
基于统计的蒙汉机器翻译中词对齐方法研究
2018-07-18 02:35:12苏依拉赵亚平牛向华
中文信息学报 2018年6期
苏依拉,赵亚平,牛向华
(内蒙古工业大学 信息工程学院,内蒙古 呼和浩特 010080)
0 引言
蒙古语是内蒙古自治区的地方性官方语言,也是蒙古国的官方语言。随着全球化的发展蒙古语被使用的地方越来越多。从机器翻译被提出以来,大量的人力、物力被投入到相关研究当中,使机器翻译方法由最初的基于规则发展到基于统计的机器翻译系统[1]。统计翻译能够从大量的语料中学习翻译知识,翻译译文质量也有明显提高。近几年,深度学习技术在自然语言处理方面得到了广泛的应用,且机器翻译译文的翻译质量较统计翻译有显著的提升。蒙古语本身词法形态变化相比英、汉等语言语法较丰富且复杂,而汉语和蒙古语又属于不同的语系,故两种语言不论形态还是句法结构都存在着很大的不同。因此蒙汉翻译的难度就更大了。
词对齐是蒙汉机器翻译关键性的数据预处理工作之一。词对齐的好坏对翻译的质量起着至关重要的作用。词对齐(word alignment)概念最早是在20世纪90年代,由IBM Watson研究中心的Peter Brown在统计机器翻译模型中被提出的。当时,统计机器翻译的译文质量远超基于规则的翻译模型的译文质量。所以,词对齐受到许多学者的关注[2]。Brown等人通过引入信息论中的噪声通道原理,把统计机器翻译看成信息传输的过程即目标语言T是噪声信道模型的输入,通过噪声信道编码后,输出相应的序列,这个序列即为源语言S。从词对齐的角度而言,目标语言与源语言之间存在着一对一、一对多以及多对多的对齐关系。为此Brown等人提出了IBM(1-5),该模型是最早提出的统计词对齐模型[3]。1999年Och等人根据Brown提出的IBM词对齐模型实现并开源了第一个基于统计的无监督词对齐工具GIZA[4]。IBM模型虽在词对齐方面取得了一定的成果,但也存在一些弊端。因IBM模型采用生成式训练方式,很难向模型中加入新的特征,故导致模型的可扩展性较差。于是一些学者开始探索基于判别式模型的词对齐研究。判别式词对齐模型通过加入句法信息很好的扩展了基于统计的词对齐模型,中国科学院的刘洋等人针对基于IBM模型3的对数线性判别式词对齐模型进行了相关研究[5]。
蒙古语相关的词对齐研究开始较晚,特别是蒙汉机器翻译研究早期在各方面的投入远远跟不上形势的发展[6]。目前,蒙汉词对齐已经进行了较多的相关研究。内蒙古大学的员华瑞在进行基于串到树的蒙汉机器翻译研究时,也进行了基于对数线性判别式词对齐模型的相关研究[7]。最终实验表明,对数线性判别式词对齐模型能够有效降低蒙汉词对齐中的对齐错误率,有利于译文翻译质量的提高。但因蒙古语属于拼音文字,有着丰富的形态变化且规则复杂,所以在进行蒙汉词对齐模型训练时通常会面临数据稀疏和长距离依赖的问题。针对该问题,本文给出了基于词干词缀粒度的蒙汉词对齐方法,并利用IBM模型3和模型4,通过实验证明了词干词缀的切分能够有效提高蒙汉词对齐模型的对齐质量。
本文还进行了基于对数线性模型的蒙汉词对齐研究,并通过融入词干词缀切分后的IBM模型特征,实验证明词对齐效果明显提升,并且本文对比了基于交集、并集以及采用启发式方法的IBM双向特征融合方式对蒙汉对数线性词对齐模型对齐质量的影响。
本文将在第一节中介绍蒙古语的特点以及词对齐模型,并对IBM模型和对数线性词对齐模型以及启发式IBM模型特征融合方法进行分析和总结;第二节介绍对蒙古语进行词干、词缀的切分以及蒙汉词对齐流程;第三节对实验进行了总结,最终的实验结果证明蒙古语进行词干、词缀的切分对蒙汉词对齐质量是有明显提高的;第四节对本文中所做工作进行了总结和对蒙汉机器翻译未来相关工作进行说明。
1 相关技术背景
1.1 蒙古语特点


首先对汉语句子进行中文分词,可得到汉语词语集合,而蒙古语句子不需要分词,则以空格进行切分。最后,我们将分别得到汉语及蒙古语句子的词汇集合。如下所示:
{<这项,1>,<工作,2>,<完成,3>,<我们,4>,<很长,5>,<时间,6>,<需要,7>,<。,8>}

然后开始词对齐过程。即对两个句子中存在互译关系的词进行连线,最终将得到词语对齐结果,如图1所示。图1中,可以发现蒙古语与汉语句子在进行词对齐时,伴随着很多的位移。
图1中是我们列举的较简单的蒙汉词一对一的对应关系。在较复杂的蒙汉词对齐过程中可能存在一对多、一对空及远距离调序等问题。

图1 蒙—汉词语对齐示例
1.2 词对齐模型
词对齐的具体任务是从双语文本的句对中找出词语的对应翻译关系,这在机器翻译中起到了重要的作用。词对齐的研究方向主要有两种: 一种是生成式模型的词对齐方法,另一种是判别式模型的词对齐方法。
1.2.1IBM统计机器翻译模型
Brown等人建立了五个复杂程度依次递增的词对齐的机器翻译模型,我们习惯上称为IBM模型1-5(IBM Models 1-5)[9]。IBM1只考虑词与词之间互译的概率。IBM 2考虑了词的位置信息,提出了词对齐概率。IBM 3中出现了繁殖数。IBM 4中有短语的翻译,在IBM 3的基础上用一组依赖于对齐位置上的词汇的形变概率参数来描述对齐关系。IBM 3针对词对齐的一对多情况,引入了繁殖概率,如式(1)所示。
(1)
其中,CT,S是常量,直译概率pr(Sj|Ti)是目标语言词汇Ti直接翻译成源语言词Si的概率。繁殖概率pr(l(Sj)|l(Ti))是目标语言Ti中的词语个数L(Ti)繁殖成源语言词Si的个数L(Si)的概率。变换概率pr(i|j,m,l)是目标语言位置j上的词翻译到位置源语言位置i上的概率,其中m和l分别表示与源语言句子以及目标语言句子长度。
1.2.2对数线性词对齐模型
IBM(1-5)模型属于生成式词对齐模型,该模型无法将双语语言学知识应用到模型中,也就不能利用语言学知识来提高词对齐的质量。本文将开展基于对数线性模型的蒙汉词语对齐研究,对数线性模型属于判别式词对齐模型[10]。判别式词对齐模型认为词对齐是在已知的一系列对齐句对(S,T)的条件下,计算一系列对齐关系的条件概率的问题。从而词对齐模型的训练问题可以转化为在给定源语言S以及目标语言T情况下最大化概率P(A|S,T)的问题。对数线性词对齐概率具体计算如式(2)所示。
(2)
其中,hm(a,s,t)是特征函数,m= 1,…,M,该模型最多融入M个特征函数。每个特征函数会存在一个权重参数rm。
1.2.3启发式IBM模型特征融合方法
本论文针对基于对数线性模型得到的蒙汉词对齐结果偏向于一对一的词对齐的问题,决定采用启发式优化思路进行双向IBM模型词对齐结果的融合[11]。IBM模型实现蒙古文到汉语以及汉语到蒙古文双向的词对齐训练后,可提取到每个平行语料句对的词对齐向量。为了方便描述,用C表示汉语到蒙古语的对齐向量集,对齐关系((a,x),(b,y),(c,z)),M表示蒙古语到汉语的对齐向量集,对齐关系((x,a),(y,b),(z,b),(z,d))。CM的交集表示((a,x),(b,y)),CM的并集表示((a,x),(b,y),(z,b),(c,z),(z,d)),则同时出现在CM并集以及CM交集周围的词对齐结果将被加入到融合后的词对齐序列中,对齐关系表示为((a,x),(b,y),(z,b),(c,z)),具体的过程如图2所示。

图2 启发式特征融合方法

1.3 实验评测指标
在词对齐实验中,词对齐模型的主要评价指标有准确率(AR)、召回率(RR)和词对齐错误率(AER)。其中准确率指的是词对齐模型所确定的正确的词语对齐关系与其所确定的全部词汇对齐关系比值。召回率指的是词对齐模型所确定的正确的词对齐关系与测试语料中全部词汇对齐关系的比值[12-14]。具体计算过程如式(3)~式(5)所示。
其中,A表示由词汇对齐模型所确定的词对齐关系,B表示由人工标注的词语对齐双语语料库所确定的词对齐关系。由式(3)可以发现词对齐错误率(AER)能够同时反映出词对齐模型的对齐准确率和召回率。因此,本文在进行词对齐模型性能评价时将主要以对比词对齐模型的词对齐错误率为主。
2 基于词干词缀的蒙汉机器翻译
蒙汉词对齐的目的是从蒙汉双语平行语料中找出蒙古文词汇与汉语词汇之间的对应关系。
2.1 蒙古语词干词缀切分

对蒙古语词汇进行词干词缀的切分[15],目前主要方法有基于词干、词缀词典的切分,基于语法规则和基于统计模型的词干词缀切分。中文分词工具我们选择了中科院的NLPIR汉语分词系统[16]。本文基于先前建立的词干词典、词缀词典和切分规则库利用逆向最大匹配算法进行了蒙古语词汇词干词缀的切分。采用逆向最大匹配算法进行蒙古语词干词缀切分时,该算法不会考虑词干词缀间组合的可能性,只按照词干、词缀的长度在词干词缀词典中寻找相匹配的成分。词干和词缀词典是根据内蒙古自治区的语言学家清格尔泰所写的《现代蒙古语语法》构建[17]。在进行蒙古语句子词干词缀切分时,考虑到蒙古语词需要进行多次切分,本文基于现有的蒙古语双语词典[18],词干词缀词典结合逆向最大匹配算法[19],给出了多层次的蒙古语词干词缀切分流程,具体如图3所示。
2.2 蒙汉词对齐流程
本文首先进行了基于IBM 3和IBM 4的蒙汉词对齐实验。主要目的是观察蒙古语词汇中词干词缀切分对蒙汉词对齐的对齐质量的影响,因此采用的训练语料为未切分和切分的蒙汉平行句对。IBM模型特征指的是通过IBM模型所获取的双语平行句对间的词汇对齐概率,词对齐关系的概率值直接作为对数线性判别式词对齐模型的特征输入值。IBM模型4将对齐句子的长度、词类、单词翻译顺序、互译词的数量等因素全部考虑进来,具有较强的表达能力。本文将分别使用IBM 3和IBM 4所确定的词对齐概率的对数值,作为对数线性词对齐模型的输入特征,并将蒙古语到汉语以及汉语到蒙古语两个对齐方向上的对齐概率作为不同的特征使用。本文在进行蒙汉词对齐研究时,主要流程如图4所示。
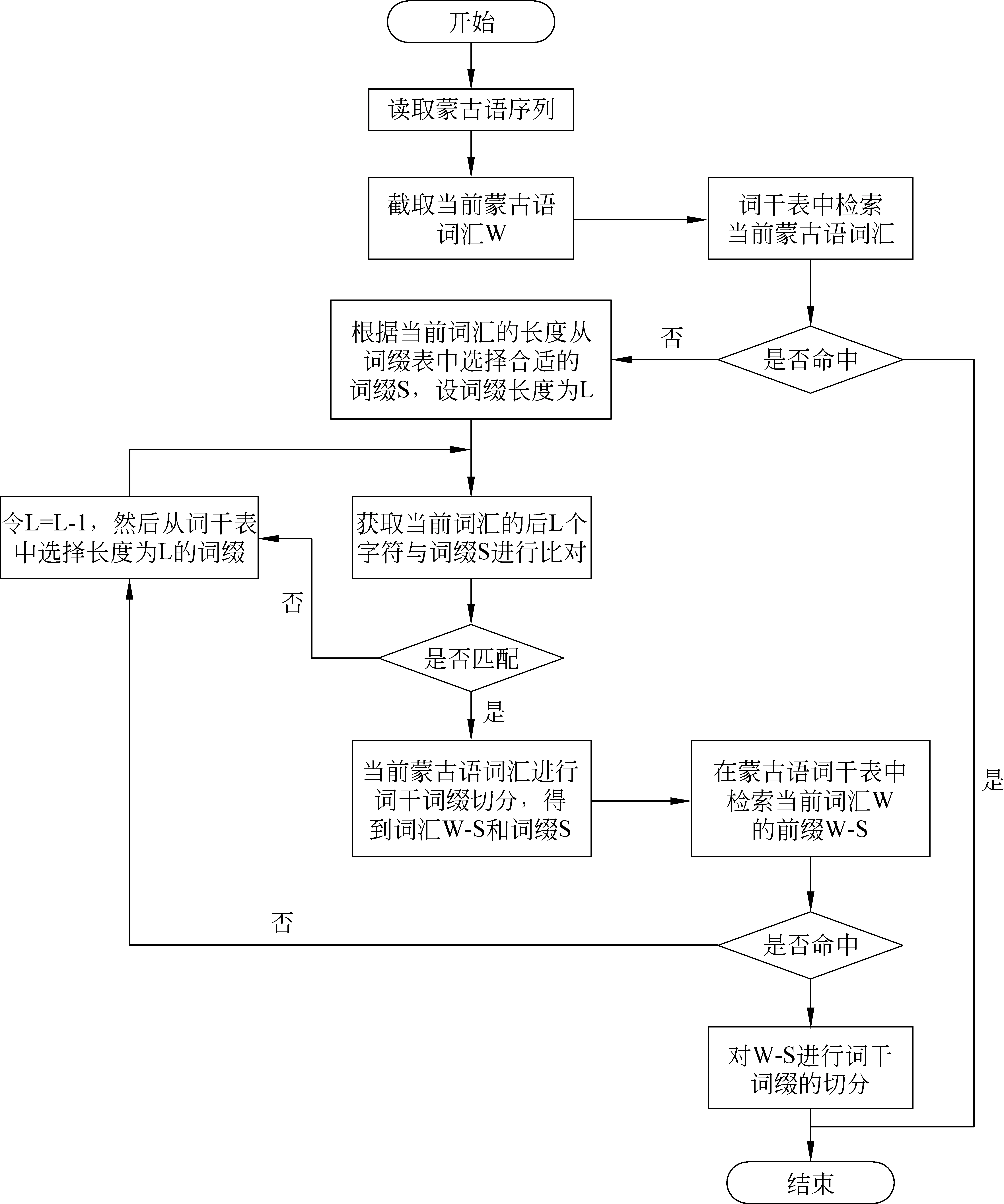
图3 词干词缀切分流程

图4 蒙汉词对齐过程
3 实验
3.1 实验设置


图5 蒙汉词对齐的结果
3.2 实验数据预处理
蒙汉词对齐实验所采用的训练语料是67 288句对的双语平行语料。其中包括了日常使用词汇、部分散文读物、自治区政府相关文献等多方面的文本。在进行蒙汉词对齐实验前,对语料进行了预处理工作,筛选出了句子长度小于30的平行语料句对,得到符合要求的平行句对49 239个,作为蒙汉词对齐实验的语料。为了对IBM词对齐模型进行实验,我们从蒙汉平行句对中随机抽取了100组句对进行了人工词对齐,作为IBM蒙汉词对齐实验的测试语料。我们邀请了对蒙古语熟悉的蒙古族的同学对平行句对进行手工的词对齐工作,最终共得到词对齐有683个。实验相关数据信息如表1所示。在对数线性蒙汉词对齐模型的训练中本文选取了800个蒙汉双语平行句对,将人工对齐的平行句对的70%作为训练语料,余下30%作为测试语料。
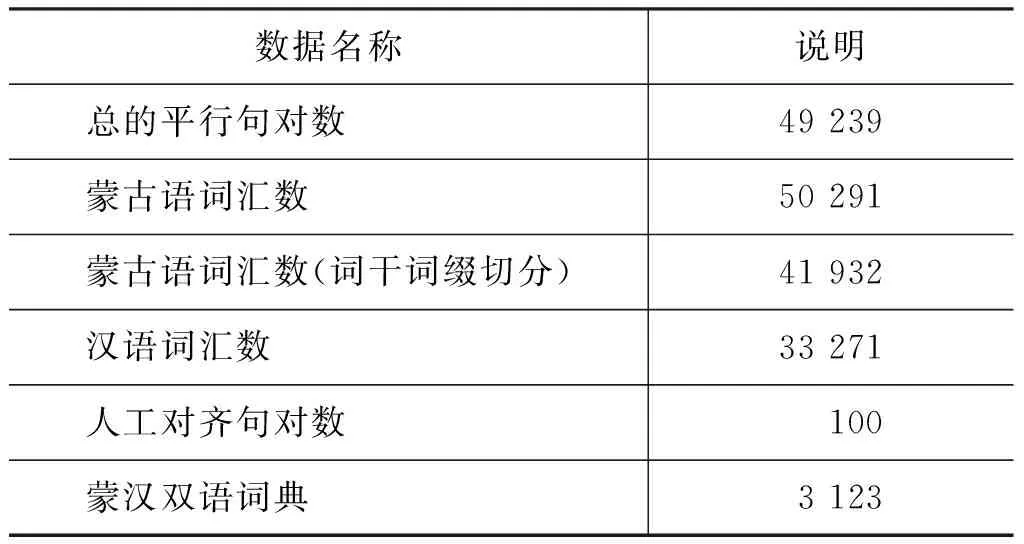
表1 实验数据信息
本文在采用IBM模型进行蒙汉词对齐实验时,需要得到全局的词对齐概率,蒙汉词对齐概率的结果文件具体表示如图6所示。图6中第一列为汉语词汇,第二列为蒙古语词汇,第三列表示蒙汉平行词语的对齐概率。本文在进行对数线性词对齐模型实验时,将对齐概率的对数值作为IBM模型特征的输入值。

图6 词对齐概率表示
3.3 实验结果
本文进行了基于IBM模型3和IBM模型4的蒙汉词对齐模型相关实验。实验重点对比蒙古语进行词干词缀切分后对蒙汉词对齐质量的影响。具体实验结果数据对比如表2所示。
本文在基于IBM模型蒙汉词对齐实验后,还进行对数线性词对齐模型的相关实验。将IBM模型特征融入到对数线性词对齐模型中去,并与IBM模型3和IBM模型4的实验结果进行对比分析。本文进行对数线性蒙汉词对齐模型的训练,主要目的是对比采用不同IBM特征对对数线性词对齐模型的蒙汉词对齐质量的影响,具体实验结果数据对比如表3所示。实验中通过控制变量方法可以有效研究蒙古语词干词缀切分对词对齐结果的影响。
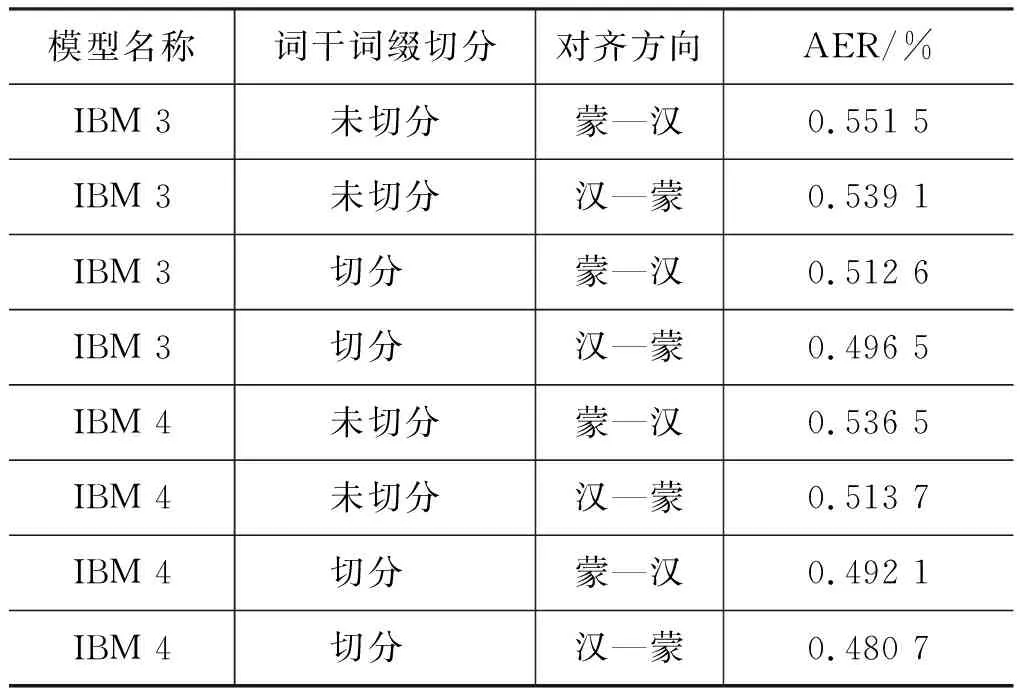
表2 IBM模型3和模型4词对齐结果

表3 对数线性模型词对齐结果
表2基于IBM(3-4)模型进行词对齐实验中,通过对比蒙古语是否进行词干词缀切分可以发现,蒙古语词干词缀切分对蒙汉词对齐质量有明显的提高。通过对比表2和表3中的实验数据发现,在对数线性词对齐模型中,蒙古语进行词干词缀的切分对蒙汉词对齐质量较IBM模型蒙汉词对齐结果有更显著的提高。对数线性判别式词对齐模型普遍取得了比IBM模型特征更好的词对齐结果。采用启发式方法融合的双向IBM模型4特征训练得到的对数线性词对齐模型取得了0.430 2的词对齐错误率。通过实验数据对比发现,在进行蒙汉词对齐模型进行训练时,对蒙古语进行词干词缀的切分有利于提高模型的对齐准确率。
4 总结和未来工作
由于蒙古语语言本身的复杂性以及蒙古语语料相对匮乏,蒙古语相关机器翻译发展始终没有大的突破。为了提高蒙汉机器翻译质量,就需要实现更高质量的蒙汉词对齐。本文提出了一种将蒙古语进行词干词缀切分后作为蒙汉机器词对齐基本单位,且这种方法对蒙汉机器翻译过程中的数据稀疏问题有明显缓解作用又有效减少了蒙语词汇表的规模。本文基于IBM(1—4)的蒙汉词对齐和对数线性模型进行了蒙汉词对齐实验。实验结果证明了对蒙古语进行词干词缀的切分对蒙汉词对齐质量确实有显著提高。接下来我们将把对蒙古语进行词干词缀切分的方法应用到整个机器翻译中去,蒙古语切分后的词干词缀将作为机器翻译的基本输入单元做进一步的相关研究。
猜你喜欢
西部蒙古论坛(2022年2期)2022-07-12 04:47:38
蒙古学问题与争论(2020年0期)2020-03-29 06:26:58
现代职业教育·高职高专(2020年22期)2020-03-24 22:46:34
内蒙古艺术(2018年4期)2019-01-18 02:56:36
中文信息学报(2018年11期)2018-12-20 06:08:44
赤峰学院学报(蒙文哲学社会科学版)(2018年4期)2018-12-05 05:21:00
赤峰学院学报(蒙文哲学社会科学版)(2018年1期)2018-04-25 07:57:25
赤峰学院学报(蒙文哲学社会科学版)(2018年1期)2018-04-25 07:57:24
卫拉特研究(2016年0期)2016-12-06 09:12:06
中国社会历史评论(2016年2期)2016-06-27 07:11:48
