
基于模糊C-均值和特征加权法的协同过滤推荐算法*
2018-06-28 02:44:44字云飞李业丽孙华艳
网络安全与数据管理 2018年6期
字云飞,李业丽,孙华艳,韩 旭
(北京印刷学院 信息工程学院,北京 102600)
0 引言
在当今大数据、人工智能(AI)时代,自媒体数据、出版数据、社交网络数据、电商数据等成为人们现实与虚拟生活的重要组成部分。为解决大数据时代的海量数据和用户隐性需求之间的矛盾,衍生了精准化和个性化推荐系统,且广泛应用于电商行业。个性化推荐系统为用户获取隐性需求节约了时间、空间等成本,也是解决信息过载的最佳途径。随着网购便捷度不断改善,用户对于网购依赖性极大增强,这也带来了用户隐性需求未能得到满足的问题,促使个性化、精准化推荐系统在电商行业显得前所未有的重要。传统协同过滤算法在电商、社交网络个性化推荐领域得到了较为成功的应用,但随着互联网数据呈几何级数增长、数据内容复杂度不断提高等问题的凸现,这些已有算法也暴露了自身的局限性,协同过滤推荐算法[1-3]的缺点有:(1) 数据的稀疏性问题;(2) 新物品问题;(3) 可扩展性问题。
现有协同过滤推荐算法[4-7]主要通过用户的历史行为、兴趣爱好等来实现个性化推荐,如根据用户A和B相似度高,A对项目i感兴趣,可以推测B也有可能对项目i感兴趣,但推荐过程中如何应用高效的方法精准划分项目候选集S成为推荐系统的核心,且候选集中每个子集i本身就是由多个模糊特征因素(x1,x2,…,xn)构成的,且多个特征因素集在项目中的权重又存在着差异,这会极大地影响推荐的精度和个性化。
很多学者基于协同过滤推荐算法[8-10]的不足,对其进行了不同维度的改进,但都没有得到彻底解决。为了解决传统推荐算法对用户-项目精准化、个性化推荐过程中存在项目评分信息不足、特征值模糊性及权重偏向导问题,本文提出了一种模糊C-均值和特征加权法的协同过滤推荐算法。通过用户在系统中的结构化、半结构化及非结构化数据记录,通过奇异值分解法把用户评分项分解为多个不同特征值来判断用户对未评项的喜好程度,然后再对C-均值计算出的候选集构建用户-项目特征因素加权模型,计算用户-项目核心特征因素的权值高低及价值大小,同时结合基于用户-项目协同过滤推荐算法的相似度等数据信息寻找最近邻,最后对用户-项目进行综合预判及终值优化,从而实现对用户显性、隐性需求的高效性、精准化、个性化的推荐。实验分析表明,该算法对于最近邻推荐的准确性有了极大的提高,同时,明显提升了个性化推荐系统精度,优化了推荐质量。
1 传统的协同过滤推荐算法
传统协同过滤(Collaborative Filtering,CF)推荐算法是根据用户-项目之间的评分、收藏、浏览信息等数据分析、计算相似度,从而寻找最近邻,最后实现对目标用户-项目的精准、个性化推荐。协同过滤推荐算法[11-15]分为基于用户的协同过滤推荐算法和基于项目的协同过滤推荐算法。
1.1 协同过滤推荐算法的实现
(1)用户-项目数据的收集及预处理。
(2)基于清洗后的数据来计算用户-项目的相似度,选取最近邻或相似度最高的N个用户或项目。
(3)把N个相似度最高的用户或项目推荐给对应的项目或用户。
1.2 相关度评价计算
协同过滤推荐系统中,D=(U,I,R)用来表示用户-项 目的数据源。U=(User1,User2,…,Usern)为用户集,|U|=n;I=(Item1,Item2,…,Itemm)为项目集,|I|=m。用户对项目的评分矩阵为Rm×n,其中Rij表示用户Useri对项目Itemj的评分,表1为评分矩阵R。
协同过滤推荐算法中计算机相似度的常用方法为Pearson相关系数法,通过用户对产品的评价数据计
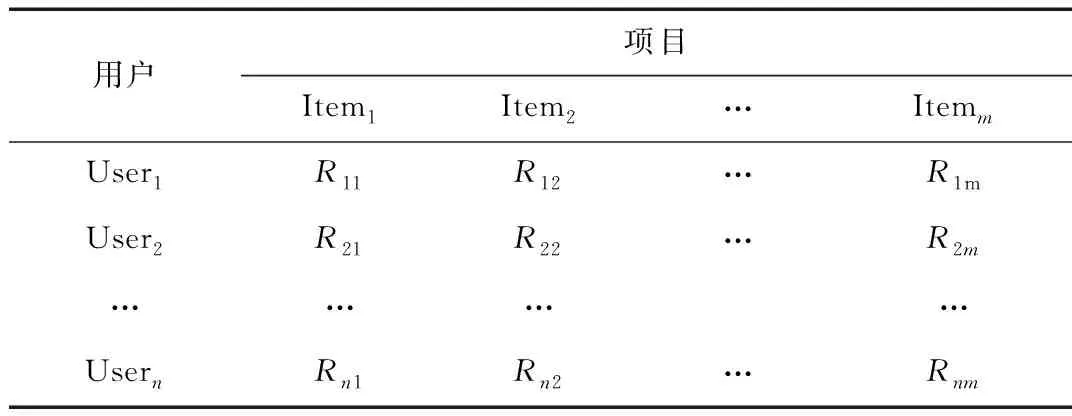
表1 用户-项目评分矩阵

(1)
计算相似度之后寻找最近邻,Zum为最近邻,对项目s预测评分的计算如下:
(2)
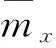
(3)
其中:Ts是项目总和,muw表示u对产品w的评价值。
2 模糊C-均值的候选集筛选
模糊C-均值聚类[16-17](Fuzzy C-Means clustering,FCM)算法是把项目集转化为模糊等价关系,通过最佳阈值法来划分项目集,划分为N个相似度较高的类。其过程为:根据选取的N个样本分为C类,而任何一个类都有自己的一个聚类中心,然后通过样本与聚类中心的距离,计算得到特征值相同或相似的最近聚类中心模糊子集,最后获得推荐项或用户的最佳候选集。描述过程如下:
给定数据集X={x1,x2,…,xn}包括N个样本,数据集可以划分为c(1≤c≤n)类,则模糊目标函数定义为:
(4)
(dik)2=xk-vi=(xk-vi)TA(xk-vi)
(5)
其中:U=[uik],uik∈[0,1]表示隶属度矩阵;V=[vi],i=1,2,…,c,vi为聚类中心矩阵集合,m=2为模糊指数;J(U,V)表示所选样本与各聚类中心的距离总和;A要求对称阵;dik是欧氏距离。
最小化聚类J(U,V):min{J(U,V)}则:
(6)
当多次迭代之后,聚类中心向量和隶属度矩阵为:
(7)
(8)
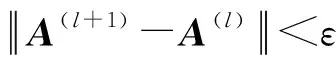
FCM算法实现过程:
Step1:确定类别划分数C,模糊指数设置为2(m=2),迭代停止参数ε;
Step2:对于聚类中心P初始化;
Step3:计算原数据的隶属度矩阵U;
Step4:通过公式(7)更新聚类中心矩阵C;
Step5:通过矩阵C计算得到所需的用户-项目之间的距离dik及隶属度矩阵U*,如dik=0,则uik=1;

Step7:根据最后计算得到的隶属度矩阵对用户-项目数据进行模糊聚类获得候选集。
3 对筛选候选集进行特征加权法
通过C-均值聚类之后得到的推荐候选集是一个属性值相似度较高的类,但要对用户-项目实现精准、个性化推荐仍存在着分类精度不高、个性化特征不足的缺陷。因为每一个推荐候选集的用户-项目信息本身又有特征值权重比,而特征值加权更能够客观、精准的表达事物本身,所以通过对C-均值聚类之后的候选集进行特征加权法能够更精准、个性化实现推荐结果。
在实际的推荐过程中,用户和项目都是由多个特征属性组成的,而特征属性[18-19]没有严格、准确的分界线,所有它们就构成了描述用户-项目本身的模糊特征集,而每一个模糊特征集是由若干个特征值相互作用而成的,且每一个特征因素又可以用一个特征模糊集来表示,此时的用户-项目论域可以表示为n个因素集的Descartes乘积,即
U=U1×U2×…×Un
设Ai∈Ui(i=1,2,…,n),Ai为某一个用户或项目特征因素集的子集,A∈U,A是由用户-项目特征因素集A1,A2,…,An复合而成的。
3.1 加权平均法
给一个用户推荐某一个项目是基于用户本身的兴趣爱好,而兴趣喜好是由用户的职业、性别、教育程度、生活环境等诸多因素决定和影响的,而每一个因素又由多个特征值构成,且每个特征因素决定项目或用户本身的比重又存在着差异,所以赋予特征模糊集中的特征因素在用户-项目中的权重比能够使推荐系统更加精准、高效和个性化。
若用户-项目A(u)是由n个子特征集A1(u1),A2(u2),…,An(un)累加而成的,则精准计算用户-项目特征本身为:
(9)
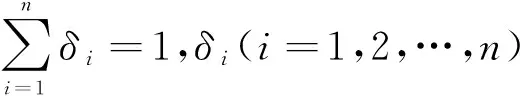
3.2 乘积平均法
当推荐用户或项目特征因素按比例变化时,如某一用户感兴趣的项目特征集A中有n个特征子集,其中每一个特征子集Ai是按比例变化的,可用乘积平均法计算机用户-项目推荐候选项的精度。
若用户-项目特征集A(u)是随(Ai(ui))αi按比例变化的,且每个特征子集Ai(ui)对特征因素集合A(u)都是必要的,当任意一个Ai(ui)为零时,A(u)都为零,则乘积平均法计算特征因素公式为:
=b(A1(u1))α1…(An(un))αn
(10)
其中:u=(u1,u2,…,un)∈U为用户-项目特征集,(α1,α2,…,αn)为特征因素在用户-项目中的权重向量,b为适当选取的常数,以保证A(u)∈[0,1]。
3.3 混合法
如果决定用户-项目特征因素集A(u)的子特征因素Ai(ui)可以分为两部分,一部分用户-项目的特征因素按权重比累加,另一部分做乘积,则计算用户-项目特征因素为:
(11)
其中:特征因素集u∈U,(α1,α2,…,αm),(δ1,δ2,…,δk)为两权重向量,且m+k=n+1,b为正实数,权重(α1,α2,…,αm)、(δ1,δ2,…,δk)通过实验取点。
3.4 特征因素加权综合法的协同过滤算法
根据前文论述,算法1实现向目标用户U1的精准、个性化推行过程。
算法1 基于特征因素加权综合法
输入:候选集信息D=(U,I,R)和权重向量
输出:为用户U1产生推荐集S
Begin:
(1)对用户及项目的原始特征因素进行预处理;
(2)选取用户U1访问记录的N个项目的特征因素值;
(3)Repeat
(4)Fori=1:n{
(5)对选取的特征因素值进行加权平均及乘积平均计算获得第i个特征值的重要程度(公式(9)、(10));
(6)取出每个项目特征因素最重要的前n个值,然后通过综合加权计算推荐项目A;
(7)}
(8)产生推荐集S;
End
基于因素加权综合法的协同过滤推荐算法通过对用户-项目特征因素值的加权研究,计算特征因素值对于用户-项目的重要程度来产生对目标用户或项目的推荐候选集,从而实现精准、个性化的推荐。
3.5 算法复杂度分析
算法复杂度包括时间和空间复杂度,它是有效衡量算法执行效率的指标。
计算目标用户-项目与筛选K个相似度较高的推荐项的过程是传统协同过滤推荐算法计算时间复杂度的核心,通过对推荐集及目标用户-项目之间相似度的计算,结合N个用户-项目的准确评分项得到。因此,计算M个用户-项目与目标用户-项目之间的相似度的时间复杂度为O(N×M),且N、M数量级一致,故时间复杂度为O(N2)。
基于C-均值和特征加权法的协同过滤推荐算法通过对目标用户-项目筛选出候选集及对候选集用户-项 目的特征值权重偏向计算其相似度得特征向量(V1,V2,…,Vs),然后通过相关度评价法(Pearson)计算特征向量与目标类别矩阵之间的距离。而C-均值和特征加权法计算相似度的时间复杂度为O(S×N),相关度评价距离时间复杂度为O(S×M),因此时间复杂度总和为O(S×N)+O(S×M)。因N、M数量级一致,而特征因素值S相比于N、M极小,则时间复杂度为O(N)。
4 实验仿真及分析
4.1 实验环境
算法性能分析的实验环境以Windows 7操作系统为实验支撑,相关配置为Intel Dual Core 2.5 GB处理器,编程语言Python,8 GB内存,2.60 GHz双核CPU,MySQL数据库。
4.2 数据集合
为了比较基于C-均值和特征加权法的协同过滤推荐算法与传统用户-项目协同过滤推荐算法之间推荐精度、效率的差异,实验数据基于University of Minnesota项目小组(GroupLens)提供并维护的MovieLens数据集(http://www.grouplens.org/)来进行真机实验。数据包括945个用户对于1 681部电影项目的100 000个评分数据信息,且一个用户至少存有对25部电影的评分记录,评分值为1~5,值越大用户喜好度越高。同时,实验数据按需求进行训练集TrainSet与测验集TestSet划分,且二者没有交集。
4.3 数据稀疏性
利用用户对于电影的评分值表达对电影的喜爱程度。数据的稀疏性为:
1-100 000/(945×1 681)=0.937 049
表明数据的稀疏性非常高。
4.4 度量标准
本文应用的统计精度测量中的绝对误差法(MAE)是度量推荐结果好坏的最有效方法之一。MAE值越小表明推荐精准度及效果越高。
(12)
其中:|itemtestset|表示项目集中评分项的个数,predi{pred1,pred2,…,predN}为对于算法预估的评判分数,qi{q1,q2,…,qN}为测试数据的实际分数。
4.5 实验结果
实验基于MovieLens数据集对传统的协同过滤推荐算法与基于C-均值和特征加权法的协同过滤推荐算法进行了平均绝对误差值的比较分析,如图1所示。最近邻的数量也将影响推荐的效果,过少将会降低推荐的精准性,过多将极大增加算法复杂度,实验中选取最近邻的数量为10~40。
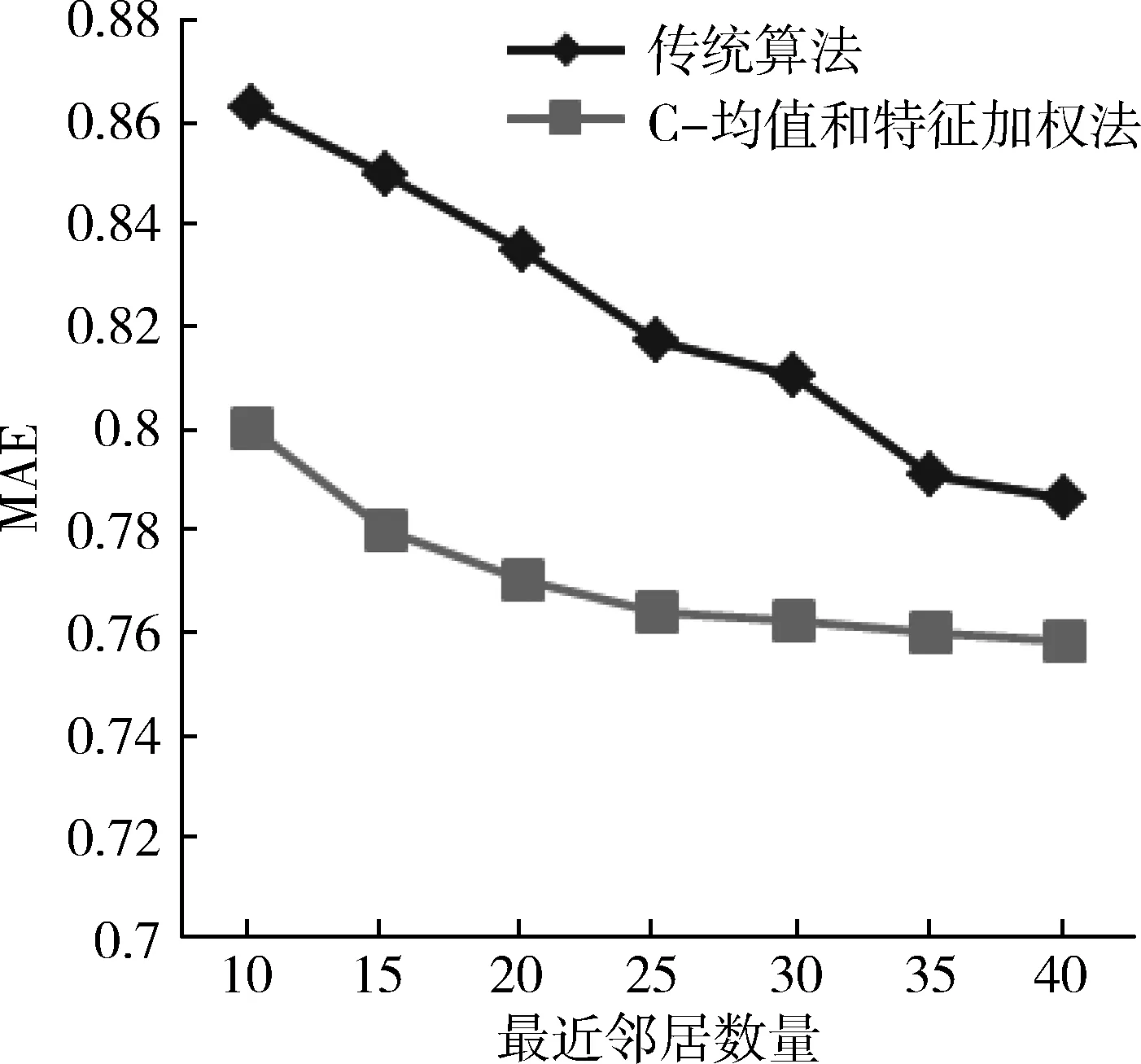
图1 两种算法的MAE比较
通过图1可知,随着最近邻居数量的增大,无论是传统过滤推荐算法,还是基于C-均值和特征加权法的协同过滤推荐算法,平均绝对误差值(MAE)都呈下降趋势,但不管近邻数值多少,只要最近邻数相同,基于C-均值和特征加权法的协同过滤推荐算法的平均绝对误差值(MAE)都低于传统推荐算法,由此表明本文的推荐算法具有较高的精准度。所以采用基于C-均值和特征加权法的协同过滤推荐算法对提高推荐系统的精准度及执行效率都有明显的帮助。
5 结束语
本文提出的基于C-均值和特征加权法的协同过滤推荐算法首先对样本数据进行C-均值聚类筛选候选集,再通过对用户-项目特征因素值权重向量的划分,计算每一特征因素值对于用户-项目的重要程度,从而精准划分候选集,提高相似度的度量。各推荐算法中相似度度量好坏将直接影响推荐项目或用户的精准度和个性化。同时,该算法通过对项目或用户特征值的内外距离计算或加权计算特征因素集,都能减小稀疏性带来的负面影响。如何通过矩阵结合时间序列、云模型等来扩展因素加权综合法的推荐算法以及应用于相关领域,是下一步研究的方向。
[1] Huang Hao, Huang Jianqing, ZIAVRAS S G, et al. A personalized recommendation algorithm based on Hadoop[C]//2015 5th International Conference on Electronics Information and Emergency Communication (ICEIEC).IEEE,2015:406-409.
[2] 秦光洁,张颖.基于综合兴趣度的协同过滤推荐算法[J].计算机工程,2009,35(17):81-83.
[3] 韦素云,业宁.基于项目类别和兴趣度的协同过滤推荐算法[J].南京大学学报(自然科学),2013,49(2):142-149.
[4] ADOMAVICUS G, TUZHILIN A. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6): 734-749.
[5] PARK C, KIM D, OH J, et al. Improving top-K recommendation with truster and trustee relationship in user trust network[J]. Information Sciences, 2016, 374:100-114.
[6] PAN J C, ZHANG X M, WANG X. Improved singular value decomposition recommender algorithm based on user reliability [J]. Journal of Chinese Computer System, 2016,37(10): 2171-2176.
[7] 孙光福,吴乐,刘淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013(11):2721-2733.
[8] 王伟,王洪伟,孟园.协同过滤推荐算法研究:考虑在线评论情感倾向[J].系统工程理论与实践,2014,34(12):3238-3249.
[9] PERA M S, NG Y K. Analyzing book-related features to recommend books for emergent readers[C]// Proceedings of the 26th ACM Conference on Hypertext &Social Media. ACM, 2015: 221-230.
[10] 荣辉桂,火生旭,胡春华.基于用户相似度的协同过滤推荐算法[J].通信学报,2014(2):16-24.
[11] 李豪,张海英,张俊.一种基于用户兴趣分析的协同过滤推荐算法[J]. 微型机与应用,2017,36(15):25-28.
[12] Zhang Qinghua, Xu Kai, Wang Guoyin.Fuzzy equivalence relation and its multigranulation spaces[J]. Information Sciences,2016, 346-347(C):44-57.
[13]Hu Liang, Wang Wenbo, Wang Feng, et al. The design and implementation of composite collaborative filtering algorithm for personalized recommendation[J]. Journal of Software, 2012: 2040-2045.
[14]Yang Hai. Improved collaborative filtering recommendation algorithm based on weighted association rules[J]. Applied Mechanics and Materials,2013:94-97.
[15] Liu Fengming, Li Haixia, Dong Peng. A Collaborative filtering recommendation algorithm combined with user and item[J]. Applied Mechanics and Materials,2014:1878-1881.
[16] Duan Lingzi,Yu Fusheng, Zhan Li.An improved fuzzy C-means clustering algorithm[C]//2016 12th International Conference on Natural Computation, 2016:861-865.
[17] ZARITA Z, ONG P. An effective fuzzy C-means algorithm based on symmetry similarity approach[J]. Applied Soft Computing Journal,2015, 35(C): 433-448.
[18] Luo Xin, Zhou Mengchu, Xia Yunni, et al. An efficient non-negative matrix-factorization-based approach to collaborative filtering for recommender systems[J]. IEEE Transactions on Industrial Informatics, 2014, 10(2): 1273-1284.
[19] PARK Y, PARK S, JUNG W, et al. Reversed CF: a fast collaborative filtering algorithm using a K-nearest neighbor graph[J]. Expert Systems with Applications, 2015, 42(8): 4022-4028.
猜你喜欢
文苑(2020年4期)2020-05-30 12:35:12
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
新闻传播(2018年12期)2018-09-19 06:27:10
电子测试(2017年15期)2017-12-18 07:19:27
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
汽车与新动力(2016年6期)2017-01-04 10:50:48
火控雷达技术(2016年3期)2016-02-06 02:30:28
智能系统学报(2015年4期)2015-12-27 09:38:39
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
电子设计工程(2015年6期)2015-02-27 12:04:53
