
图像和惯性传感器相结合的摄像机定位和物体三维位置估计
2018-07-11 03:29郭恩特陈志峰范振嘉黄立勤
福州大学学报(自然科学版) 2018年4期
郭恩特, 陈志峰, 范振嘉, 黄立勤, 潘 林
(福州大学物理与信息工程学院, 福建 福州 350116)
0 引言
自动驾驶和辅助驾驶系统中重要的一点是车辆定位和周围物体在物理世界中三维位置测量.由于摄像头相比于距离传感器, 如激光雷达等, 有价格低廉、 重量轻、 耗能少等优点, 因此, 计算机视觉技术在自动驾驶和辅助驾驶系统中有非常广泛的应用.例如在特斯拉汽车中, 无人驾驶硬件部分Autopilot2.0用了3个前置摄像头而没有使用激光雷达.结合深度学习, 计算机视觉在图像目标检测上有很大的突破, 例如, 最新的目标检测YOLO9000可以检测9 000种类别, 在VOC2007数据集上测试, 检测速度67 帧·s-1, 平均精度达到76.8 mAP[1].但是目前的CNN, 比如R-CNN, SSD等, 只能判断目标物体在图像上哪个位置[2-3], 而自动驾驶和辅助驾驶更加关心周围物体在三维世界中的位置和车辆的位置.
目前对实际物理世界中摄像机位置和物体位置估计的方法中基于视觉的同时定位于地图创建(vSLAM)是一个非常重要的方法[4].在vSLAM中, 假定周围环境都是静止的, 提取和匹配特征点, 使得每一帧重投影误差最小, 估计特征点在三维世界中的位置和摄像机的位置[5-6].但是单目slam具有尺度不确定性, 不论轨迹和环境放大和缩小多少倍都能得到同样的观测图像[7].视觉slam需要匹配精确的特征点, 复杂度较高, 在对实时性要求高的情况下很难做到高准确度.
随着MEMS 惯性传感器(IMU)的发展, MEMS IMU体积越来越小, 精度越来越高, 价格也不断降低, MEMS IMU结合嵌入式系统在车载系统、 无人机和手持设备上能有很好的应用.GPS信号在室内或者在城市受到“城市峡谷效应(urban canyon)”的影响不起作用时, IMU就能派上用场.但是IMU也存在因噪声产生漂移, 误差随时间积累的缺点.因此, 引入摄像机视觉观测融合IMU测量, 削减IMU测量误差累计的缺点, 不仅可以克服单目slam相机位置、 运动和地图构建尺度不确定性的缺点, 还可以克服由于相机运动过快而造成的图像模糊和两帧图像相交区域过少而造成的特征点匹配失败和丢失的缺点[8-9].
YOLO卷积神经网络检测连续图像序列中的物体, 采用扩展卡尔曼滤波(EKF)的方法, 融合IMU采集数据和图像信息, 估计摄像机位置和物体位置.
1 问题的提出
目前虽然可以在图像中检测行人或车辆等物体, 但在自动驾驶等实际应用中, 更希望获得物体在三维空间中的位置和摄像机的位置.双目视觉可以实现物体深度的估计, 单目视觉只能估计图像中的点在三维空间的方向而非所处的深度信息.而运动的单目摄像头一方面可以实现物体的深度估计, 另一方面通过物体在不同图像中的位置辅助IMU可以估计相机的位置和运动[10].为从图像中估计出感兴趣物体在三维世界中的位置以及相机的位置和运动, 采用惯性传感器中的加速度计和陀螺仪采集得到加速度和角速度, 由卷积神经网络对图像中的物体检测得到坐标, 并估计检测到的目标和相机的三维位置.
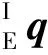
1.1 惯性传感器IMU运动模型

图1 世界坐标系下IMU运动过程 Fig.1 IMU motion in the world coordinate system
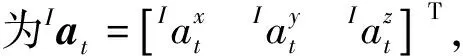
(1)
g为重力加速度, 函数R(·)为四元数到旋转矩阵的变换函数[13],
(2)
世界坐标系{E}中IMU位移求导为IMU速度, 世界坐标系{E}下IMU速度求导结果是加速度.单位四元数的求导结果为:
(3)

(4)
其中,I3为3×3单位矩阵,03×3为3×3零矩阵.
IMU包括加速度计和陀螺仪, 分别输出加速度和角速度,
(5)
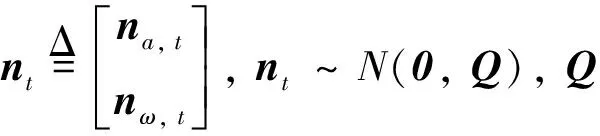
由公式(3)可知,
Ω(ω+υ)·q=Ω(ω)·q+Ω(υ)·q=Ω(ω)·q+Ψ(q)·υ
(6)
(7)
假设传感器以固定的采样周期T进行采样, 等式(5)积分得到k+1时刻旋转四元数
(8)
同样地, 已知k时刻IMU状态、 加速度计和陀螺仪的输出, 积分得到k+1时刻位移和速度:
(9)
通过等式(8)、 (9)得到IMU运动模型,
(10)
Ft为状态转移模型,Bt为控制输入模型:
(11)
1.2 相机观测模型

图2 摄像机针孔模型Fig.2 Camera pinhole model
相机观测模型是已知相机位置和目标点位置时, 目标点三维位置到二维图像的投影过程, 与摄像机位置、 角度以及被观测物体位置有关.本研究采用针孔摄像机成像模型, 如图2所示投影关系.
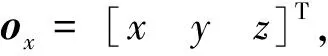
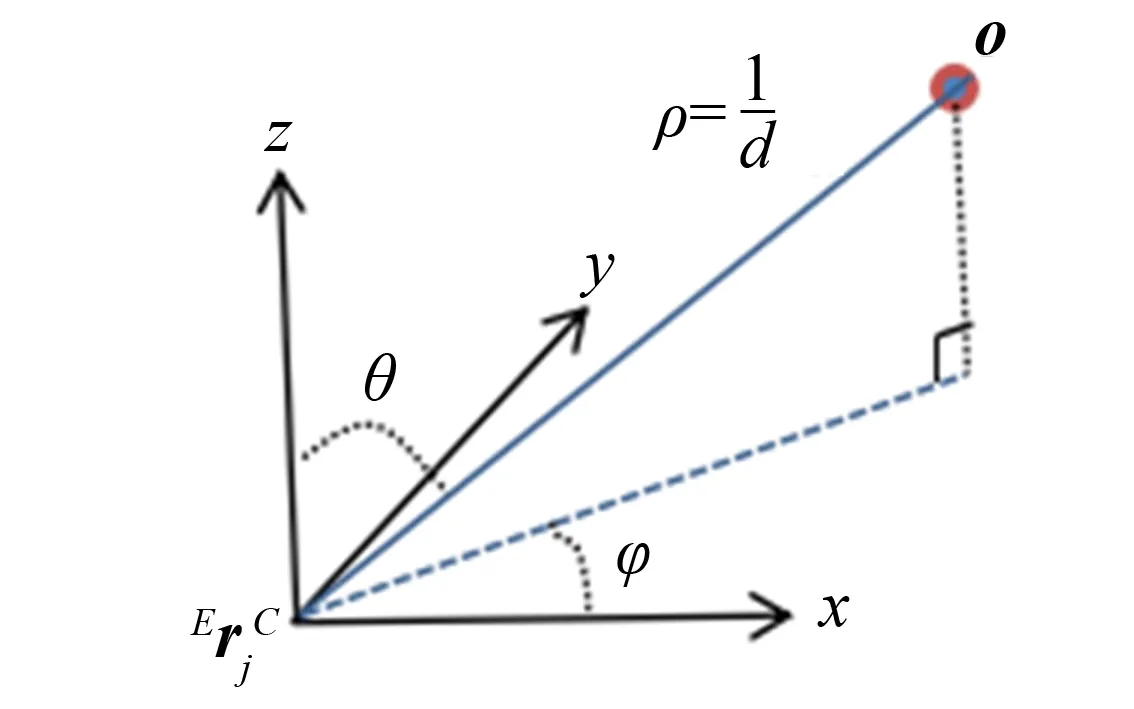
图3 三维物体用球面坐标系表示 Fig.3 Object in spherical coordinate system
如图3所示, 三维目标点ox用逆深度参数表示为:
(12)
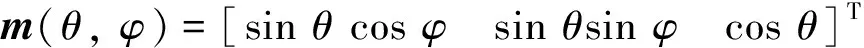
(13)
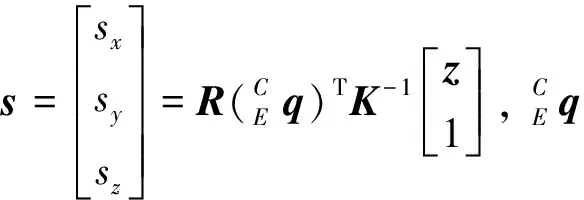

(14)

1.3 目标检测与目标点获得
图像中的物体由卷积神经网络检测获得.YOLO v2[1]采用全卷积的网络结构, 网络中一共有23层卷积层, 每层卷积层都采用了batch normalize[16]加快网络的收敛速度; 其中第26层为跳跃层, 将第27层的输入跳转到第17层的输出; 第28层为重构层将26×26×64的特征图转换为13 px×13 px×256 px; 第29层位跳跃层目的是将25层与28层的特征图结合产生13 px×13 px×1 280 px的特征图; 最终的滤波器数量Output定义为:
Output=(class+coords)×anchors
其中: class表示需要预测的类别数量(包括背景类别), coords表示预测区域左上角与右下角的坐标, anchors表示每个特征点预测不同尺度区域的数量[17].
YOLO v2在VOC 2007数据库上取得了40 帧·s-1的速度与78.6%的平均精度[1].相比于其他的高性能目标检测方法, 如Faster RCNN[17]、 SSD[3], YOLO v2在检测精度上与它们相近, 但是在检测速度上拥有巨大的优势.具体对比如表1.

表1 在VOC 2012数据集上性能对比
实验中使用YOLO检测得到图像中的物体, 用矩形框标记物体在图像上的位置, 如图4所示, 取矩形框的左上角和右下角表示物体在图像中的位置.在图像上事先人工手工标记物体位置作为真实值, 也是取左上角和右下角的点作为物体在图像中的坐标.检测得到的物体坐标减去真实值得到残差的分布近似高斯分布, 把YOLO检测物体得到的左上角和右下角坐标作为目标点的观测, 残差符合观测噪声高斯分布的假设, 如图5所示.

图4 YOLO v2对车辆的检测结果Fig.4 Result of detecting vehicle by YOLO v2
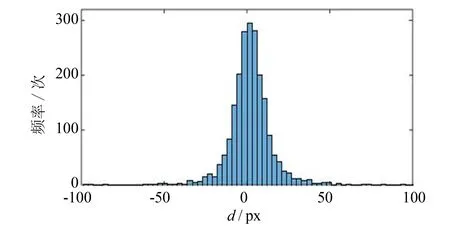
图 5 物体坐标检测值与真实值残差的直方图Fig.5 Histogram of the residual of the detected value and the ground truth
2 基于扩展卡尔曼滤波的目标三维位置估计
陀螺仪和加速度计测量得到带噪声的加速度和角速度, YOLO卷积神经网络检测图像中物体像素坐标作为观测值, 检测得到的物体坐标同样也是带有噪声的, 为了从带噪声的测量中估计摄像机位置和物体三维位置, 采用扩展卡尔曼滤波(EKF).扩展卡尔曼滤波主要由两个部分组成: 预测和更新[18].对新观测到的目标点状态进行初始化, 把新的目标点状态加入到当前状态中, 新观测到的目标点状态是之前状态中所没有的.二维图像上的点在三维空间中的位置未知, 但是可以知道三维空间中的点落在二维图像成像平面上的点和摄像机光心的射线上, 在摄像机运动的过程中, 摄像机连续观测三维空间中静止的同一个目标, 根据三角测量实现运动摄像头对静止目标的深度测量[19].
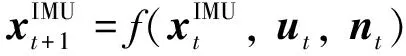
2.1 目标点状态初始化
当目标点第一次被观测到时, 需要把新目标点的状态增广到总状态x中, 增广协方差矩阵.第一次观测到目标点, 对目标点的深度没有先验知识, 但是随着摄像机运动产生足够大的视差, 目标点的深度估计就变得越加准确[19].
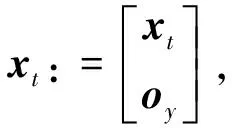
(15)
2.2 EKF预测
在YOLO未对图像检测之前, 滤波器使用上一个状态对摄像机位姿做出预测, 当前目标点的三维位置不变.由典型的扩展卡尔曼滤波可知, 在EKF的预测阶段, 状态向量预测值为:
(16)
协方差矩阵预测值为:
(17)
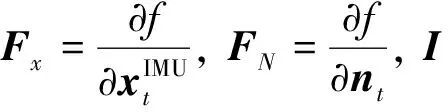
由于等式(26)可以得到稀疏的EKF预测等式:
(18)
2.3 EKF更新
当YOLO检测到静止的且在前面帧检测到过的物体后, 即有了观测值之后, 进行EKF更新.根据观测值重新调整状态, 更新摄像机位姿和物体在三维世界位置的估计, 更新状态的协方差矩阵为:
(19)
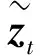
更新状态向量和协方差矩阵为:
(20)
3 实验部分
实验在模拟的场景和现实场景中分别测试算法.
3.1 模拟场景的测试
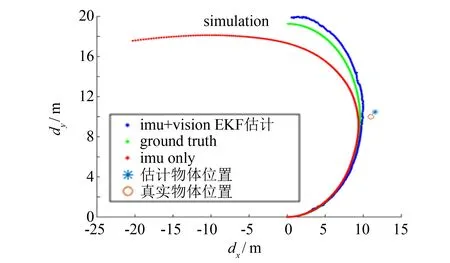
图6 模拟场景中估计的摄像机位置和真实位置Fig.6 Estimation position of camera in simulation scene
在x、y、z三个方向上的运动, 在偏航角、 俯仰角、 滚转角上的旋转如图7所示.
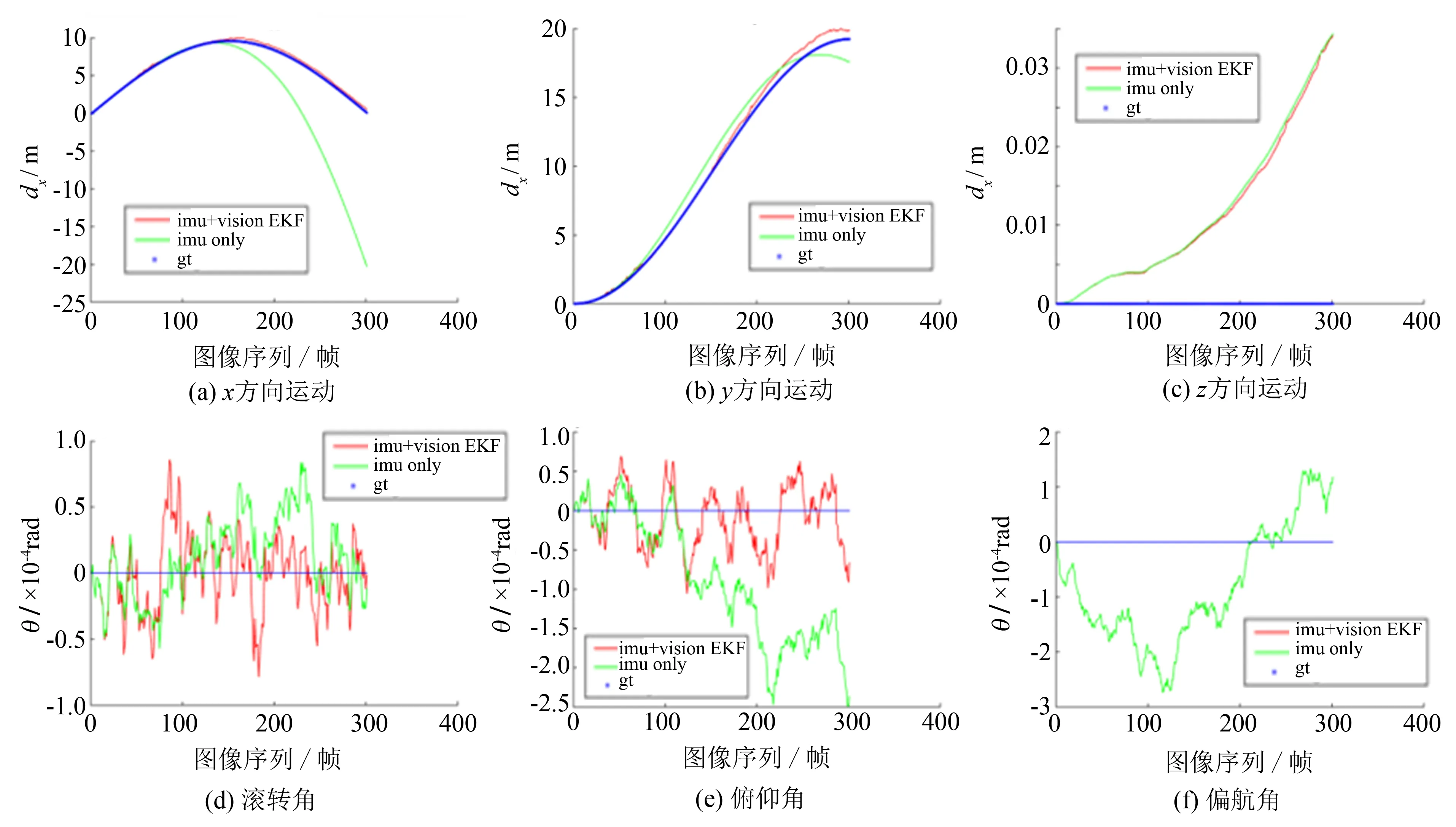
图7 运动和转动的分解 Fig.7 Decomposition of motion and rotation
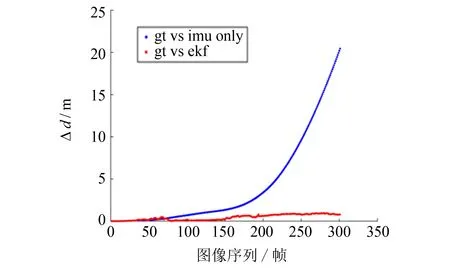
图8 每一帧真实相机位置与估计相机位置的偏差Fig.8 Residual of estimation position of camera and ground truth in every frame
每一帧IMU真实位置和估计位置的欧氏距离如图8所示.
仅用IMU数据计算得到的位置偏差很大的主要原因是角速度噪声引起的, 角速度噪声引起的IMU旋转偏差使得加速度g在x、y、z分量上引起很大的位移累积.如图9(a)所示, 角速度设为零方差, 加速度标准差σ=10-5, 引起RMSE=0.02 m的位移偏差; 如图9(b)所示, 加速度设为零方差, 角速度标准差σ=10-5, 引起RMSE=8.97 m的位移偏差; 如图9(c)所示, 设置模拟的环境为零重力环境, 加速度设为零方差, 角速度标准差σ=10-5, 引起RMSE=7.77×10-4m的位移偏差.
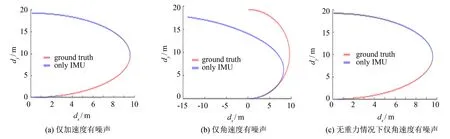
图9 模拟场景下摄像机位置和真实位置偏移情况Fig.9 Estimation position of camera and ground truth in simulation scene
3.2 户外真实场景的实验结果
采用KITTI数据集中的2011_09_26_drive_0027_sync序列作为测试数据[20].加速度和角速度由KITTI数据集提供, 观测值为卷积神经网络YOLO对KITTI数据集图像中车辆检测得到的左上角和右下角坐标作为观测数据, 如图10所示.在已经估计得到摄像机位姿和图中一辆车辆在物理世界的三维位置时, 将车辆左上角和右下角顶点投影回图像中并用线段相连.图中结果为211帧到218帧图像结果, 其中绿色矩形框为卷积神经网络YOLO的检测结果, 红色矩形框为估计结果, 蓝色矩形框为真实值.在所有图像中估计物体投影回图像的矩形框和真实值越接近则估计结果越准确, 也能纠正YOLO检测结果的偏差.
4 结语
YOLO卷积神经网络对图像中物体做检测, 结合惯性传感器采集得到的加速度和角速度信息, 用扩展卡尔曼滤波的方法估计摄像机位置和物体在物理世界中的三维位置.利用卷积神经网络提高特征点匹配准确度, 图像结合惯性传感器克服单目摄像头位置、 运动和物体在物理世界中位置的尺度不确定性, 通用地估计摄像头和物体在三维物理世界中的位置.假设卷积神经网络检测物体都为静止物体, 且每一帧图像检测得到的同一物体都已匹配.今后将研究场景中动态物体三维位置估计及大规模场景重建问题.
猜你喜欢
当代水产(2022年6期)2022-06-29
汽车观察(2018年12期)2018-12-26
金桥(2018年4期)2018-09-26
劳动保护(2018年8期)2018-09-12
中学生数理化·高一版(2017年3期)2017-07-08
中国公共安全(2017年11期)2017-02-06
办公自动化(2016年18期)2016-12-17
火控雷达技术(2016年1期)2016-02-06
中国铁道科学(2015年4期)2015-06-21
新闻前哨(2015年2期)2015-03-11
