
大数据:深调制与不透明表征①
2018-07-05 09:21:14拉斐尔阿尔瓦拉多保罗汉弗莱斯文薛永红
哲学分析 2018年3期
关键词:数据库
[美]拉斐尔·阿尔瓦拉多 [美]保罗·汉弗莱斯/文薛永红/译
一、引 言
“大数据”一词大约于1995年开始使用,其含义在2008年发生了根本性的变化:从运用大规模数据集发现并解决问题的一种方法,一跃成为建构新兴经济和文化秩序的“法宝”。它对人类所产生的深刻、普遍的影响,在让人欢欣鼓舞的同时,也让人忧心忡忡。从经济的角度来看,目前“大数据”指代一种以数据为媒介的商业形式(以谷歌为代表),它把从大规模网络中生成、收集的数据用于机器学习,从而使其成为互联网的实际中心。从文化的角度来看,该词则代表一种新的知识和知识生产的形式,《连线》 (Wired)杂志的主编克里斯·安德森(Chris Anderson)在《科学理论的终结》一文中对此就有所阐述。①C. Anderson, “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete”, Wired, Vol.16,No.7, 2008, p.17.本文中,我们将从实际社会和科学变革的可观察属性的维度探讨这两种含义以及它们之间的联系。为此,我们将引入三个核心概念:数据域(datasphere)、深调制(thick mediation)以及不透明表征(representational opacity)。这三个概念作为一个理论框架,可以帮助我们理解大数据在经济和文化维度上——一个是地方性和生成性的,另一个是全球性的和涌现性的——如何交互以及在交互过程中产生的一系列的后果、问题和机遇。
二、从小写的大数据到大写的大数据
虽然很难为“大数据”给出一个抽象的定义,但这个词的概念源起具有清晰的历史脉络。“大数据”这个词最早出现在20世纪90年代,当时各行业和各门科学广泛地使用数据采集和数据存储设备——从计算机科学仪器和收银机到关系数据库和数据仓库——使得难以控制的数据流汇集成了海量数据。为了实现大数据集中挖掘并发掘其中潜在的认知模式和商业价值,对于这些数据的组织与处理就变得十分迫切,数据挖掘应运而生。此后,这种知识挖掘的有效模式被迅速崛起的谷歌演绎得淋漓尽致。1991年通过的《高性能计算法案》解除了对互联网的监管,之后,谷歌采用了数据挖掘技术来应对互联网爆炸式增长所带来的问题,取得了瞩目的成果。②我们将“互联网”视为一个专有名词,它的前身是阿帕网(APPANET)。2008年,《自然》和《连线》杂志均围绕“大数据”这一主题组织了关于谷歌的讨论,然而主题并不是讨论它在管理和开发大数据方面所取得的成功经验,而是将谷歌作为一个科学研究的典范,讨论人类能从它身上学到什么。此后,大数据的概念不仅涵盖了一套完整而又行之有效的数据处理方法(大致对应数据科学和机器学习领域),而且作为一种发现科学知识的新工具为人们所理解。
沿着这条发展线索,大数据逐渐派生出了两种广泛的含义,我们称之为小写的大数据(big data)和大写的大数据(Big Data)。小写的“大数据”指的是拥有海量数据的组织机构所面临的技术问题。尽管在这个意义上它通常指的就是数据集本身,并强调其复杂性以及庞大的体量,但该术语更多地被用作一种代表,即代表在诸如天体物理学、生物信息学和其他领域成功应用相关方法获取数据流的科学学科以及在商业领域的消费分析等。准确地说,我们将小写的“大数据”一词视为与数据科学相关的活动和方法,因为这些数据集太大以至于不能用传统方法进行分析。
当这些活动和方法向社会各领域渗透并迅速发展——尤其是在经济和文化领域,便产生了大写的大数据。在经济上,这个术语表示以数据为中介的商业形式,包括大量的基于数据建立的公司与业务,谷歌就是其典型代表。在文化上,这个术语代表了一种由数据科学研究者所倡导的新的知识和知识生产方式。这两个方面无疑是相互联系的:大数据在经济领域产生的数据在内容上具有社会性和文化性。大数据组织和收集到的人类行为数据——从整个图书馆的数字化和通过交易得到的公共机构的数据(如使用信用卡或谷歌搜索)到从社交媒体抓取到的数据——在数量上大大超过了通过传统的方法如调查研究、参与观察、档案记录等所获取的数据。这些数据不仅规模庞大,而且涉及范围广,包括精确且详尽的行为痕迹(比如通过扫描卡或社交媒体而追踪到的关于消费者的数据)。显然,如果没有相关的技术设备的存在,就无法捕捉这些数据。这种社会性的数据在量和质的方面发生了根本性变化,这就对技术和文化提出了巨大的挑战。因此,大写的大数据是人文主义者和社会科学家所关注的领域。
三、数据域(Datasphere)
大写的大数据可以被认为是小写的大数据的经济和文化转向,因此会使社会组织的知识结构产生历史性的变革。这种转向是基于近几十年来发展、渗透在全球各领域和组织的巨大的电子网络所生产的数据之上的,包括政府、医药、金融、教育和商业。这个网络既不是抽象的,也不是虚拟的,它是在人类生物圈内发展起来的、具备技术和社会因素的具体结构,并且具有与卡尔·波兰尼(Karl Polanyi)在《大转型》 (The Great Transformation)中所描述的自由市场相似的空间结构,只是规模更大一些。①K. Polanyi, The Great Transformation: The Political and Economic Origins of our Time, Boston: Beacon, 1957.这个网络结构有许多其他的名称,例如,文学作品中吉布森(William Gibson)的“网络空间”概念,社会科学中卡斯特(Manuel Casetells)的“流动空间”概念以及祖博夫(Shoshana Zuboff)的“监督资本主义”概念等。①W. Gibson, “Burning Chrome”, Omni,Vol.4, No.10, 1982, pp.72—77; M. Castells, “The Space of Flows”, The Information Age: Economy,Society, and Culture(Vol.1),Cambridge, MA: Wiley-Blackwell, 1996, pp. 376—423; S.Zuboff, “Big Other: Surveillance Capitalism and the Prospects of an Information Civilization”, in Journal of Information Technology,Vol.30, No. 1, 2015, pp.75—89.所有这些含义都是有价值的,它们就像一个个透镜,透视着人类社会的众多维度,我们将其称之为数据域——一个由洛西克夫(Rushkoff)提出并被加芬克尔(Garfinkel)清晰地下过定义的术语,它指的是“对机器可读数据的收集、聚合和使用的基础设施”②D.Rushkoff, Media Virus!: Hidden Agendas in Popular Culture, New York: Ballantine Books, 1994; S.Garfinkel,Database Nation: The Death of Privacy in the 21st Century, Beijing: O’Reilly Media, 2000.。
数据域作为一种社会建制,从许多相互独立的领域及其相互联合的进程中涌现并嵌入其中,如计算思维的发展、自然科学和社会科学中的统计方法及各种世界假说的兴起、对用于组织和管理人口的各种记录的使用(包括纸质记录和电子记录)以及以计算设备为基础的用于数据共享的通信网络的建构等。数据域的许多文化效应并不是新事物,例如对信息超载的焦虑和对海量数据所带来的变革的乐观信念。数据域的独特之处在于,它将之前的信息实践结合到目前最新的、具备前所未有的规模和力量的计算机基础设施之中。为了满足生产和控制信息的需求,这些基础设施被合并到组织内部,由此首先产生了小写的大数据,继而为大写大数据的许多独特属性做了铺垫和规定。如果没有这些基础设施,就不可能有这种形式的数据积累,也无法使数据的挖掘和使用成为一种新的知识形式。正是因为数据域的存在,才使大数据能够以两种形式存在。最后,数据域通过全球网络化的商业和协作模式得到扩展,这些模式可以通过网络实现(如商业网站),还可以通过开放源代码软件等进行协作实践。在Web 2.0阶段,用户生成内容(UGC)的交互式网站变得很普遍,数据域在社交互动层面有了一系列的创新和发展,其中包括Facebook和Twitter等社交媒体平台、零售平台、博客圈、书签网站和移动计算设备,这些设备可以随时随地将用户连接到这些平台上。近来,数据域已经包含了新的参与平台,这就使得以Uber、Airbnb、维基解密、物联网、云计算、开源数据为代表的“零工经济” (gig economy)成为可能。
总之,数据域是历史建构的、分布在不同地理位置上的、社交性的网络,人与机器在此网络中进行数据交换。我们将这个网络视为一种拉图尔(Bruno Latour)意义上的行动者网络:它作为共同参与者,包括了人与机器之间的一系列交流,并产生了我们与特定社会、文化以及体系相联结的独特的互动模式。③B. Latour, Reassembling the Social: An Introduction to Actor-Network-Theory, Oxford: Oxford University Press,2005.与本质上的社交网络的异常特征不同,技术要素作为中介建构了人与人之间的关系。正如人类学家迈克尔·韦斯(Michael Wesch)所言,按照语言人类学的概念,每个新的数字平台(如Facebook,Snapchat或Uber)都会创建自己独有的参与者结构,将人们整合于包含具体社会关系和角色的特定序列之中。①N. L. Whitehead and M.Wesch, Human No More: Digital Subjectivities, Unhuman Subjects, and the End of Anthropology, Boulder: Univ. Press of Colorado, 2012; H.A. Innis, Empire and Communications,Oxford:Clarendon, 1950.在这个网络中,计算机的作用与多年前哈罗德·伊尼斯(Harold Innis)提出的原则一致,即媒体形式和交流方式塑造了社会关系,甚至如本尼迪克特·安德森(Benedict Anderson)在《想象的共同体》中所言,它在一定程度上形成了一个国家的民族特性。
表征数据域的参与结构通过在软件中执行编码并在硬件约束下运行规则得以生成。譬如像Facebook之类的社交媒体平台,是通过硬件和软件建立人类参与者(“朋友”)之间的对称关系网络来实现个人之间的沟通的。由此产生的社交网络,从用户的角度来看,具有或多或少的扁平化和非等级属性。与此相反,Twitter通过非对称“跟随”的逻辑建立关系,进而形成网络,用户可以通过将关注者的比例最大化来构建层级结构。
除结构性结果外,还有与使用媒体形式有关的特定的社会进程。在数据域中,典型的社会进程开始于对一些基本人类行为模式的表征和捕捉,这类行为一般是一些基本交易事件(例如打一次电话或进行一次购买),这类事件可以转化为数据,我们就称之为数据捕获事件。②需要强调的是,尽管我们把注意力放在人类这一因素上,但是数据域不仅仅局限于人与人、人与机器之间的交互。自动出租车的运行、军用无人机对信息的收集、熊入侵的视频图像等,所有这些内容都是数据域的组成部分。在每个数据捕获事件中,行为被转换并打包成具有元数据内容的自包含信息。通常情况下,可用的元数据包括事件的具体时间(秒)、地理位置(米)以及电话号码或电子邮件地址等形式的个人标识符。一旦这些数据被捕获和打包成功,捕获设备就会通过一系列通道(如WiFi集线器,光纤电缆和蜂窝塔)将这些数据发送到云端的服务器。数据包作为离散记录或“观察结果” (从数据中获取相应模式的分析员如此称呼此类数据)进入并储存在云端数据库中。在数据库中,单个数据包将与以相同方式捕获的其他数据包聚合。在这一过程中,数据将会到达一个临时的终端。数据库通常由首先创建数据捕获事件的组织拥有,如应用程序的所有者、信用卡公司或二者的组合。捕获的数据包将成为在此类组织内部使用的大量数据中的一部分——它将成为该组织历史记录的一部分,或者可能成为季度报告中聚合数据点的一部分。
在大数据时代,这些数据并不会长期停留在数据仓库中。它们将与组织的数据仓库或“湖”中的其他数据集相结合,或者出售给另一个组织。然后,数据工程师对数据进行清理并将其转化为数据分析人员可分析的形式。数据分析人员通过先进的分析方法对数据进行挖掘,以发现数据之间的关联。他们将挖掘到的结果或转交给执行官做出决定,或推送给其他算法以用于其他分析目的,或将其反馈到数据产品中并重新传输回数据捕获站点。例如,他们将个人的社交媒体帖子与他或她的朋友组群信息结合在一起进行分析,分析结果将用于构建该人能看到的推送,这反过来又会刺激另一个消息的发生,即另一个数据捕获事件。
这一过程具备一种叙事性的特质,反映为布朗和杜古德(John Seely Brown and Paul Duguid)所述的“信息社会生活”:数据在移动——从数据捕获阶段到数据聚合阶段,之后是数据分析阶段以及其他的数据运用阶段。①J. S. Brown and P. Duguid, “Mysteries of the Region: Knowledge Dynamics in Silicon Valley”, in The Silicon Valley Edge: Habitat for Innovation and Entrepreneurship, edited by Chong-Moon Lee, W. F. Miller, M. G. Hancock and H. S. Rowen, Stanford, CA: Stanford University Press, 2000, pp.16—45.这个过程说明了大写大数据与小写大数据二者间的重要区别。在自然科学领域中收集和处理极大的数据集时,只存在从世界到数据收集器的单向通道。当我们使用科学研究的结果来改变自然世界时,虽然工程学上可能会有一些例外,但在某些自然科学领域如天体物理学中,数据收集行为并不会影响星系本身。而在大写大数据的许多领域,存在信息和影响间的双向流动。例如,社交媒体公司可能会收集青少年的数据,然后利用(并出售)这些数据来重塑他们的购买习惯和娱乐偏好。同样,政党和政府收集有关选民的数据,并使用这些数据分析产品来影响个人的投票决定。这也就意味着,大写的大数据涉及观察者与观察者之间的反馈关系,而小写的大数据通常不会。
这些结构和过程中的细节与生成它们的媒体平台一样多变,但是若将之视为同一类别进行分析,则存在一个共同模式,其特征可能如图1所示:
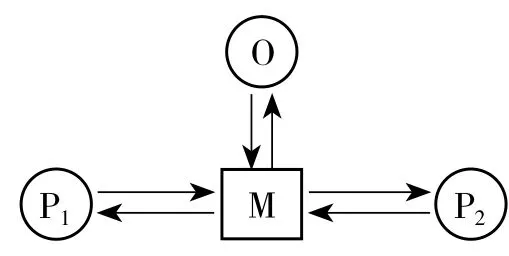
图1 数据域的基本参与结构
该图描绘了包含三类代理方(agent)及相互关系在内的基本参与结构:其中M为参与过程的机器,它介于P1和P2之间,P1和P2代表任意数量的与服务有关的人员,组织O负责托管由M支持的服务。有些读者会注意到,这种结构似乎描述了以计算机为媒介交流(CMC)的典型情况。CMC是20世纪60年代人机交互领域中的一个关键概念,在该领域中,计算机建构和改变了组织和社区中人与人之间的关系。然而,该图中的结构超出了该过程本身所创建的任何一个组织单位的界限。事实上,其所涉及的参与者(P1,P2)之间可能、也往往不认识,更不用说发生面对面的交流。该图说明了自社交媒体革命和Web 2.0时代以来,我们已经意识到了这样一种情况,即人与人之间的通信——从简单的发短信到关注Facebook上的好友以及数字平台提供的其他参与模式——绝不是私密的。即使在我们的想象中,这种人与人之间的通信方式应该移除任何的“中间人”,然而由于第三方(即图中的组织O)的存在,就使得这种非私密通信的状况成为了可能。此外,通信行为以及因这种行为产生的信息存在于这个组织的利益链条之中,就像电话公司为每次通话收费一样,但该组织绝不仅限于在通信服务中获利。所以说,众多社交媒体平台免费的理由与广播网络电视免费的原因相同,这是因为无论是作为此类服务的参与者还是观众,这些人本身就是产品。机器主要促成的是参与者——尤其是参与者的数据——与组织之间的关系,而不是参与者之间的关系。
除此之外,人们很容易得出一种极端的结论:社会媒体以及在数据域内的所有其他的以计算机为媒介的通信手段,其存在的目的都是为了赋予并扩大它们背后的组织的权力,如谷歌和亚马逊,而对用户利益的考量都是次要的或虚妄的。有一种推论认为:大数据是一种新自由主义和全球主义的阴谋,机器扮演着数字双重间谍的角色。此外,还有另一种说法,即大数据和数据科学的支持者们想要说明的是,并非所有的组织都与选民的利益相冲突,或与其他有利益冲突和监管任务的组织毫无往来。事实上,这里所描述的数据流可被用来改善成员与组织之间以及不同组织之间的关系,尤其在医学和教育领域中,大数据都发挥了明显的积极作用。我们面临的挑战是,如何从物料和可操作性两个角度调整系统,以使其适应我们共同的需求。
在数据域的基本参与结构中,有一个关键元素非常值得我们关注。从图1可以看出,无论数据如何在使用者之间传递,数据始终停留在中间地带,即某一数据库中。在数据库中,数据不但被存储、聚合,还可被用于他途,而作为参与者通常对此毫不知情。因此,尽管基本参与结构的每个元素都被认为是必不可少的,但我们观察到数据库占据着所有数据最终必然流经的中心和关键路径,其作用就像“曼陀罗” (mandala),将用户的周边关系整合到组织的中心枢纽。产生这种向心性的本质原因是数据库为系统提供了长久记录的空间。如果没有数据库的存在,所有的通信都是短暂的,即使我们想要如上文所述,将个体行为所产生的数据聚合转换成数据包,都是不可能实现的。我们很难估计这个元素的重要性。作为流动在数据域中的数据的中心存储库,数据库的功能与以读写能力为基础的社会和组织中的编写系统的功能相同。自旧石器时代以来,这种事情就一直在人类社会中上演。这是自计算机被引入公司以来,各组织投入的基本记录技术,它是在编程语言、算法和应用软件等更为多变的潮流基础上形成的信息管理的基石。基于此,我们认为数据库是真正的书写和印刷技术的继承者。①祖博夫认为,数据库在组织中起着一种文本的功能,在 In the Age of the Smart Machine: The Future of Work and Power (New York: Basic Books, 1988)一书中,他将数据库描述为一种电子文本,发挥着“信息化”的功能,与工业机器的“自动化”过程类似。在该书中,祖博夫还根据口述与读写的相关理论详细地阐述了数据库的功能与作用。
四、深调制
如果数据库在人们的网络中扮演“文本”的作用,那么我们可以将数据库在媒介传播中所做的工作描述为语言人类学家使用的另一个术语——文本化(entextualization)。所谓的“文本化”指的是将短暂的话语转化为持续的媒介形式(如写作、歌曲)的过程,其影响社会生活的能力超越了话语的原始语境。因此,数据库介入通信的一个关键作用是它会将人类的互动行为文本化,而在传统媒体渠道(如电话)中这是不可能实现的,除非线路被监听或窃听。这种持续的、实时的、无处不在的文本化的工作,使数据库介入的通信方式与其他的通信方式明显不同。因此,基于这种通信方式的数据域在历史上也是独一无二的。
从参与消息传递的两个人(P1和P2)的角度来看,通过诸如移动电话等设备进行的通信或多或少是透明(transparent conversation)的。机器提供了用以发送和接收消息的清晰通道,如电话和电报。由于这些技术的目标是忠实地将消息从发送方复制到接收方,因此我们可以说,这些技术对信息所做的是一种浅调制(thin mediation),意味着在某种程度上,信息双方成功地摆脱了通信方式本身。香农(Claude Shannon)的通信模型正体现了这种特征:通信工程师的最高目标是消除信号通过信道时所产生的噪声。②C. E. Shannon, “A Mathematical Theory of Communication”, ACM SIGMOBILE Mobile Computing and Communications Review, Vol.5,No. 1, 2001, pp. 3—55.然而,由于数据域中的信息被文本化并存储在数据库中,在数据库中又被塑造、处理和重定向到与原始会话无关的第三方,交流行为因此发生了根本性的改变。我们把这种通信方式称为深调制(thick mediation)。在这种通信方式下,启用信号通道的目的不是为了摆脱这种方式,恰恰相反,是要从根本上重塑信息,因此其对信息本身做的是一种深度的调制行为,这一事实为马歇尔·麦克卢汉(Marshall McLuhan)的著名论断赋予了新的含义。③指加拿大著名传播学家马歇尔·麦克卢汉(Marshall Mcluhan,1911—1980年)对媒介的论断,最著名的有:“媒介就是信息”“媒介是人体的延伸”等。——译者我们不能简单地认为媒介自身就带有信息,而是媒介塑造和放大了信息。
如果数据库介入的通信是深调制,那么信道的宽度以及参与者结构是数据库文本性质的函数,人类学家伊兰娜·格尔森(Ilana Gershon)也认为,新媒体形式的参与者结构是媒体形式固有属性的函数,但是受用户感知与执行方式的约束。①I. Gershon, “Language and the Newness of Media”, Annual Review of Anthropology, Vol.46, No.1, 2017,pp.15—31.因此,要了解深调制的影响,我们应该探索数据库作为媒体形式的属性以及基本参与者结构如何感知和利用这些属性。
在数据库内在属性的研究方面,列夫·曼诺维奇(Lev Manovich)将数据库看作是“一种象征形式”,我们认为他的这一开创性工作非常有价值。②L. Manovich, “Database as Symbolic Form”, Convergence, Vol.5, No. 2, 1999, pp.80—99.“数据库逻辑”与历史和文学文本的叙事逻辑相反,曼诺维奇描述了“数据库逻辑”的通用属性:在数据库中,内容的顺序并不重要(其顺序是“随机存取”);工作本身并没有任何开端或结局,而且其信息在结构上是聚合的(而不是组合关系的)。有趣的是,曼诺维奇的观点具体地体现了几年前利奥塔(Jean-François Lyotard)在《后现代状态》中所预期的计算机知识的反叙事特质。③J. F. Lyotard, The Postmodern Condition: A Report on Knowledge, translated by G. Bennington and B. Massumi,Minneapolis: University of Minnesota Press, 1984.在此基础上,我们可以再增加以下几点:数据库的文本是一个个单独提供的信息的聚合;原始数据生成行为的唯一性将丢失,因为与该行为相关联的转发和打包行为使数据变成一组相似的数据[以瓦尔特·本杰明(Walter Benjamin)在《机械复制时代的艺术作品》中所描述的“韵味的消散”的方式];该行为使数据的语境减少从而成为元数据;数据库的内容可以是数字的、分类的或语言上碎片化的;每一个数据的实例都必须遵循一个固定架构所定义的结构;这些数据能被机器读取,并能被人类用特殊的语言查询等。
鉴于这些属性,数据库所介入的信息交互关系中的参与者根据他们如何解释和行为来承担某些角色。因此,对参与结构所产生的结果需要作实证研究。在这里,我们还注意到,数据库文本的受众从来不是对话的参与者,他们只贡献和接收数据库整体文本的一小部分——作为参与结构的各方即组织或准组织,构成了所谓的“B2B” (企业对企业)的关系。对数据域中的组织及其共同参与者来说,数据库文本就是大写的大数据。
除了上文所述的参与结构外,我们还必须注意到另外一个事实,即数据库作为社交纽带处于另一类比社交媒体更为普遍(或至少存在这种可能)的参与结构的核心位置,而这两件事实共同放大了大数据作为人类行为文本化积累的意义。以上,我们描述了及物性(transitive structure)的参与结构——在这种结构中一个参与者和一个直接对象(另一个参与者)进行交互;除此之外,还有我们可以称之为非及物性(intransitive structure)的参与结构。从用户的角度来看,这种非及物性交互形式的发生不涉及直接对象。人们通过与传感器和监视设备交互,从而产生此类参与结构中的数据捕获事件。如今,这些传感器和监视设备已经变得越来越普遍,并嵌入到日常生活和工作当中——从汽车到咖啡机、垃圾桶到血糖仪,这些嵌入式设备在物联网上的增长标志着数据域在社会生活中的延伸,以至于我们的生活被这种媒介包围,就像细胞外基质中的生物细胞一样。此外,这种“基质”还包括以前的内容:由于Google Books和Hathi Trust等项目以及数不清的数字人文主义者——他们至少在过去的30年里一直在创造数字档案——的工作,大量前数字媒体形式(如书籍和绘画)的历史资料被整理为数据库的形式。
在深调制所产生的众多认知论后果中,我们特别感兴趣的是它对利奥塔曾经称之为“信息化社会中的知识”的影响。①Lyotard, The Postmodern Condition: A Report on knowledge, p.xiii.自大数据崛起以来,这些影响并没有被忽视。我们已经注意到克里斯·安德森(Chris Anderson)那极端的观点——谷歌改变了科学研究方法;如尼古拉斯·卡尔(Nicholas Carr)的黑色幽默所言,谷歌改变了我们的想法,并且可能“使我们变得愚蠢”。安德森在《科学理论的终结》一文中的观点与卡尔的观察结果非常接近,即在文学中,网络提供的碎片化的和浅层的阅读材料,使人们已经放弃了长篇、持续的阅读方式。②N. Carr,“ Is Google Making Us Stupid? ” in The Atlantic Monthly, Jul/Aug 2008. https://www.theatlantic.com/magazine/archive/2008/07/is-google-making-us-stupid/306868/.所有这些结果与对这一现象——数据库介入的通信方式改变了我们生产和消费知识的方式——的评价都截然不同。
此外,在对曼诺维奇的数据库逻辑概念的平行思考中,克雷·舍基(Clay Shirky)盛赞了由大数据导致的本体论的衰落,他认为与专家的封闭开发、研究相比,会有更有机的组织数据的模式和更加开放的社交媒体平台进行研究。③C.Shirky,“ Ontology Is Overrated: Categories, Links, and Tags”, in Clay Shirky’s Writings About the Internet(blog), 2005, shirky.com/writings/herecomeseverybody/ontology_overrated.html.在数字人文学科中,佛朗科·莫雷蒂(Franco Moretti)宣称“文学批评已经终结”,因为传统上被认为是“精读” (close reading)的文学批评被一种“远距离阅读” (distant reading)实践所取代,这种实践本质上是将统计方法和数据挖掘应用于被视为人造物的小说之中。④F. Moretti, Distant Reading, London: Verso Books, 2013.与此相似,在文学批评领域,泰德·安德伍德(Ted Underwood)也提出了关于“文学时代划分的终结”的观点,而时代划分是文学批评的支柱,是一种对文学进行分类的有用方法。⑤T. Underwood, Why Literary Periods Mattered: Historical Contrast and the Prestige of English Studies, Stanford,CA: Stanford University Press, 2013.可见,在大数据背景下,无论所处领域或评价立场如何,都会描述一种常见的认识论效应,即我们将数据库的调制作为代替文字书写的一种代表性模式。而对机器数据库中所包含的知识的访问需要特殊的技术和表征方式,这些方法与非计算规程中使用的方法和表征方式在本质上有极大的不同。
五、两种不同的表征
以下我们将从认识的不可及性(Epistemic inaccessibility)的概念展开论述。人类获取知识的途径随着时间的推移发生了根本性的变化。当大多数人还目不识丁的时候,只有少数人可以使用知识,但是随着教育的普及,几乎所有人都能接触到知识。而现今,我们正在走向另一种状态,即一个不具备必要的计算能力的人将无法访问数据库中所包含的知识。这不是传统上为人们所熟悉的由经济和教育机会的鸿沟所导致的获取知识的障碍,而是由于技术能力程度所导致的认识论划分。这种认识的不可及性的程度将一直存在,比如对于大多数知识分子来说,他们了解当代分子生物学知识的程度非常有限。但这种认知限制并不是到达认识可及性的唯一障碍。因为专有算法和知识产权法也会阻止人们对数据库的自由访问。当然,互联网所产生的(偶然)信息的开放性在一定程度上消除了这些障碍,但是多数证据业已表明,我们现在正在经历类似于英格兰在18世纪到19世纪初的农业封闭的时期,当时新贵族和地主圈占大量公共用地作为自己的私人土地,从而导致“数据霸权”“数据孤岛”等现象普遍存在。
这些特征使得那些缺乏穿透社会和技术表面的手段的人难以访问大数据。当然,这里还有一个更为深层次的问题:“这些关于数据域的不可及性对于运行它的人来说是否亦是不可知的?”一方面,数据库的规模和复杂性以及处理数据库所需的计算量,可能会对此产生直接的障碍;另一方面,缺乏合适的算法来处理数据也会造成障碍。除此以外,在数据域中有一种不同的认知障碍,那就是表征能力。
有许多不同类型的表征形式,但在这里我们将集中讨论透明和不透明的表征(transparent and opaque representations)。在透明的表征中,我们以一种能被人类进行明确审查、分析、解释和理解的方式来表示系统的状态,并且这些状态之间的转换由具有类似属性的规则来表示;相反则为不透明表征。①我们可以将这些类型细分为语法透明(不透明)和语义透明(不透明)两种,在本文中将不再阐述。就本文而言,如果一个表征在语法上或语义上具有不透明性,那么该表征就被看作是不透明的。我们所熟悉的人文科学的语言表征和自然科学的形式化表征通常是透明的。因为公理化理论方法的主要优点之一是它明确规定了基本原则,并将一个领域的所有知识都归结为这些基本原则,欧几里得的几何理论就是一个典型例子。除了理论之外,科学模型也常常是透明的,就像一个硬币抛掷的序列是可以由伯努利分布来建模一样。模型的每个部分——独立投掷、投掷概率的恒定性等——都被明确地表征。相反,存在一些使用不透明的表征的计算过程,或者其中可能没有使用任何类型的表征。而从人类的角度来看,我们目前不能、甚至永远不能详细了解这些过程是如何表征世界的。
就其性质而言,想要举出不透明表征的例子并不容易,但我们可以给出一个可能具有部分不透明表征的例子(其中只有一部分不透明的表征,并非所有的表征都是不透明的),该表征可能是说明性的。典型的例子如大数据文本分析所使用的主题建模。大数据主题建模是通过机器学习来建构与文本或文本集合相关的统计模型的。统计模型则可以生成一组在文本中出现的单词的概率分布。这些概率分布,不管是好是坏,都被称为“主题”。①关于文本的“主题”是否适应用于统计模型,存在很大争议。我们仅仅在艺术层面使用它,不支持其他用途。假设我们分析的文本是哲学家约翰·斯图亚特·密尔(John Stuart Mill)的作品。一个标准的主题建模程序给出了最有可能的主题词,如人类、男人、道德、生活、女人、存在、社会,鉴于密尔对社会和政治哲学的兴趣,这一主题建模则是一个可以被理解的结果。在另一个主题中,主题词可能是资本、劳动力、工资、生产、土地、增加、成本等,由于密尔经常研究政治经济学,这些主题词很容易被理解为他对这个领域的兴趣。但是如果主题词是方法、实例、效果、差异、原因、协议和案例呢?这些主题词所代表的含义似乎对一般人并不明显,但如果对一个非常精通密尔工作的人而言,这个主题代表了密尔在归纳和因果推理的方法上的研究。此外,还有一些主题词也很重要,如最多、必要、案例、知识、地点、部分、方法等,对于这些主题词,人们可以推测(可能是不确定的)它们反映了什么,也可以通过改变主题的建模方法来生成一个更为“相干”的列表,或者人们可以忽略这个“主题”,比如将其作为统计噪音来处理。②对统计模型所输出的“主题”如何评估,可参见 J. Chang, J. Boyd-Graber, C. Wang, S. Gerrish and D. M.Blei,“ Reading Tea Leaves: How Humans Interpret Topic Models”, Advances in Neural Information Processing Systems, Vol.32, 2009, pp.288—296。
但有趣的是,其中有一种概率分布捕捉到了密尔工作中潜在或隐藏的主题,而这些主题并不是以任何现有的英语单词或短语来表征的。数据处理方法在文本中发现了这些隐藏的统计结构,这种结构对我们人类来说不明显,但在算法方面是很明显的。这种主题结构与其他被捕获的我们所熟悉的主题一样真实,如果我们人类不能解释该主题结构,那么该部分的表征就是不透明的。这正是大数据的核心特征:我们把语言结构换成了统计结构,把透明表征换成了不透明表征。我们申明,这个例子很好地说明了表征的不透明性,但它并不是一个关于深调制的很有说服力的例子。当这种调制确实发生在大数据的语境中时,即使输入和输出具有可预测的强大功能,也可以大大增加由媒介带来的表征的不透明度。豪尔赫·路易斯·博尔赫斯(Jorge Luis Borges)已经给我们展示了一个对什么样的任务看起来是一个具有最低限度的表征透明的或表征自由的解释。他的著名小说《博闻强记的富内斯》中的主人公富内斯(Funes)被描述为一个能记住他所经历的一切的超强记忆力的人,但“我们不要忘记,富内斯几乎不会进行一般的、纯理论的柏拉图式的思维”①J. L. Borges, Labyrinths: Selected Stories and Other Writings, New York: New Directions, 1964, p. 65.。富内斯的情况类似于一个非结构化数据库,我们可以使数据库中的元素之间进行任意关联,但是要从更为一般的概念中推导出这种关联则不可能。我们必须从外部对这些信息强加概念结构从而达到理解。
我们理解的概念与我们不理解的概念之间的差异反映在机器学习中的有监督与无监督学习这两种算法之间。在前者中,数据的分类类别由用户决定,而在后者中则不是,必须要通过溯因。在无监督学习中,任何分组都只由数据点的集合组成——哲学家们称之为谓词的扩展,而在许多情况下,人类并没有熟悉的解释。这种不透明度是小写的大数据及大写的大数据的主要特征,因为数据库的规模迫使人们用计算机处理而不是人为分析。对人类来说,什么是机器的有效表征并不需要对人类透明。在大数据和机器学习的语境下,我们认为透明和不透明(或表征自由)方法之间的差异至少与基于规则和统计学的方法与人工智能的方法之间的差别一样重 要。
因为一些现代的机器学习方法,比如卷积神经网络和递归神经网络使用了不透明的表征,并且具有与熟悉的语言概念不相对应的特征,所以,我们所面临的是这些表征是否会永远不被人类所知,以及某些方法是否表征自由。在缺乏不可证明的证据的情况下,预测一件事情不可能完成是不明智的,而且大数据的发展太迅速以至于它无法做出明确的判断。尽管如此,我们坚持认为,深调制的性质会增加不透明表征的发生率。一种常见的情况是P1传递的数据被O加密。如果O不对P2提供适当的解密软件,那么,M中包含的表征将对P2是不透明的。另一个熟悉但不太明显的例子是医学成像,机器的表征对于人类来说很难理解。在CAT(计算机辅助断层扫描)扫描中,P1是作为患者的潜在肿瘤,P2作为放射技师,O则是将成像设备收集的数据转换为正弦图以便更快计算的软件。正弦图是对来自P1的数据的表征,但它们是人类无法解释的,必须进行逆变换才能被P2理解。②关于CAT扫描的详细解释可参见Humphreys, “X-ray Data and Empirical Content”, in Logic, Methodology and Philosophy of Science XIV: Logic and Science Facing the New Technologies, edited by P. Schroeder-Heister, G.Heinzmann, W. Hodges, P. E.Bour, London: College Publications, 2014。第三个例子是社交媒体行为,它在一定程度上也反映了数据域的某些特征。P1和P2代表参与社交媒体的不同群体的个体,O是一个聚合数据的公司,M使用不透明表征的机器学习来生成对O有用的预测。对于人文学科来说,表征和解释显得非常重要。大数据表征的不透明度所带来的挑战成为某些抵抗机器学习进入人文和社会科学领域的人的一个主要依据。不需要任何表征的立场是有争议的,关于这一点我们在讨论“大数据不需要模型就能取得成功”时已经作了说明。①具有代表性的讨论可参见S. Leonelli, “What Difference Does Quantity Make? On the Epistemology of Big Data in Biology”, Big Data and Society, Vol.1, No.1, 2014, pp.1—11; F. Mazzocchi, “Could Big Data Be the End of Theory in Science?” EMBO Reports, Vol.16, No.10, 2015, pp. 1250—1255。但是,即使在机器学习中使用了模型,由于它们的演化,也往往不能被人类精确地追踪,而且它们只能部分地被人类解释。尽管我们可能对内部模型有部分的理解,但是算法的输出或者内部过程可能在现有的语言中不能构建可识别的描述,就像我们的主题词建模中给出的示例一样。正是在机器内部进行的处理过程是实现转变的重要来源。当深调制的范围是一个悬而未决的问题时,我们猜想:在大多数情况下,应当存在深调制的认识论,并且不透明表征或表征自由的方法将会占据主导地位。
大数据的出现标志着我们认识和表征世界的方式发生了重大转变。和所有新方法的出现一样,比如在17世纪引入的微积分以及在19世纪末发展的统计方法,这些方法的出现使得之前无法处理的极其困难的事情变得易于处理。如微积分的发明使物理学和其他大多数科学都发生了彻底的改变。在微积分发明之前,物理学家和天文学家在很大程度上都依赖几何方法。微积分的发现带动了梯度和拐点等概念的发明,而350年后许多机器学习方法仍然在使用这些数学概念。但发展和应用这些概念需要考虑如何理解关于微积分的新表征。这些表征对人类来说是非常容易接受的,许多解释早已进入了我们的日常用语,如速度、参照系、中位数、异常值等。然而,这些旧用途与今天出现的新用途之间存在着重要的区别,因为现代机器学习方法是针对计算机的需求而不是针对人类量身定制的。
这种变化在19世纪中叶就已经出现,当时非欧几何首先被发展了起来,并且导致了从心理表征到正式数学理论的转变。我们已经逐渐习惯于这种抽象的表征方式,并将其内容融入我们的概念体系之中。尽管这种几何学仅适用于在该领域工作的数学家和物理学家,但其中关于弯曲时空的概念对于我们中的许多人来说都非常熟悉,并且可以通过适当的图形表征和专业教师的讲解而理解。②参见R. P. Feynman, R. B. Leighton and M. L. Sands, The Feynman Lectures on Physics (Vol.2), MA: Addison-Wesley, chapter 42, 1963。因此,现在关键的问题是我们是否可以为机器学习做同样的事情。相关的努力已经在诸如“可解释的人工智能”等方向上展开,虽然并不是所有方法都成问题。③有关这些方法的概述,参见Y. LeCun, Y. Bengio, and G. Hinton, “Deep Learning”, Nature, Vol. 521,No.7553, 2015, pp.436—444。但问题是,如果大数据的方法和结果不能被人类所能理解和解释,那么我们将会创造一个人类不可知的神秘世界。这对于使用大数据进行的科学研究来说是一个巨大的挑战,因为它对大数据领域的影响是巨大的,并且可能标志着科学研究方式的永久性改变。
为了理解认识论转变产生的影响,我们可以回想17世纪有关科学仪器如光学望远镜和显微镜的发展如何使科学实在论得以确立的历史过程。经验主义者只接受基于感知数据的证据,拒绝或不承认那些感知系统不可感知的实体如病毒。因此,以洛克、伯克利、休谟和20世纪逻辑经验主义者主张的经验主义作为现代科学的认识论基础是不可能的。①详 细 原 因 参 见 Humphreys, Extending Ourselves: Computational Science, Empiricism,and Scientific Method,Oxford: Oxford Univ. Press, 2004, and J.Bogen, “Empiricism and After”, in Oxford Handbook of Philosophy of Science, edited by Humphreys, Oxford: Oxford University Press, 2016。我们试探性的推测和建议是,需要为大写的大数据和小写的大数据发展出一种认识论,这种认识论可以令人满意地处理不透明表征,就像现代科学仪器的发展将药物分子和马铃薯基因组等人们的感知系统不可及的世界转化为我们能理解的数据结构一样。
我们认为,大数据中所使用的表征或模型的类型,是其重要性和显著特征的核心。基于此,我们将提供一些建议,以便探索何种认识模式适合于深调制。当然,可靠性是这些模式的核心。
六、深调制的认识论
由于大数据中所使用的机器学习能真正地基于事实进行学习,因此,大数据将会带给人类关于未知世界的知识。然而,不透明表征的存在是大数据所遇到的最关键的挑战。哲学中长期存在的传统是把知识当作确证的真信念(Justified True Belief),而这种对知识的认识已经不占主导地位,其替代理论是可靠性(Reliability)观点。一种常见的可靠性的形式是,一个人S知道p成立的条件是——当且仅当:
(1) p是一个句子;
(2) p为真;
(3) S认为存在一个可靠的过程从而形成对p的信 念。
这意味着,一个可靠的信念形成过程是产生高比例的真实信念的过程。譬如,我知道我的邻居是个医生,虽然我从未见过他以专业的身份工作,我相信是因为:我相信他是一个医生;事实上他是一个医生;他告诉我他是一个医生,并且过去他告诉我的几乎所有的事情都是真实的。以上的每一个条件对我来说都是必要的。如果我的邻居实际上是一个律师,或者我不相信他是医生,或者我从不可靠的来源收到信息,例如我从我的另一个患有痴呆症的邻居处得到信息,那么“我不知道他是一名医生”。
由于数据域中的许多知识都是为机器或机器网络所拥有,传统的知识观和可靠性的观点都使用了“信念”,但是计算机并没有信念,因此,我们所描述的两个关于知识的陈述都不适合在机器学习的背景下进行知识的归因。然而,传统或可靠性的知识观通常涉及表征,因为无论是信念条件还是可靠性条件都需要它。如果你知道p,p是代表某种状态的命题,当p为真时,它即是对世界的正确表征。虽然目前我们不能为机器学习提供一个基于统计学的可靠性解释,但是我们可以描述表征的不透明度和修改后的可靠性论证之间的联系。在基于信念的方法中,如果你的信念是明确的,那么知识就是透明地表征的,因为你有意识地进入了该表征。对机器来说,在论文第五节意义上的透明表征相对来说也没有问题。但是,一旦我们有一个对人类不透明的表征,可靠性方法只需要有一个过程——能可靠地产生内部表征以准确地表征相关系统,即使这样的内部表征是人类无法解释的。由此,一种信念自由的可靠性的要求使我们可以断言,计算机所处理的大数据问题,允许我们不理解它是如何将这些知识呈现给自身的。这样一来,我们可以在唐纳德·拉姆斯菲尔德(Donald Rumsfeld)关于“已知的已知、已知的未知、未知的未知”的这一知识分类中,加上第四类——未知的已知,意味着计算机已知的一些事情对人类来说可以是未知的。
在一些没有任何表征的极端情况下,我们必须诉诸知识的权威,在这种情况下,信息来源作为权威,无可置疑。①T. Burge, “Computer Proof, A Priori Knowledge, and Other Minds: The Sixth Philosophical Perspectives Lecture”, Noûs,Vol.32, No.12, 1998, pp.1—37.因为我们越来越多地将认知权威委托给计算机,我们在许多领域遵从它的判断,就像我们在日常生活中遵从我们自己的知觉判断一样,不需要对来源进行进一步的论证或理解。
七、结论反思
由于数据域捕获了描述系统状态的海量的多变量(或高维度)的数据,加上从传感器、社交媒体、健康记录和其他源头收集数据的行为变得越来越容易,而且虽然很多数据看上去都是匿名的,但是技术上却很容易实现对数据的去匿名化。特别是在位置追踪元数据的使用等背景下,数据挖掘者不仅了解我们所有人,还知道我们每个人的许多事情:他们知道你住的地方,你联系过的人,你购物的地方,你买过什么,你何时在何地,你在互联网上的搜索细节,你喜欢什么样的照片等。这种数据的泛滥产生了一个被称为维度的诅咒的问题。②这一术语是由贝尔曼(R. Bellman)创造的,参见 Adaptive Control Processes: A Guided Tour, Princeton, NJ:Princeton University Press, 1961。最后需要说明的是,随着收集数据的变量数的增加,有效使用某些机器学习方法和统计估算技术所需的数据量也将呈指数增长。例如,假设我们为每个变量收集10个数据点并检查这10个点以查看是否发生了数据点聚类。这样一来,当我们需要定位两个变量的相似聚类时就需要102个数据点;当需要定位三个变量时就需要103个数据点;如果用相对适中的100个变量,那就需要10100个数据点。很显然,这个数字比宇宙中存在的可见的粒子的数目还大。所以在实际的工作中有两种相反的倾向:第一,直到最近人类才具备收集海量数据的能力;第二,即使是适度复杂的模型也超出了我们收集足够数据的能力。这两种自相矛盾的情况表明,那种“只要拥有足够数据,我们就可以知道一切”的观点显得过于乐观,因为现实是我们的大数据还不够大。
大数据能将社会作为一个整体并给出全景的描述,并且能够详细地审视其中的每一个成员,即其能作为天文望远镜和生物显微镜的双重角色而发挥作用。这种双重作用一方面增大了自然科学与人文科学之间的分界,另一方面又使二者之间的界限缩小。首先,作为生物显微镜的存在,大数据形成了对人类个体层面行为数据的事无巨细的记录,丰富了人文科学在个性化维度上的资料储备,增进了人文科学对人类个体差异的深度理解。因此大数据将关注个性化的人文科学和关注一般性的自然科学之间的差距进一步扩大。其次,作为天文望远镜的存在,引入在形式上数理化、科学化(数理统计)的人文科学的方法,从整体(全样本)上获得一般性的规律,从而使二者的界限缩小。
我们需要追问的是,人类不理解数据域中所使用的表征这件事,会为人类带来多大的风险?人工智能所可能造成的危险也许已经被放大了很多。毕竟人类在塞勒斯·麦科米克(Cyrus McCormick)的收割机、福特(Ford)的装配线、蒸汽挖掘机和慕课(大型公开在线课程)的技术革命的历史浪潮中都幸存了下来,因此,我们也许不应该对自动化生产所造成的大规模失业过分担忧,我们应关注更紧迫的问题,而不是对满怀恶意的机器人将要统治世界这类的事情惴惴不安。实践和理论知识的自动化以及它们产生的不可预测性这类新事物,才是真正需要人类警惕的。如果我们人类不能理解机器学习所使用的表征,那么此类程序未来产生不可预料后果的可能性就会大大增加。人们破解恩尼格玛密码机,恰恰是因为它对人类的表征进行了加密处理。在数据域的神秘世界中,充斥着各类机器、数据库和算法,正是因为它们如此神秘,才为人类带来了更大的挑战。
猜你喜欢
财经(2017年15期)2017-07-03 22:40:49
财经(2017年2期)2017-03-10 14:35:35
华东师范大学学报(自然科学版)(2017年1期)2017-02-27 13:41:08
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
财经(2015年3期)2015-06-09 17:41:31
财经(2014年21期)2014-08-18 01:50:18
财经(2014年6期)2014-03-12 08:28:19
财经(2013年6期)2013-04-29 17:59:30
