
本地化差分隐私在数据众包中的应用*
2018-06-28 02:40方俊斌蒋千越李爱平
网络安全与数据管理 2018年6期
方俊斌,蒋千越,李爱平
(中国人民解放军国防科技大学 计算机学院,湖南 长沙 410073)
0 引言
近年来,众包技术得到了工业界和学术界的广泛关注。美国《连线》杂志的记者杰夫·豪(Jeff Howe)2006年6月提出:众包是一个公司或机构把过去由员工执行的工作任务,以自由自愿的形式外包给非特定的大众网络的做法[1]。传统的外包是指以合同的形式把任务委派给指定的人或者机构完成,但是很多任务并不能通过简单的指定的人或机构通过某些具体算法来实现,这类问题可以借助于众包模式,直接将任务发布到互联网,通过开放式集合互联网上未知的大众来解决传统工作方式难以单独处理的问题[2],例如Wikipedia、reCAPTCHA、标记图像、语言翻译[3]等。因为现实生活中存在着大量类似的问题,因此众包有着广大的应用前景和市场。
尽管众包技术充分利用了群体智慧并带来极大的效益,但众包过程中涉及许多数据安全和隐私保护问题尚未得到很好的解决,例如众包平台中任务完成者(工人)自身隐私泄露问题、工人产生的数据内容的安全问题、众包过程中手机、传感器等软硬件设施的数据安全问题等。上述隐私泄露的风险,极大限制了众包技术的应用和推广。
当前,针对众包的隐私保护模型主要有基于加密技术的隐私保护模型、基于K-匿名等匿名技术的保护模型和基于差分隐私技术的保护模型等。基于加密的隐私保护方法具有较高的隐私保护水平,但其运行开销巨大,且需要构建专门的数据库。基于匿名方法的隐私保护技术具有较好的数据安全性和可用性,目前已经得到较为广泛的应用,但该方法大都对攻击者的背景知识做出了前提假设,面对层出不穷、角度多样的攻击方式(如组合攻击、背景知识攻击、关联攻击等)时的抵御能力较弱,存在安全隐患。基于差分隐私的保护模型,不对攻击者的背景知识做出限定,即使攻击者已经掌握除某一条记录之外的所有其他信息,仍能够对攻击者未掌握的记录进行有效保护,具有很强的安全性。对比上述几种模型,由于差分隐私保护模型较强的隐私保护能力,同时兼顾适当的运行开销和较好的数据可用性,随着研究的深入将具有更广阔的应用前景。
1 众包技术与隐私问题
1.1 众包技术
众包技术是一种分布式的问题解决机制,采用的主要方式是公开召集互联网大众参与。众包任务通常是难以独自完成的、需要大量参与者共同解决的问题,大众通过相互协作或独立的方式完成分发的任务。根据参与众包的不同形式,众包被分为协作式众包和竞赛式众包。协作式众包的任务是需要大众协作来完成的,竞赛式众包的任务通常是由个人独立完成。
协作式众包中典型的案例有维基百科Wikipedia和reCAPTCHA等。维基百科是开放的、自由的、免费的百科全书编辑平台,任何大众都可以进行编辑和修改。reCAPTCHA项目则通过在验证码中嵌入书籍的扫描信息,来完成纸质书籍的电子化[4]。
竞赛式众包中典型的例子是Amazon Mechanical Turk(Mturk)。Mturk为任务请求者和工人构建了一个在线平台,为双方提供数据收集、分类工作等任务的发布与接受服务。
1.2 众包模型中的隐私问题
以典型的竞争式众包为例,假设一个空间众包平台,为任务请求者和工人建立基于位置信息等空间任务的合作关系,并负责任务请求者和工人提交的空间任务、个人位置等信息的综合处理。
图1展示了空间众包的基本工作流程。
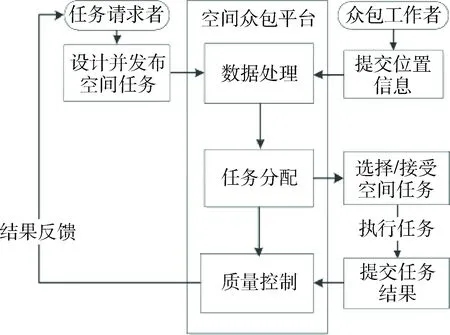
图1 空间众包的工作流程
空间众包平台收集任务请求者提交的任务以及工人的位置等信息,并由数据处理模块预处理后提交至任务分配模块,由任务分配模块完成任务的分配,最后在工人完成任务后提交至质量控制模块,综合分析并反馈给任务请求者。
在这个场景中,空间众包平台在数据处理的各个环节都可能存在用户、工人、服务内容等方面的隐私泄露问题,例如任务请求者发布任务的内容可能泄露其自身信息、工人的位置数据等包含个人住址、健康状况、生活习惯等许多隐私。这种隐私泄露的风险,极大打击用户使用众包技术的信心。
2 众包隐私保护模型及应用
2.1 本地化差分隐私保护模型
DWORK C[5]等人提出了差分隐私,这是一种有数学理论支撑并且对隐私泄露风险给出定量表示的方法。差分隐私在原始数据上添加随机噪声,使得对任意与-1条信息查询返回的结果几乎一致,即无法通过差分攻击从数据集中识别出个体信息,同时还能保持数据的统计特性,便于执行良性的聚合分析,实现较高的数据可用性。将差分隐私技术运用到众包中,能够有效防止基于背景知识的恶意攻击[6]。
目前,差分隐私技术的研究主要分两种[7]。一是中心化差分隐私保护技术。其要求可信的第三方数据收集者对原始数据进行隐私化处理。二是本地化差分隐私技术(Local Differential Privacy,LDP)。LDP中,用户在上传数据前先对个体数据进行隐私化处理,第三方收集的用户数据只涉及加噪后的泛化信息,原始数据被保护在本地设备,降低了非可信第三方隐私泄露的风险。LDP的形式化定义如下[8]:
定义:给定n个用户,每个用户对应一条记录,给定一个隐私算法M及其定义域Dom(M)和值域Ran(M),若算法M在任意两条记录t和t′(t,t′∈Dom(M))上得到相同输出结果t*(t*∈Ran(M))满足下列不等式,则M满足ε-本地化差分隐私。
Pr[M(t)=t*]≤eεPr[M(t′)=t*]
即LDP通过控制任意两条记录输出结果的相似性,确保算法M满足ε-本地化差分隐私。根据隐私算法M的某个输出结果,几乎无法推理出其输入数据为哪一条记录。
LDP数据处理框架如图2所示。

图2 本地化差分隐私处理框架
在常规的中心化差分隐私保护技术中,为保证算法满足ε-差分隐私,需要噪声机制的介入,常用的噪声机制包括拉普拉斯机制[9]和指数机制[10]。其中,拉普拉斯机制面向连续型数据的查询,而指数机制面向离散型数据的查询。上述两种噪声机制均与查询函数的全局敏感性密切相关,而全局敏感性定义在至多相差一条记录的近邻数据集之上,使得攻击者无法根据统计结果推测个体记录。在LDP中,用户上传至第三方的数据已经过隐私化处理,用户无法获知其他用户的数据,即LDP中不存在全局敏感性的概念,因此拉普拉斯机制和指数机制并不适用。目前,LDP主要采用随机响应技术、Bloom Filter[11]等技术来确保隐私算法满足ε-本地化差分隐私。LDP下,离散型数据的随机响应方法包括 RAPPOR[12]、S-Hist[13]、k-RR[14]和O-RR[15]等,连续型数据的随机响应方法有MeanEst[16]和 Harmony-mean[17]等。
LDP相比中心化差分隐私具有更广泛的应用场景,十分适用于当前的众包模型。在上述的空间众包模型中引入LDP技术,每个用户(包括任务发布者和工人)先在各自本地对数据进行隐私化处理,再将隐私化后的数据发送给众包平台,众包平台对采集到的隐私化数据进行集合、统计特征分析、综合应用与反馈等处理。在此过程中,敏感的原始数据都保留在用户本地,众包平台仅对隐私化的数据进行操作,有效保证个体的隐私信息不被泄露。
另外,由于差分隐私保护模型本质上是通过添加噪声实现对数据的扰动,使算法满足ε-差分隐私。噪声越大,对数据的保护程度越高,数据可用性就会降低。反之,噪声越低,隐私保护程度越低,数据可用性越大。因此,如何针对不同的众包应用场景,界定隐私与数据可用性,在其之间进行有效的权衡,并设计适当的隐私算法,确保模型同时具有高隐私性和高可用性,是当前LDP模型的研究重点。
2.2 研究与应用
当前,本地化差分隐私技术在数据众包中的研究持续深入研究与发展,并在许多场景中得到应用。
2.2.1主要研究方向
(1) 针对高维数据的研究。随着各种传感器和人群感知系统的发展,众包数据信息不断向高维发展,数据之间的关联性日益加强,众包参与者的隐私更容易被推断或者识别。针对这个特点,Ren Xuebin等[18]提出一个基于本地化差分隐私技术的高维众包数据发布算法LoPub。LoPub基于EM和Lasso回归,可以从分布式用户收集和构建高维数据,并通过将数据集分割成许多紧凑的聚类来降低原始数据集中的维数和稀疏度。在对聚类的分布进行分析之后,从中绘制一个新的数据集,从而实现对整个原始人群数据的近似处理,同时保证个人隐私。文献[17]研究了智能手机端收集用户的多种数值和类别数据中本地化差分隐私机制Harmony,既可以处理数值型数据,又可以处理类别型数据;在ε-差分隐私下,文献[17]研究了线性回归、逻辑回归和SVM分类器在训练参数过程中使用SGD方法避免受到噪声干扰的mini-batch数。

2.2.2当前主要应用
(1) Google的RAPPOR技术。Google在Chrome浏览器中采用RAPPOR[12]技术,利用随机应答策略和Bloom Filter实现了针对客户端群体的类别、频率、直方图和字符串类型统计数据的隐私保护分析,为提供差分隐私保护。在RAPPOR中,采用永久和即时的随机响应,可以单独调节隐私保护水平,而且Bloom Filter可以增加额外的不确定性,不仅压缩报文大小,更增加攻击者的攻击难度。在解码过程中结合成熟的假设检验、最小二乘求解和LASSO回归实现了针对字符串抽样群体频率的高可用解码框架。此外,RAPPOR的改进模型实现了数据字典未知情况下的本地学习多变量联合概率分布估计。
(2) Apple的本地化差分隐私部署应用。Apple在2016年6月的WWDC上正式宣布,在iOS 10及以后的产品中使用本地差分隐私技术。利用本地差分隐私技术,服务器以众包的方式学习由用户客户端设备生成的信息,同时保持客户端设备的本地隐私[22]。系统为本地数据添加随机信息,使得Apple无法将数据与每个用户设备关联,又能通过大量加噪数据分析出用户群体的使用模式。其应用主要涉及局部抽样、散列加密、噪声扰动等手段。
3 结束语
差分隐私作为一种隐私保护模型,最强大的地方在于只要算法每一个步骤都满足差分隐私的要求,那么它可以保证这个算法的最终输出结果满足差分隐私,即攻击者具有足够多的背景知识,也无法在最终的输出中找出单个人的某项属性。作为数据众包中的一种隐私保护手段,本地化差分隐私表现出了足够的防护能力和应用潜力。但在技术飞速发展、数据众包技术也不断演变的今天,对于本地化差分隐私保护技术,还存在理论和应用上的一些难题和新的研究方向,有待进一步深入探索。总的来说,本地化差分隐私在众包等领域中已经取得了一些研究成果,但作为一个新的保护手段,仍然需要不断深入研究,以取得更大的理论和应用成果。
[1] 冯剑红, 李国良, 冯建华. 众包技术研究综述[J]. 计算机学报, 2015, 38(9): 1713-1726.
[2] HOWE J. Crowdsourcing: why the power of the crowd is driving the future of business[M]. 2008.
[3] IPEIROTIS P G. Analyzing the amazon mechanical turk marketplace[J]. Social Science Electronic Publishing, 2010, 17(2):16-21.
[4] VON AHN L, MAURER B, MCMILLEN C, et al. Recaptcha: human-based character recognition via web security measures[J]. Science, 2008, 321(5895): 1465-1468.
[5] DWORK C. Differential privacy: a survey of results[C]. International Conference on Theory and Applications of Models of Computation. Springer, Berlin, Heidelberg, 2008: 1-19.
[6] 张琳, 刘彦, 王汝传. 位置大数据服务中基于差分隐私的数据发布技术[J]. 通信学报, 2016, 37(9): 46-54.
[7] 高志强, 王宇涛. 差分隐私技术研究进展[J]. 通信学报, 2017, 38(S1): 151-155.
[8] 叶青青, 孟小峰, 朱敏杰, 等. 本地化差分隐私研究综述[J/OL]. 软件学报, 2018, 29(7). http://www.jos.org.cn/1000-9825/5364.ht
[9] DWORK C, MCSHERRY F, NISSIM K. Calibrating Noise to Sensitivity in Private Data Analysis[M].Theory of Cryptography. Springer Berlin Heidelberg, 2006:637-648.
[10] MCSHERRY F, TALWAR K. Mechanism design via differential privacy[C]// IEEE Symposium on Foundations of Computer Science. IEEE Computer Society, 2007:94-103.
[11] BLOOM B H. Space/time trade-offs in hash coding with allowable errors[J]. Communications of the ACM, 1970, 13(7): 422-426.
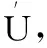
[13] BASSILY R, SMITH A. Local, private, efficient protocols for succinct histograms[C]//Proceedings of the Forty-seventh Annual ACM Symposium on Theory of Computing. ACM, 2015: 127-135.
[14] KAIROUZ P, OH S, VISWANATH P. Extremal mechanisms for local differential privacy[C]//Advances in Neural Information Processing Systems, 2014: 2879-2887.
[15] KAIROUZ P, BONAWITZ K, RAMAGE D. Discrete distribution estimation under local privacy[J]. arXiv preprint arXiv:1602.07387, 2016.
[16] DUCHI J C, JORDAN M I, WAINWRIGHT M J. Local privacy, data processing inequalities, and statistical minimax rates[J]. arXiv preprint arXiv:1302.3203, 2013.
[17] NGUYêN T T, XIAO X, YANG Y, et al. Collecting and analyzing data from smart device users with local differential privacy[J]. arXiv preprint arXiv:1606.05053, 2016.
[18] REN X, YU C M, YU W, et al. LoPub: high-dimensional crowdsourced data publication with local differential privacy[J]. IEEE Transactions on Information Forensics and Security, 2018, 13(9): 2151.
[19] BASSILY R, STEMMER U, THAKURTA A G. Practical locally private heavy hitters[C]//Advances in Neural Information Processing Systems, 2017: 2285-2293.
[20] QIN Z, YANG Y, YU T, et al. Heavy hitter estimation over set-valued data with local differential privacy[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016: 192-203.
[21] BUN M, NELSON J, STEMMER U. Heavy hitters and the structure of local privacy[C]//Proceedings of the 35th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems. ACM, 2018: 435-447.
[22] THAKURTA A G, VYRROS A H, VAISHAMPAYAN U S, et al. Learning new words[P].US: US15477921, 2018-02-08.
猜你喜欢
数学杂志(2022年5期)2022-12-02
指挥与控制学报(2022年4期)2022-02-17
新世纪智能(数学备考)(2021年5期)2021-07-28
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
爱你(2018年16期)2018-06-21
现代防御技术(2016年1期)2016-06-01
指挥与控制学报(2015年4期)2015-11-01
信息安全研究(2015年3期)2015-02-28
