
一种适用于DB_CTC的改进译码算法
2018-05-28 22:09刘志鹏
中国电子科学研究院学报 2018年2期
刘志鹏,谢 佳
(中国电子科学研究院,北京 100041)
0 引 言
1993年,Turbo码在国际通信会议上被提出[1],由于其极好的译码性能,引起了巨大的轰动,被认为是自1982年TCM提出之后在通信编码领域最重大的发明。随后,各国学者开始了对Turbo的深入研究,在1999年,非二元卷积Turbo码的概念被提出[2]。其中DB_CTC(双二进制Turbo码)得到了广泛研究。
相比于经典的二元Turbo码,DB_CTC在设计高码率时,有更少的凿孔,有更多的校验位,从而能够提高译码性能[3];DB_CTC采用二位二进制数据作编码,译码效率提高了一倍,同时网格长度减少,相应地减少了错误路径[4];DB_CTC交织深度相对于经典的二元Turbo码降低了一倍,但是由于DB_CTC不仅有符号间交织同时还有符号内交织,因此DB_CTC能够获得更好的码字重量分布[5-6]。经典的二元Turbo码会有一个明显的错误平层,而研究表明,DB_CTC采用Max-log-MAP算法时,在误码率为10-9时才出现轻微的错误平层[7]。经典的二元Turbo码要将编码器恢复到初始状态需要添加尾比特,而DB_CTC能够进行自结尾[8],不需要添加尾比特,这在短码设计时,能够提高编码效率。因此,DB_CTC已经被数字电视广播地面回传信道、数字电视卫星反传信道、全球微波互联接入等国际标准采纳为无线数字传输的前向纠错(FEC:Forward Error Correction)码型。
本文组织结构如下。首先介绍了DB_CTC的编码结构,包括分量编码器、交织器、删余器以及如何进行咬尾设计等;随后介绍了基于符号的MAP算法,与经典的二元Turbo码的译码算法相比,基于符号的MAP算法输入信息不再是单个序列而是两个序列,而且在求解前向递推联合条件概率、后向递推联合条件概率和对数似然比时有四项,不再是简单的两项[6]。针对基于符号的MAP算法中只利用了一路译码器的输出信息,本文提出了利用两路译码器输出信息的改进MAP算法,并通过仿真结果对改进的算法进行了验证。最后给出了本文的结论。
1 编码结构
DB_CTC的编码器结构如图1所示。首先信息比特经过串并转换转为并行的a、b两路。a、b两路的信息比特xa和xb经过分量编码器1输出校验信息xp0和xp1(输出的校验信息个数与分量编码器的结构有关,本文中采用的分量编码器的结构输出两个校验信息)。a、b两路的信息比特xa和xb通过交织后进入分量编码器2(一般来说,分量编码器1和分量编码器2的结构是一样的,本文默认是一样的)输出校验信息xp2和xp3。信息比特和校验比特经过删余器后,通过并串转换得到相应码率的输出信息。
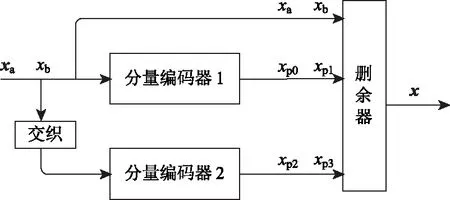
图1 编码器结构
1.1 分量编码器
在本文中,图1中分量编码器的结构图如图2所示,采用的是反馈卷积码。
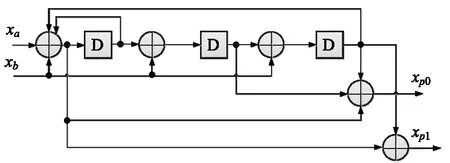
图2 分量编码器结构
1.2 删余器
对于码率为2/3、1/2和1/3的删余结构如表1所示。在表1中的P0、P1、P2、P3代表图 1中的校验信息xp0、xp1、xp2和xp3;“√”表示该校验位在相应的码率时被使用,“×”表示该校验位在相应的码率时未被使用。
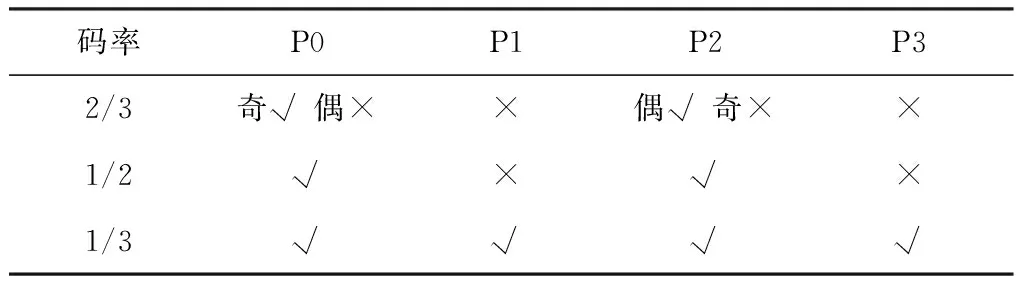
表1 删余结构表
1.3 交织器
为了设计方便,本文结合了IEEE 802.16建议的交织器和伪随机交织器设计了本文使用的交织器。这里交织器分两步实现。
第一步,符号内交织。交换A、B两路的部分数据。交换规则为,如果j mod 2=1,则交换,否则不交换,其中j=0,1,…,N-1。
第二步,符号间交织。对交换后的A、B两路数据分别采用相同的伪随机交织器进行交织。
1.4 咬尾设计
根据式(1)[8]可以确定编码的起始状态S0(或者称为循环状态Ssc)。
(1)
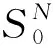
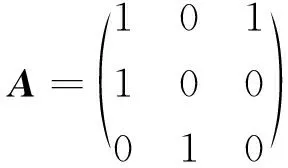
(2)
由于设计时编码器的起始状态要根据具体的比特信息来确定,因此对于接收方而言很难知道编码器的起始状态。译码时,编码器的起始状态的确定有循环状态估计法[9]和边界状态度量反馈方法[10]。本文中采用边界状态度量反馈方法。边界状态度量反馈方法是指把正向递归得到的终止时刻的前向状态度量和反向递归得到的初始时刻的后向状态度量反馈给自己,用来初始化下一次迭代的前向状态度量和后向状态度量[4]。
2 译码算法
对于DB_CTC的译码可以采用基于符号的译码算法和基于比特的译码算法,基于比特的译码算法的误码率相对于基于符号的译码算法的误码率相差0.1个dB[3]。因此本文将重点研究基于符号的MAP译码算法。
2.1 基于符号的译码算法
基于符号的译码算法的判决准则为
(4)
在引入对数似然比(LLR)后,判决准则变为
(4)
其中
(5)
(6)
(7)
而
(8)
对式(8)进一步分解后可以得到
(9)
显然对数似然比λ01(xt|r)由系统信息、先验信息和外部信息组成,其中系统信息(也即后验信息)为
(10)
先验信息为
(11)
外部信息为
(12)
(1)系统信息
(13)
同理可以得到
(14)
(15)
(2) 先验信息
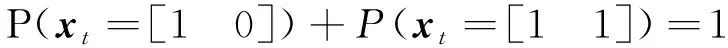
(16)
利用指数和对数的对应关系,可以得到
根据式(5)、(6)和(7),可以得到
所以
(17)
同理,可以得到
(18)
(19)
(20)
(3) 外部信息
(21)
(22)
(23)
(24)
2.2 改进算法
式(4)的等效判决规则为
(25)
(26)
上述的判决规则中只利用了一路的输出信息,而实际中两路译码器是并行的,而只利用一路译码器的输出信息,显然会丢失信息量。
如果译码器1的输出信息和译码器2的输出信息都在0值附件,但是二者的符号相反,此时说明该信息具有很大的不确定性,显然如果只取译码器1的输出信息,具有很大的误判,这时可以取二者之间的绝对值最大的作为判决依据,即
λ210(xt|r)+λ211(xt|r)-λ201(xt|r)]}
(27)
λ201(xt|r)+λ211(xt|r)-λ210(xt|r)]}
(28)
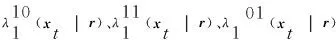
式(27)和式(28)等价于式(29)和式(30):
λ210(xt|r)+λ211(xt|r)-λ201(xt|r)]
(29)
λ201(xt|r)+λ211(xt|r)-λ210(xt|r)]
(30)
经过改进后的译码结果如图3所示。
3 仿真结果
本文中采用的交织器为伪随机交织器,迭代次数为4次,帧数200帧,每一帧5000比特,码率2/3和1/2情况下的误码率曲线如图4所示。很明显,改进的译码算法的误码率更低。
4 结 语
在传统的DB_CTC译码算法中,判决时只利用了一路译码器的输出信息,另一路的译码输出信息没有被充分利用。DB_CTC的两个译码器是并行过程,利用两路的译码输出信息可以降低误码率。本文提出的改进译码算法即是利用两路的译码输出信息作为判决信息,并且仿真结果表明本文提出的改进算法能够有效降低DB_CTC的误码率。
:
[1] C. Berrou, A. Glavieux and P. Thitimajshima. Near Shannon limit error-correcting coding and decoding: Turbo-codes [C]. Proc. ICC’93, Geneva, Switzerland. pp. 1064-1074, 1993.
[2] C. Berrou and M. Jezequel. Non-binary convolutional codes for turbo coding [J]. Electronics Letters, vol. 35, no. 1, pp. 39-40, Jan. 1999.
[3] 詹明. 双二元卷积Turbo码译码算法 [D]. 电子科技大学:博士论文. 2013.04.
[4] 王臣. 双二元卷积Turbo码的并行译码研究 [D]. 电子科技大学:硕士论文. 2012. 05.
[5] Part 16: Air Interface for Broadband Wireless Access Systems [S]. IEEE Std 802.16 TM-2009, May 2009.
[6] 刘东华,梁光明. Turbo码设计与应用 [M]. 北京:电子工业出版社, 2011.04.
[7] C. Berrou, M.Jezequel, C. Douillard et al.. The advantages of non-binary Turbo codes [C]. Proceeding of IEEE Information Theory Workshop (ITW), Cairns, Qld. pp.61-63, 2001.
[8] Kamal J. Koshy, San Jose CA, and Raghavan Sudhakar. Efficient CTC encoders and methods [P]. United States Patent Application Publication No: US 2008/163022 A1, Jul. 2008.
[9] Se-Bin Im, Min-Gu Kim, and Hyung-Jin Choi. An efficient tail-biting MAP decoder for convolutional turbo codes in OFDM system [J]. TENCON 2004, vol.2, pp. 589-592.
[10] C. Zhan, T. Arslan, A.t. Erdogan, and S. MacDougall. An efficient decoder Sheme for double binary cicular turbo codes [J]. Acoustics, Speech and Signal Processing, 2006, pp IV.
猜你喜欢
美食(2022年2期)2022-04-19
计算机工程(2022年1期)2022-01-14
沈阳工业大学学报(2021年6期)2021-11-29
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
女报(2019年3期)2019-09-10
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
科教导刊·电子版(2016年36期)2017-04-22
华人时刊(2016年17期)2016-04-05
