
一种基于隔离损失函数的人脸表情识别方法
2018-06-28 02:40曾逸琪关胜晓
网络安全与数据管理 2018年6期
曾逸琪,关胜晓
(中国科学技术大学 信息科学技术学院,安徽 合肥 230026)
0 引言
人脸表情在人类交流中扮演着重要角色,也是人机交互系统识别人类情感的重要途径。EKMAN P等定义了6种人脸表情,即生气、厌恶、害怕、高兴、伤心、惊讶,作为常见的情感表情[1]。
由于人脸表情识别在人机交互系统设计[2]中的重要性,大量的计算机视觉和机器学习算法应用到人脸表情识别。当然,目前已经存在许多标注好的人脸表情数据集[3-6],用于人脸表情的研究。
人脸表情识别本质上来说是以单帧图像或视频序列作为研究对象,对其进行分类,将其分为六种基本表情中的一类。
虽然传统机器学习方法,例如支持向量机、贝叶斯分类器,已经在简单场景下取得良好效果,但最近研究显示,传统方法并不能在复杂场景下取得良好的识别结果。
近年来,基于神经网络的方法取得重大突破,例如物体识别[7-8]、人体位姿估计[9]、人脸验证[10]等。在人脸表情识别领域,取得最好效果的方法也是基于神经网络[11]。与传统机器学习、人工提取特征方法不同,神经网络可以通过训练数据自动学习特征。基于大量数据学习到的特征,往往具有更好的泛化性。
然而,人脸表情识别仍存在许多关键的问题,主要是光照、遮挡、头部位姿、个体属性多样化等因素,导致提取的同类特征差异性较大,而不同类特征判别性过小。
针对这一问题,本文提出了一种损失函数——隔离损失作为改进方法。
一般来说,卷积神经网络是利用多分类损失进行优化,对误分样本进行惩罚,让属于不同类别的特征分离。如图1(a)所示,不同表情特征形成的聚类簇分别对应了在特征空间的不同表情特征。由于类内的差异化,导致特征簇分布分散。而又由于类间相似性,导致特征簇有部分重叠。最近有项研究,将中心损失[12]引进卷积神经网络,以此来降低类内特征差异性。如图1(b)所示,样本更靠近对应的聚类中心。可是,类间相似性的问题仍没有考虑进去。所以,针对此问题,本文提出了隔离损失,通过惩罚不同类特征之间的距离,让学习到的特征更具判别性。如图1(c)所示,隔离损失不仅压缩了聚类簇,并且让聚类中心之间距离增大。

图1 特征空间分布图
1 人脸表情识别方法
为了验证隔离损失的有效性,本文提出了以隔离损失作为损失函数的卷积神经网络模型,结构如图2所示。该网络结构中每一个卷积层后面都连接了批量正则化层(Batch Normalization, BN)和ReLU(Rectified Linear Units)激活函数。池化层采用的均是最大池化。在最后一个池化层后连接了全连接层,生成特征向量。之后再接多分类层。隔离损失在全连接层计算。多分类损失在分类层计算。用隔离损失和多分类损失的联合损失对网络进行优化。
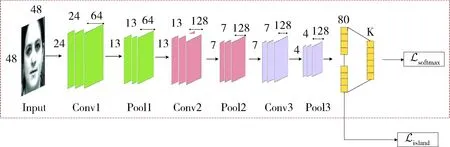
图2 网络结构示意图
1.1 中心损失
如图1(b)中描述,中心损失可以减小类内特征差异。在神经网络训练过程中,聚类中心在每次迭代过程会被更新。
(1)前向传播:中心损失表示为LC,如式(1)所示。其含义是样本和聚类中心在特征空间的欧式距离的平方和。
(1)
其中,yi表示第i个样本的类别标签;xi表示第i个样本的特征向量,该特征向量是从全连接层提取的;cyi表示与yi同一类所有样本的聚类中心;m表示一个小批量的样本数量。通过最小化中心损失,同一类的样本在特征空间会向聚类中心靠近,因此整体的类内差异会减小。
在前向传播过程中,联合损失,也即多分类损失和中心损失之和,用来训练整个网络:
L=LS+λLC
(2)
其中LS表示多分类损失;λ用于调节多分类损失和中心损失的比例。
(2)反向传播:在反向传播过程中,中心损失LC关于输入样本的特征向量xi的偏微分可表示为:
(3)
而聚类中心在使用随机梯度下降时会按如下公式更新:
(4)
其中δ(yi,j)的定义如下:
(5)
1.2 隔离损失
如图1(b)所示,最小化中心损失,会在特征空间减小类内差异,但不同的聚类簇有部分重叠的问题仍旧存在。为了克服这个问题,本文设计了隔离损失,在减小类内差异的同时,增大类间特征之间彼此距离。
(1)前向传播:隔离损失可表示为LIL,其定义是中心损失与聚类中心之间的欧式距离之和。
LIL=
(6)
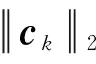
总体的网络模型的损失函数可以表示为:
L=LS+λLIL
(7)
其中,超参数λ用于平衡两项损失的比例。
(2)反向传播:隔离损失LIL关于样本特征向量xi的偏微分可以表示为:
(8)
更新聚类中心:基于随机梯度下降方法(SGD),第j个聚类中心可表示为:
(9)
其中|N|是表情类别数。
在上式的表述下,聚类中心可以在每个小批量数据进行更新,以α的学习率进行迭代:
(10)
至此,可以将隔离损失在网络模型中的前向和反向传播过程总结为如下流程:

算法 网络的前向反向传播过程输入:训练数据{xi} 1: 输入:小批量数据的大小m,迭代总数T,学习率μ和α,以及超参数λ和λ12: 初始化:t=1,网络权重参数为,多分类层参数为θ,隔离损失的训练参数为cj3: for t=1 to T do 计算公式(7)的联合损失:=S+λIL更新多分类损失层的参数:θt+1=θt-μ∂tS∂θt更新隔离损失的训练参数(即聚类中心),如式(10):ct+1j=ctj-αΔctj计算需反向传播的损失:∂t∂xti=∂tS∂xti+λ∂tIL∂xti更新网络权重:t+1=t-μ∂Lt∂t=t-μ∂Lt∂xti∂xti∂tend for输出:训练完成的网络权重,隔离损失的参数cj,多分类层参数θ
2 对比实验
为了验证本文所提方法的有效性,在CK+数据集[13]上做了一系列对比试验。此外,还在相同的网络模型下,将隔离损失与多分类损失和中心损失分别进行了对比。
2.1 预处理
为了减小图像中人脸尺度变化及人脸旋转对表情识别的影响,需要对图像做基于人脸关键点的人脸摆正。人脸关键点的检测是基于OpenCV中Dlib库的人脸关键点的检测算法[14]。然后以3个关键点(两个眼睛中心点、一个嘴巴中心点)为基准点进行校正。
此外,直方图均衡化也用于提高人脸图像的对比度,降低光照等因素的影响。
由于人脸表情数据集较小的限制,采用了数据增强的方式来扩展训练数据。从60×60大小的图像中随机裁剪出大小为48×48图像块作为训练数据,并且将图像块随机旋转一个角度,该角度范围在-10°~10°之间。此外,还要将图像以0.5的概率进行水平随机翻转。
2.2 人脸表情数据集
CK+人脸表情数据集包括327个有效图像序列,从118个不同个体中提取,每个个体包括7种表情:愤怒、轻蔑、厌恶、害怕、高兴、悲伤、惊讶。每个图像序列以中性表情作为首帧开始,到峰值表情作为最后一帧结束。为了获得更多数据,每个视频最后三帧标记为该表情的训练数据,第一帧作为中性表情的训练数据。
FER-2013数据集[15]有7种带标签的表情(包括中性表情),有28 709张训练样本以及3 589张测试样本。
训练策略:本文采用十折交叉验证的策略。将数据集分成10份,其中8份用于训练,剩余两份分别作为验证集和测试集。
2.3 卷积神经网络的实现
首先采用多分类损失的网络模型在FER-2013数据集上进行预训练。然后采用隔离损失的网络模型在CK+数据集上进行微调(fine-tune)。采用随机梯度下降的训练策略,其中,动量设为0.9,批处理大小为32,权重衰减为0.05。学习率初始设为0.001,每5 000次迭代乘以衰减因子0.1。训练迭代为100次遍历训练集。在全连接层之后的Dropout层的概率值设为0.5。
2.4 实验结果
用隔离损失作为损失函数的网络模型相比多分类损失和中心损失效果取得了明显的提升。其混淆矩阵如表1所示,矩阵对角线表示每种表情的准确率。其中,Ne表示中性,An表示高兴,Co表示轻蔑,Di表示厌恶,Fe表示害怕,Ha表示高兴,Su表示惊讶。
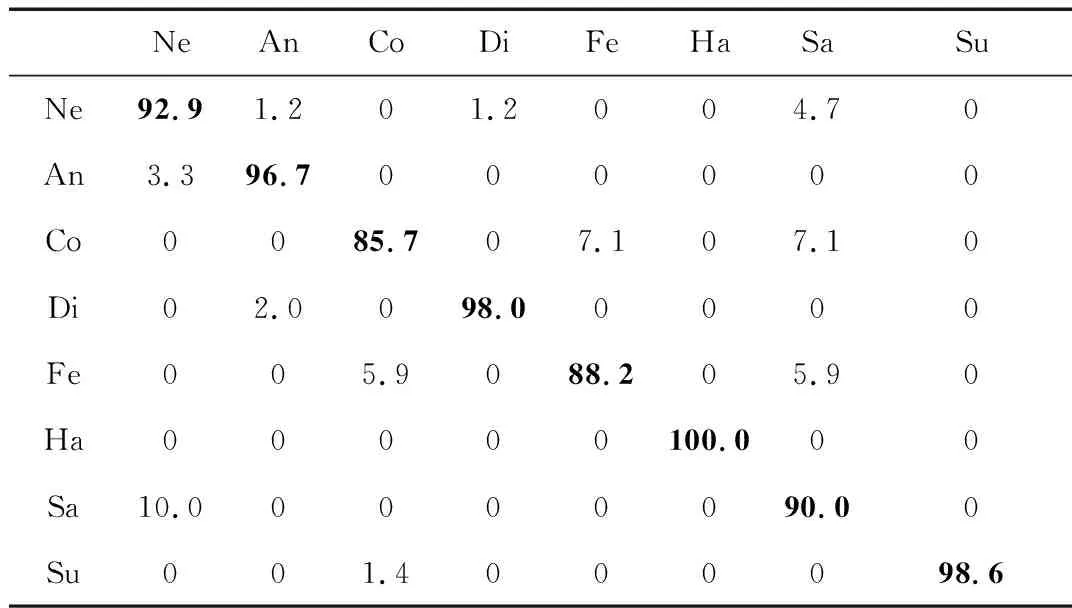
表1 实验结果的混淆矩阵 (%)
此外,将本文方法与HOG 3D[16]、Cov3D[17]、Inception[18]、IACNN[19]、DTAGN[20]等传统经典人脸表情识别方法进行了准确率的对比,对比结果如表2所示。
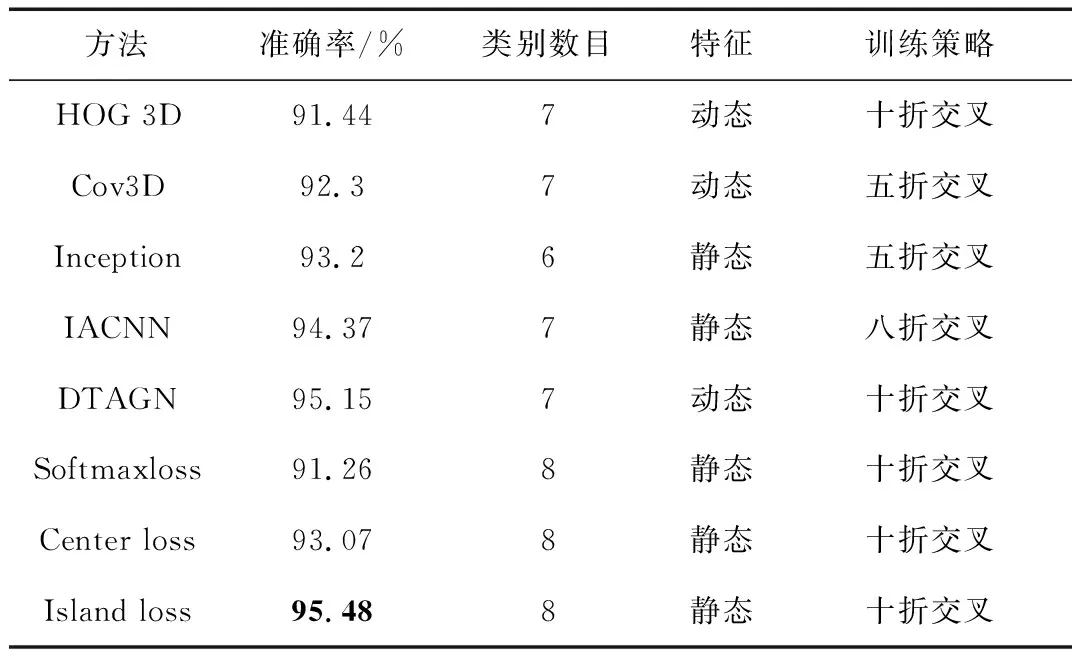
表2 人脸表情识别方法对比
实验结果表明,加强了对特征空间的约束,使用隔离损失的方法准确率获得了提升。将隔离损失与多分类损失和中心损失进行实验对比,基于隔离损失的方法效果最好。可见,加大不同类特征之间的距离约束,可以提取更具判别性的特征,提升识别的准确率。
2.5 特征可视化
对特征进行可视化,从特征空间分布的角度验证了隔离损失有效地减小了类内特征差异,且增大了类间特征之间的距离。
对网络结构全连接层的特征利用t-SNE[21]对高维向量进行降维可视化,结果如图3所示。
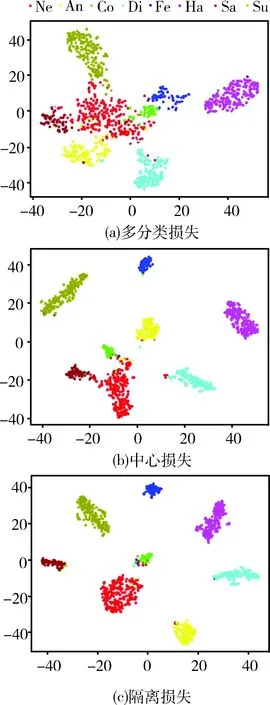
图3 表情特征分布
图3中(a)、(b)、(c)所示分别为以多分类损失、中心损失、隔离损失作为损失函数,学习之后的特征空间分布。图3(b)相比于图3(a)而言,同一类的特征分布更为聚集,说明中心损失可以有效减小类内特征差异。而图3(c)不仅相较于图3(a)特征更为聚集,而且相对于图3(b)聚类簇也更为分散,重叠部分小,说明隔离损失可以在减小类内特征差异的同时,增大类间特征距离,使特征更具判别性。
3 结束语
本文针对人脸表情识别领域存在的特征判别性不足这一问题进行改进,提出了一种新的损失函数——隔离损失,用于改进特征分布,使同一类的特征更为聚集,不同类的特征更为远离。为了验证理论,提出了卷积神经网络的模型,结合隔离损失,进行了多组对比实验。实验结果表明,该方法能够提升特征的判别性,并且取得很好的识别准确率。此项研究能够让人脸表情识别在现实场景下取得更为鲁棒的效果,对于人脸表情识别的应用具有重要意义。
[1] EKMAN P, FRIESEN W V. Constants across cultures in the face and emotion[J]. Journal of Personality and Social Psychology, 1971, 17(2): 124-129.
[2] MOLLAHOSSEINI A, GRAITZER G, BORTS E, et al. Expressionbot: an emotive lifelike robotic face for face-to-face communication[C]//2014 14th IEEE-RAS International Conference on Humanoid Robots (Humanoids). IEEE, 2014: 1098-1103.
[3] GROSS R, MATTHEWS I, COHN J, et al. Multi-pie[J]. Image and Vision Computing, 2010, 28(5): 807-813.
[4] PANTIC M, VALSTAR M, RADEMAKER R, et al. Web-based database for facial expression analysis[C]//2005 IEEE International Conference on Multimedia and Expo. IEEE, 2005.
[5] LYONS M, AKAMATUS S, KAMACHI M, et al. Coding facial expressions with gabor wavelets[C]// Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition. IEEE, 1998: 200-205.
[6] MAVADATI S M, MAHOOR M H, BARTLETT K, et al. Disfa: a spontaneous facial action intensity database[J]. IEEE Transactions on Affective Computing, 2013, 4(2): 151-160.
[7] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems, 2012: 1097-1105.
[8] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 1-9.
[9] TOSHEV A, SZEGEDY C. Deeppose: human pose estimation via deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 1653-1660.
[10] TAIGMAN Y, YANG M, RANZATO M A, et al. Deepface: closing the gap to human-level performance in face verification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 1701-1708.
[11] KAHOU S E, PAL C, BOUTHILLIER X, et al. Combining modality specific deep neural networks for emotion recognition in video[C]//Proceedings of the 15th ACM on International Conference on Multimodal Interaction, 2013: 543-550.
[12] WEN Y, ZHANG K, LI Z, et al. A discriminative feature learning approach for deep face recognition[C]//European Conference on Computer Vision. Springer International Publishing, 2016: 499-515.
[13] LUCEY P, COHN J F, KANADE T, et al. The extended cohn-kanade dataset (ck+): a complete dataset for action unit and emotion-specified expression[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2010: 94-101.
[14] SARAGIH J M, LUCEY S, COHN J F. Face alignment through subspace constrained mean-shifts[C]//2009 IEEE 12th International Conference on Computer Vision. IEEE, 2009: 1034-1041.
[15] GOODFELLOW I J, ERHAN D, CARRIER P L, et al. Challenges in representation learning: a report on three machine learning contests[C]//International Conference on Neural Information Processing. Springer, Berlin, Heidelberg, 2013: 117-124.
[16] KLASER A, MARSZAEK M, SCHMID C. A spatio-temporal descriptor based on 3d-gradients[C]// 19th British Machine Vision Conference. British Machine Vision Association, 2008: 275: 1-10.
[17] SANIN A, SANDERSON C, HARANDI M T, et al. Spatio-temporal covariance descriptors for action and gesture recognition[C]//2013 IEEE Workshop on Applications of Computer Vision (WACV). IEEE, 2013: 103-110.
[18] MOLLAHOSSEINI A, CHAN D, MAHOOR M H. Going deeper in facial expression recognition using deep neural networks[C]//2016 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2016: 1-10.
[19] MENG Z, LIU P, CAI J, et al. Identity-aware convolutional neural network for facial expression recognition[C]//2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017). IEEE, 2017: 558-565.
[20] JUNG H, LEE S, YIM J, et al. Joint fine-tuning in deep neural networks for facial expression recognition[C]// 2015 IEEE International Conference on Computer Vision (ICCV). IEEE, 2015: 2983-2991.
[21] MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学小灵通·3-4年级(2021年5期)2021-07-16
铁道通信信号(2019年6期)2019-10-08
今日农业(2019年15期)2019-01-03
动漫星空(2018年9期)2018-10-26
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
共产党员(辽宁)(2015年2期)2015-12-06
