的特征选择算法从特征池中选出分类性能较好的特征组合。
2 准备阶段
准备阶段虽然不属于特征选择的核心算法,但为算法提供了必需的备选特征、样本数据和目标,是进行特征选择的基础条件。
2.1 特征池的建立
特征池是所研究分类对象的各种特征的集合,可用 X={xi},(i=1,2,…,d)表示。对于一个具体的特征池,其需具备有限性、可扩展性和一定的通用性。有限性指对于某一类研究对象,现阶段可得到的特征数量是有限的;可扩展性是指随着相关学科的发展,新的特征被提出后可随时加入到特征池中;通用性是指某一领域的特征池一旦建立,相关的特征选择工作就可以借鉴该特征池。特征池的建立为特征选择提供了“原材料”,其所含特征维数决定了特征选择维数的上限,其含分类信息的丰富程度决定了最终选取特征的分类能力。因此建立合理的特征池是进行特征选择的重要内容。
机器视觉中一般采用图像特征,其可分为基于区域的特征、基于灰度的特征和基于纹理的特征[9],每种类型都有数量不等的特征,通过收集和整理,初步建立了含有57个特征的特征池(表1)。

表1 图像特征池Tab.1 Image feature pool
2.2 数据获取与处理
数据获取指通过图像采集得到样本的图像,图像采集过程受光照、拍摄角度等外部环境影响较大,为避免这种影响,工业系统的图像采集装置一般安放于相对稳定的环境。
数据处理则是指对所取得的图像进行分割、特征计算和归一化等一系列处理过程。其中归一化的作用是对整个训练集中所有训练样本的同一特征分量进行尺度变换,使在全部训练集上变换后的数据处于[0,1]或 [-1,1]范围内[9-10],以消除特征动态范围的影响。
2.3 降维目标确立
降维目标不仅受特征池中特征数目的限制,还会受训练样本数量N的影响,一般而言,训练样本数量越多,所选分类特征亦可相应增加。而当训练样本数量N不变时,增加分类特征的数量d′可使分类器的性能得到初步的改进,但随着特征数量的增加,分类器的错误率Pe会上升,这种现象称为峰值现象[11],如图2所示。通常Pe最小值发生在N/a处,其中a为经验值,可取2~10之间的数。
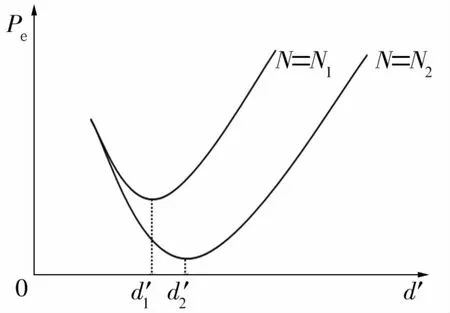
图2 峰值现象Fig.2 Peak phenomenon
在确定分类特征数量前,可首先确定训练样本的个数,然后计算峰值处的特征数量,在目标维数小于峰值维数前提下,再根据分类问题的复杂程度等因素做出最终决定。
3 核心算法
经过上述准备阶段,特征选择就转化为以样本数据所提供的信息为基础,从备选样本中选出由降维目标确定特征作为最终分类特征的问题,其核心是设计有效的特征选择算法,选出备选特征中的最优分类特征组合。
3.1 算法原理
常用的特征选择算法有标量特征选择和特征向量选择。标量特征选择是指分别计算每个特征的可分性判据值,并将特征以判据值降序排列,选择前d′个特征作为分类特征的算法。其具有计算简单、易于理解等优点,但没有考虑特征之间的相关性,只有当特征之间相互独立时才能保证解的最优性。特征向量选择是指从原始的d维特征中任选d′个进行组合,然后计算每种组合的类可分性判据,从中选择使判据最优的特征组合作为分类特征[12]。特征向量选择法选出的特征具有更好的可分性,但当原始特征和所需的特征维数较大时,计算量会急剧增加,仅适用于维数较低的特征选择。
为利用上述算法的优点,同时克服其缺点,在上述算法基础上引入相关分析,提出了一种综合运用相关分析、标量特征选择和特征向量选择的综合算法。首先,根据可分性判据将所有特征按分类性能由好到差排序,实现特征池X到特征向量x(d)的转化;其次,对各特征之间进行相关性分析,剔除相关性较强的特征,特征向量由x(d)降维到 x(d1);然后,对 x(d1)进行标量特征选择,即只选择x(d1)的前d2个特征组成新的特征向量x(d2),实现第 2次降维;最后,对 x(d2)进行特征向量选择,选出x(d2)中d′个特征组合成的最佳分类组合,得到最终的分类特征向量x(d′)。
3.2 算法实现
根据上述算法原理,建立了一种以相关系数为相关性特征选择判据,以Fisher判别率(Fisher Discrimination Ratio,FDR)为标量特征选择判据,以J1为特征向量选择判据的具体算法[13]。
假设已经按算法流程建立了特征池X,取得了标准化的训练样本集T,并确立了降维目标d′。其中,特征池中有d个特征,用X={xl},(l=1,2,…,d)表示;训练样本集 T有 c种类型(c≥3),分别为 ω1,ω2,…,ωc,每个类型 ωi有 Ni个样本,共有N个训练样本;降维目标就是从特征池中的d个特征中,选择d′个作为最终分类特征,其具体步骤如下:
(1)FDR特征排序
特征池中的特征以集合形式存在,为便于表示和计算,需要将所有特征以一定顺序组合成一个特征向量,FDR用于表征单个特征的可分性,FDR值越大,特征可分性越好。
对于特征池中的任一特征xl,其FDR值为

对X中的所有特征进行上述计算,可得到所有特征的FDR值,根据FDR值由大到小将特征重新排序,得到特征向量 x=(x1,x2,…,xd)T。
(2)相关性特征选择
相关性特征选择指用特征之间的相关性做评价指标,去除相关性高的特征,保留相对较为独立的特征。相关性的评价可用相关系数作指标。
将训练样本集T中所有样本的特征xl按顺序组成向量xl,因为每个样本有d个特征,所以可生成d个这样的向量,任意2个向量xi,xj之间的相关系数为


根据特征顺序和相关系数对特征进行相关性特征选择。首先,采用x1对与其相关系数大于设定阈值的特征进行剔除;然后,依次用未被剔除的特征剔除其后与其相关系数大于阈值的特征,直到最后一个特征为止。通过本次筛选,得到了各特征相关性较低的特征向量x(d1),实现第1次降维。
(3)FDR特征选择
相关系数筛选后的特征既保留了原始特征的分类信息,又使各特征之间相关性大大降低,满足了标量特征选择的基本条件,且特征已经按FDR进行排序,因此直接取前d2个特征组成新的特征向量x(d2),实现第2次降维。
(4)向量特征选择

4 试验验证
可分性判据只是对特征可分性的理论评价,实际应用中以此特征设计的分类器的识别率才是对特征进行评价的更好指标。为此,设计了一个实际的缺陷类型识别任务,然后用随机选择算法、标量特征选择算法和文中算法分别进行特征选择并完成分类任务,通过比较识别率的高低判断算法的优劣。
试验选取6204型轴承外圈机加工过程中常见的磨削过量、擦伤、磕碰伤3种表面缺陷作为识别对象,并收集了此型号外圈的900个缺陷样本,每种缺陷300个。缺陷示例及其分割图像如图3所示。

图3 缺陷图像示例Fig.3 Images of defect examples
分别采用随机选择算法抽取3组特征,标量特征选择算法和文中算法各抽取1组特征,共进行了5组试验。随机从每种缺陷中各取出100个并编号作为训练样本,剩余600个编号后作为检测样本;以表1中57个特征作为原始特征,降维目标定为从60个特征中选择10个;采用线阵相机扫描方式采集图像,动态阈值分割算法分割缺陷区域,分量白化算法进行归一处理;以300个训练样本为基础,分别用随机抽取算法、标量特征选择算法和文中算法进行特征选择;根据输入特征维数,输出类别等确定了如图4所示的神经网络结构;分别用所选特征对多个相同结构的神经网络进行训练,并用训练后的神经网络对检测样本进行识别,得到每种方法的识别率,从而进行比较。
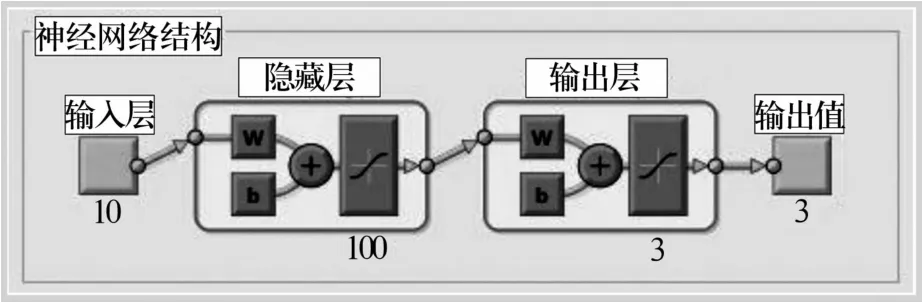
图4 BP神经网络Fig.4 BP neural network
试验结果见表2,由表可知:3组随机算法试验的识别率均不高,且很不稳定,最高识别率可达82.2%,最差识别率则仅19.0%。以FDR准则进行的标量特征选择试验也未取得好的效果,识别率仅66.7%。进一步分析发现其分类错误主要是将所有200个磨削过量缺陷误识别为擦伤,其余2类则完全正确识别。这种结果印证了算法本身的缺点,即所选单个特征具有较好的可分性,但特征之间可能存在强相关性,使特征组合总体分类能力下降,从而导致误识别。而文中算法则取得了良好的效果,在600个检测样本中,有3个被错误识别,包括:402号擦伤被识别为磕碰伤;492号和600号擦伤被识别为磨削过量,如图5所示。其余样本均正确识别,识别率高达99.5%。其部分试验数据见表3和表4,包括每种缺陷的5组数据以及被错误识别的样本数据(灰色标出)。

表2 各特征选择算法的识别率Tab.2 Recognition rates of each feature selection algorithm

图5 错误分类样本Fig.5 Misclassified samples

表4 部分检测样本的BP神经网络输出和期望输出Tab.4 BP neural network output and expected output values of part of testing sample
由以上对比试验可得:相较于不加选择的随机方法以及仅进行简单比较的标量特征选择,文中算法所选特征设计的分类器所选取的特征具有更好的可分性,且具有更高的识别率,可以尝试用于更加复杂的实际应用中。
5 结束语
围绕基于机器视觉的轴承表面缺陷分类特征的选择做了以下工作:1)总结了特征选择的完整流程,为算法应用提供了清晰的思路;2)初步建立了轴承缺陷图像的特征池,为相关领域的特征选择工作提供了便利;3)提出了一种特征选择的综合算法,通过相关性选择、标量特征选择和特征向量选择3次筛选,实现了较好的特征选择,且相对于单独的特征向量选择大大降低了计算量;4)通过对比分析验证了特征选择算法可以选出可分性高的特征及其可操作性。
应当指出,没有绝对的最优特征,只有在一定条件下的最优,因此文中提供的是特征选择的方法,而不是最终分类特征本身,所进行的实例验证目的是验证算法的有效性,而非给出一个普遍适用的分类特征。对于研究者来说,要想得到适合自己研究问题的分类特征,还需要参考文中算法进行相应的改进计算。
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
中国电子科学研究院学报(2019年8期)2019-12-23
计算机与现代化(2018年2期)2018-03-13
电子制作(2017年23期)2017-02-02
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
新高考·高一物理(2015年7期)2015-09-21
