
时政名人姓名检测系统的设计及其在字幕制作中的应用
2018-06-26 10:57:50李海彬
视听 2018年7期
□李海彬
一、引 言
电视时政新闻的采访对象主要是国内外的一些时政名人,为他们出字幕人名条是字幕员的日常工作之一。这个工作看似简单,然而却是最容易犯错误的地方,特别在大型会议的电视直播过程中,由于值班时间长、制作任务重等客观原因,加上心情紧张等主观因素,会增加人名字幕出错的概率,从而造成播出安全事故。
如何将此类错误发生的概率降低呢?我们认为应该通过技术的手段去解决,而不仅仅只通过人工校对审核的方式,在本文中将介绍自主研发的一个时政名人姓名检测系统。
二、立项背景
我台新闻频道在某次电视直播中,将某位领导的字幕人名条错打为某明星的名字,结果造成了播出事故。事后经分析发现,前线记者在文稿系统中录入稿件时使用的是拼音输入法,由于两个名字的拼音相近而造成原稿存在错误,而字幕员将文稿串编单里的新闻标题复制到字幕机软件制作人名条时,因为检查上的疏忽而造成了本次事故。
这个教训是深刻的,为了在今后的工作中减少此类事件的发生,频道领导认为需要建立时政名人姓名检测系统,并根据字幕员的工作习惯,要求将此功能集成到新闻文稿系统中。
三、检错算法的难点
初步的思路是建立一个时政人名库,将国家和省内主要领导的名字,以及一些外国国家首脑的中文译名录入库中,检错系统以此为标准进行字符串匹配,将打错的名字标注出来。
假设某位时政名人的名字为“张小军”,当天有一条关于他的新闻如“张小军到北海调研”,结果名字中“军”错打成“君”,此时系统可以用彩色字体明显地标注出错之处,如“张小君(红字显示)到北海调研”。
检错算法的原理是将人名库里的名字与新闻标题里的内容进行逐字匹配,从而找出可能错误的名字,如果要完成如上的检测,算法的一般流程如下:
1.将姓名逐字分拆为“张”“小”“军”三个字;
2.先查找“张”字的位置,在找到后检测其后的字符是否为“小”及“军”,从而找到错误的位置;
3.如果“张”字没有找到,就从“小”字开始查找,找到后检测其后字符是否为“军”字,如果姓氏出错了,则报错。
在姓名由3个文字组成的情况下,这种算法可以检测出1个文字的错误,如“章小军”“张晓军”等,而如果出现2个以上的文字错误就无法判断对错了。对于因拼音输入法的问题造成两个名字的中文汉字完全不同时,根本就没有办法检错。
另外,这种算法存在一个重要的漏洞,即当新闻标题中未包含人名时,则检测的结果也可能会出错。例如新闻标题“我区边防某部队参加国庆60周年大阅兵”,标题中并未包含人名,但假如人名库中存在“李国庆”这样的名字,此时就会产生错误的检测了。人名库记录的人名数量越多,检测错误的概率就会越高。
因此,在现有的技术条件下,要完成上面所说的姓名检错基本不可能。
四、设计思路
既然无法完成“姓名检错”,那就做一个“姓名检对”功能,即通过人名库里的名字,与新闻标题进行字符串匹配,如果匹配成功则表示名字录入正确,将正确的名字采用不同的颜色标注出来,使字幕员可以一眼分辨出错对。
假设人名库中记录了这些名字:张福明、刘正军、马峰、何洪海。将这些名字与某天的新闻串编单标题进行逐一匹配,其结果应该如表1所示。

表1 新闻串编单
其中第1~3条匹配成功了;第4条将“何洪海”打错成了“何红海”,匹配失败;第5~6条新闻标题中没有人名库中的名字,匹配失败。
实现这种检测的软件算法就简单多了:将人名库中的名字分别与新闻串编单的新闻标题逐一进行匹配,假设人名库中的人名数量为N,新闻条目为M,需要进行N×M次检测即可得到全部检测结果。
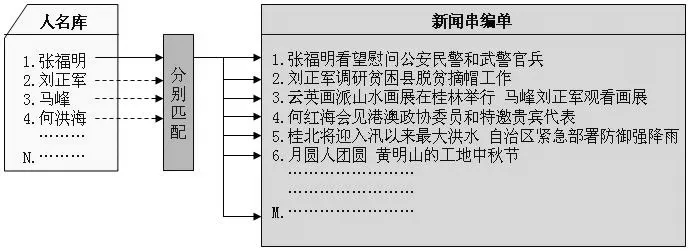
图1 人名检测算法
那这种算法的实际检测速度如何呢?该系统预计人名库的人名数量小于200,新闻串编单条目小于100,新闻标题的平均字符数小于100字节。则最多需要检测200×100=20000次,遍历字符串总长度为2MB字节,经测试其运算所需时间非常少,可以忽略不计。
五、实现方法及效果
(一)建立人名库
在文稿数据库中增加一个数据表,表名为leader,字段如下:Names nchar(20):存储姓名
BkText ntext:存储备注信息
增加人名库编辑模块,用于动态更新信息,如图2。
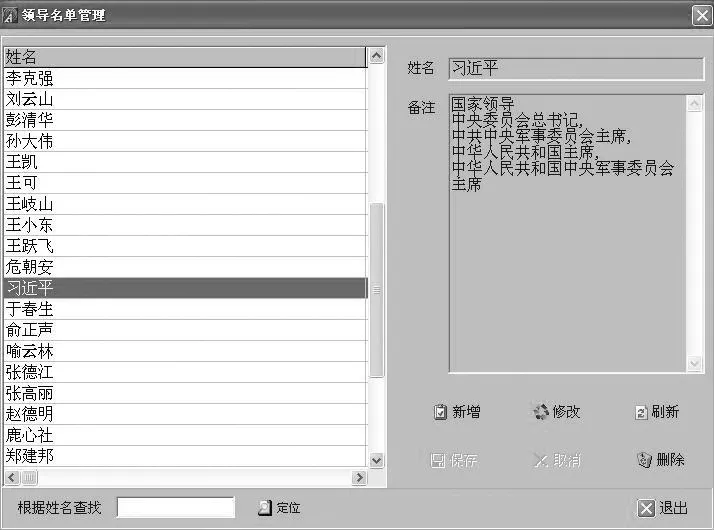
图2 人名库编辑管理模块
(二)检测及标注方法
在完成检测后,如何将录入正确的人名区分出来呢?这里采用HTML网页封装方式。即将检测结果输出为HTML文件,对于匹配成功的名字使用红色字显示,而其他内容使用黑色字显示。
HTML又称为超文本标记语言,其结构包括“头”部分和“主体”部分,通过标记符号来标记要显示的网页中的各个部分,其源程序为文本文件,不需要编译执行,浏览器按顺序阅读HTML文件内容,然后根据标记符解释和显示其标记的内容。
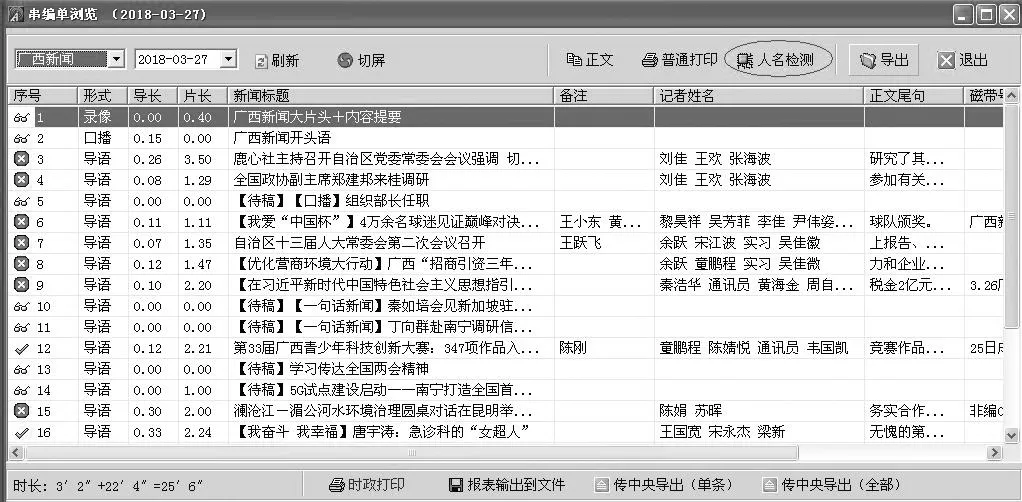
图3 《广西新闻》串编单模块
由于涉及HTML结构的输出,因此在算法步骤上做了一些改动,首先是将串编单里的全部新闻标题进行HTML结构封装,合成为一个长的字符串,之后再进行人名匹配和标注。在文稿串编单模块增加一个功能按钮,如图3。
点击“人名检测”功能按钮,检测功能将按以下步骤工作:
1.在内存中创建一个最基本的HTML文件头部结构和表格结构:
| 标签封装为1行2列的表格: |
4.循环调取人名库的每个名字,分别与内存中的HTML格式字符串进行匹配;
5.将匹配成功的名字进行字符串替换,加上字体颜色标签:如“张福明”替换为“”;
6.将内存中的HTML格式字符串输出到文件,通过浏览器控件显示。
执行检测的结果如图4。从图中可以看到,第3、4、9、10、11条新闻标题中,成功检测出人名库里记录的名字,并使用红色字做了标注;而第16条新闻标题中虽然也出现了一个人名“唐宇涛”,但由于这个名字没有录入到人名库中,因此没有标注出来。

图4 人名检测结果
通过图4的检测结果,字幕员很容易区分哪些新闻标题中时政名人的姓名是正确的,对于没有提示的新闻标题,重点进行检查即可。在确认无误后,即可直接将网页里的新闻标题复制到字幕软件中进行制作。
六、结语
检测系统虽然无法从根本上解决字幕人名条中错打时政名人名字的问题,但通过对匹配成功的人名进行标注提示,提高了字幕员人工校对的效率,也大大降低了字幕出错的概率。检测系统在2017年10月初建成并投入使用,为2017年十九大、2018年广西“两会”和全国“两会”等重要保障期的新闻安全播出做出了贡献。
猜你喜欢
电脑爱好者(2022年17期)2022-05-30 10:48:04
活力(2019年22期)2019-03-16 12:49:06
活力(2019年22期)2019-03-16 12:48:00
喜剧世界(2016年9期)2016-08-24 06:17:26
唐山文学(2016年11期)2016-03-20 15:25:57
人间(2015年22期)2016-01-04 12:47:26
新闻传播(2015年22期)2015-07-18 11:04:06
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
网络安全与数据管理(2011年17期)2011-07-25 00:33:50
