
面向文本的标签云可视化度量模型的研究
2018-06-14 07:15马明明
软件 2018年5期
马明明,胡 俊
(北京交通大学,计算机与信息技术学院,北京 100044)
0 引言
文本是数据传播和存储的主要形式之一。如何快速理解文本的主要内容及不同文本之间的关系是可视化技术应用研究的一个重要方向。随着可视化技术的发展,研究者提出了许多有效的文本可视化技术,如标签云可视化技术[1-2]与文本语义结构树[3]等,这些技术在方法、适用对象,以及实现方式等方面均具有不同的特点。如何建立可视化技术应用效果的评价模型,从多维度指标对文本可视化技术进行有效的评测,是可视化研究领域的热点之一。
标签云可视化技术是一种根据字体大小、颜色及深浅等方式对文本中关键词进行展现的一种可视化方法。通过度量指标对文本的标签云可视化技术进行有效合理的定量评测[4-5],既有助于确定技术应用的效果,也有助于可视化技术[6]应用方法的研究。
可以看出,目前对可视化方法的研究主要在技术的建立,以及对技术的分析与改进等方面,对技术应用评测[7]方面的研究还处于发展阶段,具体到文本[8-9]的标签云可视化技术应用,也缺乏有效的评价方法[10-11]。本文工作重点是针对标签云可视化技术提出三级指标度量模型,运用模糊层次分析方法[12]确定各级指标权重,并根据计算出的指标值对可视化效果进行量化分析。
1 基于文本的标签云度量模型
针对文本的标签云技术应用的度量模型的基本组成部分是根据标签云应用特点提出的三级度量指标。
1.1 数据规模指标
数据规模[4]是其它指标提取与量化的基础,标签云可视化通过单词的频度从大到小展现在屏幕中,它是衡量标签云可视化效果的一个重要指标。
定义1:文本中单词的集合为 U = { a1, a2,… ,an},其中 ai( i = 1 ,2,… ,n )代表某个单词,单词在文本中的出现个数用 n ( ai)表示。文本中多次出现且对文本主题影响小的停止词集合为 S = { b1, b2,… ,bm}。如英文文本中的介词与代词等可属于停止词。
(1)彩信词的筛选
确定区域中能够展示的单词数是有限的,在对文本进行可视化前需要将文本中的单词进行筛选,选取的单词称作文本的采信词。可以根据文本的单词集与停止词集对文本进行过滤,得到文本的单词集合U-S,通过计算得到集合U-S中的单词在文本中出现的频数,在选取一个适当的频数阈值h后,可以通过筛选得到采信词集 D = { a1, a2,… ,an1},其中对任意的 x ∈ D, n ( x ) ≥ h 。
(2)彩信词密度
根据定义 1,可以得到文本中单词总数为,采信词集D中单词a的密度可定义为p( a ) = n( a ) /N,a∈D,则文本的采信词的密度可以表示为:

1.2 认知复杂度指标
用户认知复杂度[12]可以用来衡量可视化技术是否能让用户便捷观察、搜索原数据信息及隐含模式,标签云可视化认知复杂度是由彩信词方度及方向认知度构成。
(1)彩信词方度
标签云可视化技术实现中是将每个单词转换成图片并放置到展现区中,采信词方度用于近似描述单词可视化区域的长宽比,定义为:

其中length和width分别对应单个单词图片的长和宽,其值与单词包含的符号数相关。采信词集D中全部单词的方度均值定义为文本的采信词方度,即为:

单词字体的大小取决于该单词在文本中的权重。权重大的字体从视觉上引人注目,然而某些权重较小但单词长度较大的单词,如“antidisestablishmentarianism”,其采信词方度较大,同样也会引起关注。
(2)方向认知度
标签云中词云角度增加,则其认知复杂度相应提高,认知复杂度与角度成正比。角度的变化范围通常可设定为[0, 90 °],若单词 ai的可视化展现出的角度为αi度,则该单词的方向认知度和可视化展现出的方向认知度(Direction Recognition)可分别定义如下:

显然,此时方向认知度的取值范围是[0,1]。方向认知度的值越大,认知复杂度越高。
1.3 视觉表现及效果指标
视觉表现及效果[12]可以用来衡量呈现图像的辨识度及视觉效果。度量标签云可视化视觉表现及效果的指标是由色彩比重及空间利用度构成。
(1)色彩比重
标签云中的每个单词显示不同颜色,颜色种类的多少影响视觉效果。采信词的数目是1n,颜色的种类数目是 c,色彩的种类越多,视觉效果越差,色彩比重(Ration of Color)表示为:

(2)空间利用度
展现区域是指文本可视化的区域。将文本的彩信词进行可视化时,会出现未被利用的空白区域,空间利用度可以用于衡量展现区域的利用程度。单词ai( i = 1 ,2,… ,n1)所占区域面积为 si,展现区域的宽和长分别为WIDTH和LENGTH,其面积 S= W IDTH×LENGTH,则空间利用度(Space Utilization)可定义为:

标签云可视化技术应用中将进行碰撞检测,可以通过对空白区域进行填充来充分利用展示空间。
1.4 度量模型指标的权重计算
可以根据定义的指标来建立三级层次度量模型,其中不同层级指标的依赖关系:一级指标包括总评分;二级指标包括数据规模、认知复杂度、视觉效果及表现,其中数据规模包含三级指标彩信词密度,认知复杂度包含三级指标彩信词方度、方向认知度,视觉效果及表现包含三级指标色彩比重、空间利用度。
根据度量模型的特点采用模糊层次分析方法确立度量模型各级权值。对二级指标中的元素运用指标比较数量标度进行两两对比,构造出3*3模糊互补矩阵 B = ( bij)3×3,同时根据模糊一致判断矩阵的计算方法,将模糊互补矩阵 B = ( bij)3×3变成模糊一致判断矩阵(i = 1 ,2,… ,n )。B和R矩阵如下所示:

根据方根法得到“数据规模”、“用户认知复杂度”和“视觉表现及效果”对一级指标影响的权重是 w = ( 0.3 1 62,0.4199,0.2639)。利用模糊层次分析法对二级指标对应的三级指标进行层次单排序并计算它们的权重。各自的权重如下表1所示。
根据上述的二级和三级指标的层次单排序,对“采信词密度”、“采信词方度”、“方向认知度”、“色彩比重”及“空间利用度”评价指标进行层次总排序,结果如下表2所示。

表2 层次总排序Tab.2 To tal sort weight
2 评价分数计算
本文建立的指标的量纲和数量级不同,需要对各个指标进行无量纲化处理。这里采用最大最小正规化法,计算方法如下:

其中,Xi表示指标 i的原始值,Yi表示Xi的无量纲化值,Ximin与Ximax分别为指标i的最小值与最大值。
2.1 评价分数算法模型
根据评价模型和相应指标的计算公式,设计出文本频次分析的算法流程并用Java编程语言实现,整体流程分为文本处理、可视化图片展示以及指标计算三个过程,算法流程如下:
(1)初始化待处理文本的可视化参数,包括需要展示的单词数量与颜色数量、展示单词图片的背景颜色与大小、字体最大最小值及单词最小长度等。
(2)计算文本总单词数量。
(3)根据过滤条件,包括单词长度过滤,停止词过滤和频数大小过滤等,从文本单词集中获得选定文本需要展示的单词集合,即采信词集合。
(4)根据设置参数计算需要返回单词的详细信息,包括字体大小、颜色个数等。
(5)初始化图片画布的相关信息和单词的相关信息,将单词渲染到画布上进行展示。
(6)统计展示单词所占画布总面积的比率,统计各个方向的长宽比例之和。
(7)根据计算公式,获得彩信词密度、方向认知度、色彩比重、方度平均值、方度最大值和空间利用度等用于度量分析的指标值。
2.2 实验样本数据计算结果
实验中,从百度学术下载关于 BP与数据可视化等相关英文论文,运用标签云可视化技术对其可视化,并进行指标计算与度量分析。针对源于某篇论文进行采信词选取及可视化,共得出300多条数据,其中一个的可视化结果如图1所示。

图1 文本的标签云可视化结果Fig.1 The result of tag cloud visualization
计算出彩信词密度为 0.1118,方向认知度为0.63,色彩比重为 0.15,彩信词方度为 2.0929,空间利用度为 1.7112。此处需要对彩信词方度以及空间利用度进行无量纲化,通过300条数据得到的彩信词方度以及空间利用度的最大值最小值如下表 3所示。无量纲化处理后,得到最终的彩信词方度为0.2616,空间利用度为0.1711。

表3 无量纲化最大最小值Tab.3 Nondimensionalization about maximum and minimum
按照度量模型层次关系依次计算各级指标的评分以及总评分。
“数据对象规模”由“采信词密度”表示,可按0.1118*100计算,即得11.18分。“用户认知复杂度”与“采信词方度”和“方向认知度”正相关,计算表达式为 0.6044*采信词方度+0.3956*方向认知度,计算结果为0.4073*100,即得40.73分。“视觉效果及其表现”与“色彩比重”正相关同时与“空间利用度”负相关,计算公式为 0.5505*色彩比重+0.4495*(1-空间利用度),计算结果为0.4552*100,即得 45.52分。标签云可视化度量模型与“数据规模”和“用户认知复杂度”负相关,与“视觉效果及其表现”正相关,因此标签云可视化度量模型总评分的计算公式为 0.3162*(1-数据对象规模)+0.4199*(1-用户认知复杂度)+0.2639*视觉效果及其表现,计算结果为0.6498*100,即得64.98分。
3 实验及其结果分析
可以针对单个文本、多个文本,以及特殊文本来调整算法中输入的彩信词数量与色彩种类数目等来进行可视化度量指标分析。
运用多维度折线图进行数据分析,由于数据的范围变化不同,为使各个数据在同一范围显示出趋势,对数据同样进行无量纲化处理,进行相应的扩展或缩小,例如:彩信词密度范围基本在[0,1],总评分在[1,100],将彩信词密度扩展 100倍;同样的,方向认知度、色彩比重扩大100倍;方度平均值、空间利用度扩大10倍;彩信词数量缩小2倍。实验中分析的单文本论文是An Interactive System for Set Reconstructi- on from Multiple Input Sources,简称AISSRMIS。
(1)单文本彩信词密度对各个数据结果影响
针对AISSRMIS文本,控制色彩比重不变,控制彩信词的数量逐步递增 5个,即彩信词密度递增,利用评价分数算法实现的编程获得100组实验数据。对所获得的结果数据根据度量模型及相应的指标进行度量分析,得到图2的彩信词指标变化折线图。
根据折线图可知,随着单词的递增(即彩信词密度的增加),因为标签中的单词放置的方向是随机产生的,所以方向认知度基本上保持在50%左右上下波动;方度的最大值呈现梯度上升趋势且逐渐趋于平稳;空间利用度随着彩信词数量的递增而增加,最终趋于一个稳定值;根据度量模型计算的评价总分数稳步递减,视觉表现及效果变差。
(2)单文本色彩比重对数据结果及视觉表现的影响
针对 AISSRMIS文本,控制彩信词数量不变(200个),单词颜色种类以5开始增加5种颜色,最大颜色种类数是200种,根据评价分数算法程序获得40组实验数据,得出图2中色彩比重指标折线图。
根据折线图所示,当彩信词数量不变时(即彩信词密度不变),方向认知度是随机产生,所以变化幅度很小;随着色彩比重的增加,总评分逐渐提高,相应的视觉表现及效果增加。
(3)单文本方向认知度对数据结果及视觉表现的影响
针对AISSRMIS文本,控制彩信词数量和颜色种类数量不变(彩信词数量200,颜色种类20),根据评价分数算法程序随机产生大量实验数据,获得了10000条数据,对方向认知度相同的数据进行去重获得100组不重复的实验数据,得出图3中的方向认知度指标折线图。根据折线图所示,可以得出随着方向认知度数据的增大,最终的总评分越来越小,相应的视觉效果越来越差。
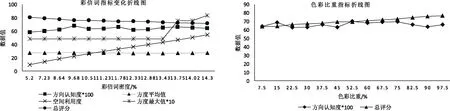
图2 彩信词与色彩比重指标折线图Fig.2 Word and color weight index line charts

图3 方向认知度指标与多文本数据变化折线图Fig.3 Direction recognition index and multi - text data change line charts
(4)多文本数据之间的关系
从百度学术上搜索ACM以及SCI的相关英文论文,控制彩信词数量为200个,色彩种类为50种。利用评价分数算法程序对150篇英文文本进行分析获得150条实验数据,得到图3中的多文本数据变化折线图。
根据折线图所示,有个别文本彩信词数量比设定的彩信词数量少,空间利用度以及方度平均值无明显规律变化且相差不大且总评分也无明显变化,这说明各个文本之间的各个指标数据无明显关系,现有的度量模型没有针对多文本之间的关系进行分析。
(5)特殊文本的数据变化
根据上述(4)的多文本情况,找出输入200彩信词最终结果显示小于200彩信词的一个英文文本Keeping Apace with Progress in Natural Language Processing,同时将彩信词数量由5逐步递增至160,根据评价分数算法程序得到实验数据并对其各个数据变化规律进行分析,得到图4中的特殊文本数据变化折线图。
根据折线图可知,该英文文本最多能够在展现区显示出151个彩信词,之后趋于一致,同时其方度平均值、方度最大值以及空间利用度均趋于一致。
(6)不同类型英文文本数据对比
从 ScienceDirect eBooks-Mathematics-journals中找出三组(Advances in Accounting、biology和physics)类别的英文论文,控制彩信词的数量为200,颜色种类为50,根据评价分数算法程序得到实验数据,得到如图4所示的三种类型文本指标折线图。由图所示不同类型总评分相差无几,也就是说数据的总评分和英文文本类型几乎无关联。
4 总结

图4 特殊文本数据与三种类型文本指标折线图Fig.4 Special text data and three types of text index line charts
本文给出了一组针对标签云可视化结果进行度量分析的指标,并运用模糊层次分析方法得出各指标影响标签云可视化结果的权重。通过使用算法实现,计算出针对文本的标签云可视化结果的指标值,以此进行有关文本的标签云可视化效果的分析。所做实验标明,针对同一篇英文文本,随着彩信词密度的增加,方度最大值和空间利用度会相应地增加;总评分减少,视觉表现效果显示会变差;总评分与色彩比重呈反比关系;对于特殊文本的可视化,当彩信词数量在一定范围内时,方度平均值、方度最大值,以及空间利用度均趋于一致。针对多文本的可视化结果分析也可以看出,设计的指标之间是相互独立。
[1] Jin Xu, Yubo Tao, Hai Lin. Semantic word cloud generation based on word embeddings[J]. IEEE Pacific Visualization Symposium, 2016: 239-243.
[2] 任磊, 杜一, 马帅, 等. 大数据可视分析综述[J]. 软件学报, 2014, 25(9): 1909-1936.
[3] H. Paul Zellweger ArborWay Labs, Rochester MN. Tree Visualizations in Structured Data Recursively Defined by the Aleph Data Relation[J]. IEEE Conference Publications, 2016:21-26.
[4] 曾晶. Radviz可视化技术度量模型的研究[D]. 北京: 北京交通大学图书馆, 2011.
[5] 高芳. 平行坐标可视化的度量模型研究[D]. 北京: 北京交通大学图书馆, 2009.
[6] 岳钢, 王楠. 网络学习中知识可视化效率研究[J]. 软件,2015, 36(2): 92-96.
[7] Jimmy Johansson, Camilla Forsell. Evaluation of Parallel Coordinates: Overview, Categorization and Guidelines for FutureResearch[J]. IEEE Transactions on Visualization and Computer Graphics, 2016, 22(1): 579-588.
[8] 陈海红. 多核SVM 文本分类研究[J]. 软件, 2015, 36(5): 7-10.
[9] 谢子超. 非结构化文本的自动分类检索平台的研究与实现[J].软件, 2015, 36(11): 112-114.
[10] Florian Heimerl, Steffen Lohmann, Simon Lange, et al. Word Cloud Explorer: Text Analytics based on Word Clouds[J].IEEE Conference Publications, 2014: 1833-1842.
[11] Rita Oliveira, Telmo Silva, Jorge Ferraz de Abreu. Development and evaluation of Clouds4All interface: A tag clouds reader for visually impaired users[J]. IEEE Conference Publications,2015: 1-6.
[12] 雷莹. 基于Web的可视化数据挖掘分析平台及可视化度量模型的研究与实现——树图可视化技术的度量模型研究[D]. 北京: 北京交通大学图书馆, 2014.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
数学年刊A辑(中文版)(2019年3期)2019-10-08
新产经(2018年7期)2018-02-20
中国医药指南(2018年22期)2018-01-22
中国医药指南(2018年33期)2018-01-20
中国学术期刊文摘(2016年1期)2016-02-13
中国继续医学教育(2015年6期)2016-01-07
通信技术(2011年3期)2011-03-06
