
基于深度学习的恶意URL识别①
2018-06-14 08:48付华峥
计算机系统应用 2018年6期
陈 康,付华峥,向 勇
(中国电信股份有限公司 广东研究院,广州 510630)
信息技术的普及极大促进了在线银行、电子商务和社交网络的发展,人们越来越多地通过互联网完成社交、购物、资讯获取等行为,政府也在通过互联网推行电子政务,增强政府的透明性,改进公共决策质量.但同时,互联网也成为不法分子的活跃平台,涌现出大量的网络犯罪行为.网络攻击者通过钓鱼网站、垃圾广告和恶意软件推广等方式非法牟利.截至2016年12月,中国网站数量为482万个,年增长14.1%[1].360互联网安全中心截获新增钓鱼网站196.9万个,同比2015年(156.9万个)上升25.5%;平均每天截获新增5395个,每小时涌现超过225个钓鱼网站[2].由公安机关与360安全中心联合发起的猎网平台发布《2016年网络诈骗趋势研究报告》显示:猎网平台共收到全国用户提交的网络诈骗举报20 623例,举报总金额1.95亿余元,人均损失9471元.
在这些攻击行为中,有相当大的一部分是以恶意URL为主要手段实现的.URL,即统一资源定位符,是对互联网上资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址.而恶意URL是指欺骗用户访问,达到“执行恶意行为”或“非法窃取用户数据”目的的URL.攻击者通过恶意URL构建攻击操作的关键部分,诱导不知情的用户访问攻击者提供的URL,达到其窃取用户的个人隐私信息,例如用户的银行帐号及密码信息等,或者下载和执行恶意程序或脚本(例如病毒,木马,蠕虫等)等攻击目的.
因此,及时精确地检测恶意URL,从而有效应对大量和多种类型的网络安全攻击,是构建网络安全解决方案中的重要一环.为识别恶意的URL,近年来,研究者已经做了较为深入的研究,如Liu等人[3]利用无监督学习算法DBSCAN对钓鱼网页的攻击目标进行识别;Ma等人[4]使用Naïve Bayers在多个公开数据集上进行检测;Huang等人[5]提出了基于SVM实现了钓鱼网页识别系统.
在本文工作中,我们提出一种基于深度学习的恶意URL识别模型.本文的模型基于URL词法特征进行检测.首先通过正常URL样本训练得到URL中的字符的分布表示,将URL转化成二维图像,然后通过训练CNN模型对二维图像进行特征抽取,最后使用全连接层进行分类.本文的恶意URL识别系统有以下两个优点:
(1) 得到URL中每一个字符的特征向量表示,将字符与字符之间的编辑距离、前后顺序等信息准确包含在特征向量中;
(2) 使用CNN算法,通过多个尺寸的卷积核提取URL中字符分布情况特征,大大降低了传统方法中所需的特征工程带来的巨大工作量.
本文余下部分的组织为:在第2节,我们介绍当前恶意URL识别的相关研究进展;第3节是本文的核心,我们提出一个基于CNN的恶意URL识别模型;在第4节,我们将报告本文提出的模型在真实数据上的识别结果;最后一节是全文工作的总结.
1 相关工作
1.1 恶意URL识别
目前的恶意URL识别工作使用的主要是黑名单启发式技术和机器学习技术.
黑名单技术是恶意网址发现算法中最传统、最经典的技术.网页黑名单中包含已知的恶意网址列表,通常是由具有公信力的网站根据用户举报、网页内容分析等手段生成并发布.当用户浏览某一网址时,基于网页黑名单的数据库就开始进行搜索.如果这个网址在网页黑名单库中,它就会被认为是恶意网址,浏览器会出现警告信息;否则认为此网址是正常网址.在网址生成算法成熟的现在,每天都会有大量的恶意网址出现,黑名单技术不能够及时更新所有的恶意网址.因此,黑名单技术只能给与用户最低程度的保护,并不能及时检测出恶意网站,阻断用户对恶意网站的访问.虽然黑名单技术有着漏判严重、更新时效性低等缺点[6],但是其简单易用,因此仍是许多杀毒系统常用的技术之一.
启发式算法是对黑名单技术的一种补充算法,其主要原理是利用从恶意网址中发现的黑名单相似性规则来发现并识别恶意网页.此算法可以依靠现有的启发式规则识别(已有的以及部分之前未出现的)恶意网页,而不需要依靠黑名单的精确匹配来完成恶意网页识别.但是,这种方法只能为有限数量的相似恶意网页而设计,并不能针对所有的恶意网页,而且恶意网页要绕过此类的模糊匹配技术并不难[7].Moshchuk等人提出了一种更具体的启发式方法,这些方法通过分析网页的执行动态,比如并不寻常的过程创建、频繁的重定向等寻找恶意网页的签名[8,9].但是启发式算法有,比如误报率高以及规则更新难等一些众所周知的缺点.
机器学习算法是目前研究的热点之一[10,11],此类算法通过分析网页URL以及网页信息,提取域名的重要特征表示,并训练出一个预测模型.目前用于恶意网页识别的机器学习算法主要分为无监督算法和有监督算法.有监督算法也叫分类算法,此类算法需要大量的已标注恶意/良性的网页地址作为训练集,抽取网页特征,然后利用现有的分类算法(SVM、C5.0、决策树、逻辑回归等)进行恶意网页识别.有监督学习算法首先要对所有标注URL的信息进行特征提取(域名特征、注册信息、生存时间等),然后从中选择出能够区别恶意/良性URL的特征,之后再利用分类算法进行建模分析.此算法的准确率较高而且误报率相对较低,但是却对标注数据以及特征工程比较敏感,标注数据的准确率以及选择使用的特征会严重影响算法的准确率和效率.
无监督机器学习方法又称聚类方法.此类方法的具体分类过程主要由特征提取、聚类、簇标记和网页判别等步骤组成.主要做法是首先将URL数据集划分为若干簇,使得同一簇的数据对象之间相似度较高,而不同簇的数据对象之间的相似度较低.然后,通过构造和标记数据集中的簇来区分恶意网页和良性网页.文献[12]和[13]都提出了使用无监督机器学习识别恶意网页的具体做法,他们都结合了域名与IP地址的关系来进行聚类算法的实现.
1.2 深度学习
深度学习是机器学习的一个分支.深度学习通过学习深层非线性网络结构,逐层训练特征,将样本在原空间的特征表示逐步变换到新特征空间,展现从样本集中学习数据集本质特征的强大能力.相比于机器学习,深度学习是唯一端到端的系统,中间不需要人为参与,不需要先验知[14].深度学习的最大好处是可以自动学习特征和抽象特征.深度学习算法中使用最多的是卷积神经网络(CNN)以及循环神经网络(RNN).
在CNN算法中,相邻两层神经元之间只有部分节点相连.CNN算法有两个很重要且特殊的部分:卷积层和池化层.在卷积层,神经网络中的每一小块被深入分析从而得到抽象程度更高的特征.一般来说.通过卷积层的处理,输入数据的深度会增加.在池化层,输入矩阵的尺寸会被有效缩小.池化层的使用既可以加快计算速度也有防止过拟合的作用.CNN算法经常用于图像识别领域[15],因为它可以排除出现位置的影响有效识别图像特征[16].
RNN算法可以充分挖掘输入数据中的时序信息以及语义信息的深度表达能力,因此被广泛应用于语音识别、语言模型、机器翻译等领域.RNN算法的主要用途是预测和处理序列数据.从网络结构上讲,循环神经网络会记忆当前序列之前的信息,并利用之前的信息影响后面结点的输出.也就是说,循环神经网络的隐藏层结点之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻的隐藏层的输入.
2 基于卷积神经网络的恶意URL识别模型与实现
传统的机器学习算法非常依赖于特征,其效果很大程度上取决于人工构造的特征的好坏.深度神经网络能够自动提取数据特征的特性为URL识别提供了一种新的思路.根据Anh等人[17],正常和恶意URL具有不同的词法特征,即字符出现的频率,位置,和前后字符的关系具有可以区分的特征,见表1的恶意URL样例.基于此,我们提出一种完全基于URL字符串的词法特征,利用深度神经网络实现的恶意URL识别算法.

表1 恶意URL样例
识别算法分为3个阶段,首先训练构成URL的字符表示为实数向量的形式;其次基于第一步得到的映射表,将URL转换成特征图像;最后将特征图像输入卷积神经网络CNN去学习特征,通过一个全连接层实现对URL的分类.算法概述如图1.
本算法共有两个部分:训练部分和预测部分.
如图1所示,训练流程被分为4个部分.首先,系统监控用户浏览行为过程并生成日志;然后,使用深度学习对日志文件进行训练得到字符的嵌入式模型;第三步,利用上一步得到的模型对网页URL进行特征转化;最后,使用并行的CNN算法训练已标注的恶意/良性URL特征.
在训练模型之后,我们使用经过训练的CNN模型进行评估验证过程.首先,使用字符的嵌入式表示对日志行为数据进行特征转化;然后,使用训练后的CNN模型进行词法特征提取,最后再使用分类输出层进行恶意概率的计算.下面详细描述模型的训练过程.
2.1 使用语料训练RNN生成字符的嵌入式表示
我们将单个字符作为最小的语义单元,一个URL就看成由基本单元构成的句子.因此,可以利用语言模型的概念对URL进行建模.在训练语言模型的过程中,得到URL中各字符在模型中的向量表示.
语言模型中对于词的一种主要表示方法是onehot编码.如图2所示,这种方法把每个词表示为一个很长的向量.这个向量的维度是词表大小,其中只有一个维度的值为 1,其它元素为 0.值取1的这个维度就代表了当前的词.这种方式如果使用稀疏方式存储,存储效率很高,但这种表示方法有一个很大的缺陷,词的表示是任意的,不能从词的表示中看出两个词之间的关系.同时,如果当词汇表数量大的时候,这种方式还可能会导致维度灾难.
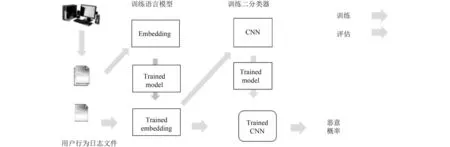
图1 推荐模型概述

图2 one-hot编码
另一种更好的表示方法是分布式表示(Distributed Representation),分布式表示最早由Hinton在1986 年提出[18].其基本思想是通过训练将每个词映射成K维实数向量(K一般为模型中的超参数),不同词在K维空间的距离(比如cosine相似度、欧氏距离等)来表示它们之间的语义相似度.word2vec是基于分布式表示思想的一种具体形式.它使用了一个两层神经网络对CBOW/Skip-Gram模型进行训练,在训练过程中获得一种单词在向量空间上的表示.
本文参照这个语言模型的思想,但是针对字符而不是词进行建模.这一步骤的主要工作是将字符映射到K维向量空间,将其转为连续值的向量表示.
具体过程如下:
1) 首先从0开始对URL中出现的所有字符进行编码.设定一个词汇表大小v,将所有出现的字符按出现的频率从1到v-2进行编码.0作为填充字符的编码,v-1作为未知(未出现在字符表中)字符的编码1;
2) 训练一个两层的神经网络模型.构建一个[v,k]的二维向量,将正常的URL作为训练样本输入.例如www.baidu.com,转换为训练序列(w,w),(w,w),(w,w),…,(a,b),(a,i),…,(m,o),然后计算输出预测和它实际值的损失函数,训练过程中更新二维向量的值;
3) 训练结束后,得到维度为[v,k]的映射表.
2.2 将URL转化为特征图像
通过上述训练得到的映射表,将URL转化为特征图像.由于后续的CNN模型接受固定大小的图像,我们确定一个URL最大长度n,构建一个[n,k]大小的图像.如果URL长度小于n的,使用0作为填充,对于长度大于n的URL做截断.
转换后图像的每一行即是URL中的一个字符的向量表示.如图3所示.

图3 字符转换
2.3 CNN提取特征并进行分类
构建一个CNN分类模型,将上述得到的特征图像作为输入,通过卷积层对进行特征提取,最后通过一个全连接层进行分类,得到输出变量-即分类结果.CNN模型如图4所示.
CNN的结构包括一个输入层,4个并列的卷积层以及池化层,和一个全连接层,最后的输出层.
上述4个卷积层中的每一个对应不同大小的卷积核,高度h分别是2,3,4,5,宽度为k,卷积核的个数取256.
设是k维的字符向量,对应于URL字符串里的第i个字符.长度为n的URL字符串(需要的时候可以进行填充或截断)表示为表示字符串卷积操作用一个卷积核应用到h个字符的窗口上,生成一个新特征.例如一个新特征ci通过下式生成:
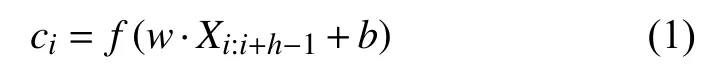
其中是bias项,f是一个非线性函数.该卷积核应用到U R L字符串中的每一个可能的子串上形成一个特征集:
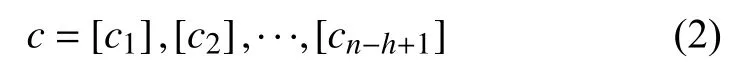
其中非线性激活函数使用RELU.
每一个卷积层对应一个池化层.使用最大池化方法,将同一个卷积核生成的特征集中最大的数值保留,即将卷积层的输出尺寸转换为1*1,因此256个卷积核生成1*256大小的输出.
池化层的输出拼接后得到256*4=1024个单元作为全连接层的输入,由于是二分类,最后的输出层的节点是2.
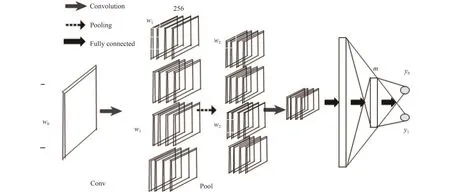
图4 CNN模型结构图
2.4 过拟合和dropout
深度神经网络含有大量非线性隐含层,使得模型表达能力非常强.在有限的训练数据下,导致学习了很多样本噪声的复杂关系,而测试样本中可能并不存在这些复杂关系.这就导致了过拟合.本文采用了dropout防止过拟合.
Dropout的意思是随机移除神经网络中的一些神经元(隐含层和可见层),同时包括该神经元的输入和输出.在分类问题中,使用dropout比传统的正则化方法,泛化误差都有显著的减小.
这里在每个卷积层做完池化之后,做一次dropout,防止在样本数量不大的情况下,出现过拟合情况.
3 实验
3.1 数据与评估标准
为了获取数据,本次研究筛选出某个月的用户浏览记录前50 000的url作为正常的URL;同时采用爬虫从网站 https://www.malwaredomainlist.com/mdl.php、http://www.phishtank.com/等网站中收集了3万多条URL数据作为恶意网站数据.
本次研究使用混淆矩阵以及准确率、召回率、F1值和ROC曲线进行模型的评估.在二分类算法中,混淆矩阵的表示如表2
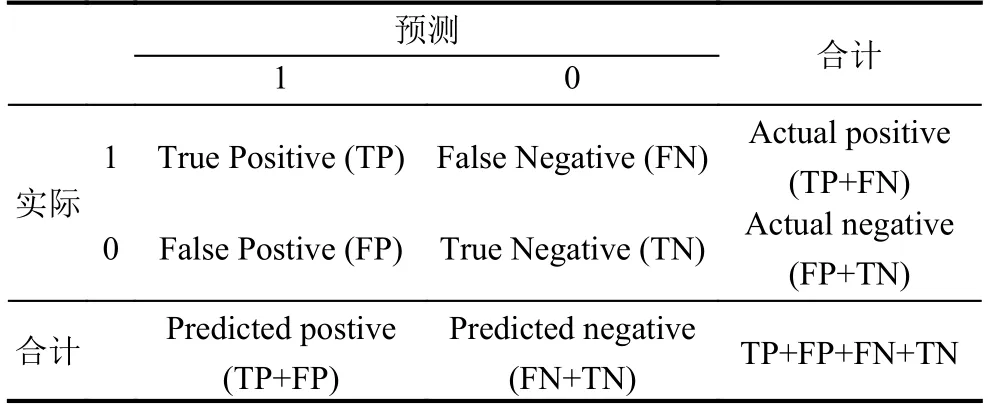
表2 混淆矩阵表示
根据上述矩阵中的数据,可以得到准确率、召回率、F1值等评价标准.
为了避免样本集中数据不均衡造成的影响,我们同时选用了ROC (Receiver Operating Characteristic)曲线作为评价标准之一.ROC也称为受试者工作特征曲线,是一种以信息检出理论为基础,广泛应用的数理统计方法[19].它根据一系列不同的阈值或者分界值,以TPR为纵坐标,FPR为横坐标绘制曲线,曲线下面积越大,算法精度越高.
3.2 实验结果和讨论
本次实验使用一台服务器进行,安装了python3.6.2,TensorFlow1.2.0,sklearn等.服务器操作系统是Centos 7.2版本,内存为512 G,核数为40.
本研究采用十折交叉验证对80 000多个URL进行分类验证.图5和图6为算法精度和损失函数曲线和ROC曲线图.
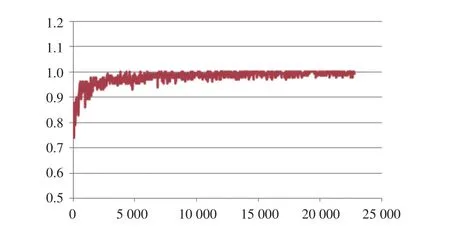
图5 精度变化曲线图

图6 模型ROC曲线图
在我们的实验数据集上,模型的准确率为0.962、召回率为0.879、F1值为0.918,模型整体达到了很好的预测效果.在本次试验数据的过程中,目前测试的样本集下,全连接层的个数会严重影响模型结果,如果在算法的最后再增加一层全连接层,模型效果精度将会降低50%左右,因此对类似数据量的模型训练来说,全连接层的个数至关重要.我们使用grid search进行参数选择,发现卷积核分别设置为128和256,批处理数量分别设置为128或者256,学习率设置为0.001时,算法较好.
4 结束语
针对如何利用机器学习算法进行恶意域名和URL识别的问题,本文提出了一种基于URL字符串的深度学习分类算法,并利用TensorFlow进行了代码实现.实验证明,本文提出的恶意域名和URL识别分类方法,在准确率与召回率方面都达到了较好的效果.目前模型是二分类,主要用于判断URL是否为恶意.但是恶意URL种类较多,判断出具体种类有助于进行针对性防御,未来将进行多分类模型训练,判断恶意URL种类.
1 中国互联网络信息中心.第39次《中国互联网络发展状况统计报告》.http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201701/t20170122_66437.htm.[2017-01-22].
2 360互联网安全中心.2016年中国互联网安全报告.http://zt.360.cn/1101061855.php?dtid=1101062514&did4902 78985.[2017-02-15].
3 Liu G,Qiu BT,Liu WY.Automatic detection of phishing target from phishing Webpage.Proceedings of the 20th International Conference on Pattern Recognition.Istanbul,Turkey.2010.4153-4156.
4 Ma J,Saul LK,Savage S,et al.Beyond blacklists:Learning to detect malicious Web sites from suspicious URLs.Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,NY,USA.2009.1245-1254.
5 Huang HJ,Qian L,Wang YJ.A SVM-based technique to detect phishing URLs.Information Technology Journal,2012,11(7):921-951.[doi:10.3923/itj.2012.921.925]
6 沙泓州,刘庆云,柳厅文,等.恶意网页识别研究综述.计算机 学 报 ,2016,39(3):529-542.[doi:10.11897/SP.J.1016.2016.00529]
7 Sahoo D,Liu CH,Hoi SCH.Malicious URL detection using machine learning:A survey.arXiv:1701.07179.2017.
8 Moshchuk A,Bragin T,Deville D,et al.Spyproxy:Execution-based detection of malicious web content.Proceedings of 16th USENIX Security Symposium.Boston,MA,USA.2007.
9 Rieck K,Krueger T,Dewald A.Cujo:Efficient detection and prevention of drive-by-download attacks.Proceedings of the 26th Annual Computer Security Applications Conference.Austin,TX,USA.2010.31-39.
10 Tobiyama S,Yamaguchi Y,Shimada H,et al.Malware detection with deep neural network using process behavior.Proceedings of the 40th Annual Computer Software and Applications Conference.Atlanta,GA,USA.2016.577-582.
11 张洋,柳厅文,沙泓州,等.基于多元属性特征的恶意域名检测.计算机应用,2016,36(4):941-944,984.[doi:10.11772/j.issn.1001-9081.2016.04.0941]
12 张永斌,陆寅,张艳宁.基于组行为特征的恶意域名检测.计 算 机 科 学 ,2013,40(8):146-148,185.[doi:10.3969/j.issn.1002-137X.2013.08.030]
13 邹福泰,孙文杰,谭凌霄,等.基于Passive DNS迭代聚类的恶意域名检测方法:中国,CN106060067A.2016-10-26.
14 胡二雷,冯瑞.基于深度学习的图像检索系统.计算机系统应用,2017,26(3):8-19.[doi:10.15888/j.cnki.csa.005692]
15 Anthimopoulos M,Christodoulidis S,Ebner L,et al.Lung pattern classification for interstitial lung diseases using a deep convolutional neural network.IEEE Transactions on Medical Imaging,2016,35(5):1207-1216.[doi:10.1109/TMI.2016.2535865]
16 郑泽宇,顾思宇.TensorFlow:实战Google深度学习框架.北京:电子工业出版社.2017.141-145.
17 Le A,Markopoulou A,Faloutsos M.PhishDef:URL names say it all.2011 Proceedings IEEE INFOCOM.Shanghai,China.2011.191-195.
18 Hinton GE.Learning distributed representations of concepts.Proceedings of the 8th Annual Conference of the Cognitive Science Society.Amherst,MA,USA.1986.1-12.
19 石昊苏.基于实例与MATLAB的ROC曲线绘制比较研究.电子设计工程,2010,18(9):36-39.[doi:10.3969/j.issn.1674-6236.2010.09.011]
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
成都信息工程大学学报(2021年6期)2021-02-12
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子技术与软件工程(2019年20期)2019-11-30
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年11期)2019-07-04
魅力中国(2018年5期)2018-07-30
