
基于用户评论情感分析的CDN缓存替换方案*
2018-07-03 08:55陈步华陈戈梁洁
移动通信 2018年5期
陈步华,陈戈,梁洁
(中国电信股份有限公司广州研究院,广东 广州 510630)
1 引言
内容缓存技术就是通过缓存的内容副本为访问的用户提供服务,使得用户向源站服务器发起的内容访问请求变成用户到缓存服务器的就近访问过程。高效的缓存算法在减少CDN服务器的负载和延时方面发挥着很重要的作用。但是,缓存服务器的磁盘空间通常是有限的,尤其是4K/8K以及AR等高数据量内容的引进,对缓存策略提出了更高要求。
目前,CDN中的缓存策略是根据热度排序将高热内容(用户访问最集中的内容以及预测出来的用户未来会最集中访问的内容)缓存在边缘服务器,来实现用户到边缘服务器的就近访问。
然而,仅从上述热度内容来配置CDN的缓存策略是不够充分的。目前,相当多的视频网站都支持用户发表简短的文字评论。事实上,获取用户的文字评价进行分析,进一步挖掘用户对内容的喜好程度,对优化CDN缓存策略提供了重要指导意义。本文在用户的访问行为的基础上,融合用户基于文字评价的情感等信息进行建模,提出了基于情感分析的改进的CDN内容缓存策略。
2 基于CNN的用户评论情感分析
自然语言处理(NLP, Natural Language Processing)是指用自然语言对信息进行处理的技术,通过利用计算机来分担自然语言的自动识别、语言翻译、语言理解和语言生成等工作[1],情感分析就是自然语言处理的任务之一。
2.1 情感分析的任务
情感分析主要是针对主观性文本自动获取有价值的意见信息,其任务分为自动识别情感句中的评价对象和判别情感句中评价对象的情感倾向性[2]。由于句子的长短存在差异,传统的机器学习分类模型难以使用。并且,在特征提取的过程中,句子描述的对象样式繁多,包括主题、人、物体或者事件,所以,人工提取特征耗费的精力太大[3]。再者,需要在特征提取时考虑词与词之间的联系。因此,情感数据挖掘模型的选取至关重要。
2.2 卷积神经网络
近年来,深度学习在语音识别、图像处理等领域表现出了卓越的能力,并且,深度学习也适合做文字处理和语义理解。这是因为深度学习结构灵活,其底层利用词嵌入技术可以避免文字长短不均带来的处理困难。使用深度学习抽象特征,可以避免大量人工提取特征的工作[4]。并且,深度学习可以模拟词与词之间的联系,有局部特征抽象化和记忆功能。正是这几个优势,使得深度学习在情感分析,乃至文本分析理解中发挥着举足轻重的作用。因此本节采用深度学习中的卷积神经网络(CNN, Convolutional Neural Network)进行情感分析挖掘建模。
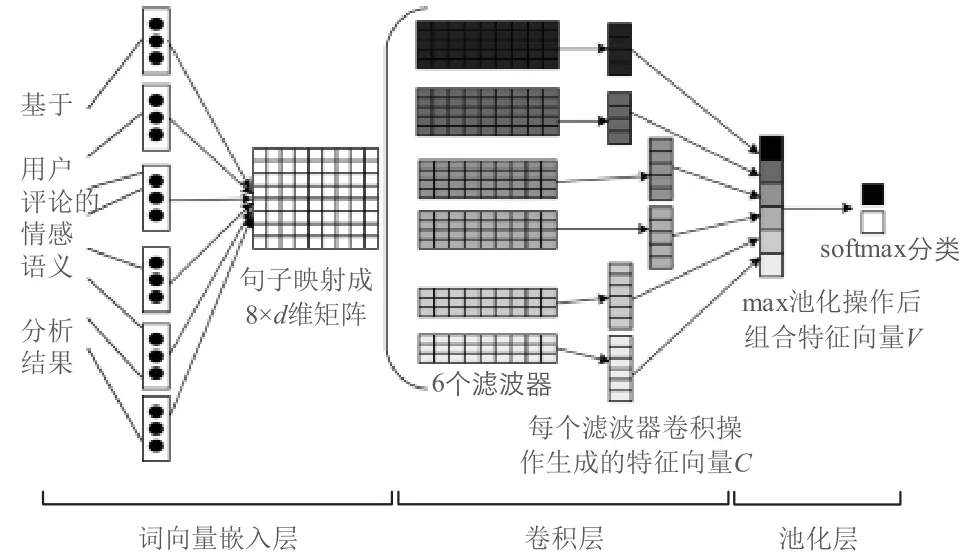
图1 卷积神经网络情感分析框架
如图1所示,第一层是词向量嵌入层,用word2vec把词语映射为向量[5];第二层是卷积层,该卷积层会使用多个滤波器;第三层是池化层,本文采用max-overtime池化;最后将所有池化层的结果放在一个长特征向量上,并加入dropout正则,最后采用softmax输出结果。具体过程如下:
(1)词向量嵌入层
采用CNN模型处理文本时,需要将文本转化成CNN能够识别的输入特征。首先,将句子分词后,将该句子划分后的各个词语分别映射到d维实数向量,词向量表使用word2vec提前训练[6],令xi∈Rd代表句子中第i个词的d维的词向量,所有的词组成句子矩阵Mj∈Rl×d,其中,j代表所有评论集中第j条评论句子,l代表句子中词的数量,d代表每个词向量表示的向量维度,矩阵每行代表句中词的词向量表示,将矩阵Mj作为CNN的输入[7]。
(2)卷积层
对于输入句子矩阵Mj,利用大小为h×d的滤波器(滑动窗口)wh×d进行卷积操作,卷积滑块涉及h个词,滑块宽度d与词向量表示维度相同:

其中,b代表偏置量,f(·)为非线性卷积核函数,xi,i+h-1表示矩阵第i行到第i+h-1行,ci表示由卷积操作所产生的局部特征。因此,在句子矩阵Mj上,卷积滑动窗口将作用于{x1,h, x2,h+1,……, xl-h+1,l}个局部特征区域。所以:

其中,C∈Rl-h+1。
(3)池化层
对于池化层,采用max-over-time池化的方法。这种方法就是简单地从之前的特征向量中提取出最大值,最大值代表着最重要的信号,即滑动窗口获得的局部特征中最重要的特征。可以看出,这种池化方式可以解决可变长度的句子输入问题和滤波器大小不同的问题。因此,对于一个滤波器产生的输出的C,采用maxover-time方法进行特征映射,得到池化后的特征s:

对于整个卷积神经网络模型,将使用多个滤波器wjh×d(h为不同的值)对输入矩阵Mjl×d进行卷积操作,产生多个特征,将特征组合作为全连接层的输入向量V:

其中,S(m,h)表示大小为h的第m个滤波器产生的特征。
(4)softmax输出
池化层的一维向量的输出通过全连接的方式,连接一个softmax层,softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。因此,最后将全连接的输出利用softmax函数生成分类结果,模型利用实际分类标签,使用反向传播算法对参数进行优化。
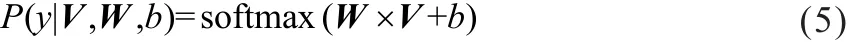
其中,y代表情感分析的类别标签,W代表全连接层的参数,b为偏值项。
3 改进的缓存替换算法设计
通过用户的用户评论确定用户喜欢观看的视频内容,从而在CDN边缘节点中缓存满足用户兴趣的视频,需要通过构建情感数据挖掘模型来实现。本节将具体介绍提出的基于用户评论情感分析的改进的缓存替换算法。
(1)数据准备
首先设计一个网络爬虫,使用爬虫抓取大量页面,并剔除无关数据。然后,对收集到的评论进行有监督的人工给文本标注类标签,将不同的评论语句标注为不同的情感程度等级,这就是类标签。
(2)构建情感数据挖掘模型
在完成数据准备等阶段的工作后,就开始进入模型的建立阶段。基于本文的研究问题,使用深度卷积神经网络来构建基于用户评论的情感分析模型。情感数据挖掘模型构建分为训练和测试两个阶段。用数据训练分模型,再用训练好的模型对测试集里的数据进行分类,给出分类得到的情感程度标签。
(3)缓存替换策略
在缓存替换策略中,传统方式只考虑用户访问行为带来了访问和预测的热度信息。为了获得更合理的缓存替换方法,需要考虑用户的文字评论信息,用评论信息去调节热度值。因为在目前的互联网视频环境中,许多视频并不是根据自然冷却法则变成冷片。例如,某影片有热门影视明星出演时,一开始会访问热度很高,但如果影片本身质量不高,用户评论口碑不佳,影片会在很短时间内变成冷片,并不遵循访问热度下的自然冷却法则。因此,本文提出的基于评论情感信息的缓存策略,是将不同用户对某影片评论通过CNN模型输出的情感程度标签进行平均,获得综合情感权值Y。因此,考虑用户的文字评论信息,用评论信息去调节热度值H的缓存更新策略模型如下:

其中,H0是影片的初始热度值(访问热度或预测访问热度值),Y是情感权值,t0是内容第一次被请求的时间,t是当前时间,a是冷却系数,用于调整冷却速度,e是自然对数。
设置每隔一段时间T,更新H值,再按H值排序,选取H值最高的前10%的内容进行缓存,从而完成缓存替换与更新。
4 实验设计与结果
4.1 数据准备
天翼视讯是中国电信移动端的一种流媒体技术,以视频内容为主,利用移动流媒体、视频下载等技术为用户提供影视、新闻、娱乐等视频内容播放和下载的服务[8]。本文提取了天翼视讯部分影片的历史用户评论数据作为建模初始样本。为避免原始数据中的噪声数据和缺失值对模型精度的影响,模型运行前进行了数据清洗、转换以及噪声和缺失值处理[9]。
4.2 基于用户评论的情感分析结果
实验抓取了天翼视讯中影片的用户评论数据作为情感分析和可视化方法应用研究的实验数据集,其中某影片的部分用户评论如表1所示:
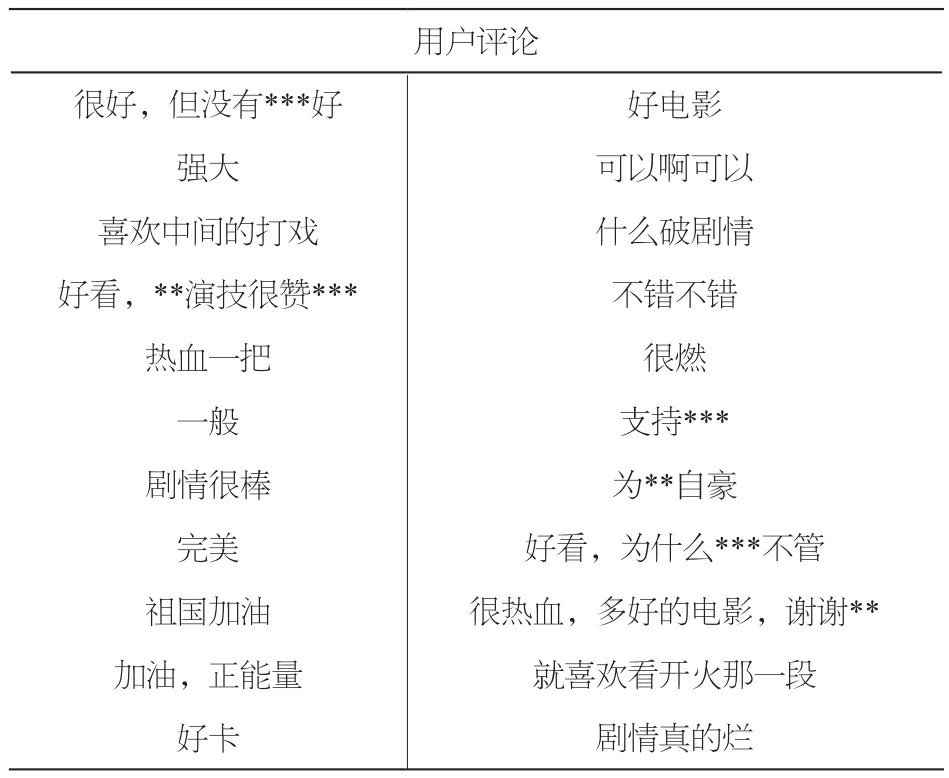
表1 某影片的部分用户评论
通过采用深度学习CNN模型进行用户评论情感分析,情感分析结果输出共有5个等级,每条用户评论对应一个等级值,即是情感标签[1, 2, 3, 4, 5]中的一个值。等级值越接近5,情感越积极,表示该影片越受用户喜欢;等级值越接近1,情感越消极,表示该影片越不受用户欢迎。表1中,对某影片的部分用户评论采用CNN方法进行情感分析,输出的情感程度值如图2所示:
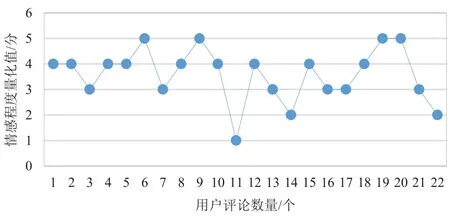
图2 基于CNN的用户评论情感程度值
雷达图是专门用来进行情感分析倾向性比较分析的专业图表。绘制不同影片的情感倾向性雷达图,能够直观体现用户数在各个影片在5个情感程度等级上的分布情况,进而分析用户情感倾向性。通过观察图3中的不同影片的情感类别倾向性雷达图可以看出,影片1和影片4形成的雷达图,分别是在等级5和等级4的方向上最为突出,这说明表达赞扬或喜爱这些影片的用户居多;对于影片3形成的雷达图,在等级3的方向上最为突出,意味着观看感受一般的用户评论较多;而对于影片2则是在等级2方向上最为突出,说明表达讨厌、不喜欢的用户评论较多。
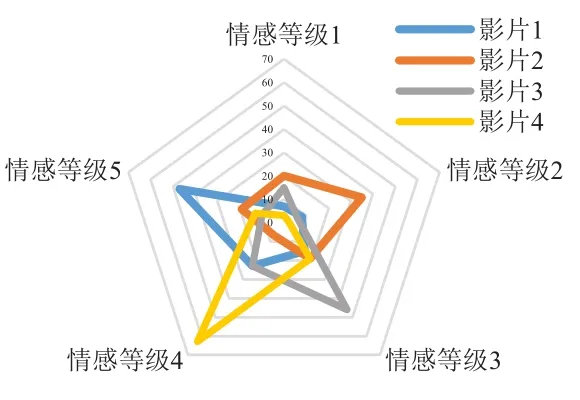
图3 不同影片的情感类别倾向性雷达图
4.3 缓存命中结果
本文在对视频CDN打流时,采用“源站-缓存”二级架构组网[10],模拟不同用户对影片的请求访问行为,在稳定运行期间,对源站和缓存设备的网卡流量数据进行监控。
下面通过对系统的本地命中率及用户请求的平均响应时间两方面来比较传统LFU策略和本文提出的缓存替换策略对系统性能的影响。表2所示为本地数据命中率的比较,随着系统稳定运行时间的增加,本文提出的缓存替换策略的本地命中率在10小时左右就达到97.1%以上,这说明用户请求的数据中,97.1%的影片内容都已经推送到在本地存储,远远高于传统最少频率使用(LFU, Least-Frequency Used)方法对于用户请求内容的71.7%的本地存储,体现了存储策略的优势。
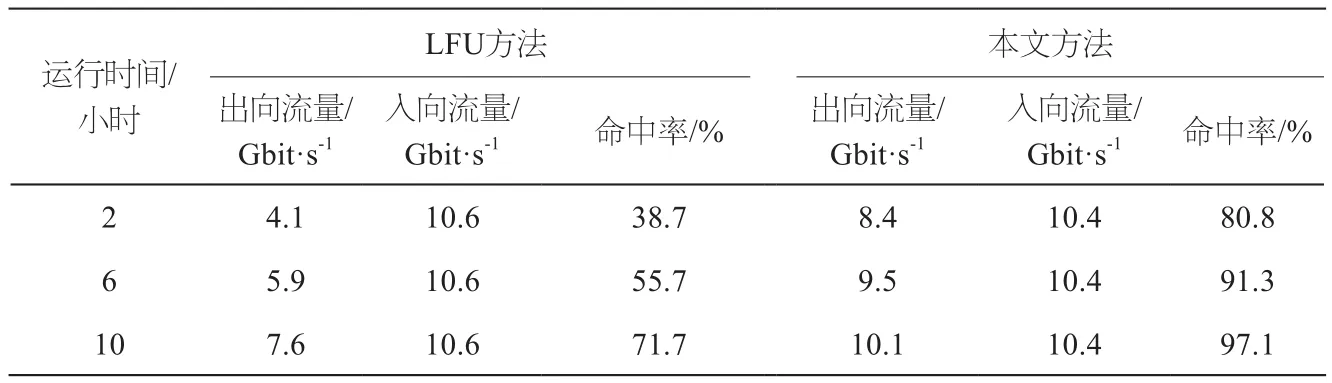
表2 缓存命中结果
图4所示为传统LFU方法与本文替换的缓存替换策略的请求响应时间的比较,可看出,本文提出的缓存替换策略有效地减少了用户的请求响应时间,并减少了节点间数据的传送,可以有效缓解网络带宽的压力。
5 结束语
通过仿真实验和对比测试可以得出,本文提出的基于评论情感分析的CDN内容缓存替换方案,结合了用户访问行为(热度)信息和用户评论情感信息的融合优势,使现存内容最大可能地满足用户需求,有效地提高了本地缓存命中率。因此,本文提出的缓存替换策略不仅能够优化CDN节点存储配置,还为提高缓存效率、节省带宽资源起着重要指导作用。
[1] 程希文. 基于领域的中文信息抽取模式自动生成的研究[D]. 上海: 上海交通大学, 2005.
[2] 刘鸿宇,赵妍妍,秦兵,等. 评价对象抽取及其倾向性分析[J]. 中文信息学报, 2010,24(1): 84-88.
[3] 秦胜君. 基于稀疏自动编码器的微博情感分类应用研究[J]. 广西科技大学学报, 2015(3): 36-40.
[4] 李跃鹏,金翠,及俊川. 基于word2vec的关键词提取算法[J]. 科研信息化技术与应用, 2015(4).
[5] 李晓磊. 面向评论的文本倾向性分析中关键问题的研究[D]. 北京: 北京化工大学, 2016.
[6] 王盛玉,曾碧卿,胡翩翩. 基于卷积神经网络参数优化的中文情感分析[J]. 计算机工程, 2017,43(8): 200-207.
[7] 郑立洲. 短文本信息抽取若干技术研究[D]. 合肥: 中国科学技术大学, 2016.
[8] 曹晔. 浙江电信家庭信息化发展战略研究[D]. 杭州: 浙江大学, 2013.
[9] 尔古打机,苏小龙,朱征. 基于用户行为分析的移动终端偏好模型研究[C]//中国管理学年会, 2013.
[10] 袁宏绘. 呼和浩特市IPTV业务与承载网络组建研究[D]. 北京: 北京邮电大学, 2012. ★
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国生殖健康(2020年5期)2021-01-18
北极光(2019年12期)2020-01-18
小太阳画报(2019年10期)2019-11-04
电子制作(2019年11期)2019-07-04
中国生殖健康(2018年5期)2018-11-06
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
