
多特征关键词提取算法研究①
2018-07-18 06:06王丽清
计算机系统应用 2018年7期
王 洁, 王丽清
(云南大学 信息学院, 昆明 650223)
随着互联网的飞速发展, 网络资源的数据量日益庞大. 面对海量的数据, 如何有效、准确地提高对文章内容的检索效率, 一直是一个研究热点. 一篇文章的关键词往往反映了文章的主题, 具有与内容高度相关的代表性. 准确、快速地提取关键词, 对于信息检索至关重要.
近年来, 国内外相关学者在关键词提取技术领域开展了大量的研究工作. 其中, TFIDF (Term Frequency-Inverse Document Frequency)算法主要通过对词频的计算来判断提取词对文章的代表性, 是常用的一种基于统计的提取方法. 但却存在过度依赖词频的问题. 为此, 往往会引入特定因子进行计算以此减少对词频的依赖. 例如, 考虑基于词位置和词跨度的方法进行TFIDF算法的权重改进[1,2], 或者利用语义的连贯性, 结合词频和位置特征, 进行加权[3], 也有引入信息熵的方法[4]. 但这些方法存在一定计算复杂性问题, 或者在文章类型和语料规模上有一定局限. 也有结合文章综合信息和引用新闻类别因子的方法[5,6], 增加了其他特征因子对权重进行加权, 能一定程度校正词频依赖问题.但未考虑关键词词性以及关键词覆盖度不同所带来的影响.
针对上述问题, 本文将TFIDF算法和中文语言的特性进行了有效结合, 通过引入位置因子、词性因子等多特征值进行权重的二次计算, 校正词频依赖造成的关键词偏差, 并利用Python完成算法实现验证. 实验结果表明词性因子和位置因子的引入, 计算简单、高效, 能够有效地提高中文关键词的提取效果, 适于短文章关键词的提取.
1 基于TFIDF的多特征关键词提取改进算法
1.1 TFIDF算法
TFIDF算法基本思想是: 利用词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)相乘, 得到权重值. 权重越大, 则该词为关键词的概率越高[7]. 根据TFIDF算法, 词权重Wtf(i)的计算公式如下:

式(1)中, tfi=该词在文章内容中出现的次数/文章总词数, tfi值表示该词在文档中出现的频率; idfi=log(语料库文档总数/包含该词的文档数), 即: idfi=log(N/dfi),idfi值的大小代表了该词的类别区分能力[8].
根据以上公式可知, 当词在文档中出现频率较高,而在包含该词的文档数中出现频率较低时, 则该词根据TFIDF算法得到的权重值Wtf就越高, 故该词可以在一定程度上表示文章的内容.
1.2 算法改进思想
(1)特征分析
位置因子. 分析新闻或信息内容的特征可知: 新闻篇幅相对较短, 其标题往往具有概括性. 如果一个词,在标题中出现, 该词的重要性往往高于其他词. 词语出现的位置在一定程度上反映了词语的重要性[9].
词性因子. 词性是一种浅层语言学知识的表示, 根据汉语词性可分为实词和虚词. 实词包含: 名词、动词、形容词、数词、量词和代词. 虚词包括: 副词、介词、连词、助词、叹词、拟声词. 关键词词性分布一般是名词或名词性短语为主. 其次是动词, 最后是数词、副词和其他修饰词等[5]. 考虑词性特征可以有效避免传统采用语言学方法的缺陷[10].
(2)加权方式
TFIDF算法在提取中, 主要依赖词频进行权重计算, 但存在过度依赖词频的噪声. 因此, 可以先利用TFIDF算法完成权重计算后, 再对每个词进行位置判断. 并且, 在考虑标题位置的同时也考虑该词在正文中的位置. 将同时出现在标题和正文中的词, 其因子设置为最高; 只出现在标题中的次之; 而只出现在正文中的因子设为逐次递减的不为零的低值.
完成位置特征引入后, 再进一步考虑引入词性特征. 对提取出来的关键词进行词性标注. 按名词、动词和其他词汇的顺序从高到低设置为不为零的值.
最后, 将以上词频、标题位置、正文位置和词性作为多特征因子, 共同引入权重计算中, 计算出每个特征词的综合权重, 按其排序进而确定关键词. 这就是本文算法的核心思想.
1.3 关键词提取流程
关键词的提取流程示意图如图1.

图1 关键词提取
在关键词提取前, 首先需要对文本进行分词和去停用词等预处理. 分词是进行中文关键词提取的第一步, 也是重要的一步. 通过分词将文本中的每一个句子,按照一定的规则划分成有序的词语片段, 其中标点、词语、单字均可以划分. 本文利用Python语言结合结巴分词进行实现.
停用词在文本分析中, 属于一种冗余数据, 对文章的主题不具备表达能力, 往往具有高频、无意义等特点. 例如: “的”、“啊”、“但是”等词语以及标点符号. 通过去除停用词, 能消除对关键词提取的干扰. 在本文中,采用引入对应的停用词表并保存, 再以Python编程调用完成去除处理.
在Python中, 词性的标注规则如表1所示, 名词均是以n开头, 动词以v开头.
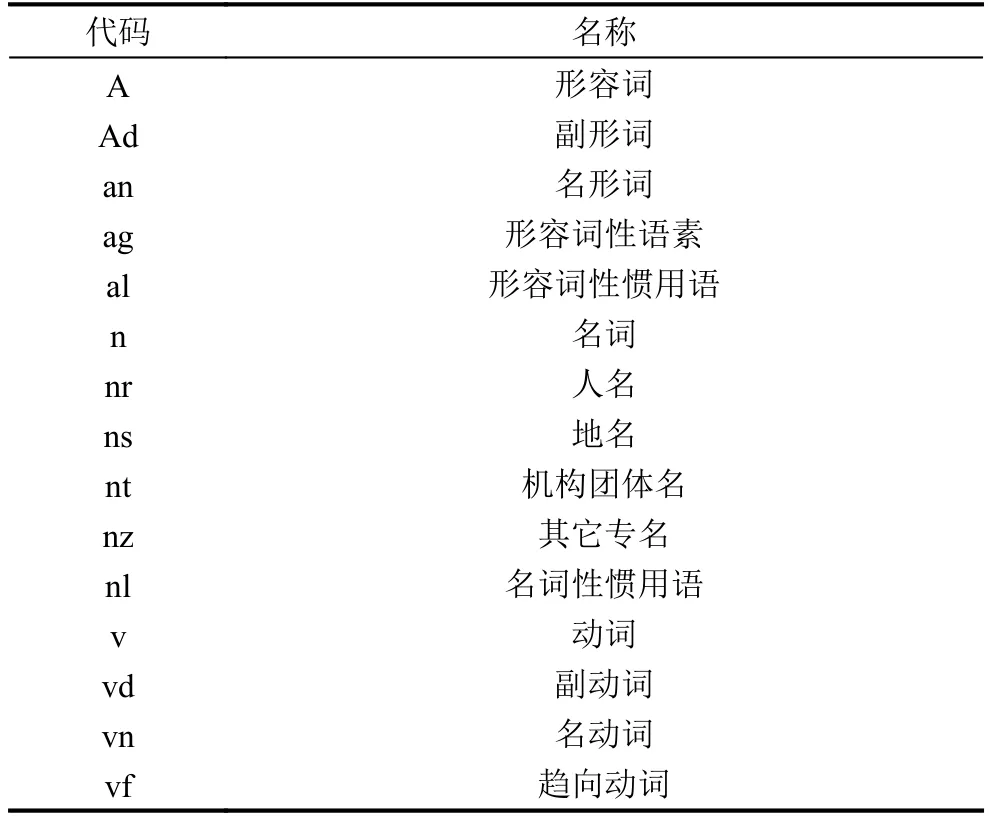
表1 部分结巴分词词性标注
1.4 权重计算
本文提出的权重计算函数如下:
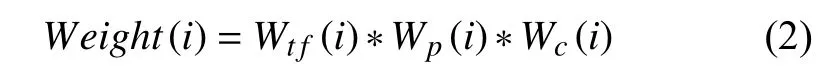
其中,Weight(i)为候选词i的综合权重;Wtf(i)为TFIDF提取词i得到的权重; 计算方法是:Wtf(i)=tfi*log(N/DFi);Wp(i)为位置因子权重, 计算方法是: 根据提取词在文章中出现位置进行赋值.Wp=3, 出现在标题和正文中;Wp=2, 仅出现在标题中;Wp=1, 仅出现在正文中.Wc(i)为词性因子权重, 计算方法是: 根据提取词的词性来进行赋值. 提取词是名词性词汇Wc=3, 动词性词汇Wc=2, 其他词汇Wc=1.
在本文算法中, 在计算词Wtf(i)权重的基础上, 结合词性和词在文中出现的位置, 进行综合权重计算并由高到低排序, 从中提取5个词作为关键词, 仅提取5个词的原因是太多不利于检索, 太少不够全面. 在此过程中, 词性和词在文中出现的位置是权重计算的重要参数.
2 算法实现
本文算法python语言实现如下, 主程序中通过调用keyword()完成提取:



3 实验分析
为完成算法的测试和评价, 测试数据采用的是预先提取的中国商务部日常新闻语料库, 分别采用传统TFIDF算法和本文所述TFIDF多特征改进算法完成关键词提取, 然后对结果进行评价.
3.1 评价标准
在结果评价中采用准确率P, 召回率R以及F因子完成评价. 准确率是检索出的相关文档数与检索出的所有相关和不相关文档总数的比率, 也叫查准率;检索出的相关文档数和文档库中所有检索到和未检索到的文档总数的比率, 也叫查全率.F因子是两者的综合指标, 当F因子较高时, 则能说明试验方法比较有效. 计算方法如下所示:
(1) 准确率Precision
准确率P=提取出的正确信息条数/提取出的信息条数.
(2) 召回率Recall
召回率R=提取出的正确信息条数/样本中的信息条数.
(3)F因子F-measure:
F因子=准确率P*召回率R*2/(准确率P+召回率R).
3.2 实验结果及分析
实验数据为预先提取的4000条新闻信息, 从中抽取300条新闻作为测试用例. 300条新闻中包含了100条左右的短新闻, 并进行对应的分组. 将300条新闻分别分成20篇、50篇、80篇、100篇和150篇, 目的是希望通过测试数据的增加, 验证本文所述改进算法是否会一直优于传统TFIDF算法.
利用百度搜索引擎进行关键词检索, 验证是否能检索到对应的新闻文章. 最后计算TFIDF算法和改进算法的准确率P, 召回率R,F因子. 计算结果如表2所示.

表2 两种算法评价指标对比
为方便观察实验结果的变化, 对两种算法的准确率(图2)、召回率(图3)和F因子(图4)三项指标分别做图,如下所示:
根据表2和图2~图4可知: 在新闻篇数相同的情况下, 准确率P, 召回率R,F因子三项指标结果均是TFIDF改进算法优于原本的单一算法. 证明本文所述TFIDF改进算法在一定程度上能够有效地提高关键词提取的准确度. 此外, 通过计算提取关键词的时间, 发现改进的TFIDF算法与传统的TFIDF算法执行时间之差在1 ms以内.
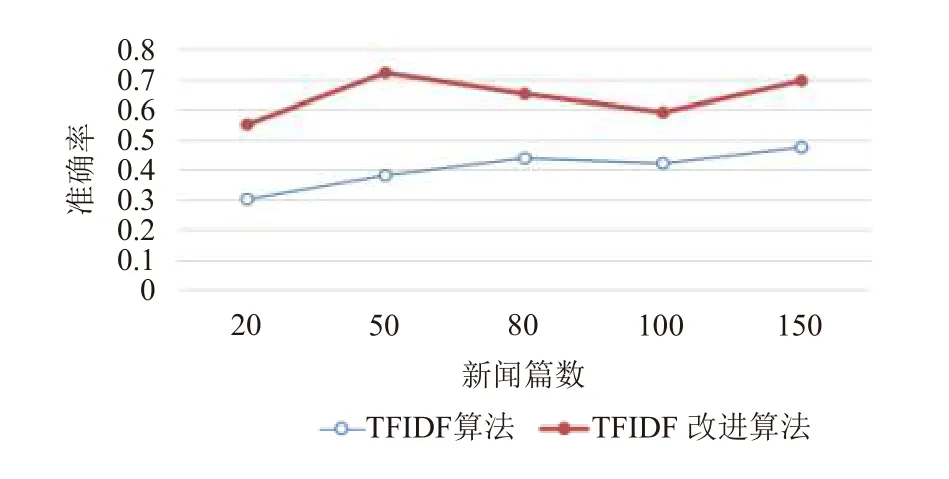
图2 准确率折线图结果
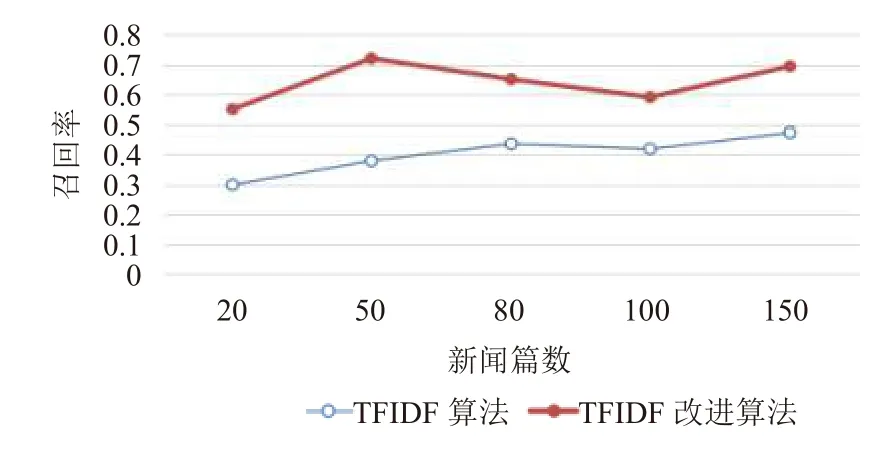
图3 召回率折线图结果
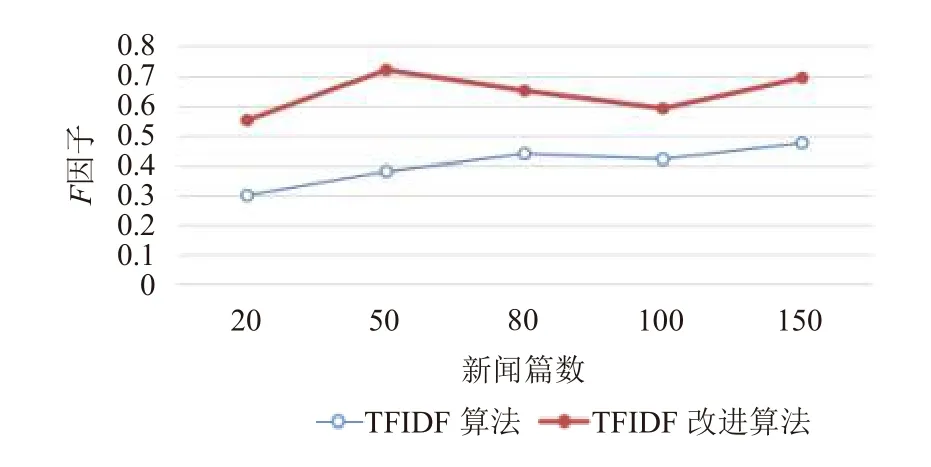
图4 F因子折线图结果
4 结论与展望
本文对传统的TFIDF算法进行了改进, 通过在关键词权重计算中引入词的位置因子和词性因子以降低TFIDF算法依赖词频而造成的影响. 同时, 利用Python语言完成了算法实现, 并对算法结果进行了实验验证.
实验结果表明, 本文所述算法能有效提升关键词提取的质量效果. 但由于测试条件有限, 本文评价标准的计算结果主要依赖于人工检索, 在测试语料的多样性和总体数量上也有一定局限性. 因此, 下一步将在条件许可时, 在大规模多样性测试语料集上进一步验证和改进算法.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
电脑爱好者(2017年7期)2017-05-06
读者·校园版(2015年7期)2015-05-14
