
基于粗糙集理论与CAIM准则的C4.5改进算法①
2018-07-18 06:06于宏涛贾宇波
计算机系统应用 2018年7期
于宏涛, 贾宇波
(浙江理工大学 信息学院, 杭州 310018)
决策树算法在数据挖掘领域占有非常重要的地位.当前主要的决策树算法[1]包括ID3算法、C4.5算法、CART算法、SLIQ算法、SPRINT算法、PUBLIC算法等. C4.5算法[2]是1993年由Quinlan提出的, 其因直观高效等优点在医疗、金融、教育、互联网等多个领域得到广泛应用. 徐鹏等[3]利用C4.5算法对网络流量进行了分类; 罗森林等[4]将C4.5算法引入到糖尿病的数据处理中, 建立了有效的预测糖尿病的规则; 周琦[5]采用C4.5算法对学生成绩进行分析, 对学生高考成绩进行了预测; 吕晓丹[6]利用C4.5算法为商业银行建立了企业信用评价模型. 该算法的基本思想是首先将整个数据集做为根节点, 用各个属性的信息增益率作为度量属性重要程度的标准, 选择信息增益率最大的属性作为分裂属性将根节点划分成若干个子节点,并在各个子节点上重复进行分裂操作生成一棵完整的决策树.
C4.5算法克服了ID3算法偏向于选择属性值较多的属性的缺点, 新增了对连续属性的处理方法. 但是该算法生成的决策树分类精度不高, 树的规模较大. 造成上述问题的原因为: 1) C4.5算法在选择连续属性的分裂点时只考虑单个属性与类别属性的关系, 割裂了各个属性之间的联系, 这就造成了信息损失, 导致最终的决策树分类精度下降. 2) 在一个信息系统中, 并不是所有属性都是同等重要的, 有些属性与分类无关, 这些冗余属性的存在, 使生成的决策树规模较大, 分支增多.当前有许多学者对C4.5算法进行了优化, 刘佳等[7]基于Fayyad和Irani的证明, 对C4.5算法的连续属性离散化等方面进行了改进, 提高了算法效率和分类准确率; 曹燕等[8]提出了一种粗糙集理论与C4.5算法相结合的算法RSC4.5, 降低了分类结果的复杂度; 黄秀霞等[9]将泰勒公式引入到信息增益的计算公式内, 提高了决策树的构建效率.
本文提出了一种基于粗糙集理论与CAIM准则的C4.5改进算法. 本算法在连续属性的处理上采用了一种基于CAIM准则的多属性关联的离散化算法, 使得在连续属性离散化过程中造成的信息损失降低, 提高了决策树的分类精度; 运用一种基于粗糙集理论的属性约简算法去除了决策表中与分类无关的条件属性,使得生成决策树的规模减小.
1 基于CAIM准则的离散化方法
C4.5算法的一个优点是支持对连续型数据的处理, 其处理方式为对首先每个连续属性选取足够多的候选断点, 再分别计算每个候选断点的信息增益, 选取信息增益最大的断点作为最终断点. 但是C4.5算法的断点选择过程中只考虑了单个连续属性与决策属性之间的关系, 这中处理方式造成了较多的信息损失, 使得构建的决策树分类精度降低. 杨萍等[10]提出了一种基于CAIM准则的数据离散化方法, 该算法根据决策表中决策属性与多个条件属性之间的联系构造离散化框架, 使得离散化后的条件属性与决策属性的关联程度达到最大. 利用这种离散化方法可以降低连续属性离散化过程中的信息损失, 有效提高C4.5算法的分类精度.
1.1 CAIM准则
Kurgan和Cios在2004年提出了CAIM准则[11],它是类别和属性值之间的关联程度的一种度量. 下面对CAIM准则进行简单的介绍.
给定一个决策表S, 条件属性集为C, C中包含w个连续属性, 决策属性为{d}. 决策表S共包含n个元素, 决策属性d将所有元素划分为k个类别. 对C中任意一个连续属性c, 可以确定一个离散化框架, 将c的值域划分为m个离散区间为属性c值域中的最小值, cm为最大值,对于任意的有 ci>ci–1.
根据一个确定的离散化框架、决策属性变量和连续属性c的离散区间, 可以确定一个二维矩阵, 如表1所示. 其中表示决策属性d的k个取值,eir表示在决策表中决策属性取值为di且连续属性c的取值在(cr–1, cr]中的元素个数. Ndi表示决策属性取值为di的元素个数, Ncr表示属性c的取值在区间(cr–1,cr]的元素个数.

表1 离散化二维矩阵
由一个离散化二维矩阵可得CAIM准则的如下定义:
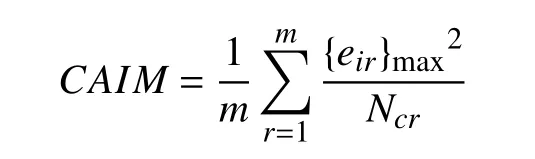
{eir}max表示当i变化时eir的最大值, 如果{eir}max=则称决策属性取值为dh的元素构成的集合为区间(cr–1, cr]中的主导类. 主导类中包含的元素个数越多, CAIM的值就越大, 类别与离散区间的关联程度就越大.
1.2 一种基于CAIM准则的离散化算法
离散化算法的根本目的是求取一个断点集合, 将连续属性划分为多个区间. 在最理想的情况下, 可以选取出k–1个断点(k为决策属性取值个数), 断点划分出的k个区间中的元素全部属于同一个类别, 此时CAIM达到理论上的最大值CAIM=n/k, k–1个断点为最佳划分断点集合. 在实际问题中CAIM的值随着断点的增加而增加, 达到局部最大后开始下降, 此时为使决策属性与待离散的条件属性关联程度达到最大, 必须要选择足够多的断点, 使划分出的离散区间中所有元素都属于同一个类别. 如果只考虑离散区间中的主导类则会造成信息损失, 使离散结果的质量下降.
前面论述的都是单个连续条件属性与决策属性之间的关联, 实际上仅仅依靠单个属性是不能区分元素的, 因此应该考虑到决策属性与所有属性之间的关联关系, 从而降低信息损失, 提高分类的精度. 从多个属性的角度考虑连续属性的离散化, 实质上就是寻找一个最小的断点集合, 这些断点可以将整个决策表划分成一个个的超立方体, 并使得每个超立方体中的元素都属于同一个类别. 在考虑多个属性与决策属性关联的离散化算法时如果只追求由断点集划分出的超立方体空间中的元素都属于同一个类别, 则会使断点个数太多, 离散效果不好. 因此我们需要在断点个数与超立方体空间中元素纯度之间寻找一个平衡, 使离散化结果达到我们想要的效果. 由前面的讨论我们知道在最理想的情况下每个连续属性的断点个数为k–1个, 将每个连续属性划分为k个离散区间, 在此我们将k设为离散化区间的期望个数. 在每个离散化区间中, 设定一个最小阈值, 使得每个区间中主导类的个数不小于最小阈值, 给出一个常量则有{eir}max>R*Ncr, r=1, 2,…, k. 此时有最小的CAIM期望值为:
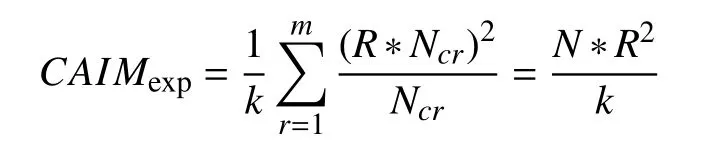
设CAIMpmax为局部最大值, 则每增加一个断点CAIM的下降幅度不超过(CAIMpmax–CAIMexp)/(k–1)时, 可以得到预期的离散化结果.

算法1. 基于CAIM准则的多属性关联离散化算法1) 设i=1, DS={U}, 离散化结果断点集合CutPoint=.2) 设DStemp=, r=1. 对DS中的一个元素Ur, Ur内共包含kr个类别.

3) 取一个连续属性 ci, 将 ci的值域按照升序排列得:, 取两个相邻属性值的平均数构成集合. B为候选断点集. 初始化离散化框架为, 历史CAIM最大值CAIMpmax=0, 属性ci的断点集合Point=.4) 设j=1, CAIM的最小期望值为CAIMexp=|Ur|R2/kr.5) 遍历B中的断点加入离散化框架LS中计算CAIM值, 取使CAIM值最大的点, 记CAIM最大值为CAIMh. 6) 如果第5步中CAIMh满足 或, 则令CAIMpmax=CAIMh. 将第4步选择的断点加入离散化框架LS和断点集合Point中, 并在B中删除该断点.另j=j+1, 如果j<kr则转到第5步.7) 假设离散化框架LS将Ur划分成多个小集合, 设Ux是其中一个,如果Ux中的元素不都属于同一类别则另.8) 令 DS=DStemp, r=r+1, 如果, 则转至第 3 步.9) 此时Point为属性ci的断点集合, 令, i=i+1,如果i<l, 转至第2步, 否则算法结束, CutPoint为各个连续属性的断点集合.
2 基于粗糙集理论的属性约简
2.1 粗糙集理论
1982年Pawlak提出了粗糙集理论[12], 它是一种新的处理不确定、不精确和含糊信息的数据分析理论.下面对本文用到的粗糙集理论相关概念进行简单介绍.
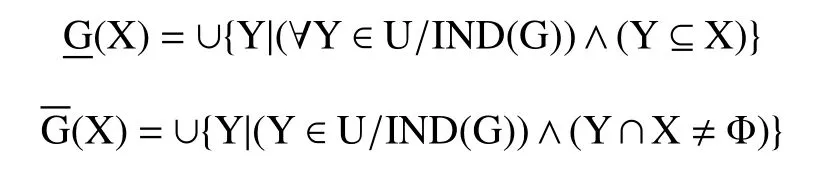
定义2. 设P和Q分别是决策表S的属性子集,则P, Q分别将论域U构成一个划分X=U/IND(P)和Y=U/IND(Q)记将X和Y在论域U上的概率分布表示为:
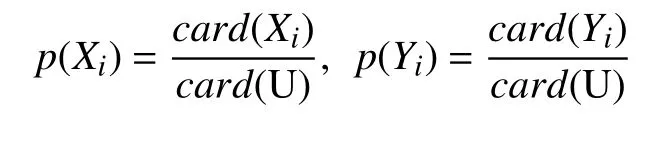
其中card(E)表示集合E中的元素个数. 记p(Yj|Xi)为Yj对Xi的条件概率, 计算公式如下:
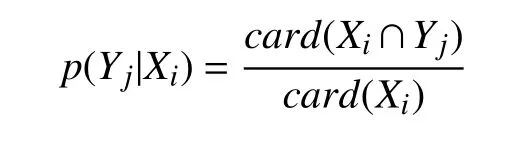
定义3. 对于给定的属性子集P和他的概率分布,称H(P)为P的信息熵, 计算公式如下:
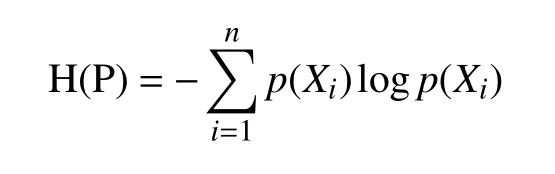
定义4. 对于给定的属性子集P和Q以及它们的概率分布和条件概率分布, 称H(Q|P)为Q相对于P的条件熵, 计算公式如下:
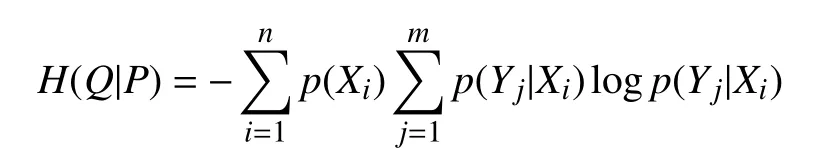
定义5: 给定属性子集P、Q以及他们的信息熵和条件熵, 称H(Q)-H(Q|P)为P与Q的互信息, 记为I(P;Q).
定义6[13]. 对于决策表S, 条件属性集为C, 决策属性集为D, 取p∈C, 如果条件熵H(D|C)=H(D|(C-{p})),则称属性p在C中是D-不必要的; 如果条件熵H(D|C)<H(D|(C-{p})), 则称属性p在C中是D-必要的.如果C中所有属性都是D-必要的, 则称C是相对于决策D独立的. C中所有D-必要的属性组成的集合称为C的相对于决策D的核, 记为CORED(C).
定义7. 对于决策表S, 条件属性集为C, 决策属性集为D, 设如果满足都有则称B是C的一个相对决策D-约简, 记为是所有约简组成的集合.
2.2 属性约简算法
属性约简是运用粗糙集理论处理的主要问题之一.属性约简的根本目的是在保证决策表分类能力不变的前提下删除条件属性中的冗余属性. 当前有很多有效的属性约简算法, 如基于属性重要度的约简算法[14]、基于信息熵的约简算法[15]、基于互信息的属性约简算法等[16]. 本文将采用基于互信息的属性约简算法对决策表进行属性约简, 其约简算法步骤如算法2.

算法2. 基于互信息的属性约简算法1) 计算决策表中条件属性C和决策属性D的互信息I(C;D)=H(D)–H(D|C).2) 计算C相对于D的核属性集合CORED(C), 另B=CORED(C).

3) 计算B与决策属性D的互信息I(B;D)=H(D)–H(D|B), 如果I(B;D)=I(C|D)则转到第5步.4) 取任意的条件属性ci,, 计算互信息,求得使I(ci, D|B)最大的属性cm, 令, 转到第3步.5) 输出B, B即为决策表的属性约简.
3 基于粗糙集理论与CAIM的C4.5算法
3.1 C4.5算法
C4.5算法是一种在ID3算法基础上改进的决策树生成算法, 它采用信息增益率作为节点选择衡量标准,在ID3算法的基础上增加了对连续属性的处理和剪枝方法. C4.5算法整体上分为3步: 1) 如果决策表中有连续属性, 对连续属性进行离散化处理. 2) 以信息增益率做为分裂节点的选择标准, 递归构建决策树. 3) 对构建的决策树采用悲观剪枝方法[17]进行剪枝处理. 下面首先介绍信息增益率的相关概念, 再对C4.5算法的步骤进行简单说明.
定义8. 给定一个决策表S, 决策属性将整个决策表划分为m个样本子集表示决策表中一个元素分布在Si中的概率, S的信息熵定义为:

定义2. 给定决策表S, 条件属性c将决策表划分为k个不同样本子集则按属性c划分S的信息增益定义如下:

定义3. 信息增益率定义如下:

C4.5算法的具体步骤如算法3.

算法3. C4.5算法1) 如果决策表中有连续属性, 则首先对决策表的连续属性变量进行离散化处理. 设连续属性有n个取值, 处理过程为首先对连续属性取值进行从小到大排序, 再选择相邻值的平均值作为分割点将连续属性划分为n个小区间.

2) 计算每个属性的信息增益率. 对于连续属性, 分别计算以候选分割点进行划分的信息增益率, 选择信息增益率最大的候选分割点作为该连续属性的最终分割点. 比较各个属性的信息增益率, 选择信息增益率最大的属性作为分裂节点.3) 分裂节点的每个属性取值都对应一个子集, 再对子集递归执行第2步, 直到划分的每个子集中的元素都属于同一类别, 生成决策树.4) 对第3步生成的决策树采用悲观剪枝方法进行剪枝处理.
3.2 改进的C4.5算法
通过对4.5算法的分析, 发现以下问题导致C4.5算法生成的决策树分类精度不高, 树的规模较大.1) C4.5算法对连续属性的处理只考虑了单一连续属性与决策属性的关联关系, 在离散化过程中会造成较多的信息损失, 导致分类精度降低. 2) 决策表中可能存在与分类无关的冗余属性, 使得决策树构建过程中生成树的规模过大.
为解决上述问题, 本文提出了一种基于CAIM准则和粗糙集理论的C4.5优化算法. 其基本思想是首先判断决策表中是否有连续属性, 如果有则采用基于CAIM准则的数据离散化方法对连续属性进行离散化处理. 再利用基于粗糙集理论的属性约简算法对决策表进行属性约简, 最后计算每个属性的信息增益率, 选择分裂属性递归构造决策树. 此算法采用的离散化方法考虑了多个条件属性与决策属性的关联关系, 避免了C4.5算法在连续属性的处理过程中只考虑单一属性与决策属性关系所造成的信息损失, 可有效提高决策树的分类精度. 改进的C4.5算法在构建决策树之前增加了属性约简的步骤, 属性约简可以剔除与分类无关的条件属性, 使生成的决策树规模减小. 该算法具体步骤如算法4.

算法4. 基于CAIM准则与粗糙集理论的C4.5改进算法1) 如果决策表中有连续属性, 运用于CAIM准则的离散化方法对连续属性进行离散化处理, 否则转至第2步.2) 运用基于粗糙集理论的属性约简算法对决策表进行属性约简, 去除冗余属性.3) 计算每个属性的信息增益率, 选择信息增益率最大的属性作为分裂节点.4) 分裂节点的属性取值将决策表划分为多个小决策表, 对每个小决策表递归执行第3步, 直到划分出的每个小决策表中的元素都属于同一类别, 生成决策树.5) 对第4步生成的决策树采用悲观剪枝方法进行剪枝处理.
4 实验设计与分析
为验证本文改进算法的有效性, 从UCI机器学习数据库[18]中选取了3个有代表性的决策数据集: 虹膜植物集iris、葡萄酒识别数据集wine、皮马印第安人糖尿病数据集pima进行实验分析. 这3个数据集的详细信息如表2所示.
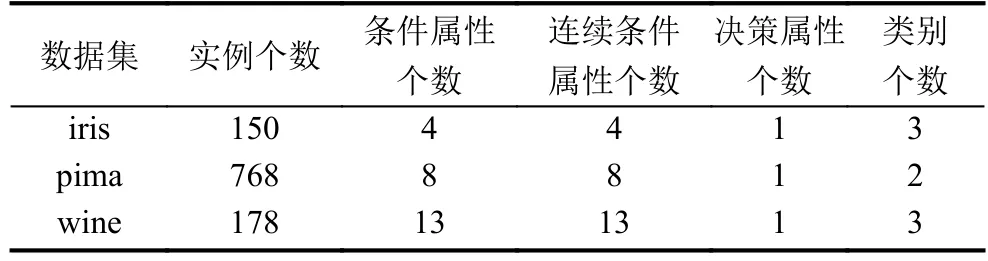
表2 实验数据
取每个数据集的70%作为训练样本数据, 30%为测试数据. 将本文算法中离散化过程的参数R设为0.8与Weka中的J48(即C4.5)算法在分类准确率与生成决策树节点个数两个方面进行对比, 实验结果如表3所示.
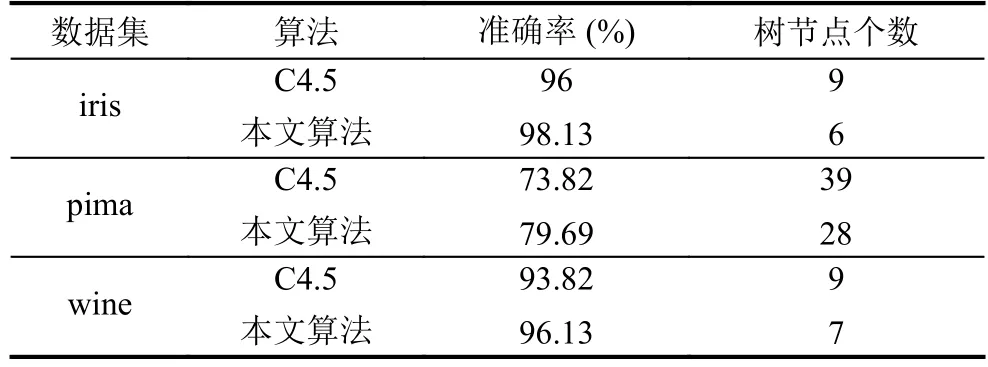
表3 实验结果
从表3可以看出, 本文算法与C4.5算法相比iris数据集准确率提高了2.13%, 树节点个数减少3个;pima数据集准确率提高了5.78%, 树节点个数减少8个; wine数据集准确率提高了2.31%, 树节点个数减少了2个. 从实验结果中可以看出, 本文算法相较于C4.5算法在分类准确率和生成树规模上都有一定程度的优化, 证明本文算法切实有效可行. 通过本文算法生成的决策树能够更好的对新数据进行分类和预测.
5 结论
本文对基于CAIM准则的离散化方法、基于粗糙集理论的属性约简算法和C4.5算法进行了简单介绍.通过对C4.5算法分类精度不高、生成决策树规模较大的问题产生原因进行分析. 本文用基于CAIM准则的离散化方法代替C4.5算法中对连续属性的处理方法, 在离散化的基础上进行属性约简, 去除冗余属性,降低了决策表的属性维度, 最后生成决策树. 实验结果表明改进后的C4.5算法有更好的分类效果, 生成更为简洁的决策树.
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
聊城大学学报(自然科学版)(2022年5期)2022-10-29
辽河(2022年4期)2022-06-09
小型微型计算机系统(2019年10期)2019-11-11
电脑报(2019年20期)2019-09-10
小型微型计算机系统(2019年9期)2019-09-09
计算机与数字工程(2019年8期)2019-09-03
电子技术与软件工程(2019年12期)2019-08-22
初中生世界·九年级(2019年6期)2019-08-15
计算机与生活(2019年3期)2019-04-18
