
基于Hadoop的地表温度反演系统的设计与实现*
2018-05-22 03:50郑逢斌
计算机时代 2018年5期
袁 帅,郑逢斌
(河南大学计算机与信息工程学院,河南 开封 475004)
0 引言
地球表面温度LST(Land surface temperature)是指,全球的陆地表层系统和水体表层系统与大气之间相互作用,能量交换的临界层的温度。地球表面温度是当前人类生活圈中一项非常重要的指标参数。该参数在研究全球气候变化(如温室效应),全球植被的生长(如NDVI,PVI的分析),自然资源的生成和消亡(如非洲动物的大迁徙),人类的生活、生产和生存(如农田温度对水汽蒸发的影响)条件时,具有很高的意义和价值[1]。
研究表明,通过常规的地表观测或多地点的定点采样等一系列方法,都不能很好地适用于地表温度复杂多变的模型中去,进而发现只有通过卫星遥感技术,才是目前惟一的解决方式[2]。遥感反演本身既是计算密集型,同时又是数据密集型的科学应用[3],随着我国空间技术的发展,遥感信息的数据量也呈现出爆炸式增长,海量的遥感数据也对计算能力和存储环境提出了新的要求。基于我国自主卫星的条件和优势,在海量的遥感数据中更高效地处理和提取出地表温度值,就成了需要面临的问题。
针对上面的问题,本系统使用了并行计算和HDFS技术来对大量基于五层十五级理论的数据进行处理和存储,应用Hadoop提供的分布式集群框架来形成一个大数据开发计算平台。其可以提供在特定时间内特定区域的地表温度值的遥感数据分布情况的查看统计等功能。
1 基于Hadoop环境下的系统架构
1.1 总体说明
该系统的总体架构以大数据的云计算框架作为思路,根据生产流程,相应的划分为客户端,信息传递层,平台层,数据存储层。系统的总体设计思路如图1所示。
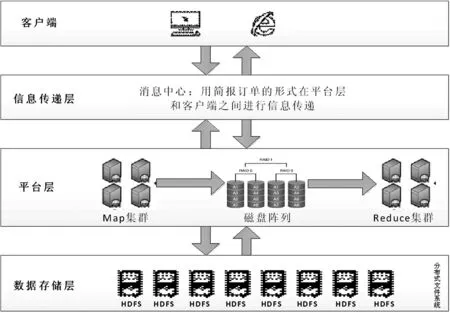
图1 系统总体设计图
⑴ 用户交互层
用于可视化和处理用户需求,也使得用户对系统流程和本身进度有一个清晰的认识,可根据用户自身需求来进行相应设计和调整。
⑵ 信息传递层
把用户的需求做成订单,传递给平台层,并传递平台层的运行进度情况和最终的遥感处理数据,以便于用户进行可视化操作,所有的信息都会用生成简报订单的方式在交互层和平台层之间传递。
⑶ 平台层
这一层级是整个系统的核心,提供对遥感数据处理的核心服务与管理,卫星原始输入的数据放入磁盘阵列之后,通过相应流程得到温度反演产品。此流程进行MapReduce并行化处理,用来缩短需要处理海量数据的时间,从而获得更高的效率。Map阶段根据实际需求,用并行的方式对磁盘阵列中的遥感原始数据进行采样,得到发射率文件并生产星上亮温产品和大气水汽产品,最终得到温度反演产品。Reduce阶段则是对Map阶段的产品碎片进行拼接处理和规约统计,使用户可以方便的查看地表温度数值在特定区域的分布情况。
⑷ 数据存储层
这一层级是存储数据的硬件层,其有两个功能:数据信息的存储和查询。
鉴于遥感数据是非常宝贵的资源,为了防止硬件故障或存储环境问题,导致遥感数据的丢失,本系统采用了HDFS数据块多副本存储设计,由于每个数据块都进行了多副本存储,最大程度的保证遥感数据的完整性。①文件分块来进行读写提高了文件随机读取的效率。②保存切分的数据块副本不但分摊了数据存储的风险,而且由于可以并发读取提高了效率。③遥感数据进行切分后,不但契合于MapReduce并发技术,而且契合了HDFS的策略思想,可以很好的实现高性能和高可靠性的珍贵遥感数据存储数据。本层的PC机硬件集群中都会采用HDFS多副本存放策略,数据分块会采用HDFS策略的默认大小,读写数据块都通过其本身的NameNode节点进行遥感数据的管理。
1.2 算法与流程说明
1.2.1 关键算法说明
本系统采用的地表温度反演产品生产的总体算法结构如图2所示。

图2 反演过程图
本系统中,星上温度计算运用了普朗克公式:

其中,Mλ(T)的单位为W·m-2·μm-1;Bλ(T)的单位为W·m-2·μm-1·Sr-1。
传感器收到的辐射亮度可以由以下公式作为表达:
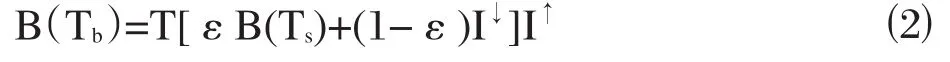
其中,Tb是卫星上的亮度温度(K);Ts是地表温度(K);I↓和I↑分别表示大气下行和上行辐射;T和ε分别为大气透过率和地表发射率
由公式⑵可进行继续推导,从而得到单窗算法方程:
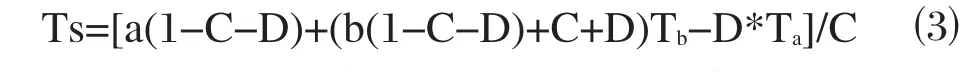
其中,Ta是大气平均作用温度(K),Tb、Ts意义同上;a、b为常数;C=ε*T;D=(1-T)[1+(1-ε)T]。
当我们假定地表为朗伯体时,可求表观反射率ρ,如下:

其中,θ代表了太阳入射天顶角;而波段内的平均辐射照度用ESλ来表示;d为太阳和地球之间的平均距离;Lλ则代表了卫星传感器的接受亮度。
本系统的算法是把大气的影响因子放入方程中进行演算,需要大体流程中需要三个参数,可参考函数总体结构图大气透过率,大气水汽含量就对反演的精度影响较大,地表反演误差一般为1.2K。而大气水汽含量又由相对湿度和饱和水汽压两部分组成,其关系如图3所示。

图3 大气柱含水量流程图
1.2.2 产品生产流程
在初始的遥感数据输入阶段中,根据原始数据量的大小,将按五层十五级标准切出来的瓦块数据作为原始的卫星遥感数据放入磁盘阵列做原始参数。由于瓦块数据为卫星遥感产品的.tif格式文件,为了更加方便进行Hadoop操作,在输入数据时先把图像瓦块数据转换成txt格式,其文本信息按行、列进行存储,每一行为一个记录单位,其中划分为{经纬度、日期、温度反演值内容}字段信息,为了使键值信息中的Key-value的对应关系更加准确,在字段信息的外部把该记录单位的起始位置与相对应文件的起始位置的偏移进行量化和记录。然后使用MapReduce模型中的TextInputFormat并行程序类把瓦块数据集中的信息进行文本文档形式的输入。
在Map阶段,需要把初始输入的单位原始卫星数据计算转化为地表温度反演产品。这一过程主要包括从中提取出需要的反射率文件,通过近红外比值法获得大气水汽数据,再使用普朗克公式得到相应的星上亮温数据,最后通过单窗算法获得地表温度反演产品。如图4所示(右侧为Map阶段中的流程)。
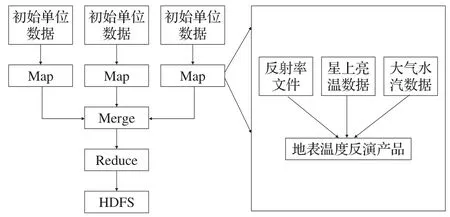
图4 基于MapReduce的温度反演产品生产流程图
Map阶段作为映射阶段(如图5),在初始单位数据进入map阶段后,根据应用中的相应需求,对map()函数进行设计,本系统的map()函数中的键值对信息分别包含为(地表温度反演值,<经度,纬度,日期>),并且对地表温度反演所求的null值和0值进行筛选过滤。其中间过程值如:反射率文件,星上亮温数据和大气水汽数据所求的数值,也会按照对应日期和标准写入环形内存缓冲区(即磁盘阵列)中,以便后续在有需要的情况下进行二次查询。而所求得的地表温度反演值则通过Partitioner类中的get/set方法进行分区的实现,在不同的分区中每一个键值对应一个结果值进行排列(如:Key-LST值)。为了提升传输效率,本系统会在此阶段增加组合器,即意味在这个阶段就进行简单的Reducer,利用combiner中的方法对需要的数据进行规约,理想状态下数据应合并为以键值为依据用空格隔开的形态(如:LST值,{<1经度,1纬度,日期>,<2经度,2纬度,日期>,<3经度,3纬度,日期>,…})。其combiner状态使用心跳周期的TaskTracker通过RPC协议汇报给JobTracker,再经过调配,给相应的计算节点分配不同的Task进行Reducer阶段运算。
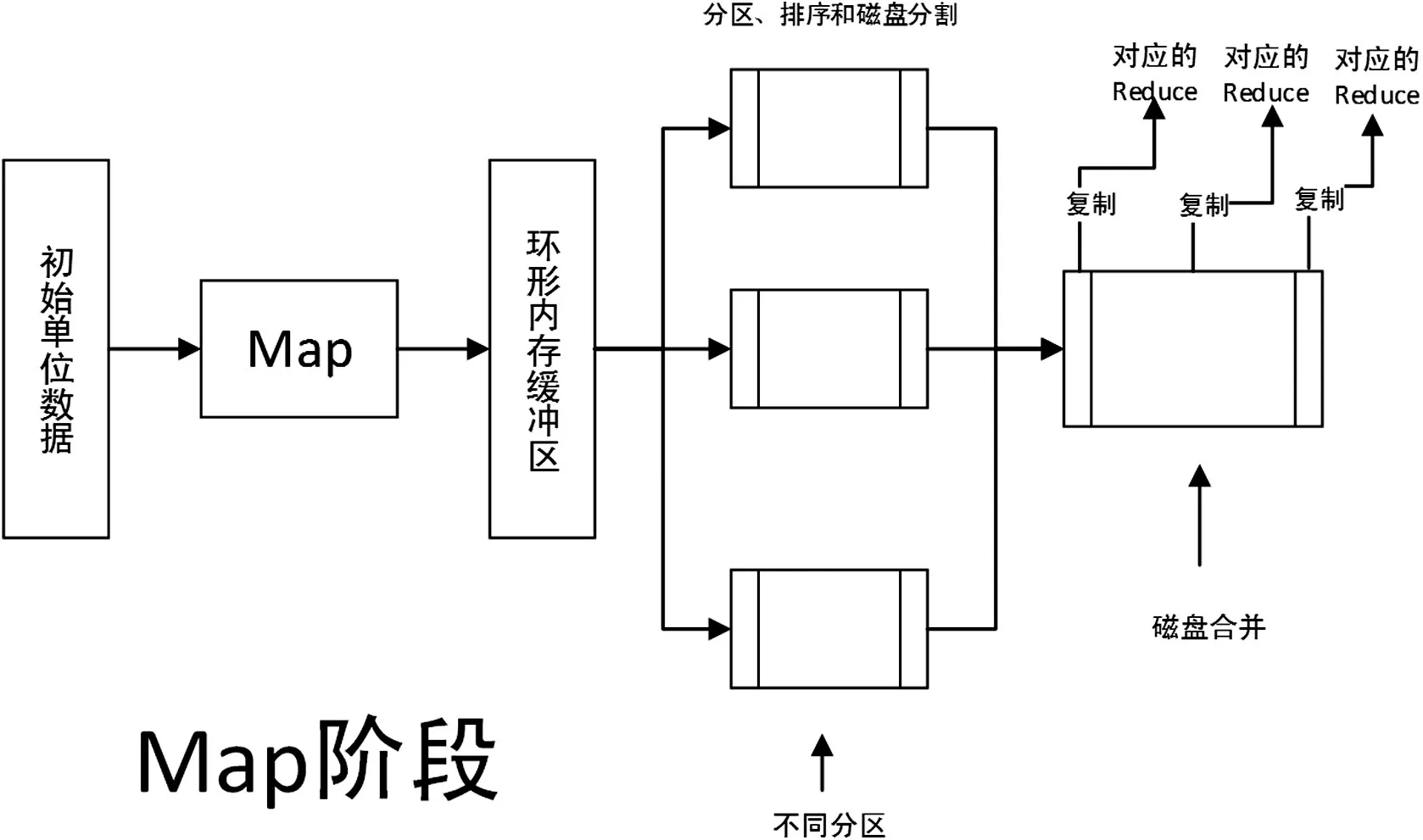
图5 Map阶段流程图
Merge阶段为Map阶段得出的内容,经过经纬度等有规则的排序合并,从而得出相应遥感数据的过程。经过排序合并后的数据则输入到Reduce阶段中进行规约合并,而每个Reducer任务会根据Map阶段中按键值进行简单合并后的结果,利用哈希函数进行按天数时间对应关系的规约合并,这样便可实现对特定需求时间内的特定区域的LST值进行统计和查询。
HDFS阶段则是Reducer中的每一个Reduce都是一个相应的输出文件。每一个Reduce任务规约合并完成,得到需要的产品后,随即利用HDFS存储策略存入数据存储层的PC硬件中,如图2所示。
最后,为了使用户可以清晰而便捷的可视化到特定时间、一定区域反演的地表温度产品,需要对生成的温度反演产品的具体数值进行统计,根据统计出的数值利用普朗克公式的反函数,根据辐射亮度求得地表真实温度。按照反演流程规约的键值对应,即可查到用户需求的特定时间和地点的地表温度空间分布图,其与高分卫星的可见光波段进行合成,就能得到更直观的彩色卫星图。
2 实验与分析
2.1 性能分析
本系统的实验数据使用“高分一号”卫星京津冀地区2017年7~10月份原始数据约250GB。实验环境为Dell PowerEdgeM6348刀片服务器(八个刀片及外围设备,中央处理器双核、intelXeon E5),以及戴尔Precision T7810工作站,磁盘阵列200T。具体数据如表1所示。
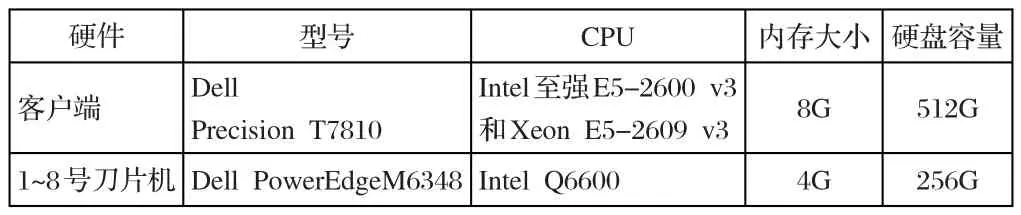
表1 实验硬件数据表
八个刀片机设备之间的物理联系图和逻辑连接图如图6所示。

图6 刀片机间的物理逻辑与连接图
安装JDK、Hadoop等必须的软件环境,使用VMware虚拟机,使用虚拟机将每台刀片机虚拟为多台机器,可以根据实验需要自由组成1、2、4、8、16、32节点的hadoop集群等,用以验证本系统的并行运算是否具有高效性,其实验的时间结果如图7所示。
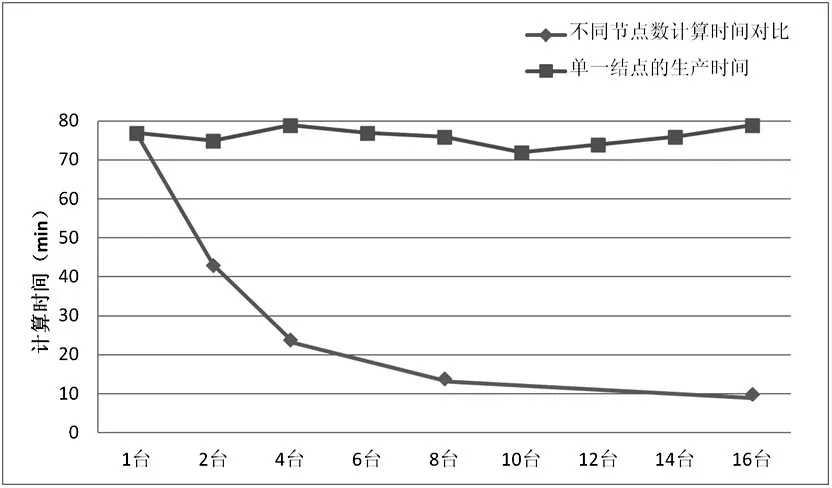
图7 不同节点数的产品生产时间对比
可以直观的看出,用单一的生产节点运算,需要时长约76分钟左右,而随着集群节点数增长,对产品生产流程做并行处理后,生产时间非常显著的降到了10分钟左右。对比单机生产模式,本系统策略缩短了生产时间,在生产效率方面做出了大幅度的提升。
3 结束语
尝试性的对海量遥感数据进行地表温度反演的生产处理,基于Hadoop平台自身服务对节点数目没有明显限制的特性,可以方便的用不同节点数的集群来进行测试,并使用HDFS副本存储策略,进行安全且高效的读取存储,实现了对海量遥感数据进行更高效的处理和存储。
系统也有一定缺陷,如当遥感数据量过小,本系统的并行处理因为需要相互间信息的传递,反而没有单机运算的效率高;由于算法原因,遥感数据图像中多云或气溶胶影响较大时,对地表温度反演产品的精度有一定影响。
未来将进一步规划、研究和完善算法及流程,并将其扩展到更多的遥感反演算法中去,实现遥感产品生产整体的高效化与应用化。
参考文献(References):
[1]朱贞榕,程朋根,桂新,腾月,童成卓.地表温度反演的算法综述[J].测绘与空间地理信息,2016.5.25.
[2]万伟,基于网格的高性能气溶胶遥感定量反演研究[D].中国科学院遥感应用研究所,2008.
[3]孟鹏,胡勇,巩彩兰,李志乾,栗琳.热红外遥感地表温度反演研究现状与发展趋势[J].遥感信息,2012.
[4]潘巍,李战怀.大数据环境下并行计算模型的研究进展[J].华东师范大学学报(自然科学版),2014.5:43-54
猜你喜欢
军事文摘(2023年10期)2023-06-09
中等数学(2022年5期)2022-08-29
科学与社会(2022年1期)2022-04-19
莫愁(2019年36期)2019-11-13
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
河北书画研究(2016年2期)2016-08-24
营销界(2015年22期)2015-02-28
海峡姐妹(2015年6期)2015-02-27
长江大学学报(自科版)(2014年2期)2014-03-20
