
基于HBase的遥感数据分布式存储与查询方法研究*
2018-07-05 10:47景维鹏田冬雪
计算机工程与科学 2018年6期
景维鹏,田冬雪
(东北林业大学信息与计算机工程学院,黑龙江 哈尔滨 150040)
1 引言
近年来,随着航空航天遥感技术的迅猛发展,人们所能获取的影像数据(如航空摄影像片、卫星遥感像片、地面摄影像片等)的数量正在呈几何级数增长[1]。遥感图像的快速存储与查询,在对地观测、军事、勘探等领域发挥着重要作用。海量影像数据如何高效地存储、组织、管理与发布,提高处理和分发效率,已成为迫切需要解决的问题。
传统的基于文件系统[2]的管理方式利用了文件系统的读写优势,但是不能保证数据的完整性,在多用户并发访问时处理效率低。文献[3]提出了一种使用Oracle数据库来管理影像数据的方法,有效地解决了数据的完整性和一致性等问题。然而,在海量影像数据面前,这种方法受单个节点硬件设备的限制存在单节点故障、可扩展性不足、查询效率低等问题。随着开源大数据技术的发展,一些使用大数据技术来处理遥感影像的方法相继被提出[4 - 6]。文献[4]采用Hadoop平台存储矢量空间数据,该方法有效地解决了单节点故障和扩展性不足等问题。但是,没有考虑影像数据在存储过程中产生许多小文件的问题,导致占用了大量的主节点内存,增加了主节点负担。文献[5]在文献[4]的基础上提出了一种分布式Key-Value存储模型来管理海量影像数据,将小文件合并存储为一个大的数据文件,有效地解决了大量小文件问题。但是,没有对每层影像设计元数据进行描述,从而加大了数据的检索时间。文献[6]对文献[5]进行了改进,对每层影像设计了元数据,将存储过程中产生的瓦片利用MapFile进行合并,提高了影像数据的访问能力。但是,以上方法均是将影像数据直接存储在HDFS上,由于HDFS不支持在文件的任意位置进行修改且不适合吞吐量小和要求低延时的操作,所以上述方法存在不能直接对任意位置的数据进行更新和查询时间过长的问题。
为了解决上述问题,利用非关系型数据库HBase对遥感影像数据进行存储受到了国内外专家学者的青睐。文献[7]将处理后的影像数据存储在HBase中,可以对任意位置的数据进行更新操作,解决了遥感影像数据中存储的多时相问题,但并没有考虑数据的插入效率。文献[8]在文献[7]的基础上,设计了基于Key-Value的分层索引结构,在保持高容错能力和高可用性的同时保持高插入吞吐量和大数据量。但是,分层的索引结构加大了索引的存储空间,当数据量大时不利于管理。为了缩小索引空间,文献[9]则将四叉树与网格索引分别作为主要和次要索引,整体索引所需要的空间也更小,且在范围查询时具有高效的性能,然而这种方法的查询时间较长。为了缩短查询时间,文献[10]设计了二级索引机制,在减少查询时间的同时支持对地理位置的高并发访问。文献[11]在文献[10]基础上利用协处理器实现了二次索引,实现了基于HBase的气象数据分布式实时查询方案,有效地缩短了查询时间。上述方法均是利用二级索引来缩短空间数据查询时间,对遥感影像数据的研究较少且较少考虑利用遥感影像本身特点对HBase存储模型进行优化。因此,本文提出了一种基于HBase的分布式存储与查询方法。该方法利用MapReduce并行计算框架和HBase对于非结构化数据的存储优势构建了遥感影像存储模型。
2 影像数据的存储模型设计
为了实现对影像数据的分布式存储,本文在传统瓦片金字塔的影像数据存储的基础上,设计了适合影像数据存储的HBase模型。通过对影像数据建立索引和元数据描述,提高了影像数据的处理效率。另外,通过设计过滤列族达到了筛选数据的目的,从而提高了查询的准确率。
2.1 影像数据的划分
影像数据分块组织中最常用的方法是建立具有多尺度层级结构特征的格网影像金字塔模型,使用户能够根据需要对特定分辨率层级、特定空间区域范围的影像块进行访问[12]。传统的倍率方法[13]通过2n×2n大小的原始影像进行分层操作,本文对上述方法进行改进,可以使其对任意分辨率的影像进行分层分块操作。
假设原始影像的分辨率为n×m,瓦片的大小为 2p×2p(p=0,1,2,…),则需要构建的金字塔层数L=min(L1,L2)。
其中L1需要满足:
(1)
同理,L2需要满足:
(2)
得到不同层次的影像层之后,采用均匀网格法对每层影像进行划分。在瓦片划分过程中如果存在不足2p×2p像素的“尾块”时,可先对其补全再进行剖分。其中 “尾块”的大小TailX和TailY可由下列公式获得。
TailX=2-k×n-(2-k×nmod 2p)
(3)
TailY=2-k×n-(2-k×mmod 2p)
(4)
其中,k代表瓦片数据所在的影像层,n和m代表原始图像的分辨率,mod为取余函数,2p代表瓦块的大小。在本文中2p=128 与ArcSDE建立影像金字塔时默认的块大小一致。

Figure 1 Division of image data图1 影像数据的划分
由图1可知,在对影像数据分层处理之后,选取任意一层的影像数据进行网格划分,当出现“尾块”时通过公式(3)和公式(4)得到“尾块”的大小,通过向左平移进行补全。
2.2 遥感数据存储模型
本文基于Key-Value的存储结构并结合分布式数据库HBase的存储特点,将网格ID和Hilbert曲线结合后的值作为key,每个瓦片的描述信息分别作为value,组成〈keym,valuem〉键值对,对应地存储在不同的列中。
影像数据的存储模型如表1所示,表中的元数据区存储每层影像的元数据,用于在检索时快速得到该层影像的描述,缩短查询时间;主数据区用于存放该影像数据的全部瓦片信息。其中GeoInfo列族用于存放该瓦片数据的描述信息,Filter列族用于存放数据过滤信息。
2.2.1 元数据的设计
基于HDFS存储的影像数据,通常将元数据的相关信息存储在Master节点的内存中[14]。为了提高数据的存储和查询效率,本文将每层影像的元数据信息存储在HBase表中,在查询时可以快速得到该层影像的描述信息。
每层影像的元数据包括四个信息,分别是该影像数据所在的层号k、该层瓦片数据的分辨率X=n×2-k和Y=m×2-k、该层影像数据的经纬度范围以及该层瓦片的真实坐标的横向跨度TileSpanX和纵向跨度TileSpanY。其中瓦片的TileSpanX和TileSpanY可由以下公式获得:
(5)
(6)
其中,(Xmin,Ymin),(Xmax,Ymax)分别代表该影像数据的起始经纬度坐标,k代表该瓦片所在的影像层,L代表该影像数据金字塔的总层数。
2.2.2 索引建立
本文通过对每层影像数据构建索引,达到了提高数据查询效率的目的。传统的基于HBase的存储方法采用将查询条件拼接到RowKey中的方法,进行多条件查询。但是,这种方法导致索引所需的空间随着查询条件的增加而增多。在遥感数据存储中,这种方法没有考虑到数据的空间临近性,从而导致了遥感数据空间位置的跳跃,增加了查询时间。
为了保证遥感数据的空间临近性,本文在利用网格对影像进行划分的基础上使用Hilbert曲线进行填充。由于在HBase中,RowKey是按照字典排序进行存储的,因此需要对Hilbert值进行转化,最终RowKey的值为:
RowKey=k+L(L(φ))+L(φ)+φ
(7)
其中,k代表了当前遥感影像所在的层,L(x)表示当前x的长度,φ表示当前网格所在的Hibert编码,“+”用来分割每个字符串。这种方法在保证影像数据空间临近性的同时,缩小了索引所需要的空间。
改进后的索引结构在HBase表中的存储结构如图2所示。其中图2a表示瓦片数据在网格中的位置;图2b表示经Hilbert填充后得到的改进的HID值;图2c表示网格中第0层瓦片数据在HBase表中的存放位置。
由图2c可知,数据在HBase表中的存放按照改进后Hilbert编码的值由大到小依次排列,这样保证了在分割region时,可以将空间位置相邻的影像数据存储在相同region中。因此,可以看出经改进后的索引在HBase表中具有较高的空间临近性。

Table 1 Image data storage model表1 影像数据存储模型

Figure 2 Index and HBase table mapping图2 索引与HBase表映射图
2.2.3 过滤列族的设计
为了在检索中过滤掉不相关的数据,我们设计了过滤列族,实现了数据在服务器端的过滤。过滤列族中存放当前瓦片的中心经纬度坐标,其值可由下列公式得到:
(8)
(9)
其中,(Xmin,Ymin)代表影像数据的起始经纬度坐标;(x,y)代表该瓦片数据所在的网格坐标;(TileSpanX,TileSpanY)为该层影像瓦片的横纵坐标跨度,其在HBase中存储的逻辑视图如表2所示。

Table 2 Design of filter family表2 过滤列族的设计
3 影像数据的并行处理
本文设计了一种基于MapReduce的影像数据写入和查询方法,对分层分块处理后的影像数据进行并行处理,有效地提高了影像数据的处理效率。
3.1 影像数据的并行写入
MapReduce是Hadoop的开源计算框架,它遵守分治原则,通过迁移计算使每台机器可以尽快访问和处理数据。HBase最大的特点之一就是可以和MapReduce紧密结合,在数据的入库处理中,我们只需要实现setup方法和map方法即可。其中setup方法负责初始化数据信息和共享数据信息,map方法用于将数据写入到HBase中,其具体流程如图3所示。

Figure 3 Parallel framework of image data storage图3 影像数据并行入库框架
由图3可知,此过程中大部分操作都是在存储瓦片数据的本地节点执行,DataNode节点和Master节点只有少量的信息交换。具体算法伪代码如算法1所示。
算法1影像数据的并行写入
但是,另一种情况更可能发生,甲把乙说的话完全理解成了另一个样子,甚至可能与原意相反。这也就导致另一种让人无奈的现象产生:人们只能听到自己想听到的,只能看到自己想看到的。然而,模式拼接能力也不是全然无用的东西,否则我们的大脑就不会进化出这种能力了。
输入:影像数据的所有信息。
输出:HBase 数据表。
setup(Mapper.context){
initGridID[][] andHilbert[][]← compute(by the level);
initargs[] ←context.getConfiguration();/*通过context传递信息,初始化表的信息*/
}
map(key,value,context){
// 得到瓦片的行键
RowKey=getRowKey(key);
//将图片转化为BASE64编码
ImageValue=value.toBASE64();
// 将瓦片信息存放到put中
Putput=getPut(args[],ImageValue);
// 写入到HBase中
context.write(RowKey,put);
}
}
3.2 影像数据的并行查询
由于HBase将数据分别存放在不同region中,每一个region可以由一台region server即DataNode加载。因此,我们可以使用MapReduce并行处理的方法对影像数据进行查询。在查询过程中,每个节点只需得到当前region中符合查询条件的数据即可,最后通过map函数直接将数据写入到HDFS中。
在进行区域查询时,首先根据输入的信息得到需要查询的影像层。其次,根据读取的该影像层的元数据信息得到本层瓦片的具体描述。然后,根据输入的空间数据的查询范围将其映射到该层网格ID的数组中,从而得到网格范围内对应的RowKey值,以便HBase检索识别。最后,通过重新设计了MapReduce方法中Map函数,对范围内的数据进行并行查询,算法2如下所示。
算法2影像数据的并行区域查询
输入:查询区域的经纬度坐标(x1,y1),(x2,y2)。
输出:该层影像查询范围内的所有瓦片数据。
第一步:get the iamge level;//根据用户输入
第二步:GridID[x][y]← compute(the level;the metadata information);/*根据图层号计算该层影像的网格信息,得到网格存储的经纬度坐标*/
第三步:BinarySearch() Calculatexandyaccording to the input query range;/*根据输入的查询范围,利用二分查找,得到对应的网格坐标*/
第四步:get startRowKeyand stopRowKey←Hilbert[][];/*根据该层网格对应的Hilbert值,得到最大和最小的Hilbert值,并将其转化为起始行键和结束行键*/
第五步:map(key,value){
if(fit(getFilter(value),search(x1,y1,x2,y2)))←{SingleColumnFamily( );/*根据设置的单列值过滤器,决定一行时间是否被过滤*/
key=getrowkey(value);
value=getvalue(image_value);
write(key,value);
}
}
第六步:end
4 实验结果
实验中选取Landsat8 8波段分辨率为15 m的3幅高分辨率影像数据,经处理后影像数据的大小分别为700 MB、1.72 GB和2.64 GB。分别对三幅影像进行数据的并行存储与查询实验,以验证本文所提方法的效率。
4.1 实验环境
本实验采用虚拟软件XenServer6.2将3台曙光 I450-G10塔式服务器(Intel Xeon E5-2407四核2.2 GHz处理器,8 GB内存)虚拟成9台主机,一台HP Compaq dx2308(Intel Pentium E2160 1.8 GHz处理器,1 GB内存)作为Master。每台虚拟机装有ZooKeeper 3.4.8版本,HBase的版本为0.98.23,Hadoop版本为2.7.2,在Cenos6.4_final(内核2.6.32)系统上搭建起Hadoop的cloud cluster,HDFS总大小为450 GB。
4.2 影像数据入库实验
在遥感影像数据的入库实验中,我们将三幅影像分层分块后,分别在9个节点的情况下对影像进行数据入库操作。由表3可知,当数据量增大时,每秒的写入速率有所增加,这是因为减少了单位数据量的写入,但是总体保持稳定。当数据量越大时,HBase写入数据region会发生分割操作,这是耗时的主要原因。

Table 3 Time consumption表3 遥感影像导入HBase 消耗时间
为了验证不同节点个数对数据写入效果的影响,我们分别采用不同节点对三幅影像进行入库操作。由图4可知,随着节点数量的增加,数据的入库时间缩短。数据量越大,入库时间减少越明显。当节点数较少时,数据导入时间较长,这是因为单个节点可能存储几个region,导致其负载较重,从而时间较长。image1影像由1个节点到4个节点的时间变化最为明显,在6个节点之后,入库时间几乎持平。这是因为数据image1数据量较小,HBase表需要划分的region较少。当表不再切割时,region只存在固定的几个节点中,从而导致节点数量增加,但是影响写入数据的时间变化并不明显。
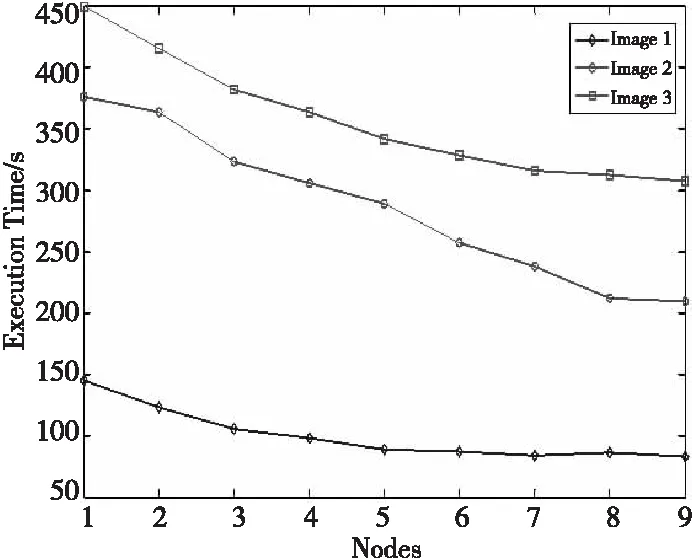
Figure 4 Data import time of different nodes图4 不同节点数据导入时间
4.3 影像数据查询实验
我们分别采用基于键值对的MapFile、MySQL集群和本文设计的基于MapReduce的HBase(简称MRHBase)进行对比分析。我们选择image3影像中分辨率最大的一层作为查询对象,分别将整幅影像占比为10%~80%作为输入的查询范围,测试数据的查询时间。由图5可知,MRHBase在不同区域的查询时间增长最为缓慢,MapFile增长最快。当查询区域小于20%时,MySQL集群的查询时间和HBase集群并行查询时间相差不多,但是当查询范围增大时,MRHBase查询时间的增长速度远低于MySQL。其中MapFile的查询性能最差,这是因为MapFile在读取文件时通过调用get()方法随机访问文件中的数据,当数据增大时查询时间将会越来越长。由此可以发现,数据量越大,MRHBase的效果越明显。
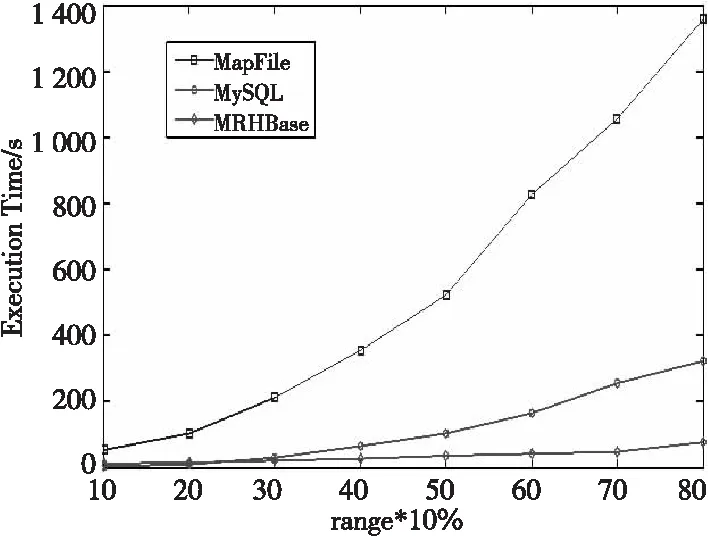
Figure 5 Query time in different areas图5 不同区域的查询时间
为了验证MRHBase的可扩展性,我们分别使用不同的节点对image3影像中分辨率最大的一层进行查询,其中查询区域包含的瓦片数量约为32 768张,大小约786.8 MB。由图6可知,随着节点的增加查询时间逐渐减少,节点由1到3查询时间呈线性减少。当节点数由3到6时,查询时间下降速度最快。通过查看HBase表的分区可知,region的个数为6且均匀分布在不同的节点之上,所以每个节点可以同时查询当前region下的数据。当节点继续增加时,此时需要从已存在region的节点中读取数据,导致总体减少时间缓慢。

Figure 6 Query time for different node numbers图6 不同节点个数查询时间
5 结束语
本文将Hilbert曲线与网格索引相结合,利用HBase分布式数据库的特点,对影像数据的存储进行研究。通过重新设计HBase的索引和表的存储模式,保证了影像数据的空间临近性。实验结果表明,与MapFile和MySQL相比,本文方法具有更好的查询效率和可扩展性。
[1] Yang R,Ramapriyan H,Meyer C.Data access and data systems[M]∥Advanced Geoinformation Science,Boca Raton:CRC Press Inc,2010.
[2] Güting R H. An introduction to spatial database systems[J].The VLDB Journal,1994,3(4):357-399.
[3] Kothuri R K V,Ravada S,Abugov D.Quadtree and R-tree indexes in oracle spatial:A comparison using GIS data[C]∥Proc of ACM SIGMOD International Conference on Management of Data,2002:546-557.
[4] Zheng K,Fu Y.Research on vector spatial sata storage schema based on Hadoop platform[J].International Journal of Database Theory & Application,2013,6(5):85-94.
[5] Zhong Y,Sun S,Liao H,et al.A novel method to manage very large raster data on distributed key-value storage system[C]∥Proc of International Conference on Geoinformatics,2011:1-6.
[6] Chi Z,Zhang F,Du Z,et al.Cloud storage of massive remote sensing data based on distributed file system[C]∥Proc of IEEE International Conference on Signal Processing,Communication and Computing,2013:1-4.
[7] Rajak R,Raveendran D,Bh M C,et al.High resolution satellite image processing using Hadoop framework[C]∥Proc of IEEE International Conference on Cloud Computing in Emerging Markets,2015:16-21.
[8] Nishimura S,Das S,Agrawal D,et al.MD-HBase:A scalable multi-dimensional data infrastructure for location aware services[C]∥Proc of IEEE International Conference on Mobile Data Management,2011:7-16.
[9] Han D,Stroulia E.HGrid:A data model for large geospatial data sets in HBase[C]∥Proc of IEEE the 6th International Conference on Cloud Computing,2014:910-917.
[10] Zhang N,Zheng G,Chen H,et al.HBaseSpatial:A scalable spatial data storage based on HBase[C]∥Proc of International Conference on Trust,Security and Privacy in Computing and Communications,2014:644-651.
[11] Ma T,Xu X,Tang M,et al.MHBase:A distributed real-time query scheme for meteorological data based on HBase[J].Future Internet,2016,8(1):6.
[12] Xia Y,Yang X.Remote sensing image data storage and search method based on pyramid model in cloud[C]∥Proc of International Conference on Rough Sets and Knowledge Technology,2012:267-275.
[13] Wei X,Lu X,Sun H.Fast view of mass remote sensing images based-on image pyramid[C]∥Proc of International Conference on Intelligent Networks and Intelligent Systems,2008:461-464.
[14] Zhang G,Xie C,Shi L,et al.A tile-based scalable raster data management system based on HDFS[C]∥Proc of International Conference on Geoinformatics,2012:1-4.
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
浙江大学学报(理学版)(2020年1期)2020-03-12
电子制作(2019年13期)2020-01-14
数学年刊A辑(中文版)(2019年3期)2019-10-08
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2017年6期)2017-11-23
浙江大学学报(工学版)(2016年10期)2016-06-05
