
基于公开信息的微博用户可信性评价研究
2018-05-29 08:31:02赵丽华李卫康
天津大学学报(社会科学版) 2018年3期
赵丽华, 杨 勇,2 , 闻 西, 李卫康
(1. 天津职业技术师范大学经济与管理学院, 天津 300222; 2. 天津大学管理与经济学部, 天津 300072; 3. 湖南大学工商管理学院, 长沙 410082)
Web 2.0时代,人们已经习惯于从虚拟社区获取信息和表达情感。作为虚拟社区的典型,微博是一个基于用户关系的信息分享、传播及获取平台。其共享性、实时性和互动性等特点使得其用户群逐渐稳定并持续增长。截止到2014年9月,仅新浪微博,其日活跃用户已达到7 660万人,月活跃用户达到11.67亿人。
然而,微博公众平台的快速发展,在给人们带来便利的同时,也带来了许多烦恼。例如,垃圾信息、谣言、欺诈信息等在微博平台中的泛滥。作为信息的发起者和传播者,微博用户的信誉对信息质量有着重要影响。虽然认证可以有效评估用户信誉,但微博平台实际存在的是更多的非认证用户。显然,单一的认证手段无法对用户信誉进行有效评估。对微博用户及其发布的信息进行人工识别判断也不现实。自微博面世以来,虽然已经对其进行了许多研究,然而,如何有效评价或度量非认证微博用户的信誉还没有公认的解决方案。事实上,公开的微博用户注册信息、社交关系信息及其行为信息中,蕴含了丰富的信誉信息。
如何对这些信息进行有效地提取和量化,并以此作为判别依据,是实践中的一个难点。 本文以新浪微博用户为研究对象,依据其公开的资料信息,考察分析了相关信息与微博用户信誉之间的关系,尝试抽取并构造了可信度评价特征集合,通过数据挖掘的方式,最终构建了非认证微博用户可信度评价模型,为辨别微博用户信誉提供了一个可行的解决方案。
一、 文献回顾
微博以Twitter于2006年的诞生为标志,研究者基本从2008年才开始对微博进行关注和研究。根据已有文献,关于微博的研究主要从3个方面开展:微博信息、微博用户影响力和微博社交网络。
(1) 对微博信息的研究。主要包括垃圾信息检测[1]、谣言检测[2-3]、话题的可信度分析[4-10]等。研究对象和方法集中于微博消息本身和结合用户关系的消息传播的拓扑结构。其中有部分研究微博用户本身的特征结合考虑进去,例如粉丝数、微博数量等[1]。
(2) 对微博用户影响力的研究。Bakshy等[10]通过追踪Twitter上7 400万新闻事件的用户传播图谱调查了160万用户的特征和影响力,应用了粉丝数、关注数、Tweets数量和注册时间4个用户特征;Cha等[11]研究了入度、转发数和提及数3种影响力指标,分析了用户影响力随时间和主题的变化规律;Ghosh等[12]提出了一个用户影响力模型来评估用户在社交网络上的影响力;Ghosh等[13]通过对用户的关注列表进行挖掘找出话题专家;原福永等[14]则通过对用户关注度的计算得到微博用户的影响力和活跃度,进而得到用户的影响力;王峰等[15]选取微博用户的微博数、粉丝数、关注数、收藏数和互粉数5个因素,借鉴网页排名的思想提供了一种用户排名的模型对用户可信度进行了排序。
(3) 对微博社交网络的研究。主要是研究微博用户及信息在微博平台的传播特点。Bakshy等[10]在研究用户影响力时,对Twitter上7 400万事件的用户传播图谱进行了分析应用;Canin等[16]利用用户对某一话题的相关性和专业性,对用户在社交网络上的影响力进行了自动识别和排序;Al-Sharawneh等[17]研究了在危急情形下如何去识别社交网络上的领导者,利用了用户的专业性和信用度计算用户的可信度。
三者的研究角度和重点虽然不同,但彼此之间存在一定关系。例如,微博信息的有效性、真实性与微博用户(发布者或传播者)的影响力相关,而社交网络的传播特性也常牵涉到用户的影响力以及信息本身的特性。与“信息”的可信性和用户的“影响力”不同,本文关注的是微博用户的“可信性”,这也是一个值得探讨的有趣问题,具有很好的应用前景。例如,用户的可信性信息可帮助人们筛选关注对象,也可为微博平台运营商提供监管便利;可为第三方机构提供信用评价、用户画像等参考信息;另外,也可作为一项衡量微博信息的可信性指标。总之,这对促进健康微博信息的分享、传播、发展与利用有着重要意义。
然而,对用户进行可信评价最首要的问题是“以什么数据来源作为评价依据?”不同学者利用潜藏在网络上的各种数据,提出了不同的评价模型。例如Gupta等[18]基于用户所发布的微博信息、微博事件数据构建基于图的模型来判断微博信息是否是流言,并以此评价用户的可信性。Chu[19]收集了50万个Twitter账户,根据其用户行为、信息内容数据判别账户的可信性。闫光辉等[20]基于用户社交关系数据构建了用户可信度评价模型。徐建民等[21]基于微博用户在线时长、发帖时间、互动程度等用户行为数据判别用户是否是僵尸账户,以此评估用户可信性。上述这些方法或者数据难以获取(甚至涉及隐私,只有通过后台获得),或者处理相当复杂,导致准确率和计算效率受到限制。事实上,微博平台上存在着微博用户的一些公开的个人资料信息,这类信息获得比较便利,而且不牵涉法律和隐私等可行性问题。因此,本文探讨的兴趣点便是这些公开的个人资料信息是否可以作为用户可信度评价的原始数据来源。如果可以,怎么来提取这些信息?怎样形成评价结果?
二、 公开资料中的可信信息分析
1. 用户可信度
用户可信度是指根据用户的特征、行为表现而给出的用户可信程度的判断。本文将用户可信度分为4类,分别是可信、偏向可信、偏向不可信、不可信,每个用户唯一地被分配到其中的某一类。可信用户个人信息全面真实,并有较大的公众影响力;偏向可信的用户具有一定的微博活跃度、粉丝基础,并在各特征的数据表现上存在一定的互解释性;偏向不可信的用户微博活跃度、粉丝数等存在一定不足,或特征表现的互解释性上存在一些矛盾;不可信用户在微博活跃度、粉丝数等方面存在明显不足,或在特征表现上存在强烈的矛盾。用户的可信度存在一定的偏序关系,即可信>偏向可信>偏向不可信>不可信。
2. 微博用户原始特征
准确划分用户可信度,需找出有效度。量用户可信度差异的特征,即准确选择并确定与用户可信度识别有关的信息。通过观察新浪、腾讯微博公众平台的信息传播特点及用户公开信息,借鉴已有研究成果,剔除一些与用户可信度评价无关信息,本文将蕴含微博用户可信度的公开资料信息划分为两类,即用户的真实性特征和用户的权威性特征(见表1)。
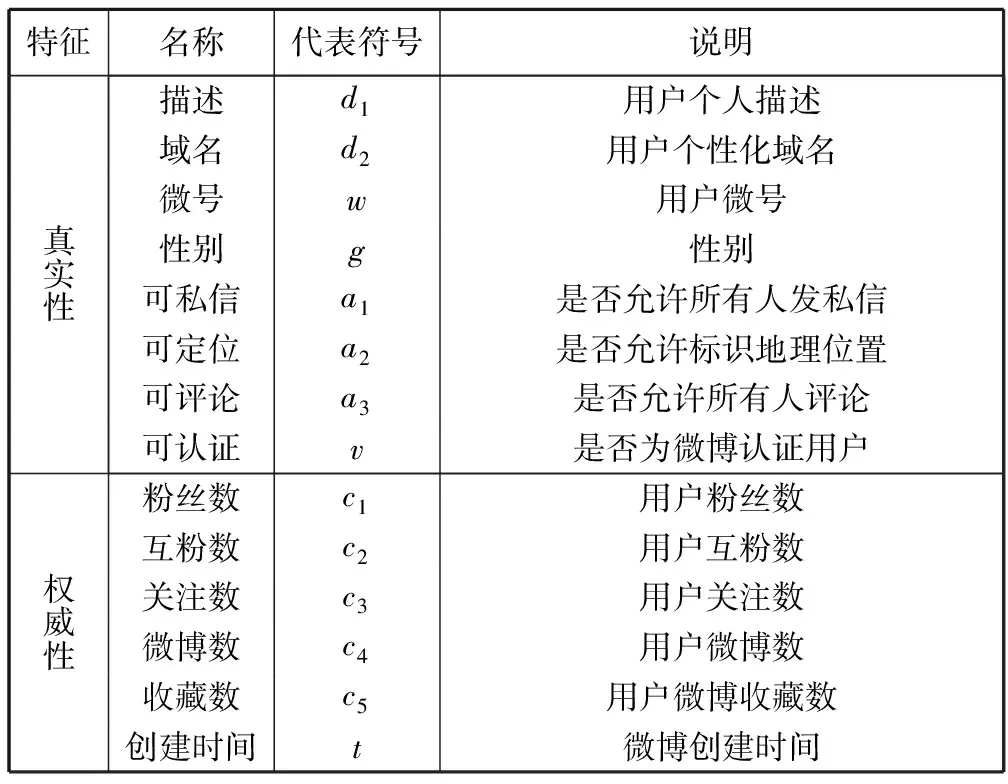
表1 用户可信度的特征说明
真实性特征主要为微博用户的个人信息,是对用户的静态描述,越是可信的用户,这些特征表现得越完备真实;权威性特征主要为用户的类型和级别及其在微博社会网络的影响力,是对用户的动态描述,可以反应出用户在平台的活动特征。
3. 用户可信度分布特征
文献[17]选取用户的微博数、粉丝数、关注数、收藏数和互粉数5个特征项,对用户可信度进行了研究,在一定程度上说明用户的权威性特征项对用户可信度具有辨别效果。因此,本节主要探索分析真实性特征对用户可信度的辨别效果。
风险管理,知易行难。引入澳新风险管理标准,风险化“无形”为“有形”。多措并举构建多元化方案,一切尽在运筹帷幄之中。
为方便起见,探索分析时,将其转化为二分类问题,即可信用户与不可信用户。由于认证用户一般具有很高的可信性,因此以其作为可信用户的替代,而非认证用户作为不可信用户的替代。由于用户个人描述、用户个性化域名等特征项处理较为复杂,简化为二分类问题,即以该特征项是否为空值为处理标准。
在新浪微博中随机抓取了1 470名用户,其中,1 394 名未进行认证,76名为认证用户。如图1所示,这是在不同真实性特征下,认证用户和非认证用户的分布情况。每个柱状图均表示认证用户与非认证用户中该信息项含有该值的用户数与不含该值用户数的比值。可见,除了“是否允许所有人评论特征项”之外,其余各个特征项下,认证用户与非认证用户的概率分布存在非常明显的差异,暗示这些特征蕴含了丰富的用户可信度信息,可以作为用户可信度划分的判别依据。
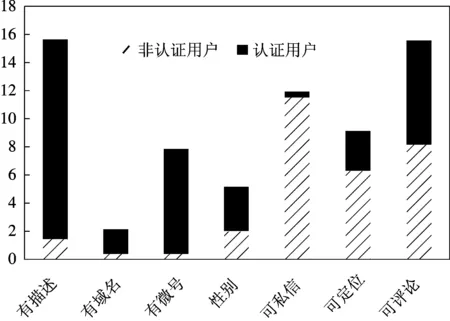
图1 认证用户与非认证用户真实性特征对比
三、 评价模型
1. 模型构建

图2 微博用户可信度评价模型
微博用户可信度评价模型的构建过程如图2所示。这是一个典型的基于数据挖掘技术的建模过程。
首先,基于微博用户公开的个人原始资料信息,通过特征转换和特征选择,获得对用户可信度具有较好辨别能力的输入特征集合,而后基于该特征集合,应用分类算法对微博用户数据进行训练,获得用户可信度评价器。该过程中,如何处理数据,构建最终的评价输入特征集合是本文评价模型的基础和核心,下面重点对其进行介绍。
2. 数据处理
数据处理的目的是利用已有的原始数据处理成一个抽象程度更高的特征集。蕴含用户可信度信息的原始特征进行处理后,才能更好地用于用户可信度的辨别。原始的公开资料信息可划分为两类:真实性和权威性。
真实性特征是对用户的静态描述,主要体现微博用户信息的完备性。本文进行处理时,根据用户是否填写相应信息,将其处理为一系列的二元属性,包含相应信息时,取值为1,否则取值为0, 如表2所示。
权威性特征取值为数值,主要体现了用户的行为特征。名人、专家、普通用户等微博用户之间和内部在这些特征的取值上存在一定差异。深入分析用户在这些特征上的不同表现之后,对其进行了数据归约和数据变换处理,而不是简单地进行离散处理。
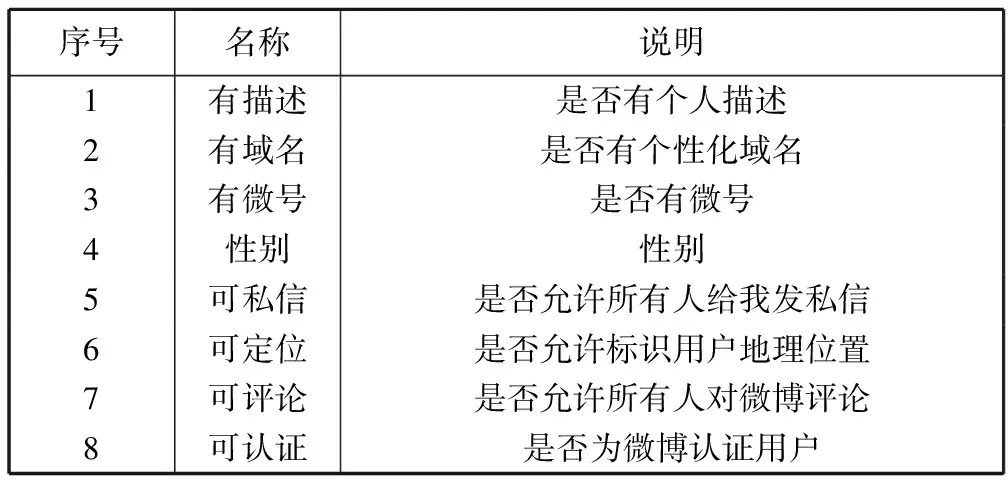
表2 真实性特征转换结果说明
(1)
(2)
(3)
涨粉速率可以体现用户受关注的程度;微博活跃度可以体现用户在微博平台的参与度;收藏活跃度可以体现用户从微博平台上获取高价值信息的程度。
类似地,通过观察分析微博用户名人、专家、普通用户在互粉数、关注数、粉丝数的不同表现,对原始特征进行了数据变换,延伸衍生出BiFo(互粉比例系数)、BiFr(关注相熟度)、FrFo(关注粉丝比) 3个特征指标,计算公式为
(4)
(5)
(6)
互粉比例系数和涨粉速率结合,可以更全面反应用户受关注的程度;关注相熟度,体现的是微博平台上的熟人社交程度,假设相互关注的人的连接强于单方面关注这种弱关系;关注粉丝比,体现的是用户在微博平台上是偏向散布信息还是获取信息,将微博间的关注行为等同于信息流的订阅与被订阅。
经过数据变换后,对获得的特征项进行检验,选取那些最具有判别能力的特征项构成最终的输入特征集合。评价用户可信度的微博用户权威性特征最终如表3所示。

表3 权威性特征转换结果说明

图3 不同特征项下认证用户(1)/非认证用户(2) 分布盒
仍以在新浪微博平台随机抓取的1 470名用户为例,以认证用户作为可信用户的替代,非认证用户作为不可信用户的替代,将其转化为二分类问题,考察特征集合中各特征对微博用户带可信度的辨别能力。如盒图3所示,这是在不同权威性特征下,认证用户和非认证用户的分布情况。由图3可见,可信用户在是否有个人描述、是否有个性化域名、是否有微号等特征方面趋向为真,可信用户更愿意通过信息的完备性让外界了解自己,但在是否允许标识用户的地理位置、是否允许所有人给自己发微信方面又趋向于假,说明可信用户可能还比较注重私人空间。在微博使用年限上,可信用户趋向于一些使用年限在4年及以上的用户。在FoPd、StPd、FavPm、BiFr、FrFo等特征方面,偏向可信用户与偏向不可信用户的特征分布也有较明显的不同,可信用户的关注相熟度普遍较高,在微博平台上表现得也比较活跃。
四、 实验
1. 实验数据
实验数据根据新浪微博提供的开放API,应用网络爬虫程序收集。首先按一定比例关注了不同类型的微博用户,例如微博名人、专家、明星和普通用户。其次,以所关注账号为中心,每天不定时地对所关注用户发出的微博进行采集。实验数据便来源于所采集的微博发布者、微博评论人的信息。
对所采集数据进行随机抽样,抽取1 600名非认证用户进行人工标注(表4为若干标注用户的实例)。标注采用3人一起进行标注的模式,对每一微博用户最终的标注结果由3人都赞同的结果决定。标注实例如表4所示。通常高可信度用户和不可信用户通过人的直觉,可以很容易地被分辨出来,而偏向可信与偏向不可信用户则差异较小,难以判别。为提高标注效率,标注时设计了一个小的标注系统,将用户特征友好的展现给标注者,在减少其工作量的同时,提高标注准确度。对1 600用户数据进行标注,最终3人标注意见一致的数据为1 203条,以其作为本文的实验数据,该数据中各类用户的分布情况如图4所示。

表4 标注用户实例
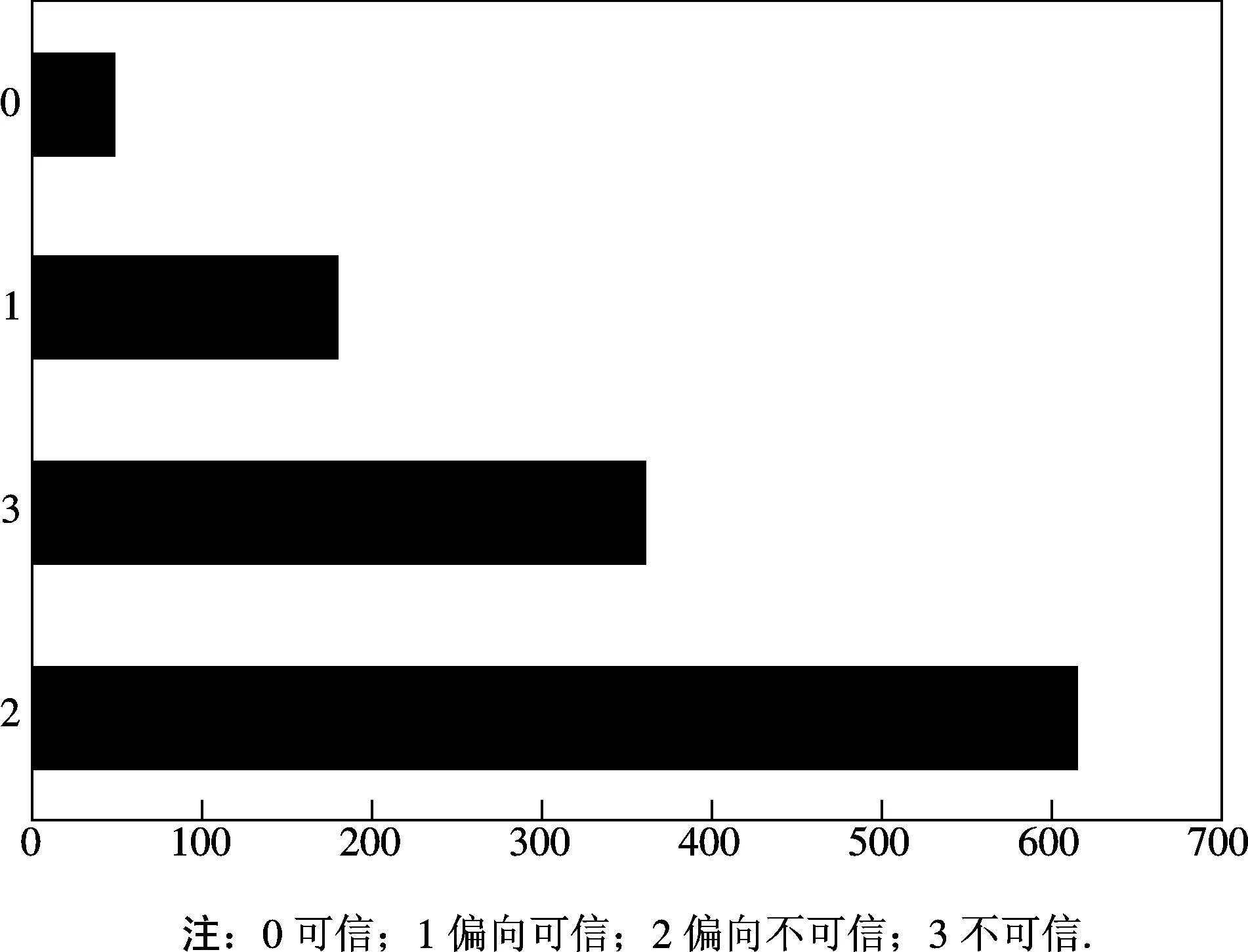
图4 标注用户的可信度分布
2. 实验方法及评估指标
实验步骤如下:步骤一,将1 203条数据随机按约75%和25%分成两部分;步骤二,基于CART决策树(CART)、朴素贝叶斯(NB)和支持向量机(SVM)3种常用分类方法在75%的实验数据上应用三折交叉验证,选取最佳分类器;步骤三,应用最佳分类器在该75%的数据集上生成训练模型,然后在剩余25%的实验数据上进行测试以评估可信度评价模型性能。
鉴于可信度评价模型应用分类方法,模型评估主要采用了评估分类方法的常用指标,即准确率、召回率和F值。同时,也考察了模型的稳定性,提供了评估结果在一定置信区间内的标准差。
3. 实验结果
步骤二各模型实验结果如表5所示。 由表5可见,CART决策树取得了较好的实验结果。在对用户可信度进行判别时,CART在95%的置信区间内达到[75.27%, 79.27%]的准确率。
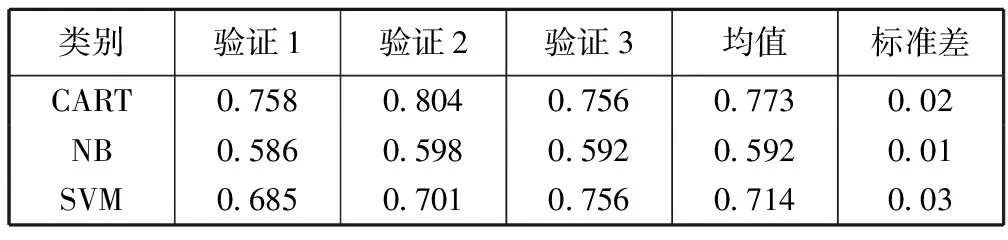
表5 各分类器实验结果对比
鉴于CART效果较好,选取CART在75%的实验数据上训练,并应用生成的训练模型在测试集上进行测试。CART在测试集上的表现如表6、表7所示。
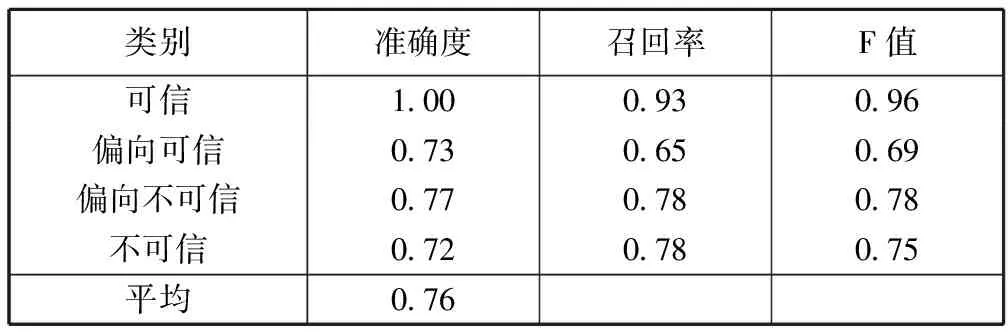
表6 用户可信度分类测试结果
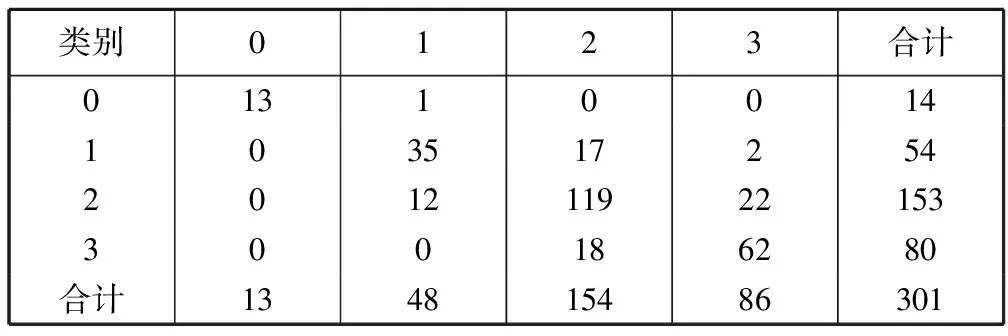
表7 用户可信度分类测试结果的混淆矩阵
注:0 可信;1 偏向可信;2 偏向不可信;3 不可信.
由表6、表7可见,模型对可信用户的识别有较高的准确度和召回率,这说明可信用户被判断为可信的概率比较高,而其他类别的用户被误判为可信用户的概率又比较低。在其他3个类别中,准确度、召回率、F值的表现都较均衡,在0.65~0.78之间,说明该模型对微博用户可信度有较好的辨别效果。
判别错误用户主要发生在相邻类别,跨类别误判的情况较少。分析其原因,可能是数据标注质量欠佳,也有可能是预测模型未拥有足够的信息更准确地区分相邻类别间的细微差别。也进一步说明,构建的微博用户特征集合还存在改善的空间,例如改善特征的组合方式,挖掘新特征加入特征集合。
总体而言,对测试集上用户可信度分类的准确率达到76%左右,在多分类问题中,该结果明显优于随机猜测,表明模型能通过用户的特征对用户可信度进行较有效的自动分类。
五、 结 语
随着微博的快速发展,围绕微博问题的研究正引起越来越多学者的兴趣。微博用户可信度度量是其中一个有趣而且有意义的问题。本文分析了将公开资料数据用于评价用户可信度的可行性,应用不同的数据挖掘分类算法,实验考察了这些数据对用户可信度的识别性能。结果表明,通过数据挖掘方法构建的评价模型,其评价准确率达到了76%的水平。这充分说明,这些公开的资料信息蕴含着丰富的用户信誉信息。本文的主要贡献在于:1) 用于用户可信度评估的基础数据具有易获得性,相比于微博信息本身,或者微博用户之间的关联信息之类的数据,本文建议的数据更加便于处理,且不涉及个人隐私的侵犯;2) 本文从用户真实性和权威性两个角度对用户相关信息进行梳理,提出若干用户可信度评价特征抽取公式,这对模型构建具有至关重要的作用。需要指出的是,构建评价模型时,各特征并未根据对可信度的辨别效果的不同而赋予不同权重;数据挖掘算法也仅应用了单一的分类算法,未进行综合。改善上述问题,构建更为有效的微博用户特征集合,进一步提高微博用户可信度模型的评估性能,也是下一步的研究工作。
[1] Gupta A, Kumaraguru P. Credibility ranking of tweets during high impact events[C]//Proceedingsofthe1stWorkshoponPrivacyandSecurityinOnlineSocialMedia. New York:ACM Press, 2012: 2.
[2] Mendoza M, Poblete B, Castillo C. Twitter under crisis: Can we trust what we RT? [C]//ProceedingsoftheFirstWorkshoponSocialMediaAnalytics. New York:ACM Press, 2010: 71-79.
[3] Qazvinian V, Rosengren E, Radev D R, et al. Rumor has it: Identifying misinformation in microblogs[C]//ProceedingsoftheConferenceonEmpiricalMethodsinNaturalLanguageProcessing. Stroudsburg:Association for Computational Linguistics, 2011: 1589-1599.
[4] Kwak H, Lee C, Park H, et al. What is twitter, a social network or a news media? [C]//Proceedingsofthe19thinternationalConferenceonWorldWideWeb. New York: ACM Press, 2010: 591-600.
[5] Castillo C, Mendoza M, Poblete B. Information credibility on twitter[C]//Proceedingsofthe20thInternationalConferenceonWorldWideWeb. New York:ACM Press, 2011: 675-684.
[6] Gupta M, Zhao P, Han J. Evaluating event credibility on twitter[C]//ProceedingsoftheTwelfthSIAMInternationalConferenceonDateMining.Anaheim:Omni Press, 2012: 153-164.
[7] Morris M R, Counts S, Roseway A, et al. Tweeting is believing?: Understanding microblog credibility perceptions[C]//ProceedingsoftheACM2012ConferenceonComputerSupportedCooperativeWork. New York: ACM Press, 2012: 441-450.
[8] Suzuki Y. A credibility assessment for message streams on microblogs[C]//P2P,Parallel,Grid,CloudandInternetComputing(3PGCIC), 2010InternationalConference. Piscataway: IEEE, 2010: 527-530.
[9] 王 晟, 王子琪, 张 铭. 个性化微博推荐算法[J]. 计算机科学与探索, 2012, 6(10): 895-902.
[10] Bakshy E, Hofman J M, Mason W A, et al. Everyone’s an influencer: Quantifying influence on twitter[C]//ProceedingsoftheFourthInternationalConferenceonWebSearchandDataMining. New York: ACM Press, 2011: 65-74.
[11] Cha M, Haddadi H, Benevenuto F, et al. Measuring user influence in twitter: The million follower fallacy[J].ICWSM, 2010, 10(10-17): 30.
[12]GhoshR,LermanK.CommunityDetectionUsingaMeasureofGlobalInfluence[M].Berlin:Springer:2010:20-35.
[13] Ghosh S, Sharma N, Benevenuto F, et al. Cognos: Crowdsourcing search for topic experts in microblogs[C]//Proceedingsofthe35thInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval. New York: ACM Press, 2012: 575-590.
[14] 原福永, 冯 静, 符茜茜. 微博用户的影响力指数模型[J]. 现代图书情报技术, 2012, 28(6): 60-64.
[15] 王 峰, 余 伟, 李石君. 新浪微博平台上的用户可信度评估[J]. 计算机科学与探索, 2013, 7(12): 1125-1134.
[16] Canini K R, Suh B, Pirolli P L. Finding credible information sources in social networks based on content and social structure[C]//ProceedingsoftheThirdIEEEInernationalConferenceonSocialComputing(SocialCom). Piscataway: IEEE, 2011: 1-8.
[17] Al-Sharawneh J, Sinnappan S, Williams M A. Credibility-based twitter social network analysis [C]//WebTechnologiesandApplications. Berlin: Springer, 2013: 323-331.
[18] Gupta M, Zhao P, Han J. Evaluating event credibility on twitter[C]//ProceedingsoftheTwolfthSIAMInternationalConferenceonDataMining. Anaheim: Omni Press, 2012: 153-164.
[19] Chu Z, Gianvecchio S, Wang H, et al. Detecting automation of twitter accounts: Are you a human, bot, or cyborg?[J].IEEETransactionsonDependableandSecureComputing, 2012, 9(6): 811-824.
[20] 闫光辉, 刘晓飞, 王梦阳. 基于链接的微博用户可信度研究[J]. 计算机应用研究, 2015, 32(10): 2910-2913.
[21] 徐建民, 粟武林, 吴树芳, 等. 基于逻辑回归的微博用户可信度建模[J]. 计算机工程与设计, 2015, 36(3): 772-777.
猜你喜欢
中国交通信息化(2023年10期)2023-11-30 06:04:22
中国特种设备安全(2022年1期)2022-04-26 14:16:06
廊坊师范学院学报(自然科学版)(2020年1期)2020-04-17 07:32:12
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
疯狂英语·新读写(2018年3期)2018-09-07 11:10:56
NBA特刊(2018年14期)2018-08-13 08:51:40
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
人大建设(2017年11期)2017-04-20 08:22:49
瞭望东方周刊(2015年12期)2015-04-14 23:28:02
