
浅析SQL Server数据库在搅拌站控制系统中的设计与应用
2018-05-31 19:18:08黄光慈周菊万林林曹希龙
商品混凝土 2018年5期
黄光慈,周菊,万林林,曹希龙
(徐州徐工施维英机械有限公司,江苏 徐州 221004)
1 数据库的设计
1.1 表的设计
表(Table)是数据库的基本结构,表中能够存储不同类型的字段,如整形(int)、浮点型(float)等等。对于需要保存数据,可以根据数据的类型来设计表。根据笔者这几年的开发经验,总结出了以下几条表设计的原则:
(1)一个表就只存储属于同一个类对象的数据。以某品牌的搅拌站控制系统为例,为了存储搅拌站的生产任务,专门设计如下表,用来存储生产任务的数据。如图1 所示。
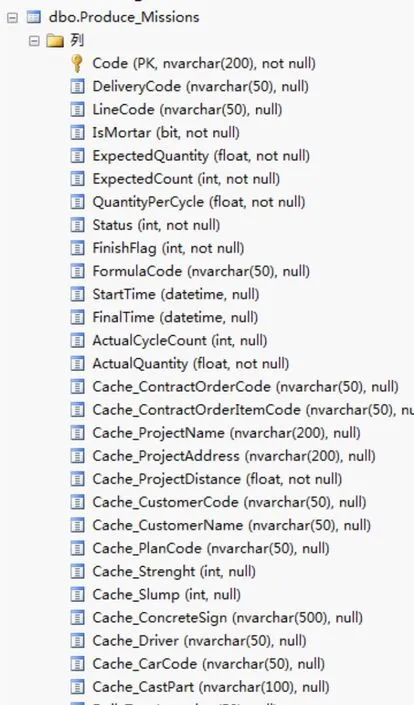
图1 某控制系统的 Produce_Missions 表
图1 中各个字段的释义如下:

字段名 中文释义 备注Code 任务编号DeliveryCode 交付任务编号 该任务所隶属的交付任务编号LineCode 生产线编号 用以区别不同的生产线IsMortar 是否砂浆 指示该任务是否为生产砂浆ExpectedQuantity 期望生产方量Status 状态FinishFlag 完成标志位FormulaCode 配方编号StartTime 任务开始时间FinishTime 任务结束时间ActualCycleCount 实际盘次数量ActualQuantity 实际生产方量Cache_Contract OrderCode 合同编号Cache_Contrace OrderItemCode 合同项编号Cache_ProjectName 项目名称Cache_ProjecetAddress 项目地址Cache_CustomerCode 客户编号Cache_CustomerName 客户名称Cache_PlanCode 计划编号 该任务所隶属的生产计划编号Cache_Strenght 强度数值Cache_Slump 坍落度Cache_ConcreteSign 完整的强度信息Cache_Driver 司机Cache_CarCode 车号Cache_CastPart 浇筑部位
从图1 可以看出,该表的名称为“Produce_Missions”,并且拥有多个不同类型的字段,用来存储重要的数据,比如混凝土的强度、坍落度和浇筑部位等。在设置字段的名称时,最好将字段的名称与实际所要存储的字段意义相匹配,这样会增加数据库的可读性。比如在上表中,项目名称就用“Cache_Project Name”字段表示,强度则使用“Cache_Strength”表示。
如果有多个类对象的数据需要存储,则可以设计多个表来存。如在搅拌站控制系统中,需要有生产订单、生产计划和生产任务三个类型的对象需要存储,则可以分别设计三个不同的表,以此来满足用户的需求。
那么可不可在一个表中存储生产订单、生产计划和生产任务的对象呢?答案是可以的,但是严重不推荐这样做。因为这样在查询、修改和插入数据时会带来很大的不便,而且这也会对阅读数据库造成比较大的困难。同时,如果一个表含有过多的字段,在对表进行操作时电脑资源的占用也会比较大。因此,在设计表时,最好一个表只用来存储一个类型的对象的数据。
(2)某些类型的对象,可能会有一个唯一的标识,这个唯一的标识在数据库中被称为主键。主键具有唯一性和不可修改性,就像是人的身份证号一样。如在图1 中,Produce_Missions 的第一个字段 Code,就是该表的主键。
主键的唯一性有两个含义。其一,具有主键的表,在向其中插入内容时应该首先检查要插入的主键是否已经存在,然后再执行插入操作,否则有可能会造成插入失败。假如在图1的表中已经存在一个任务的编号为 25,如果再次插入一个编号为 25 的任务,将会产生一个主键重复的 SQL 异常,同时本次插入操作也将失败。因此在插入之前,需要检查要插入的编号是否存在,可以使用如下 SQL 语句进行查询:
Select count(Code) from Produce_Missions where Code= '25'
如果该编号已经存在,则将会返回的结果大于 0;如果编号不存在,则返回的结果为 0。
其二,主键的唯一性也指的是一个表只有能一个字段作为它的主键。
主键的不可修改性指的是一旦向主键中插入了内容之后,将无法修改其中的内容。
主键根据实际需要,可以是由程序指定的内容,也可以是 SQL Server 自动生成的内容。SQL 自动生成的主键编号,一般都是从 1 开始的整数叠加,即每次插入一行,编号自动加 1。使用这种方式时,无需向主键插入内容,只需向改行的其他自动插入数据,主键的编号会自动生成。例如,在图2 中所示的是某搅拌站控制系统的盘次信息表,其中的第一列 ID,即为 SQL 自增列。
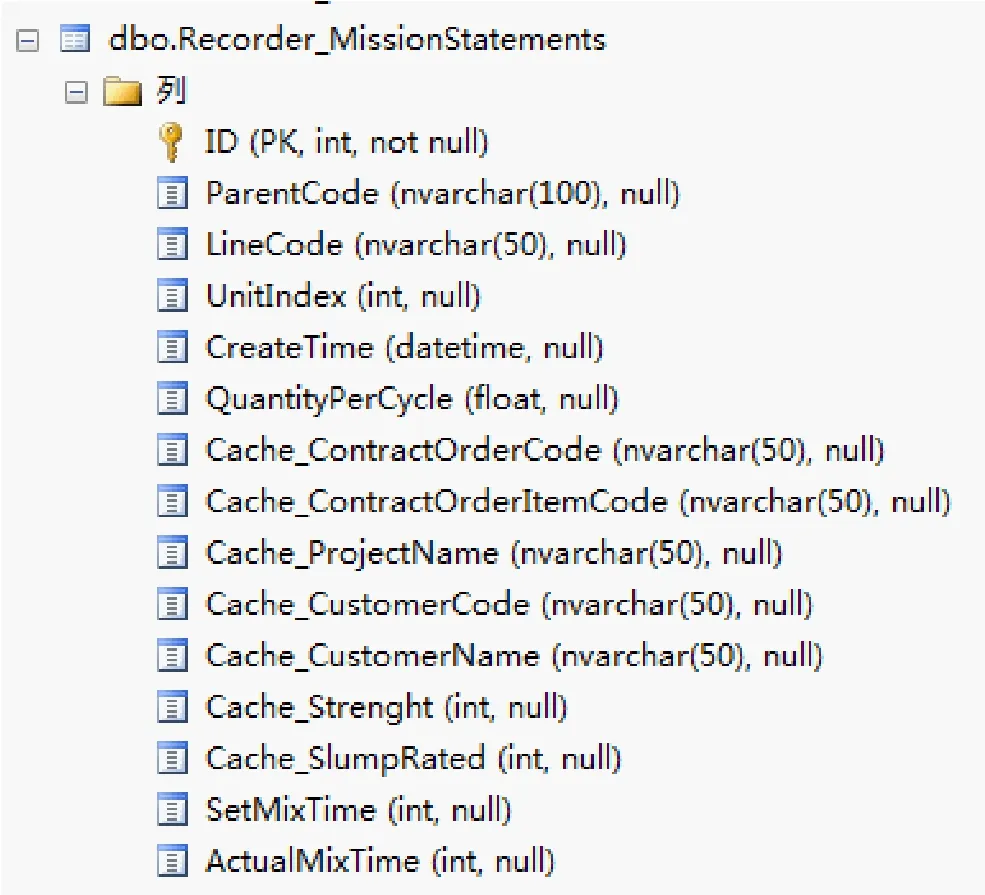
图2 某系统的 Recorder_MissionStatements 表
图2 中各个字段的释义如下:

字段名 中文释义 备注ID 自增列 数据库中的自增列序号指示改行数据所隶属的父项编号,与图1 中的Code 字段相对应LineCode 生产线编号 用以区别不同的生产线UnitIndex 盘次序号CreateTime 创建时间QuantityPerCycle 当前盘次方量Cache_Contract OrderCode 合同编号Cache_Contrace OrderItemCode 合同项编号Cache_ProjectName 项目名称Cache_CustomerCode 客户编号Cache_CustomerName 客户名称Cache_Strenght 强度数值Cache_SlumpRated 坍落度SetMixTime 预设的搅拌时间ActualMixTime 实际搅拌时间ParentCode 父项编号
除了以上两种方式的主键外,主键还可以是 GUID列。GUID 同样表示一行数据唯一的 ID,只是 GUID 是由计算机生成的标识列,虽然保证了唯一性,但是却由一串完全无法找到规律的字母数字组成,容易给阅读造成困难,因此除非必须要使用 GUID 列,否则一般不推荐使用该种方式的主键。笔者做了一个小实验,由计算机生成十次 GUID 标识,生成的主键内容如图3 所示。

图3 GUID 列内容
1.2 信息相关表的设计
刚才所介绍的方式,都是表中的一行数据,就可以表示一个对象的基本内容。但是有时候我们会碰到,一个对象的全部内容需要从不同的表中获取,比如在某控制系统中,一车生产完成之后会产生各种物料的消耗,而这些物料的消耗却与该车的基本任务信息存储在不同的表中,这样该如何设计表呢?
首先,在主表中,必须要有该行数据的唯一标识,即主键。因为主键是该行内容的唯一代表,因此可以将主键的信息放到附表中,附表通过该表中的主键信息的备份查询到对应的主表中的内容。
其次,附表可以有主键,也可以没有。如果有,则不能把附表中主键信息的备份作为主键,因此会导致附表的信息也不能重复,由此将无法满足客户的需求。此时推荐使用上文所述的自增列来满足附表对主键的需求。
例如在图2 所示的表中,该表的 ParentCode 列所存储的内容,即为该表对应的主表的信息,通过该字段就可以获取到主表中对应的信息。如在主表(图1 所示的表)中,主键信息为“Plan_1_2_1”,可以查到一行数据(图4),在附表(图2 所示的表)中,可以查到三行数据(图5),这四行数据完全可以通过 ParentCode字段获取到全部的内容。

图4 主键信息为 "plan_1_2_1" 在主表中的搜索结果

图5 主键信息为 "plan_1_2_1" 在附表中的搜索结果
在附表中设置主键字段内容的备份,还有一个好处是可以在多表之间进行连接,SQL 提供了多种手动可以时间多表联合查询,如内连接、外连接等。具体的内容将在后面的部分进行叙述。
2 数据库的应用
除了生产之外,搅拌站控制系统还必须要给用户提供详细的报表查询功能,大到项目方量、材料用量,小到每车每盘的生产误差,必须能够完整、准确、快速地呈献给客户。因此,报表功能是控制系统中重要的组成部分。
2.1 多表联合查询
在 1.2 所述的例子中,只需要知道任务的编号,就可以分别从 Produce_Missions 和 Recorder_Mission Statements 表中查找到需要对信息。但是这种方式需要查询两次,在数据量大时会消耗比较长的时间。那么有没有一种比较节约的方式呢?
答案是有的。使用 SQL Server 提供的内连接方式查询即可一次从两个表中查询出需要的信息。内连接时需要指定两个表中需要查询的字段,同时指定内连接的条件即可完成一次内连接。例如在 1.2 的例子中,使用一条语句即可完成对两个表的联合查询,SQL 语句如下:
Select Recorder_Mission Statements.Parent Code,Recorder_Mission Statements.Line Code,Recorder_Mission Statements.Quantity Per Cycle,Produce_Missions.formulacode from Recorder_Mission Statements inner join Produce_Missions on Recorder_Mission Statements.parentcode = Produce_Missions.code where Recorder_Mission Statements.parentcode = 'Plan_1_2_1'
查询的结果如下:
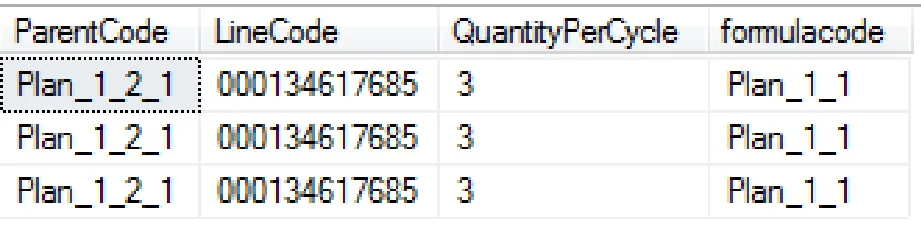
图6 内连接查询
为了节省页面空间,在上面的例子中只选择了Recorder_MissionStatements 表中的三个字段(图6 中的前三列)和 Produce_Missions 表中的一个字段(图6 中的最后一列)。内连接也可以进行多层嵌套,但是嵌套的次数越多,对电脑性能的消耗越大,因此一般情况下除非必要,否则最好不要使用多层嵌套内连接进行查询。
2.2 适当增加索引来提高查询效率
在现在的电脑硬件发展水平,对于数据量不多的数据库而言,一般的查询等待时间不会太久。但是随着时间的增加,运行数据必然会越来越多,查询等待时间也必然会延长。为了减少用户的等待时间,我们可以向数据库中某些关键字段增加索引,索引可以大大提供 SQL查询的效率,降低用户的等待时间。因此,好的数据库必须要有好的索引设置来支撑。那么,什么是索引,又该如何使用索引呢?
打个比方,在一个图书馆中,有那么多书,怎么管理呢?我们可以建立一个字母开头的目录,例如:a 开头的书,在第一排,b 开头的在第二排,这样在找什么书就好说了,这个就是一个索引。或者我们可以再写一个目录,按照作者进行排序,显示某某作者的书分别在第几排,这同样也是一个索引。
索引是一类在物理上连续或逻辑上连续的数据,有索引的数据库在查询时使用索引字段能够大大的提高查询效率。因为这些数据都是在内部按照一定规律排列好,只需直接从索引中查找就能完成。比如,将Produce_Missions 表的客户字段设为索引,设为索引之后查询的效率有了 20%~30% 左右的提升。查询语句如下:

索引虽然能够提升查询的效率,但是索引太多也对会系统造成负担。因此,对于什么样的字段能够创建索引,也有一些通用的规则。这些规则都是经过前人大量的实践而总结出来的,因此在设计索引时务必遵循以下几条原则:
(1)对于经常查询的数据列最好建立索引。
(2)对于需要在指定范围内的快速或频繁查询的数据列。
(3)经常用在 WHERE 子句中的数据列。经常出现在关键字 order by、group by、distinct 后面的字段,建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。
(4)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
(5)对于定义为 text、image 和 bit 的数据类型的列不要建立索引。
(6)对于经常存取的列避免建立索引。
3 总结
数据库是控制系统的记忆系统,如何能够设计出良好的数据库和如何能够快速地从数据库中查询数据,是软件开发者在开发软件时重要指标。本文粗略的列出了笔者在数据库的设计与应用中总结的经验,希望广大的软件开发者能够从中获取到自己所需的内容。软件优化与发展之路永无止境,愿与各位软件开发者共勉!
猜你喜欢
无线互联科技(2022年15期)2022-11-03 03:19:00
江苏科技信息(2022年16期)2022-07-17 09:07:36
岩石学报(2021年9期)2021-10-29 10:22:22
地球学报(2021年1期)2021-01-26 07:59:12
教育界·中旬(2019年7期)2019-11-24 05:53:39
湖南饲料(2018年3期)2018-07-03 06:17:58
湖南饲料(2017年3期)2017-07-18 11:15:37
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
图书馆建设(2014年3期)2014-02-12 15:41:35
