
一种大规模的跨平台同源二进制文件检索方法
2018-07-19 11:59刘中金赵威威石志强孙利民
计算机研究与发展 2018年7期
陈 昱 刘中金 赵威威 马 原 石志强 孙利民
1(物联网信息安全技术北京市重点实验室(中国科学院信息工程研究所) 北京 100093) 2(中国科学院信息工程研究所 北京 100093) 3(中国科学院大学网络空间安全学院 北京 100093) 4(国家计算机网络应急技术处理协调中心 北京 100029) 5 (兰州大学信息科学与工程学院 兰州 730000) (shizhiqiang@iie.ac.cn)
随着物联网的发展,嵌入式系统在人们的日常生活中无处不在.根据Gartner发布的市场报告,到2020年,物联网设备的数量将达到208亿[1].与此同时,物联网设备也遭遇了越来越多的网络攻击,给国家安全以及人民生命财产安全带来了巨大威胁.例如2017年10月出现的物联网恶意软件“IoT_reaper”[2]利用9个固件漏洞进行代码植入与传播,目前已感染的物联网设备超过200万台,并且每天以新增1万台的速度在网络空间迅速蔓延.
最近的网络安全事件表明:来自于同一厂商甚至不同厂商的多种物联网设备经常被相同的恶意软件感染,造成这种现象的主要原因为近年来物联网厂商越来越多地使用开源共享代码.正是由于物联网设备固件中存在广泛的代码重用,当某个固件被爆出漏洞二进制文件时,包含该同源二进制文件的其他固件也将处于高风险中.例如被物联网蠕虫SHELLBIND所利用的SambaCry漏洞(CVE-2017-7494)影响了物联网设备长达7年之久,直到2017年5月才被安全研究人员发现.因此当安全事件发生时,知道哪些厂商、哪些设备的固件中包含有Samba组件对于物联网安全应急响应意义重大.
目前,同源代码分析在代码反侵权[3-5],二进制搜索[6-8]以及恶意软件家族鉴定[9-11]等领域已经有了较为深入的研究.但是缺少面向嵌入式设备固件的大规模同源二进制文件检索方法的研究.存在的挑战有3个方面:1)物联网固件在编译时拥有比传统软件更多的编译配置选项,例如不同指令集架构、不同的编译器等,导致相同的源代码在不同的编译配置下可能编译生成非常不同的二进制代码;2)动态分析物联网固件是很困难的,因为很难模拟外围硬件的反馈;3)当在一个固件中发现漏洞二进制文件,需要及时通知相关厂商发布相关的安全补丁.然而,目前市场上有着数以百万计的物联网固件,传统方法[12]的时间复杂度是O(N),在一台双核计算机上完成该任务可能需要数日甚至数周的时间.
本文设计和实现了一种时间复杂度为O(lgN)的面向物联网设备固件的同源二进制文件检索方法.该方法的核心思想是通过深度学习网络编码二进制文件中的可读字符串,然后对编码向量生成局部敏感Hash从而实现快速检索.方法共包括3个步骤:1)我们从二进制文件中提取所有的可读字符串;2)采用基于双层双向Bi-GRU[13]的深度学习网络模型将过滤后的字符串编码成固定长度的编码向量;3)采用局部敏感Hash(local sensitive Hash, LSH)方法构建索引,提高检索速度.
我们按照16种不同的编译参数编译了893个开源组件,共生成71 129对带标签的二进制文件来训练和测试网络模型.结果表明该方法的ROC特性远好于传统方法.此外,实际应用案例表明该方法只需不到1 s的时间即可完成一次针对22 594个固件的同源二进制文件检索任务.
本文的主要贡献有3个方面:
1) 设计、实现和评估了一个时间复杂度为O(lgN)的大规模同源二进制文件检索方法.实验结果表明,该方法不仅比传统方法快了3个数量级,而且结果更加准确.
2) 在实际应用案例中对52个厂商共22 594个固件进行了同源漏洞组件安全评估,并公布了分析结果.
3) 本文编译的数据集是第1个具有标签的同源二进制文件数据集,我们承诺在论文收录后将其公开,供其他研究人员研究使用.
1 基本思想和方法概述
物联网组件的源代码中通常包含有大量的可读字符串,例如调试字符串、标语字符串、错误信息字符串、日志消息字符串等,如表1所示:

Table 1 Examples of Strings in Binary
根据大量的实验观察,这些可读字符串拥有“编译不变性”,即在不同的编译配置下编译而生成的多个同源二进制文件中,可读字符串的内容和顺序基本保持一致.本文正是利用可读的字符串的这种“编译不变性”来实现同源二进制文件的检索.即若2个二进制文件的可读字符串内容和顺序基本一致,则它们有很大可能是同源的.该思想虽然简单,但在将其转化为高效的实用方法前,还需要解决2个主要问题:
1) 如何提取更多的字符串?鉴于物联网设备的国际化和全球化市场,在二进制文件中使用Unicode字符串是较普遍的现象.但是,目前的字符串提取工具(如Linux中的strings命令)只能从二进制代码中提取ASCII格式的字符串.此外,在局部变量中定义和存储的字符串,其字符通常存在于压栈指令的操作数中,传统方法同样无法提取这种类型的字符串.
2) 如何将可读字符串序列编码成特征向量?该问题是实现本文方法所面临的最大的挑战.因为编码出的特征向量需要能够用于局部敏感Hash(LSH)[14]构造反向索引库,只有这样才能实现时间复杂度仅为O(lgN)的文件检索.
本文提出的同源二进制文件检索框架如图1所示,包括3个阶段:1)字符串提取与过滤;2)字符串编码;3)LSH相似度Hash索引.
在字符串提取与过滤阶段,提取每个输入二进制文件中的可读字符串并进行过滤.有关字符串提取和过滤方法的详细介绍参见2.1节.
在字符串编码阶段,利用训练好的双层双向Bi-GRU模型对字符串序列进行编码,生成拥有LSH函数族[15]的距离测度编码.本文采用的是余弦距离测度,并将采用其他距离测度的研究放在未来工作中.有关双层双向Bi-GRU模型的详细介绍参见2.2节.
在LSH相似度Hash索引阶段,使用面向余弦距离的LSH函数族计算出每个特征向量的相似度Hash,最后以给定的同源性阈值为参数对相似度Hash构造倒排索引数据库.构建LSH相似度Hash索引的详细介绍参见2.3节.
上述3个阶段中,阶段2为本文的主要贡献,通过该模块编码的二进制文件特征向量可以用于LSH Hash构造反向索引库从而可实现时间复杂度仅为O(lgN)的文件检索.
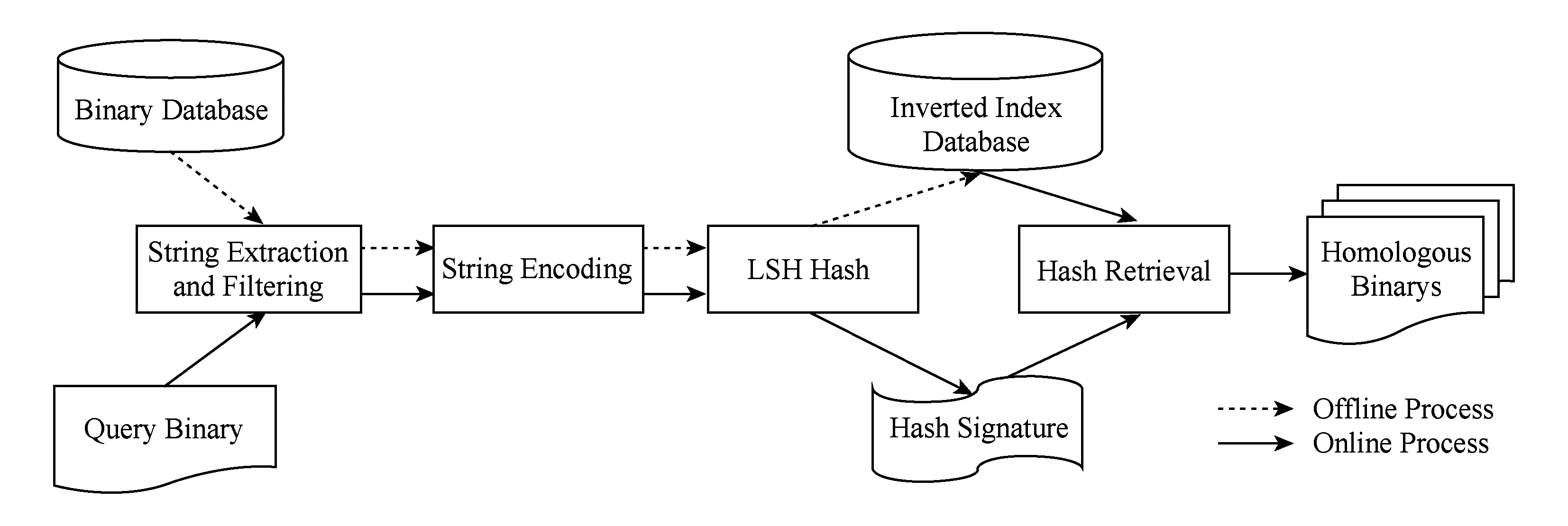
Fig. 1 Homologous binary file retrieval framework图1 同源二进制文件检索框架
该框架在应用时存在2个数据处理过程:1)离线索引过程;2)在线检索过程.图1虚线箭头连接的是离线过程,实线箭头连接的是在线过程.
在离线索引过程中,离线对二进制文件库中的所有二进制文件进行编码并生成LSH相似度Hash,最后对所有的相似度Hash进行倒排索引,构建倒排索引库.
在线检索过程中,只需先对待查二进制文件生成相似度Hash,然后将其在倒排索引库中做一次查询即可得到二进制文件库中所有与其同源的二进制文件.
2 详细设计
2.1 字符串提取与过滤
如果一个字符串至少由n个连续的可读字符组成,并且以NULL或换行符结尾,则该字符串被视为可读字符串.在本文中,我们根据经验将n设置为6.为了过滤来自于指令的可读无序字符串, 在使用strings工具时通过不指定‘-a’选项将提取范围限制为数据段.物联网设备固件中的二进制文件存在3种类型的可读字符串:数据段中的ASCII格式字符串、数据段中的Unicode格式字符串、代码段中的ASCII格式的字符串.介绍3种字符串的提取方法:
1) 数据段中的ASCII格式字符串.我们使用Linux下的字符串提取工具strings来提取数据段中的ASCII格式字符串.同时采用strings的‘-d’选项来限制只提取数据段中存在的字符串,并使用‘bytes’选项来指定只能提取包含多于6个可读字符的字符串.
2) 代码段中的ASCII格式字符串.正如本节之前所讨论的,当代码段被定义并存储在局部变量中时,可读字符串也可能存在于代码段中.在这种情况下,可读字符串被分成几个连续指令的操作数中存在的字符.首先我们识别连续入栈指令;然后从这些连续指令中提取指令操作数,构造栈帧字节流;最后判断栈帧字节流中是否有连续可读的ASCII格式字符,若有则将它们拼接成可读字符串.
3) 数据段中的Unicode字符串.与ASCII格式的字符串不同,数据段中的Unicode格式字符串不能通过判断它们是否包含连续的可打印字符来识别,因为大多数双字节单元都可以用相同或不同语系的Unicode编码打印.但是,在同一固件中语系通常是一致的.因此,我们可以通过判断是否包含连续一致语系编码的字节单元来识别Unicode格式的字符串.
通过上述字符串提取过程,我们得到了二进制文件中的可读字符串序列.但是上述字符串中包含了与SDK或指令集平台相关的字符串以及库函数符号表字符串,前者降低了同源检索的准确率,而后者则增加了同源检索的误报率.我们通过将上述2种字符串添加入黑名单,并用该黑名单对字符串序列中的字符串进行过滤.黑名单的生成过程步骤描述如下:1)使用 buildroot工具交叉编译千余种常用的嵌入式开源组件源码包到ARM,MIPS,PowerPC等平台;2)提取不同平台但同源的二进制代码中的可读字符串,并对每个字符串计算其信息增益:
IG(s)=[P(s,Ci)lgP(s,Ci)+
(1-P(s,Ci))lg(1-P(s,Ci))],
其中,Ci是目标平台,P(Ci) 是Ci的二进制文件与全部二进制文件的比率,P(s)是包含s的二进制文件与全部二进制文件的比率,P(s,Ci)是Ci中包含s的二进制文件与全部二进制文件的比率.若某字符串的增益大于预定的的阈值μ,则将其纳入到黑名单中.除此之外,位于内核级和系统级库(如lib,usrlib目录下的库文件)的符号字符串也被加入到黑名单中.
2.2 基于双层双向Bi-GRU模型的字符串序列编码
传统基于最小Hash的字符串编码方法由于缺失了字符串序列的顺序信息,会导致准确率下降.由于Bi-GRU模型能够学习到时序输入数据中的上下文信息,因此为了将字符串序列顺序信息编码进特征向量,本文提出了一种基于双层双向Bi-GRU模型的字符串序列编码方法.
本节首先给出二进制文件编码问题的形式化定义,然后介绍本文所提出的深度学习模型的结构与训练方法.
2.2.1 编码问题定义
用b1,b2表示2个二进制文件,用π表示同源性计算算子,π(b1,b2)=1表示b1和b2同源,π(b1,b2)=-1表示b1和b2不同源.给定数据集T{(〈b1,b2〉,π(b1,b2))|b1和b2由多编译参数交叉编译得到,通过人工标记π(b1,b2)的取值}其中,多编译参数交叉编译是指按照不同编译器,不同编译优化选项等编译参数将同一份源码交叉编译成不同指令集架构的二进制文件,其中人工标记π(b1,b2)的原则为:当b1和b2为同一份源码编译得到的则π(b1,b2)=1,否则π(b1,b2)=-1.然后按照一定比例将数据集T划分为训练集Train Set、评估集Validation Set和测试集Test Set.
我们的目标是设计一个基于深度学习的编码模型ζ将二进制文件b编码成特征向量v,即ζ(b)→v,同时保证2个v之间可以用简单的余弦距离Cosine来度量它们所表示的二进制文件之间的同源性.模型ζ的参数P在Train Set中进行训练,训练的目标是:
模型ζ的超参数调整在Validation Set中进行,模型ζ的效果评估在Test Set中进行.
2.2.2 模型结构与训练方法
本节将详细介绍2.2.1节中定义的字符串编码模型.模型的输入为代表二进制文件的字符串序列,模型的输出为编码向量.如图2所示,模型主要由词嵌入网络(embedding layer)[16]、双层双向循环神经网络(Bi-GRU layer)和全连接编码网络(encoding layer)三部分构成.采用词嵌入网络的目的是尽可能保留字符串的语义信息;采用双层双向循环神经网络的目的是从2个方向提取字符串序列的上下文信息;采用全连接编码网络的目的是将特征向量编码成特定长度的编码向量.
词嵌入网络采用了文献[17]中的模型并使用二进制文件中提取出的字符串序列作为预料进行预训练.字符串序列在经过词嵌入网络后被编码成512×TS的中间张量,其中TS为输入字符串序列的长度.
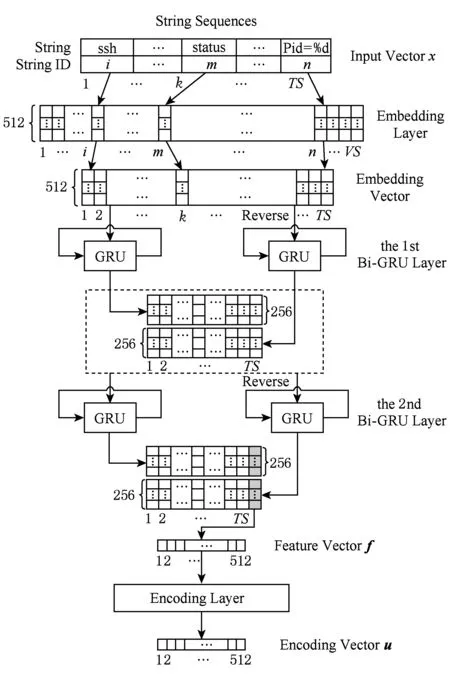
Fig. 2 Two layer Bi-GRU encoding model图2 双层双向Bi-GRU编码模型
双层双向循环神经网络由2层Bi-GRU网络构成.如图2所示,词向量序列在经过第1层左边的Bi-GRU模块后生成了256×TS的临时张量;接着将词向量反序后输入第1层右边的Bi-GRU模块生成另一个256×TS的临时张量;然后将上述2个临时张量合并,生成512×TS的中间张量.采用完全一致的过程将上述中间张量送入第2层Bi-GRU网络进行处理,将结果张量中的最后一列抽取出来得到512维的特征向量.
全连接编码网络负责将512维的特征向量映射为编码长度为p的编码向量,关于p取值的影响见3.4节中的讨论.本文中采用简单的单层全连接网络作为编码网络的实现.
然而如2.2.1节所述,图2所示的模型并不能单独训练,需要根据如图3所示的Siamese架构将2个共享参数的编码模型结合在一起训练,从而保证编码结果可以用简单的余弦距离Cosine来度量它们所表示的二进制文件之间的同源性.
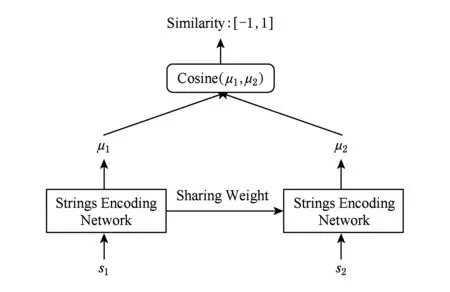
Fig. 3 Siamese architecture图3 Siamese架构
2.3 LSH相似度Hash索引
给定一个待查询的二进制文件和一个二进制文件库,在线搜索的任务是从二进制文件库中检索出所有与待查二进制文件同源性大于某给定阈值的二进制文件.直接计算2个二进制文件特征向量之间的余弦距离便可度量这2个文件的同源性.但这种“一对一”的匹配方法,因其时间复杂度为O(n),不适用于第4节提出的大规模同源二进制文件检索的应用场景.本文借鉴了信息检索领域中基于Hash的近似最近邻搜索的思想,利用LSH技术将时间复杂度降低至O(lgN).由于上述方法不是本文的主要贡献,所以在本节剩下的内容中仅对该方法的主要流程做一个大致的介绍.首先对二进制文件库中的每个二进制文件用训练好的深度学习模型编码成特征向量,然后使用事先构造好的面向余弦距离的LSH函数族计算出每个特征向量的相似度Hash,最后以给定的同源性阈值为参数对相似度Hash构造倒排索引数据库.需要注意的是上述这些步骤均可以离线完成,无需消耗在线搜索时间.当收到在线搜索任务后,首先对待查询的二进制文件采用与离线时相同的方法生成相似度Hash,然后在倒排索引数据库中对相似度Hash进行时间复杂度仅为O(lgN)的检索,最终得到库中所有满足阈值条件的同源二进制文件.
3 实验评估
在本节中,首先介绍数据集的构建方法,然后将本文方法与具有代表性的基于模糊Hash的方法sdhash进行性能和时间开销的对比,最后将展示作为本文方法核心的编码模型的训练细节.
3.1 数据集
由2.2.1节问题定义可知,训练模型需要人工标记大量的同源性计算算子π作用到二进制文件对后的取值.人工标记的原则为:当2个文件是由同一份源码编译生成的,π取值+1,否则π取值-1.参与编译的源码共涉及893个从开源社区收集得到的开源组件,包含声音、压缩与解压、加密、数据库、文件系统、图形、硬件处理、javascript、JSONXML、日志、多媒体、网络、安全、文字与终端处理等类别,涵盖嵌入式设备中常见的组件,如openssl,binutils,libmad,boa,web,server,sudo,openssh,ntp,nginx,tcpdump,libgd,libxml2等.编译参数包括不同的平台(ARM,MIPS,PowerPC,X86,X64)、不同的编译器(gcc,clang,icc)以及不同的编译优化级别(-O0,-O1,-O2,-O3,-Os).数据集中包含的二进制文件概况如表2所示:
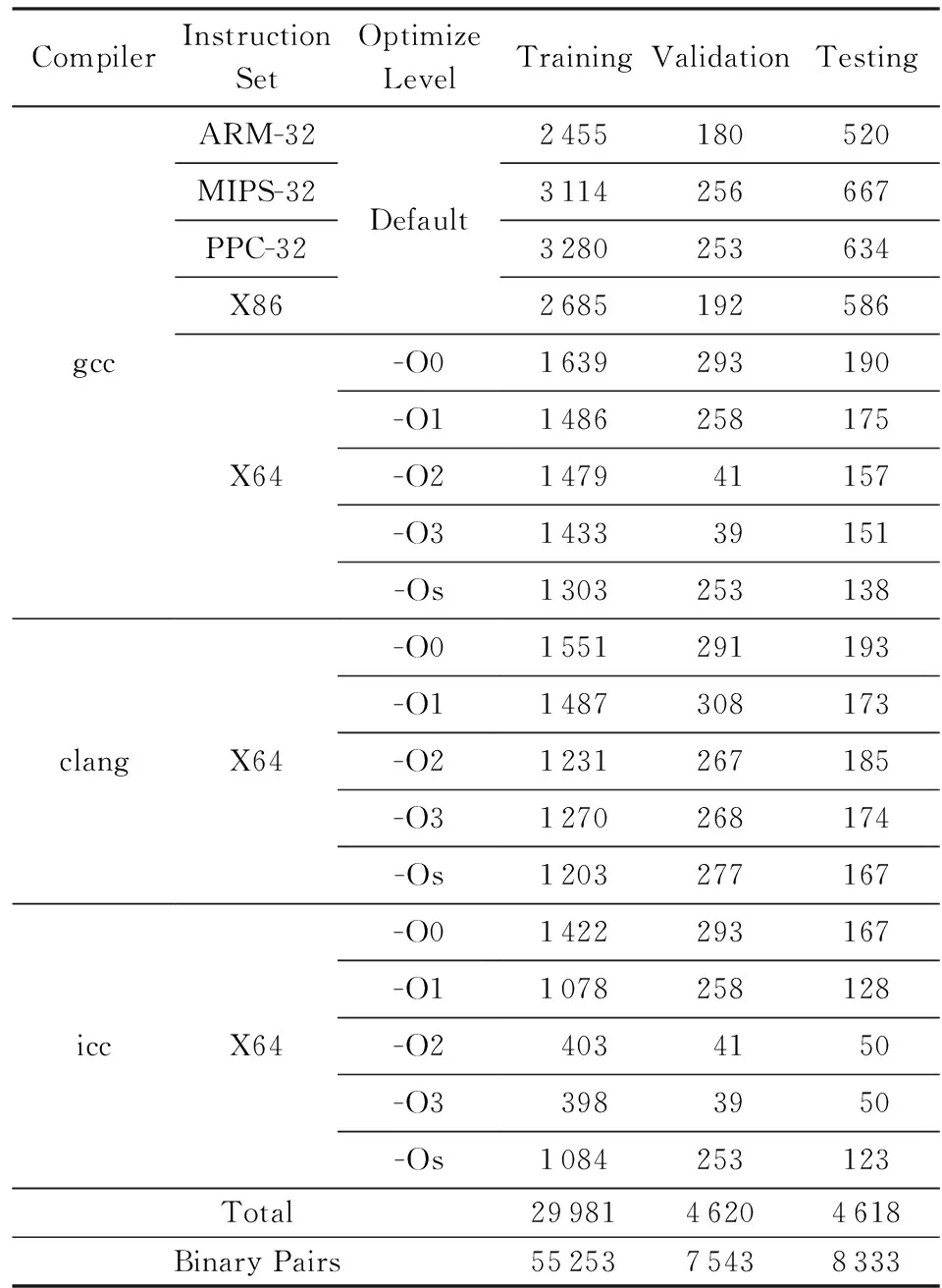
Table 2 Dataset Overview
训练集共29 981个二进制文件,验证集共4 620个二进制文件,测试集共4 618个二进制文件.值得注意的是,在划分文件到上述3个文件集的过程中,我们确保3个文件集是没有“交集”的,即编译自同一份源码的多个二进制文件不允许同时存在于2个不同的文件集中,这样可以检验模型对训练集中没有遇到过的二进制文件的编码能力.最后按照π取值为+1与-1的文件对数量比例大致相等的原则对上述二进制文件进行配对处理,共生成55 253个文件对用于训练模型,共生成7 543个文件对用于在每个Epoch后对模型的编码性能进行验证,共生成8 333个文件对用于测试训练和调参等步骤完成后模型最终能达到的编码性能.
3.2 性能评估
本文方法与sdhash方法在测试集中的ROC曲线性能对比如图4所示:
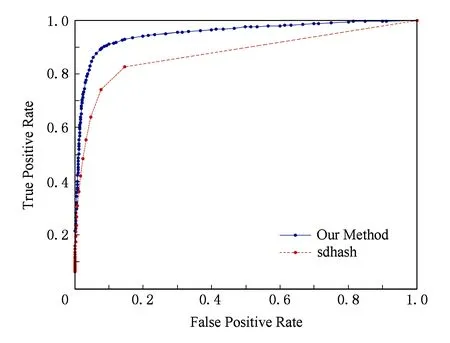
Fig. 4 ROC curves for our method and sdhash method图4 ROC曲线性能对比
由图4可知,本文方法比sdhash方法的ROC性能更好.例如当假阳率为0.05时,本文方法的真阳率为0.85而sdhash只有0.67;当假阳率为0.1时,本文方法的真阳率达到了0.91而sdhash只有0.78.除此之外,从图4中描点的密度分布可知,本文方法在真阳率较高的阶段点密度显著高于sdhash,说明本文方法对阈值的选择更具有鲁棒性,因此稳定性更好.
3.3 时间开销
从本质上讲,本文方法与sdhash方法均为基于签名的方法.即需要先计算签名然后再进行签名的检索.在实际应用中,签名计算是可以离线进行的,而签名的检索必须在线进行.因此在线检索速度比离线签名速度重要的多.2种方法的时间开销对比如表3所示.本文方法平均每个二进制的离线签名时间约为sdhash的一半,更重要的是在对百万量级二进制文件库进行检索时本文方法的速度比sdhash快了3个数量级.
Table3ComparisonofOfflineSignaturesandOnlineSearch
TimeCosts

表3 离线签名和在线检索时间开销对比 s
3.4 训练细节
我们将模型训练50个epoch,并在每个epoch结束后打印损失函数的数值,同时在验证集中对AUC值进行评估.损失函数变化趋势和AUC变化趋势分别如图5和图6所示:
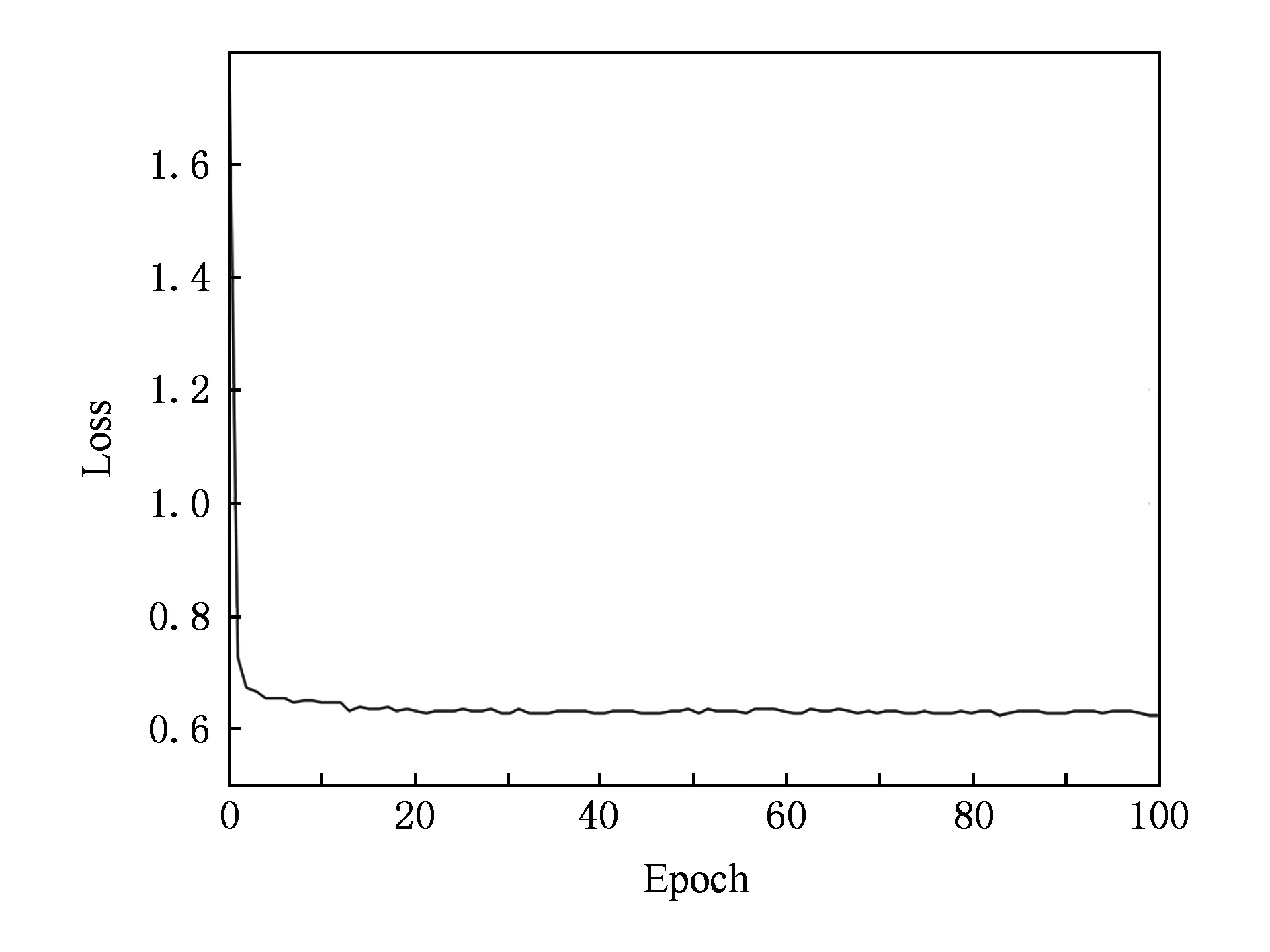
Fig. 5 Loss versus number of epochs图5 损失函数变化趋势

Fig. 6 AUC versus number of epochs图6 AUC变化趋势
从图5中可以看出,经过10个左右的epoch训练后,损失函数下降到一个较低的水平,然后几乎保持不变.从图6中可以看出AUC也有类似的趋势,在10个左右的epoch训练后稳定在一个较高的数值上.因此,我们得出这样的结论:模型可以快速训练,只需要10个左右的epoch,即30 min的离线训练可达到很高的编码性能.
为了考察编码长度p对编码性能的影响,我们将编码长度分别取16,32,64和128时模型的ROC性能曲线放在一起进行对比,如图7所示:

Fig. 7 The effect of encoding length on ROC performance图7 编码长度对ROC性能的影响
由图7可知,编码长度越长,模型的编码性能越好,但是随着编码长度的增加,存储和计算的开销也在增加,然而不同编码长度之间的性能差距也越来越接近.综合考虑后,本文选择64作为模型的编码长度.
4 应用案例
为了验证本文方法的实用性,我们对14 种物联网设备中常用组件(libgcrypt,libssh,msmtp,nginx,ntp,openssh,openssl,rsync,stunnel,subversion,sudo,tcpdump, wget,samba)进行了大规模同源分析实验,这些组件的某些版本曾经都爆出过安全漏洞.实验所使用的二进制文件库由从52个厂商共22 594个固件解压出的1 637 797个二进制文件构成.这些厂商的固件均是通过网络爬虫从各厂商的固件发布网页中爬取得到.在构建完离线索引库后,完成一次同源二进制文件检索的时间只需要不到1 s.通过小样本的人工分析与验证,本文方法在该应用场景下的误报率率低于20%,漏报率低于10%.由于篇幅所限,我们只展示其中4个典型组件openssl,samba,nginx,ntp的同源分析结果.它们曾经爆出过的CVE漏洞如表4所示.分析结果如图8所示.

ComponentCVE VulnerabilityopensslCVE-2017-3731 CVE-2017-3730 CVE-2014-0160 CVE-2016-6309 CVE-2016-6308 CVE-2016-6304sambaCVE-2017-7494 CVE-2015-0240 CVE-2013-4496 CVE-2012-1182nginxCVE-2017-7529 CVE-2016-1247 CVE-2016-4450 CVE-2016-0747ntpCVE-2015-5146 CVE-2015-3405 CVE-2015-7691 CVE-2015-7701
可见openssl和samba影响范围较广,这说明心脏出血和SambaCry漏洞对物联网设备安全构成了巨大的威胁.
5 相关工作
文献[18]提出了一种模糊Hash算法ssdeep,该算法基于上下文触发的滚动Hash实现了自动对齐和模糊匹配功能;文献[19]设计了另一种模糊Hash算法sdhash,该算法基于熵估计来挑选出区分度最高的特征;文献[20]验证了现有的模糊Hash算法在恶意软件家族分类等安全应用中的有效性;文献[21]使用ssdeep在CERT Artifact Catalog数据库中对一千多万个文件进行了聚类实验.
近年来,越来越多的机器学习方法被用来解决二进制分析领域的问题,以下列出一些比较有代表性的工作.本文作者在文献[22]中提出了一种固件漏洞函数关联方法,该方法基于BP神经网络提取函数跨平台特征,因而不依赖特定的指令集,可以跨平台进行固件漏洞关联;文献[23]将循环神经网络RNN应用于函数边界识别;文献[24]利用3层RNN网络对函数参数的个数以及数据类型进行了识别;文献[25]提出了使用ACFG表示函数,并使用无监督学习模型将ACFG转换为数值向量,最后使用LSH技术完成对漏洞函数的快速检索;文献[26]在文献[25]的基础上使用与本文类似的图嵌入网络对ACFG进行编码从而提升了检索性能.本文方法受到了以上研究工作,特别是文献[25]和文献[26]的启发,但在2个方面存在显著不同:1)编码对象不同,本文是将二进制文件编码成Hash向量,而文献[25]和文献[26]编码的是函数; 2)数据集的原创性,本文第1次将多达893个开源组件按照16种不同的编译参数进行编译,总共生成了带标签的71 129个二进制文件对用于训练和测试模型.
在大规模嵌入式固件安全分析领域,文献[12]首次对3万多固件样本进行了关联分析,但由于他们所采用的是基于模糊Hash[18-19]的二进制文件关联方法,需要进行一对一的文件相似度关联的计算,因而不适用于大规模的文件检索应用.而本文方法由于借助了局部敏感Hash技术进行加速,从而可以将检索的时间复杂度由O(n)降低至O(lgN).
6 结束语
本文设计和实现了一种时间复杂度为O(lgN)的面向物联网设备固件的同源二进制文件检索方法.该方法的核心思想是通过深度学习网络编码二进制文件中的可读字符串,然后对编码向量生成局部敏感Hash从而实现快速检索.
本文按照16种不同的编译参数编译了893个开源组件,共生成71 129对带标签的二进制文件来训练和测试编码模型.实验结果表明:基于本文方法的同源二进制文件检索性能好于传统方法.此外,应用案例表明本文方法只需不到1 s的时间即可完成一次针对22 594个固件的同源二进制文件检索任务.
本文方法的不足之处为对于包含字符串较少的或者做过字符串混淆处理的二进制文件的检索能力较差,拟在未来工作中研究基于非字符串特征的提取与编码方法,并与更多的同源二进制检索方法进行性能对比.
猜你喜欢
电脑报(2022年4期)2022-02-07
中等数学(2021年8期)2021-11-22
软件导刊(2021年10期)2021-10-28
无线互联科技(2020年11期)2020-12-01
中学生数理化·七年级数学人教版(2020年4期)2020-08-10
数学大王·低年级(2019年10期)2019-11-25
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
中国信息技术教育(2015年21期)2015-09-10
中国信息化周报(2015年14期)2015-06-01
