
CREBAD:基于芯片辐射的物联网设备异常检测方案
2018-07-19 11:54倪明涛吴福生樊佩茹
计算机研究与发展 2018年7期
倪明涛 赵 波 吴福生 樊佩茹
1(武汉大学国家网络安全学院 武汉 430072) 2(空天信息安全与可信计算教育部重点实验室(武汉大学) 武汉 430072) 3 (乐山师范学院计算机科学学院 四川乐山 614000) (nmt@whu.edu.cn)
物联网(Internet of things, IoT)概念由国际电信联盟于2005年11月在消息世界峰会上正式提出.随着传感网、云计算、微芯片等技术不断的发展,物联网产业也迅速发展壮大[1].专家估计,到2020年,物联网设备的数量会达到300亿台[2],物联网的全球市场规模将会达到7.1万亿美元[3].
随着物联网逐步应用到各个领域,物联网设备端的安全问题日益凸显.物联网是物理设备彼此连接的网络,这些物理设备由各种微处理芯片和片上系统(system on chip, SoC)组成.与传统的计算机相比,物联网设备具有功耗低、尺寸小、资源受限等特点,这些特性使得物联网设备更加难以编程和交互,也导致了物联网设备在安全上的先天不足.如何对物联网设备进行保护,使其免受各种攻击和侵害,成为当前物联网安全的一个关键问题.
尽管物联网设备品种繁多,硬件架构千差万别,但其程序、控制结构等与传统计算机系统相似.因此,为了对物联网设备进行保护,研究者借用传统计算机系统的的入侵检测方法,提出了相应的解决方案.文献[4]通过对不同安全区域的流量特征进行提取,在不需要解析具体协议的情况下,发现物联网设备中的异常流量;文献[5]从物联网设备的通讯协议入手,采用成熟的协议格式和状态分析技术,对报文中协议状态的变化进行监测,达到对异常行为检测的目的;文献[6]通过在物联网设备底层中加入系统软件,对运行于设备中的程序进行监控,对软件的正常和异常行为进行刻画,判断程序状态转移的趋势,监控操作序列等方法检测异常行为.但是,这些传统的基于入侵检测的安全机制在应用于物联网设备时存在局限性,主要问题有3个方面:
1) 针对物联网设备的攻击手段越来越高明,采用缓慢渗透的入侵攻击流量稀少[7],传统的基于流量特征的异常检测机制在物联网场景下难以从稀疏的样本中提取有效的流量特征,从而导致检测失效;
2) 由于物联网设备的专有性,很多通信协议采用私有或加密的方式,针对报文协议的分析在此种场景中则无能为力;
3) 物联网设备的资源有限,运行的系统千差万别,甚至不少程序运行于无操作系统的“裸”设备上,且对实时性的要求较高,这些特性导致很难在这些设备中部署杀毒软件或监控软件.
针对上述问题,本文提出了一种基于芯片辐射的物联网设备异常检测方案(chip radio emission based anomaly detection, CREBAD),主要贡献有3个方面:
1) 提出了一种基于芯片辐射能量序列检测方法,通过分析给定时间窗口的辐射能量序列,判断其是否为异常行为,无需在物联网设备中额外部署检测软件,不依赖于对网络流量的分析;
2) 提出了一种无侵入式的检测方式,基于芯片在工作时辐射能量的物理特征,具有普适性,不依赖于硬件架构,也不受限于操作系统,且物联网设备对检测过程不可预知、不可篡改、不可抵赖;
3) 利用一类支持向量机(one-class SVM, OCSVM)对异常值敏感的特性,能够在只有一类正常训练数据集的前提下,对无法预测的异常行为序列进行有效检测.
1 相关工作
常见的物联网设备异常检测方案,从检测层次来划分,可分为网络层、软件层和物理硬件层.
在网络层,文献[8]提出了一种使用异常方法的僵尸网络检测方案.作者认为,僵尸网络会导致6LoWPAN传感器节点流量的意外变化.所提出的解决方案计算3个度量的平均值以组成正常行为配置文件:TCP控制字段、数据包长度和每个传感器的连接数之和.然后,系统会监视网络流量,并在任何节点的度量标准违反计算的平均值时发出警报.文献[9]介绍了一种物联网分布式内部异常检测系统,其原理是通过监视单跳邻居节点的特性(如分组大小和数据速率)来查找网络中的任何差异;文献[10]介绍了一种入侵检测系统,旨在检测物联网设备中的虫洞攻击.作者假设,蠕虫攻击总是在系统中出现症状,例如隧道两端交换大量的控制报文,或者攻击成功后形成大量的邻居.使用这个逻辑,作者提出了3种算法来检测网络中的这种异常情况.根据他们的实验,该系统在虫洞检测方面达到了94%的正确率,在检测到攻击者和攻击方面达到了87%.尽管这些系统都达到了较好的效果,但它们都依赖于特定的场合和假设,缺乏通用性.
在软件层,有研究者从体系结构、配置文件、规则制定等角度提出了解决方案.如文献[11]提出了一个无线异常检测的架构.该架构应用计算智能算法来构建网络设备的正常行为配置文件.对于分配给设备的每个不同的IP地址,都会有一个不同的正常行为配置文件.但这种架构不适合部署在低端物联网设备中.Summerville等人[12]开发了一种旨在在资源受限的物联网设备上运行的深度包异常检测软件.作者认为,小型IoT设备使用少量且相对简单的协议,导致网络负载高度相似.基于这个想法,他们使用一种称为比特模式匹配的技术来执行特征选择.网络有效载荷被视为一个字节序列,特征选择是对重叠的字节元组进行操作.最终利用这些字节序列进行模式匹配,从而检测出系统的网络异常行为.
在软件层面,还有基于“规范”的检测方法,规范是定义预期的一组规则和阈值.当物联网设备行为偏离规范定义时,基于预先设定的规范,就能检测到异常.如Le等人[13]提出了一种基于规范的方法,重点是检测针对低功耗和有损网络路由协议(routing protocol for low-power and lossy network, RPL)的攻击.他们在有限状态机中指定了RPL行为,用于监视网络并检测恶意行为.作者使用仿真跟踪文件为RPL协议生成有限状态机.这个配置文件被转换成一套应用于从网络节点检查监控数据的规则.根据他们的实验,准确率在某些情况下可以达到100%,但不可回避的是,该方案让原系统增加了6.3%的能量开销.Misra等人[14]提出了一种防止IoT中间件从分布式拒绝服务(distributed denial of service, DDoS)攻击的方法.为了检测攻击,指定每个中间件层的最大容量.当对图层的请求数量超过指定的阈值时,系统会生成警报.Amaral等人[15]提出了另一个基于规范的异常检测系统,允许网络管理员创建攻击检测规则.当违反这些规则时,检测系统向事件管理系统(event management system, EMS)发送警报.EMS运行在没有资源约束的节点上,以关联网络中不同节点的警报.这些方法在很大程度上取决于网络管理员的专业知识,这是基于规范的方法的一个特点.错误的规则可能导致过多的误报和漏报,对网络安全构成更大的风险.
软件方式的异常检测具有很大的灵活性,能够随着系统的变化做出适应性的修改.但软件方式面临一些无法回避的问题:物联网设备往往是无人值守的,攻击者攻破设备后,第1步就是关闭这些监测软件,从而导致所有后续的异常检测失效.更重要的是,很多物联网设备对实时性要求很高,部署检测系统会降低实时性,这种软件的检测方式在很多场合是无法满足需求的.
在硬件检测层面上,Lee等人[16]假设能耗是分析节点行为的一个参数.他们定义了网状路由方案和路由节点方案的常规能耗模型,然后,每个节点以0.5 s的采样率监测其能量消耗.当能耗偏离期望值时,检测系统将该节点分类为恶意节点,并将其从路由表中删除.作者声称这是一个轻量级的方法,专门为低端物联网设备设计.但是,仅仅基于能耗阈值的偏离就对系统的行为认定为异常,具有很大的误判性,不具有说服力.Xiao等人[17]提出了一种基于功率的可编程逻辑控制器(programmable logic controllers, PLC)异常检测方案.其基本思想是通过分析其功耗来检测PLC中的恶意软件执行情况,作者通过在PLC电源回路中串联一个分流电阻来实现功率的测量.为了分析功率变化,作者从功率迹中提取一个判别特征集,然后训练一个具有正常样本特征的长短期记忆(long short-term memory, LSTM)神经网络来预测正常样本的下一个时间步长.最后,通过比较预测样本和实际样本来识别异常样本.该方案理论上适合任何物联网系统,但依赖于分流电阻的能耗测量,需要对电源部分做适当的修改,在很多低功耗物联网设备上难以有效地对电流进行监测.同时加入的分流电阻也会增加系统的能量开销.
本文提出的CREBAD也是基于硬件层的检测方案,但与前面提及的系统不同的是,本方案不需要对系统进行任何的修改,测量的是芯片工作时对外辐射的无线电波,任何现代芯片在工作时都会向外辐射电磁波信号,具有普遍性.
2 威胁模型与假设
为了达到入侵物联网设备的目的,我们假设攻击者有3种能力:
1) 攻击者可以通过网络入侵到受害设备,并对系统的固件或软件进行非法修改;
2) 攻击者修改代码的目的之一是为了对系统进行破坏,因此系统原有的软件防护措施会被对手关闭甚至移除;
3) 攻击者侵入物联网设备后,会运行修改后的程序,用以达到对机密数据进行窃取和伪造,对连接的外设进行非法控制和破坏的目的.
由于物联网设备的硬件特性,与传统计算机系统相比,运行的软件相对简单,行为模式也较为固定.因此,我们认为:运行于物联网设备中的“正常”软件的行为是可预期的,其样本是可以获取和训练的;运行于物联网设备中的“异常”软件的行为是不可预期的,其样本是无法预先获取的.同时,由于物联网设备被对手非法修改,系统的行为会发生改变,这些软件行为的改变,必然会引发芯片辐射能量的相应变化.并且,芯片辐射属于物理特性,对手无法对这种特性进行篡改,更无法消除异常行为导致的辐射变化.
3 CREBAD异常检测方案
CREBAD基于芯片工作时向外辐射的能量特征,利用一类支持向量机算法,构建异常检测方案.该方案在数据采集阶段利用时间窗口对辐射能量建立时间序列,然后利用遗传算法和近似熵理论对序列特征进行提取和构造,最后通过降维的方式选择关键特征.在模型的训练与检测阶段,利用一类支持向量机对异常值(奇异性)敏感的特点,识别出异常行为.
在本节中,我们将先介绍基于芯片辐射异常检测的可行性,然后给出整体构建方案,最后给出特征提取、选择和样本训练、检测的理论基础.
3.1 方案可行性
CREBAD的核心思想是通过侧信道的方法来采集芯片内部的工作状态.通常,侧信道方法往往用于攻击场合,如Li等人[18]的研究工作表明,在广泛使用的视频监控设备中,存在着侧信道信息的泄露,即使视频流被加密,也可以通过视频差分编码中的时间冗余来探测信息.利用这种侧信道信息的泄露,攻击者可以仅通过对加密视频流的流量大小进行测量,从而推断用户的日常生活行为.受到该思想的启发,我们利用物联网设备在工作时,其主芯片会向外辐射电磁波信号这一物理特性(侧信道信息),并利用这种物理侧信道信息对目标设备中的异常行为进行检测.其主要原理是:当物联网设备在工作时,所有的程序指令都会在主芯片的CPU中执行,不同的任务或程序执行会引起CPU负载的变化,从而导致芯片向外辐射的信号也会发生相应的改变.为了验证这种想法,我们在一款基于Atheros 9331芯片的工业数据采集器上进行了简单的实验.设备中分别运行3个不同的任务,任务1在1 s之内采集下位机的各种运行状态,并将数据上传到服务器,暂停一秒钟后继续开始下次采集和上传;任务2与任务1类似,只是暂停时间延长,变成了4 s;任务3进行密集运算,实时统计系统所有运行数据,并将数据压缩打包,每次持续时间大概为4 s,暂停时间约为1 s.从图1中可以看出,每个程序在执行时,芯片向外辐射的频谱信号都不相同.初步研究结果为我们进行更大规模、更细致的研究奠定了基础.

Fig. 1 Spectrum signals corresponding to different tasks图1 不同任务对应的频谱信号
3.2 整体方案构建
CREBAD的整体检测框架如图2所示,包括数据获取、数据预处理、特征提取与选择和训练与预测模块.
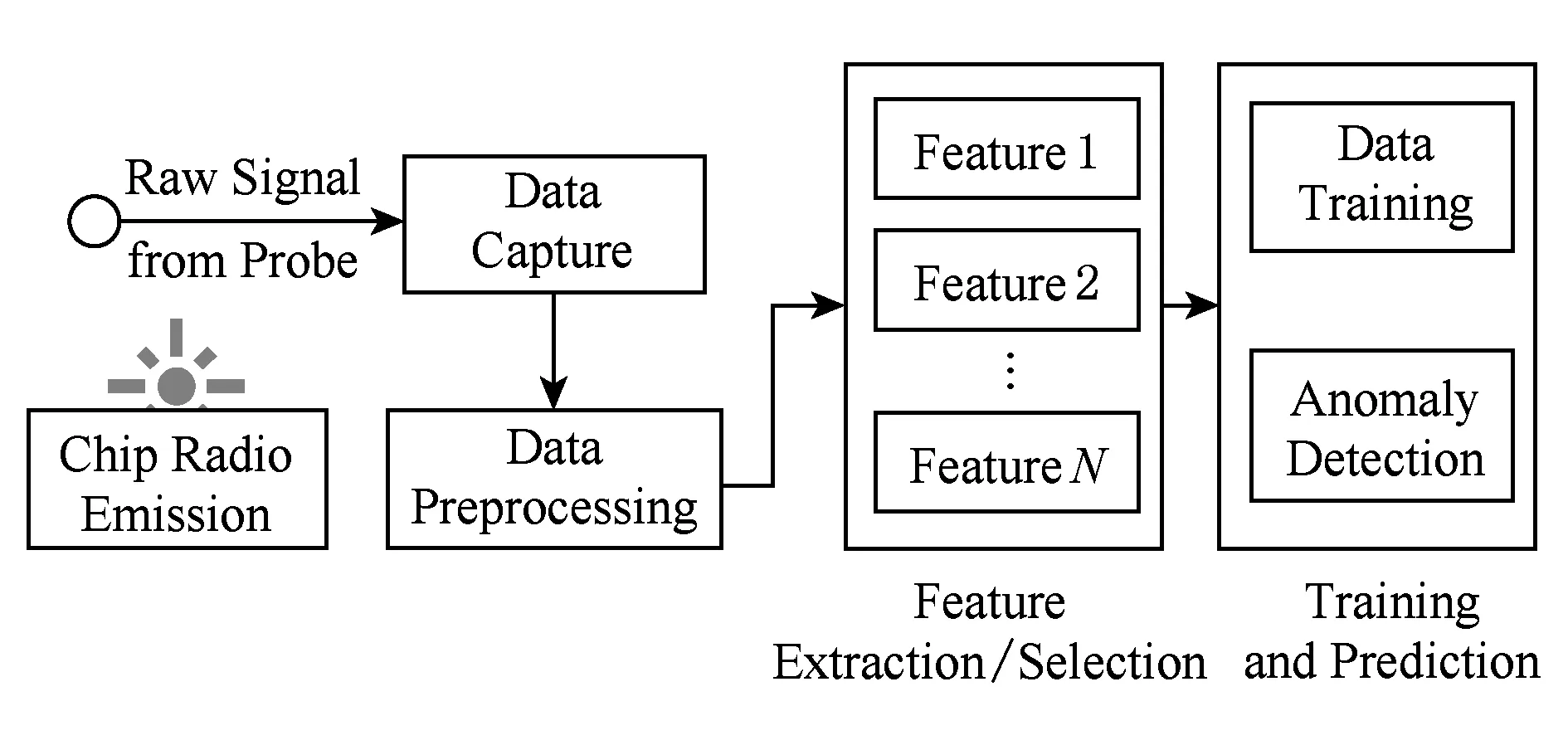
Fig. 2 CREBAD framework图2 CREBAD整体框架图
部署在主芯片附近的近场探头负责收集其工作时的电磁辐射,这种装置是完全无侵入式的,对原有设备不会造成任何影响.采集到的原始信号通过数字示波器进行信号放大和模数转换,转变成时域信号.在数据预处理阶段,我们对时域信号进行相关处理,包括对信号进行平滑处理、消除噪声等.随后,我们对时域信号进行快速傅立叶变换得到频域信号,分别从时域和频域中提取各种特征.芯片辐射的信号特征频谱非常丰富,数据维度高,为了实现更好地分类和降低训练复杂度,我们使用遗传算法对特征进行降维.由于没有异常样本,只能用正样本进行训练来预测异常样本.我们选择一类支持向量机来进行异常检测.
3.3 特征提取与选择
为了有效区分正常信号和异常信号,我们必须构建正确的特征集,包括原始特征提取和特征选择.本文将捕获到的时域信号按照5 s的窗口大小进行分段,称为一个样本.由于每一个样本含有丰富的信号特征,无法直接用于特征训练,因此,对原始信号进行特征提取和选择操作变得尤为重要.本文首先利用遗传算法对频域特征进行了有效的提取和降维,然后利用近似熵理论提取了表征异常信号的熵值,最后和其他5个关键特征一起构建成最终的特征样本集用于后续的训练与预测工作.
在转换后的频谱信号中,存在大量的无关和冗余特征,这些特征会严重降低学习模型的准确性,导致学习速度下降.如果直接将这些高维特征用于训练,将会造成计算上的“维度灾难”.当数据集中包含的特征数量巨大时,特征子集选择是缓解这种问题的有效方法.遗传算法(genetic algorithm, GA)由于在求解组合问题中的优异特性,使其成为一种日益流行的特征子集选择工具.遗传算法是受自然选择和遗传规律启发的自适应启发式搜索算法,于20世纪70年代初由文献[19]提出.传统的基于梯度的优化算法通过迭代改进单个解决方案,以此在多维优化表面中搜索最佳点,但该算法在初始猜测时可能陷入局部最优而导致结果失真.遗传算法比传统算法更有可能定位全局最优点,这对于高维度空间的特征搜索是非常有效的.
遗传算法从个体的初始种群开始,每个个体代表一个给定优化问题的可能解决方案,并且在连续的迭代中向一组更优或适合的个体演化.个体由固定长度的连续或不连续的字符串(通常是位串)组成,类似于DNA中的染色体.进化过程由3个基本操作控制:选择、交叉和变异.选择过程模仿了自然界适者生存.根据对问题解决方案的优劣,为总体中的每个个体或染色体分配适应度值(基于适应度函数).基于适应度分数,遗传算法从当前种群中挑选出一些父母的最佳个体,并允许他们将基因遗传给下一代.交叉算法用以让2个父母交换基因,形成称为子代的新个体.一部分新的个体是通过变异来创造的,这涉及到父母基因的随机修饰,并有助于维持种群的多样性.
在信号处理中,频域是描述信号频率特征的坐标系统,通常用于分析信号特征,频谱图反映了信号的频率和幅度之间的关系.图3显示了快速傅立叶变换(FFT)之后的4个信号A,B,C和D的频谱图.从图3中可以看出,当频率处于某一特定区域时,每个等级都会出现显著的变化,如虚线框(红色)中的振幅.但是,也有部分的振幅很难区分,如位于中部点画线(绿色)区域.遗传算法的全局最优特性,使其适合在频谱中搜索一组适合分类的特征.
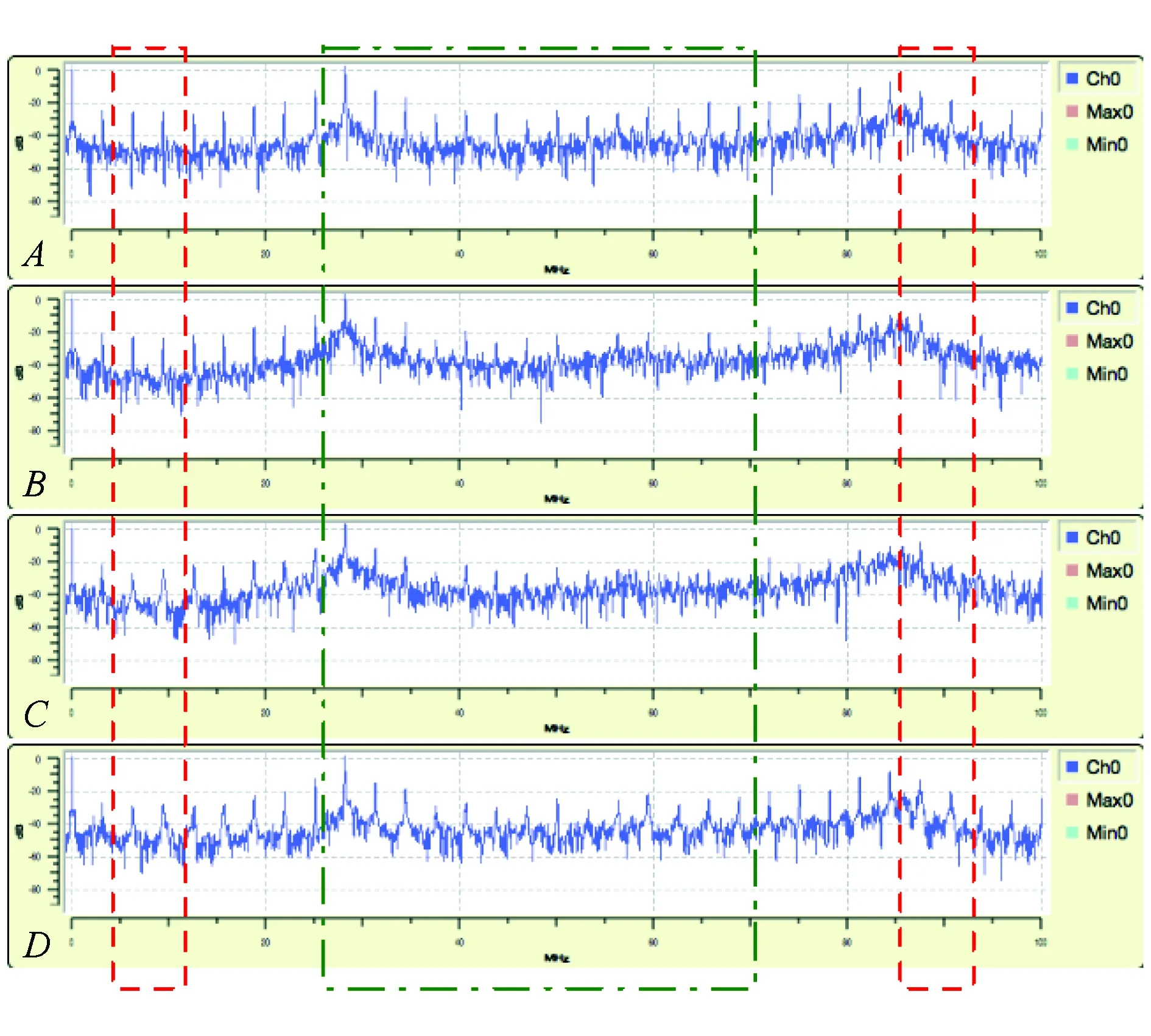
Fig. 3 Feature extraction based on the frequency domain图3 基于频域的特征提取
本文的主要目标之一是要在频谱空间中获取多个有显著辨识能力的频域特征.我们借鉴了文献[20]提出的特征选择算法,描述如下:
算法1. 关键频率特征提取算法.
输入:对时间序列X应用快速傅立叶变换后获得长度为m的序列Y;
输出:关键频率特征集合.
①InitPopulatoinSet(Y);
② while criterion not satisfied
③calcFitnessVal();
④ while crossover not complete
⑤selFilterStrings();
⑥doCrossover();
⑦doMutation();
⑧LocalSearchOperation();
⑨ end while
⑩doReplacement();
步骤1.InitPopulationSet()初始化具有f个特征的集合F、k个突出特征的子集K以及p个字符串的总体集合P.每个字符串的长度 |p| 等于原始特征f的数量.然后通过基因值1和0对群体的字符串进行编码.每个字符串中所需数量的特征k由子集大小决定.
步骤3.calcFitnessVal()使用前馈神经网络(feed-forward NN)训练模型计算P中每个字符串p的适应度值.通过组合特定串的相关性信息以及NN的分类精度百分比来确定每个串p即子集的适应度.
步骤6.doCrossover()依次对每个字符串p执行标准交叉操作.使用预定义的交叉概率进行标准的基于等级的选择过程,然后选择可能的过滤器串.
步骤7.doMutation() 对新生成的后代进行标准变异操作.每个字符串的每一位都遵循预定义的变异概率.
步骤8.LocalSearchOperation()对所有新产生的后代依次进行局部搜索操作,以重新调整1 b的数量.通过一般和特殊的特征可以修复和改进子集的质量.然后检查交叉操作的进度,以确定是否完成了所有可能的选定字符串组合.如果未完成,则转至步骤4.
步骤10.doReplacement()将P中最低排列的字符串替换为整个生成的后续字符.
在该算法中,本地搜索操作(local search opera-tion, LSO)将给定数据集的特殊和一般特征提供给新生成的后代,这是整个算法的关键.为了在算法中实施LSO,我们分别用特征分组、后代分割和后代改进3个步骤来实现.第1步只需要执行一次,最后一步由2个主要的操作符Add和Del完成.Add操作符为所生成的后代插入所需数量的特征,Del运算符从生成的后代中移除所需数量的现有特征.详细说明如下:
1) 特征分组.分组的目标是为了找出特征之间的关系,以便该算法可以将不同的信息特征分布到新生成的后代中.算法使用皮尔逊积矩相关系数来衡量一个给定的训练集的不同特征之间的相关性.2个频率i和j之间的相关系数ci j为
(1)
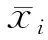
(2)
此后,算法根据其相关值按升序排列所有特征.为了创建2组特征,算法尝试将原始特征集合等分成2组:不相似组D和相似组S,2组中的第1个特征是其中最明显的特征,最后一个特征是其中最相似的特征.
2) 后代分割.这一步涉及到分割新生成的后代.该算法将1 b的数目与新产生的后代进行区分,并以特征数量的形式放入子组X中.然后将X的每个元素与D和S的元素进行比较.再次尝试分割X为Xd和Xs,并根据其相关值按升序重新排列Xd和Xs的所有特征.
3) 后代改进.比较Xd和Xs的当前长度,Add操作符在每个添加步骤中使用D或S组向Xd或Xs添加一个不同的特征,而Del操作符只删除与Xd或Xs相似的特征,而不考虑每个删除步骤中的D或S组.Add运算符会根据不同数量的不同顺序依次使用2个组的特征.最后,Xd和Xs中可用的特征在特定子代中由二进制数字1编码而其余基因被赋值为0,以获得最终改良的后代.通过不断迭代,最终得到能够显著标识时间序列的关键频域特征.
由于异常样本的不确定性,提取关键频域的特征还不足以有效地区分异常行为.因此,本研究还提取了近似熵(approximate entropy,ApEn)作为另外一个重要的特征维度.
近似熵用来衡量时间序列的规律性或复杂度[21].它被定义为对数似然性,即在下一次递增比较中,相互靠近的特定长度的模式的运行将保持接近.与高度不规则或随机的时间序列相比,确定性时间序列预计具有更小的ApEn值,这意味着其模式具有更高的被相似测量值跟随的概率.另一方面,对于随机时间序列,随着时间的推移,模式不太可能保持彼此接近.
为了计算时间序列yi(i=1,2,…,N)的ApEn值,首先必须使用时间延迟方法构造嵌入空间中的状态向量Rm:
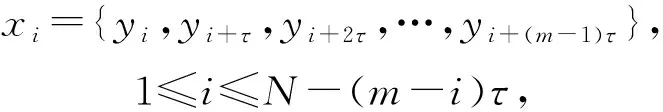
(3)
其中,m和τ分别是嵌入维数和时间延迟.2个状态向量之间的距离可以定义为它们相应元素的最大差异:
d(x(i),x(j))=
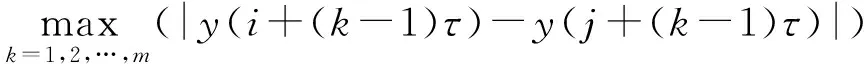
(4)
然后,状态向量和所有剩余的向量之间的相似度被计算为
(5)
其中,θ(x)是标准的Heavyside函数,当x>0时,θ(x)=1,否则θ(x)=0;r是矢量比较距离.最后,我们定义Φm(r)为
(6)
对于固定的m,r和τ,ApEn可以计算为
ApEn(m,r,τ,N)=Φm(r)-Φm+1(r).
(7)
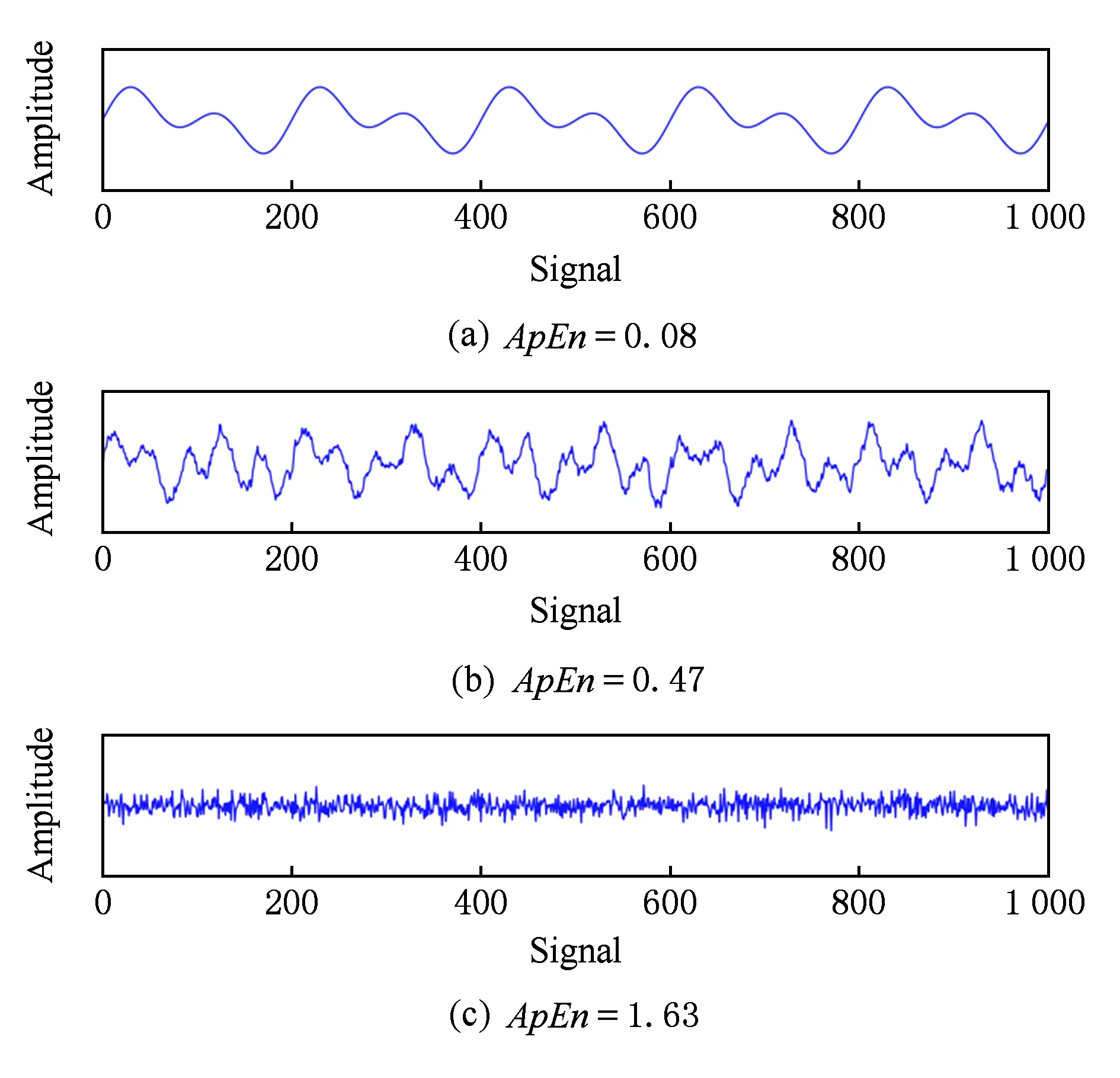
Fig. 4 Approximate entropy of different signals图4 不同信号的近似熵
图4显示了3个测试信号,每个信号由1 000个样本组成.第1个信号是2个正弦波叠加在一起构成的;第2个信号是某一个异常行为序列期间采集获取的;第3个信号是一个正态分布的随机噪声序列.得到的近似熵分别为0.08,0.47和1.63.正如预期的那样,第1个信号的近似熵最低且最接近于零,因为它由2个确定的正弦波信号叠加而成,而正态分布噪声的近似熵是最大的.用近似熵作为衡量可预测性的指标,这意味着第1个信号比第3个信号更容易预测,这是显而易见的.第2个信号是半确定性的,虽然比第1个信号更难预测,但比第3个信号更可预测.作为第2个测试,我们采用相同的测试信号并随机化序列中样本的顺序.这样的变化对香农熵的计算没有任何影响,但由此产生的近似熵分别变为1.51,1.58和1.65,这表明由于样本的随机化,前2个信号的可预测性已经完全丢失.因此,近似熵能够比较准确地度量时间序列的复杂度,适合作为本研究的一个重要的样本特征.
有了以上特征后,如果能结合一些经典的度量特征,将会进一步提升训练的准确性.因此,本文又对原始的信号进行离散小波变换,分解成几个子信号,每个子信号代表不同频段的原始信号.然后,针对每个子信号计算5个用于信号分析的经典度量值.这些是从时间、统计和信息论中选出来揭示最重要的信号特征.S是长度为n的时间序列样本,Si是第i个样本.
信号幅度的均值μ:
(8)
信号的标准偏差:
(9)
信号的平均瞬时能量:
(10)
信号的曲线长度(样本之间垂直线段的长度之和,它提供了时间和频率特征的度量).
(11)
信号的偏度(衡量数据分布的不对称性)
(12)
最后,本研究结合前面遗传算法提取的关键频域特征和近似熵ApEn,与均值μ、标准差σ、平均瞬时能量ε、曲线长度λ、偏度ζ一起作为特征训练数据集.
3.4 样本训练与检测
一类支持向量机是一种流行的异常(离群点)检测算法,广泛应用在文档分类、机器故障检测等场合.受到一般SVM分类器的启发,Schölkopf等人[22]提出了一类支持向量机OCSVM.它的目的是找到一个超平面,将训练的一类实例与期望空间F的原点分离开来;然后,这个超平面被用来通过确定实例属于哪个类来检测测试实例的异常值.
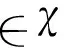
(13)
(w·Φ(xi))≥ρ-ξi,ξi≥0,i=1,2,…,l,
其中,w是与超平面正交的矢量;ξ=[ξ1,ξ2,…,ξl]是松弛变量的向量,用于惩罚被拒绝的实例;ρ表示边界(超平面与原点的距离).
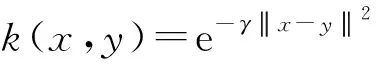
(14)
测试实例z在f(z)为正时被接受,当f(z)为负时被拒绝.接受表示测试实例z被认为与训练数据集相似;拒绝表示它离开训练数据(离群),被认为是异常值.
在一类支持向量机模型中,有一些参数影响训练数据集的决策边界(decision boundary).如高斯核的多项式内核的程度和宽度参数控制所得到的决策边界的灵活性.当使用高斯核函数时,如果参数γ的宽度较小,则SVM模型失去非线性幂,且决策边界趋于平滑;如果γ很大,那么SVM模型的决策边界往往对训练数据非常敏感,缺乏正则化.因此,确定考虑分类性能的适当参数非常重要,本文将在后续实验中对该参数进行讨论.
4 实验与评估
4.1 实验设计
图5为本文的实验场景,由工业采集器JC9331、近场探头、虚拟示波器和台式机组成.近场探头放置在被测物联网设备主芯片上方,用以采集芯片在工作时向外辐射的电磁波.采集到的模拟信号通过屏蔽线传送到虚拟示波器,然后通过虚拟示波器进行模数转换,将采集到的时间序列信号发送到台式机.最后,台式机负责对信号进行变换、滤波、特征提取和训练预测.

Fig. 5 Experiment platform of CREBAD图5 CREBAD实验场景
4.2 评估指标
本文从4个基本值构建了4个度量指标来评估CREBAD方案.4个基本值分别是:真阳性(true positive,TP)、真阴性(true negative,TN)、误报数(false positive,FP)和漏报数(false negative,FN).度量指标分别是:准确度(Accuracy)、精准度(Precision)、误报率(FalseAlarm)和相关系数(correlation coefficient,Cor).计算为
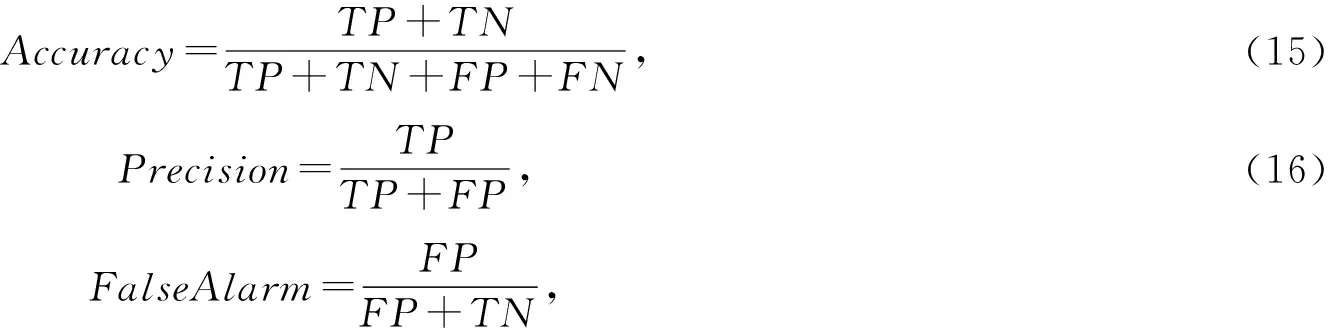
(17)
Cor=(TP×TN-FP×FN)[(TP+FN)×
(TP+FP)×(TN+FP)×(TN+FN)].
(18)
准确度是样本总数中正确标记样本数量的百分比,准确度越高,分类性能越好.该指标反映了分类器对整个样本的判定能力(将正的判定为正,负的判定为负).
相关系数是预测值如何与实际数据相关的度量.其范围从-1~1,其中1的相关系数对应于完美匹配期望值的预测,0的相关系数对应于随机猜测(毫无预测性可言).
4.3 结果分析
在本节中,我们进行3个实验来验证提出的CREBAD检测方案的可行性和高效性.其中,训练样本和正常测试样本来自3.1节中描述的3个任务.对每个任务,我们分别采集了300个样本用于训练,另外300个样本用于测试.异常样本来自一次网络攻击事件,总共采集了200个样本.
实验1是通过改变γ的取值范围,判断其取何值时能够达到最合适的检测率和误报率.使用高斯核的OCSVM模型的决策边界由参数γ控制.图6显示了不同γ值下决策边界的变化.当γ=1时,模型几乎失去了检测异常的能力,因为它将正常数据划分得过于宽泛.随着γ的增加,决策边界逐渐变得紧致.当γ=50时,模型能够检测到所有的未知异常,但由于正常的数据收缩得过于狭窄,导致具有较高的误报率.因此,综合考虑检测率和误报率,将γ的取值设置为10是比较合适的.
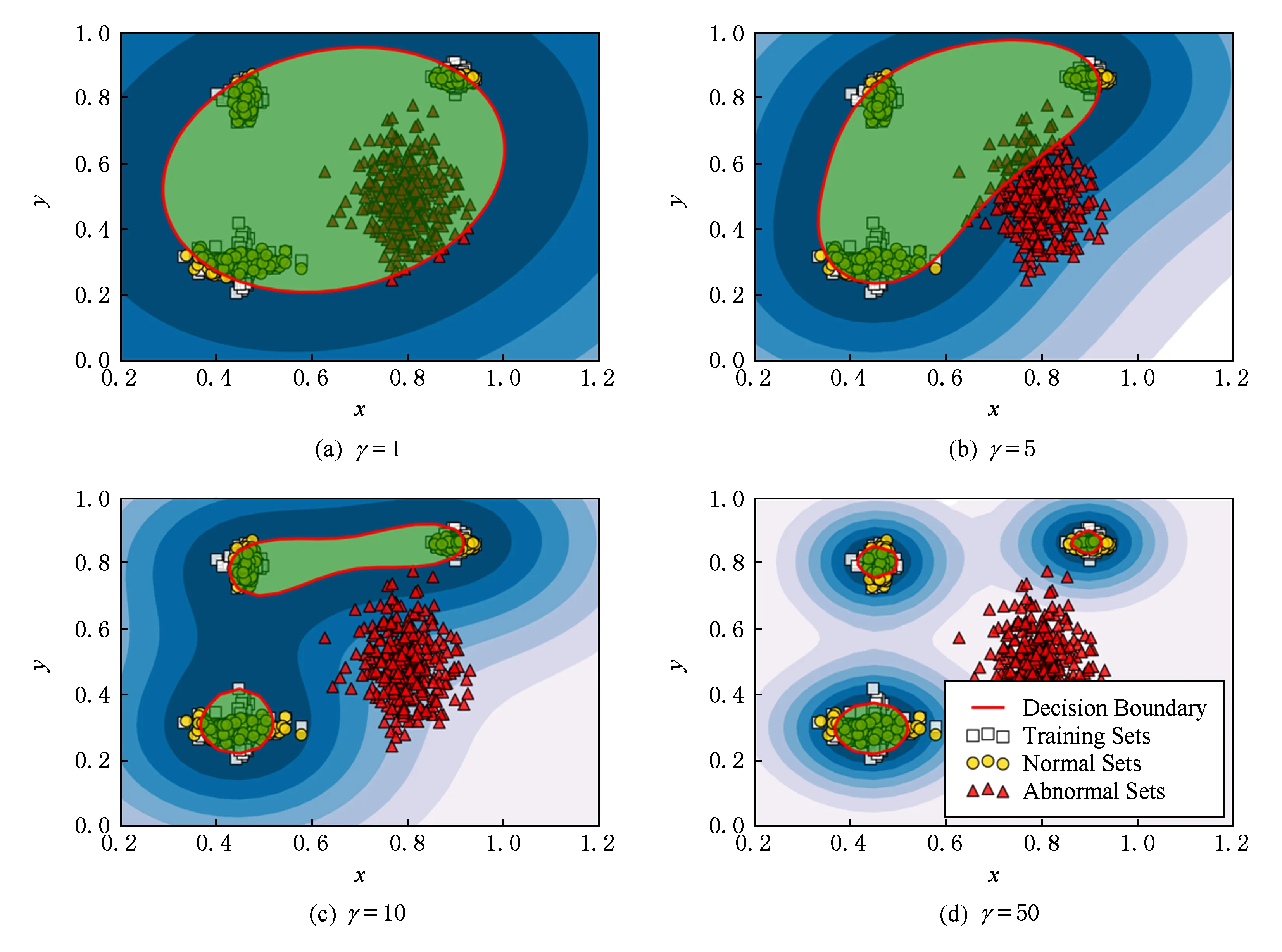
Fig. 6 The impact of γ value on decision boundary图6 γ值对决策边界的影响
实验2是通过与其他常用异常检测算法的对比来判定OCSVM的可行性.本实验选取了随机森林(random forest)和局部异常因子(local outlier frac-tions, LOF)两种常用的异常检测算法,与本文提出的OCSVM算法进行比较,结果如表1所示:
Table1ComparisonBetweenOCSVMandOtherAnomalyDetectionAlgorithms
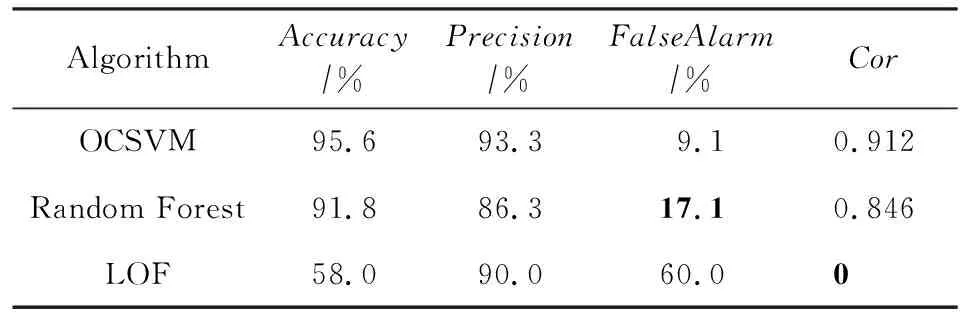
表1 OCSVM与其他异常检测算法的比较结果
通过比较发现,随机森林算法和OCSVM的准确性相当,但是其误报率偏高(17.1%),不适合用在本文的异常检测算法中.同样,LOF的误报率高达60%,且相关系数为0,这表明,LOF算法完全不能用在本文的环境中.
实验3中我们选取了不同的窗口时间tw做对比实验,如表2所示.
从结果可以看出,当tw=1 s时,由于样本数据太少,无法进行有效的检测,随着tw的增加,实验结果逐渐好转,但当tw>5 s后,我们发现,结果并没有出现明显的变化,这说明,随着窗口时间的增加,样本数目随之增长,过多的样本数目虽然能够更加准确的描述样本的特征,但同时也会引入更多的噪声干扰数据,两者相互抵消,除了增加额外的训练时间外,对实验的结果并无实质性的提高.因此,选取5 s的窗口时间是比较合理的.图7给出了准确率和误报率随窗口时间变化的趋势图.
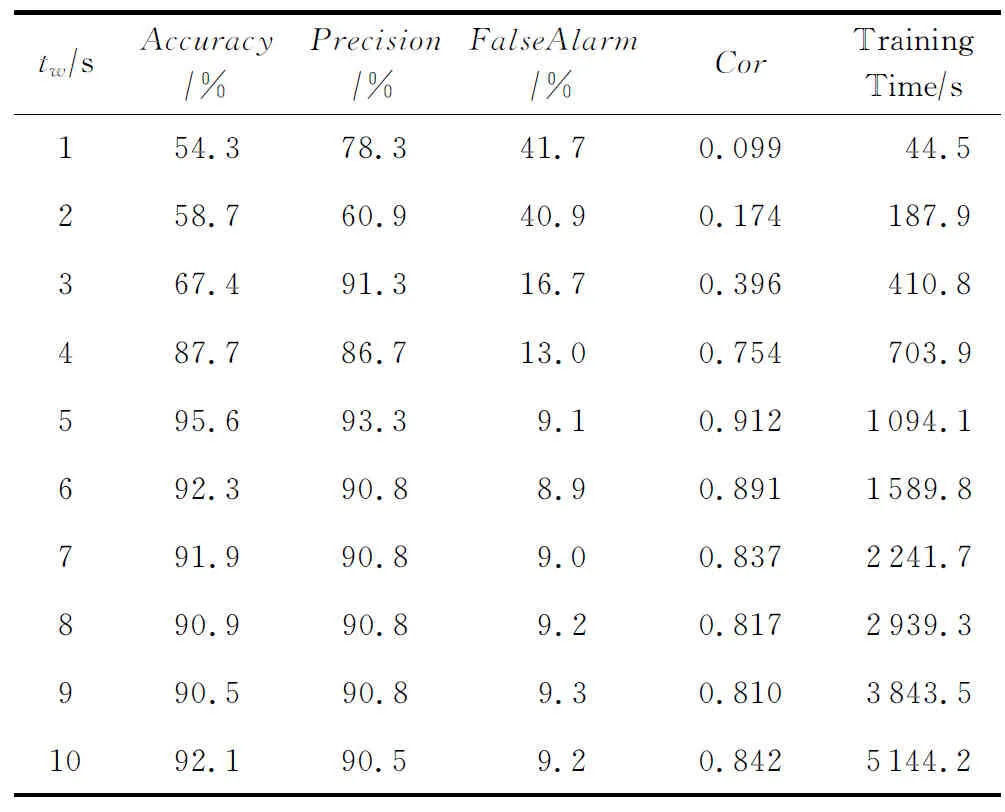
Table 2 Comparison Between Different Window Time表2 不同窗口时间的比较
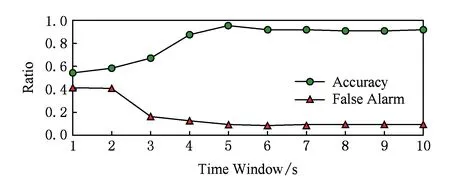
Fig. 7 Window time on the detection results图7 窗口时间对检测结果的影响
5 总 结
针对物联网设备异常检测问题,本文提出了一种基于芯片辐射的异常检测方案CREBAD.方案的新颖之处在于:将原本用于侧信道攻击的芯片辐射信号,转用到异常检测领域.利用芯片辐射信号与工作任务相关的物理特性,构建了CREBAD方案.首先,利用近场探头对芯片辐射信号进行采集,随后,采集到的信号经过相关变换,提炼出频域特征.为了对复杂的频域特征进行降维,本文通过遗传算法、近似熵理论对特征进行了选择和优化.最后,利用一类支持向量机具有对异常值敏感的特性,采用该算法对样本数据进行训练和预测.最后的实验结果表明,与常见的随机森林、LOF等异常检测算法相比,本算法检测精度高误报率低.由于芯片辐射的物理特性普遍存在于各种架构的物联网设备中,因此,本方案具有较好的适应性,适合在设备种类繁多的物联网系统中进行部署和推广.
猜你喜欢
环球时报(2022-09-29)2022-09-29
党的生活(黑龙江)(2022年4期)2022-04-25
现代电子技术(2022年8期)2022-04-13
现代电子技术(2022年4期)2022-02-21
发明与创新(2021年17期)2021-07-05
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
军民两用技术与产品(2021年12期)2021-03-09
电子制作(2019年22期)2020-01-14
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
