
基于动态用户画像的信息推荐研究①
2018-06-14 08:49吴翔宇解本巨
计算机系统应用 2018年6期
刘 勇,吴翔宇,解本巨
1(青岛科技大学 信息科学技术学院,青岛 266061)
2(青岛惠泽创建信息新技术有限公司,青岛 266000)
“信息过载 (information overload)”[1]效应是互联网高速发展的副产物,为了解决“信息过载”问题,研究人员提供了两种方案,一种是搜索引擎,另一种为推荐系统.前者通过检索关键字对海量信息进行筛选,列出用户可能用到的信息列表供用户选择;后者通过综合分析用户历史数据(兴趣、行为)、用户所在场景、环境等,把用户最为感兴趣的内容主动推送给用户,相较于前者,推荐系统的普适性、智能化程度以及精准度都存在一定的优势[2].现如今推荐技术已经成为学术研究的热点之一,在社交网络、电子商务、广告投放等诸多领域独占鳌头[3].
目前主流的推荐方法可以分为:基于内容的推荐(content-based recommendation)、基于协同过滤的推荐(collaborative filtering-based recommendation)、基于知识的推荐(knowledge-based recommendation)以及组合推荐(hybrid recommendation)[4].针对应用场景和环境的不同可以选择不同的推荐方式.
在网络信息推荐领域,用户和信息交互只存在浏览行为,并没有对项目进行评分,用户的兴趣偏好隐含在浏览历史当中,所以必须通过分析用户行为来挖掘用户的兴趣[5].传统的基于标签的信息推荐,通过分析用户浏览记录给用户打上“兴趣-权重”标签然后进行推荐,在一定程度上忽略了用户兴趣的变化趋势,随着时间的推移,推荐精度往往会降低,影响用户体验.
所以,要想提高信息推荐的精度,需要一种可以随时间增长,动态更新用户推荐候选项的方法,基于这个设想,本文提出一种基于动态用户画像的方法,该方法建立在文本分类和用户行为动态分析的基础上,后续相关实验证明了该方法的可行性.
1 文本处理和分类
在进行文本信息的推荐之前,首先要对推荐集合中的文本进行处理.本文使用支持向量机(SVM)文本分类法[6,7]对文本进行分类处理,其核心思想是在n维向量空间内寻找一个最优分类的超平面,表示为:

SVM文本分类的主要步骤大致可以分为:文本特征提取、文本特征表示、文本分类.
1.1 文本特征提取
首先对文本进行分词,然后对文本中的停用词和单字词进行过滤.计算给定文本中词语的词频:

其中,ni,j为 该词在文本dj中出现的次数,分母为总词语量.选取特征之前,假设每个特征具有独立性,然后选取若干词频较高的词语作为该文本的特征词集合,将文本表示为n维特征向量:

其中,n为选取词语的个数.
1.2 文本特征表示
特征词的权重使用TF-IDF公式进行计算,公式如下所示:

其中,t fik表示词tk在文本中的词频,N为所有的文本,nk为包含特征词tk的文本数.
1.2.1 归一化处理
因为文本长度偏差会影响特征词的权重计算,所以要进行归一化处理,将选定的特征词权重规范到一定区间内,其公式为:
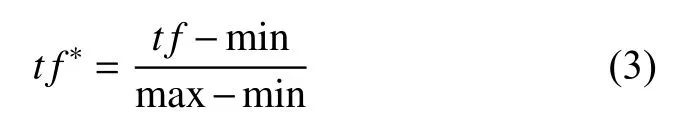
其中,t f∗为标准化后的词频,m in为该特征词在所有文本中的最小词频,max为最大词频.
1.3 文本分类
通过上述过程计算就可以得到文本的n维特征向量:

其中,ti表示特征词,wi(d)为该词在文本中的权重,n为特征词的个数.
由上述步骤就可以将文本量化为可进行计算的数据结构,然后通过相似度计算就可以确定目标文本的所属分类,经文本处理和分类后的文档集可以表示为如下的向量集:

其中,d ocumentCollection为向量余弦相似度较高的一类文本集合,N∗为不含0的自然数集.
2 动态用户画像
2.1 用户画像
用户画像是通过综合分析用户数据,抽象出的一个可代表用户各项维度的标签模型,其中维度一般包括:人口统计学维度、兴趣维度和商业维度,形式如图1所示.

图1 用户画像
在本文的研究场景中,用户浏览过程一般是匿名的,所以可得到的用户人口统计学维度信息较少,而用户的浏览历史数据相对容易获取,这使得建立用户兴趣模型成为可能.
2.2 引入动态用户画像
随着时间的推移,用户浏览历史的文本集合不断扩大,用户的兴趣标签权重会发生变化,如果不能更新兴趣标签的权重,会导致推荐精度下降,所以必须通过一定的方式更新用户的兴趣标签集.
为了方便表示用户兴趣维度,本文采用一个n维元组[8]表示用户兴趣标签集,其形式表示为:
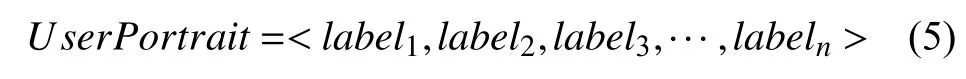
其中labeli代表用户兴趣标签.
用户兴趣维度的n维特征向量可表示为:
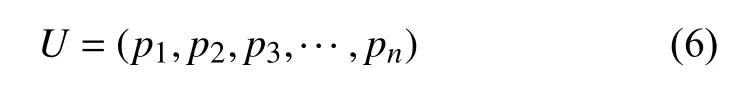
设用户兴趣标签集为查询向量:

通过计算查询向量和推荐集中的文档向量的相似度,来决定是否将文本推荐给目标用户.本文选用余弦相似度来度量两向量的相似程度:

随着用户的浏览集合不断扩大,能代表用户兴趣的标签的权重会随时间推移而发生变化,通过动态的分析用户的浏览行为,在一定程度上可以预测用户的兴趣变化.
为了更好的预测用户的兴趣的变化趋势,提高推荐的精度,本文使用贝叶斯动态线性模型对用户兴趣维度进行预测,下面给出模型定义:

其中,yt为t时刻的观测值;θt为未知的状态向量;Ft为已知的n维向量,用来描述观测数据和状态之间的关系;vt为观测误差值;wt为状态误差值,且vt和wt相互独立.
对用户浏览集合U进行采样,
时间间隔为
观测序列为
由模型定义给出其一步预测和后验分布:

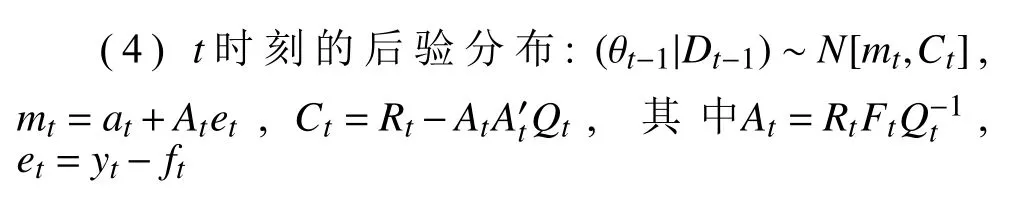
通过后验信息不断修正先验信息,求得预测值,根据预测值更新用户画像兴趣维度的标签权重,从而更新用户兴趣集U,由公式(5)计算更新后的兴趣集与文档向量的余弦相似度,当相似度大于0.6时将该文本信息推荐给用户.
3 实验分析
3.1 实验数据
本文通过网络爬虫抓取某信息分享平台200用户的交互信信息,其中包括个人主页信息、关注人URL、收藏、个人动态、关注领域等信息.为了高效的提取网页文本信息,使用行块分布函数对网页文本内容进行抽取.
本文分别对传统的基于标签的信息推荐(Basedon Label Recommendation,BLR)和基于动态用户画像的推荐( Based-on Dynamic User Portrait Recommendation,BDUPR)进行实验,前者直接通过分析全部的用户浏览集合进行用户的偏好计算,后者通过对用户浏览集进行分时段采样,动态计算用户的兴趣偏好.
3.2 评价标准
预测准确度有3类[9]:评分预测准确度评测、使用预测准确度评测、物品排名预测准确度评测.在本文的应用场景中,推荐并不预测用户对项目的偏好(评分),而是用户是否点击(收藏、关注等)被推荐的信息,所以选用“使用预测准确度评价”作为本文方法的评价标准.
为用户推荐的内容可能有下列几种情况:

表1 结果分类
通过统计上表数值,计算如下比率:

在实际推荐中,用户的浏览量十分有限且推荐集中的文本数量较多,所以这里选用查准率作为验证标准.
3.3 实验结果
推荐列表长度对多用户平均查准率具有较大的影响,如果取值太则小无法说明推荐方法的可行性,取值过大会造成结果难以预估[2](查准率可能偏大也可能偏小).图2为推荐列表长度与查准率的关系:

图2 查准率
测试列表长度的实验条件是优化过的,所以查准率可能较高.经过多次试验最后设定列表长度为100,那么两种推荐方式的查准率和时间序列的关系如图3所示.

图3 查准率对比
从图中可以看出,在时间序列的一开始,BDUPR的查准率并不理想,这是因为训练集数量较小,所以查准率偏低,但随着时间序列的增长,训练集不断增加,成上升趋势,开始趋于平稳.BLR在推荐的一开始具有较高的查准率,这是因为BLR在推荐进行之前就将全部的用户历史数据量化,用于构建用户的兴趣模型,其文档训练集数据要多于BDUPR的分时段采样训练集合,所以在靠前的推荐周期当中,BLR的推荐准确率要高于BDUPR,但随着时间推移,用户兴偏好会发生一定的变化,致使BLR的推荐准确率降低.
两种方法在进行实验过程中都存在一定的数据波动,可能有以下几个原因:用户群体中部分用户的兴趣点差距很大,导致平均查准率偏低;由于网络信息更新速度较快,用户兴趣波动较大.
4 结束语
本文研究的基于动态用画像的推荐在捕捉用户兴趣变化方面较静态推荐有一定优势,但在新异推荐方面还存在不足:建立用户兴趣模型的数据全部来源于用户和服务器的历史交互数据,对于那些用户之前从未接触过的信息,存在冷启动问题.
1 王国霞,刘贺平.个性化推荐系统综述.计算机工程与应用,2012,48(7):66-76.
2 吴丽花,刘鲁.个性化推荐系统用户建模技术综述.情报学报,2006,25(1):55-62.
3 孟祥武,刘树栋,张玉洁,等.社会化推荐系统研究.软件学报 ,2015,26(6):1356-1372.[doi:10.13328/j.cnki.jos.00 4831]
4 许海玲,吴潇,李晓东,等.互联网推荐系统比较研究.软件学报,2009,20(2):350-362.
5 史艳翠,戴浩男,石和平,等.一种基于时间戳的新闻推荐模型.计算机应用与软件,2016,(6):40-43.[doi:10.3969/j.issn.1000-386x.2016.06.010]
6 王正鹏,谢志鹏,邱培超.语义关系相似度计算中的数据标准化方法比较.计算机工程,2012,38(10):38-40.[doi:10.3969/j.issn.1007-130X.2012.10.008]
7 张征杰,王自强.文本分类及算法综述.电脑知识与技术,2012,8(4):825-828,841.
8 王智囊.基于用户画像的医疗信息精准推荐的研究[硕士学位论文].成都:电子科技大学,2016.
9 Ricci F,Rokach L,Shapira B,et al.Recommender Systems Handbook.2nd ed.北京:机械工业出版社,2015
猜你喜欢
计算机技术与发展(2022年8期)2022-08-23
小哥白尼(神奇星球)(2022年3期)2022-06-06
计算机系统应用(2021年9期)2021-10-11
非公有制企业党建(2020年10期)2020-10-27
现代信息科技(2020年18期)2020-02-22
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
瞭望东方周刊(2017年7期)2017-03-01
读者·校园版(2015年7期)2015-05-14
延河(下半月)(2014年1期)2014-02-28
